在自然語言處理(NLP)的廣闊天地中,序列數據是絕對的核心——無論是流淌的文本、連續的語音還是跳躍的時間序列,都蘊含著前后緊密關聯的信息。傳統神經網絡如同面對一幅打散的拼圖,無法理解詞語間的順序關系,注定在序列任務上舉步維艱。而循環神經網絡(RNN)的誕生,正是為了解決這一核心挑戰,為機器賦予了處理序列信息的記憶能力。
一、序列數據:NLP世界的基石
序列數據無處不在:
-
文本序列:?"我愛自然語言處理" – 每個字的位置都影響語義
-
語音信號:?隨時間變化的聲波,前后幀高度相關
-
時間序列:?股票價格、氣象數據、用戶行為日志
關鍵特性:?序列中元素的順序至關重要。"貓追老鼠"與"老鼠追貓"意義截然相反。傳統神經網絡(如MLP、CNN)的固定輸入輸出結構無法有效建模這種動態的、長度可變的依賴關系。
二、RNN:賦予網絡記憶的靈魂
RNN的核心思想直擊要害:引入“記憶”概念,使網絡具備對歷史信息的持續感知能力。
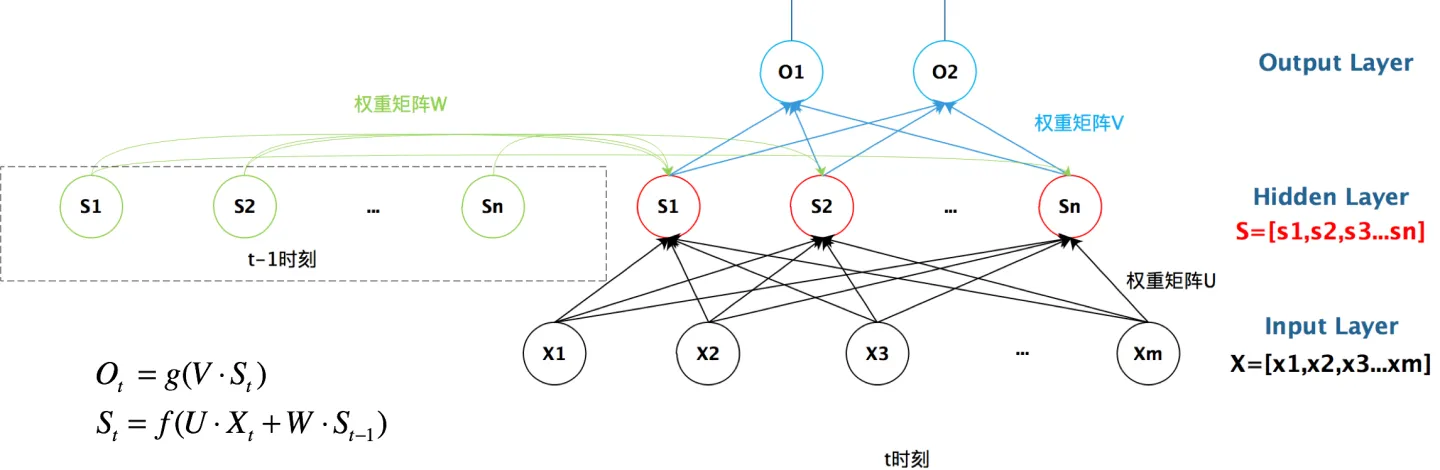
1. 循環結構:時間展開的秘密
想象一個不斷自我更新的筆記本:
-
輸入序列:?在時間步?
t,接收輸入?x_t(如句子中的第t個詞向量) -
隱藏狀態?
h_t:?網絡的“記憶體”,編碼了截至當前時間步的所有歷史信息 -
輸出?
y_t:?基于當前記憶?h_t?生成的預測(如下一個詞的概率分布)
核心遞歸公式:
h_t = f(W_{xh} * x_t + W_{hh} * h_{t-1} + b_h)
y_t = g(W_{hy} * h_t + b_y)
其中:
-
f?和?g?是激活函數(如?tanh,?softmax) -
W_{xh},?W_{hh},?W_{hy}?是權重矩陣 -
b_h,?b_y?是偏置向量 -
h_{t-1}?是前一時間步的隱藏狀態,充當了記憶的角色
RNN在時間維度上展開,形成深度網絡鏈,共享參數W?
 ?
?
2. 參數共享:智慧的傳承
與傳統網絡不同,RNN在所有時間步共享同一組參數?(W_{xh},?W_{hh},?W_{hy})。這帶來兩大優勢:
-
模型尺寸恒定:?無論輸入序列多長,參數量不變,大大提升內存效率
-
泛化能力增強:?網絡學會的“處理序列片段”的知識可泛化到序列的不同位置
3. 前向傳播:記憶的流動之旅
以句子“我愛NLP”為例(分詞為["我", "愛", "NLP"]):
-
t=1:輸入?x1 = "我",初始?h0?常置零向量
h1 = tanh(W_{xh} * "我" + W_{hh} * h0 + b_h)?→ 記憶更新為包含“我” -
t=2:輸入?x2 = "愛"
h2 = tanh(W_{xh} * "愛" + W_{hh} * h1 + b_h)?→ 記憶融合了“我愛” -
t=3:輸入?x3 = "NLP"
h3 = tanh(W_{xh} * "NLP" + W_{hh} * h2 + b_h)?→ 記憶包含完整句子信息 -
輸出?
y3?可能預測句子結束符或下一個可能詞
三、RNN的訓練:穿越時間的反向傳播(BPTT)
訓練RNN如同教導一個擁有記憶的學生回顧歷史錯誤。BPTT算法是標準反向傳播在時間軸上的擴展:
-
前向傳播:?沿時間軸展開網絡,計算所有?
h_t?和?y_t -
計算損失:?匯總各時間步損失(如交叉熵)
L = Σ L_t(y_t, y_true_t) -
反向傳播:?從?
t=T?開始倒序計算梯度:-
損失?
L?對?y_t?的梯度 -
y_t?梯度反向傳播至?h_t -
關鍵:?
h_t?的梯度不僅來自當前輸出,還來自下一時刻的隱藏狀態?h_{t+1}(因為?h_t?影響?h_{t+1}),梯度計算變為:
?L/?h_t = (?L/?h_t|_{direct}) + (?L/?h_{t+1} * ?h_{t+1}/?h_t)
-
-
參數更新:?累加所有時間步梯度,更新共享權重?
W
四、RNN的阿喀琉斯之踵:挑戰與局限
盡管開創性,基礎RNN面臨嚴峻挑戰:
1. 梯度消失/爆炸:記憶的消散與風暴
-
問題本質:?計算?
h_t?對?h_k (k<<t)?的梯度時,涉及多次矩陣連乘:
?h_t / ?h_k ≈ ∏_{i=k}^{t-1} (diag(f') * W_{hh}) -
梯度消失:?若?
W_{hh}?的特征值?<1,梯度指數級衰減 → 網絡無法學習長距離依賴(如段落開頭的主題詞影響結尾) -
梯度爆炸:?若?
W_{hh}?的特征值?>1,梯度指數級增長 → 數值溢出,訓練崩潰 -
影響:?RNN實際只能有效利用有限歷史(約10步),成為處理長序列的瓶頸。
2. 長程依賴建模困難
梯度消失直接導致模型難以關聯序列中相隔較遠的相關元素,如:
“在遙遠東方的古老王國里,住著一位...(數百詞后)...?巨龍守護著寶藏。”
基礎RNN可能遺忘關鍵主語“巨龍”與開頭的關聯。
3. 計算效率與并行化
RNN的順序依賴性(計算?h_t?必須先有?h_{t-1})阻礙了GPU的并行加速潛力,訓練速度受限。
五、進化之路:RNN的強力變體
為克服基礎RNN缺陷,研究者提出革命性改進:
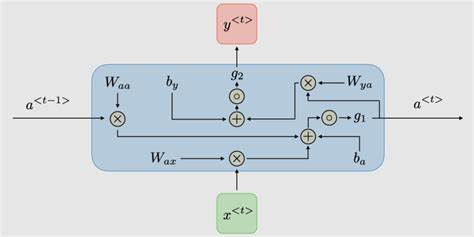
1. LSTM:長短期記憶網絡(記憶的精密控制)
LSTM引入“門控”機制和細胞狀態?C_t,如同一個可精確讀寫擦除的記憶板:
-
遺忘門?
f_t:?決定丟棄哪些舊記憶?C_{t-1}
f_t = σ(W_f * [h_{t-1}, x_t] + b_f) -
輸入門?
i_t:?控制新信息??C_t?的寫入量
i_t = σ(W_i * [h_{t-1}, x_t] + b_i)
?C_t = tanh(W_C * [h_{t-1}, x_t] + b_C) -
細胞狀態更新:?
C_t = f_t ⊙ C_{t-1} + i_t ⊙ ?C_t?→?核心!梯度高速公路 -
輸出門?
o_t:?基于?C_t?生成當前輸出?h_t
o_t = σ(W_o * [h_{t-1}, x_t] + b_o)
h_t = o_t ⊙ tanh(C_t)
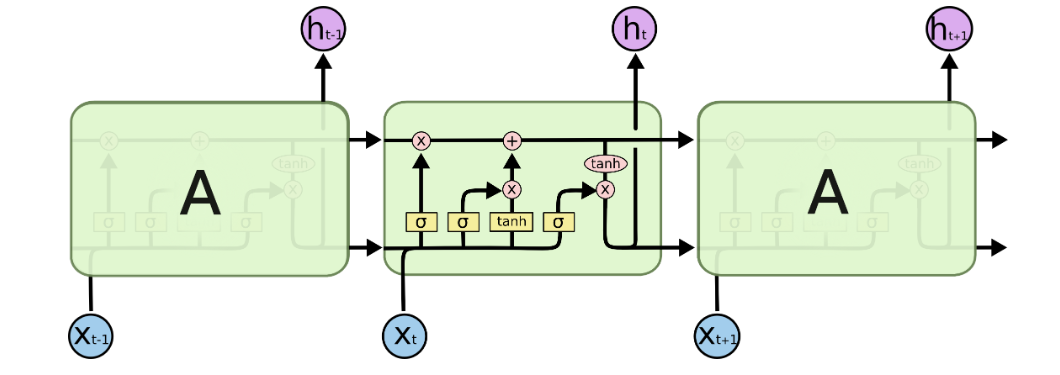
?LSTM通過門控機制保護梯度,解決長程依賴問題
2. GRU:門控循環單元(簡約高效的記憶)
GRU融合LSTM的門控思想,結構更簡潔:
-
重置門?
r_t:?控制歷史記憶?h_{t-1}?對當前新候選狀態的影響
r_t = σ(W_r * [h_{t-1}, x_t]) -
更新門?
z_t:?平衡舊狀態?h_{t-1}?和新候選狀態??h_t
z_t = σ(W_z * [h_{t-1}, x_t]) -
候選狀態:?
?h_t = tanh(W * [r_t ⊙ h_{t-1}, x_t]) -
隱藏狀態更新:?
h_t = (1 - z_t) ⊙ h_{t-1} + z_t ⊙ ?h_t
GRU在效果接近LSTM的同時,參數更少,計算效率更高,成為許多場景的首選。
六、RNN在NLP中的璀璨應用
RNN及其變體推動了NLP的爆發式發展:
-
語言建模:?預測下一個詞的概率?
P(w_t | w_1, w_2, ..., w_{t-1}),是機器翻譯、語音識別的基石。 -
文本生成:?基于歷史詞序列生成連貫文本(詩歌、故事、代碼)。
-
機器翻譯:?經典Seq2Seq架構:編碼器RNN壓縮源語言句義為向量,解碼器RNN據此生成目標語言序列。
-
情感分析:?分析評論/推文的整體情感傾向(正面/負面),需理解上下文語氣。
-
命名實體識別:?序列標注任務,識別文本中人名、地名、組織名(如?
[B-PER, I-PER, O, O, B-LOC])。 -
語音識別:?將聲學特征序列映射為文字序列。
# 使用PyTorch實現一個簡單的GRU情感分類器 import torch import torch.nn as nnclass SentimentGRU(nn.Module):def __init__(self, vocab_size, embed_dim, hidden_dim, output_dim):super().__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)self.gru = nn.GRU(embed_dim, hidden_dim, batch_first=True)self.fc = nn.Linear(hidden_dim, output_dim) # 輸出情感類別def forward(self, text):# text: [batch_size, seq_length]embedded = self.embedding(text) # [batch_size, seq_len, embed_dim]output, hidden = self.gru(embedded)# 取最后一個時間步的隱藏狀態作為句子表示return self.fc(hidden.squeeze(0))
七、總結與展望:RNN的遺產與新篇章
循環神經網絡(RNN)及其變體LSTM、GRU,是序列建模史上的里程碑。它們通過循環結構與隱藏狀態,賦予神經網絡處理序列數據的關鍵能力——記憶,解決了傳統模型處理不定長、依賴關系的難題。
盡管如今Transformer憑借其自注意力機制和強大的并行能力,在諸多NLP任務中(如BERT、GPT)取得更優表現,但RNN的價值并未褪色:
-
歷史地位:?深刻理解RNN是掌握序列建模思想的必經之路。
-
特定場景優勢:?在流式數據處理(實時語音識別)、超長序列(某些時序預測)、資源受限環境(GRU的輕量性)中,RNN及其變體仍有獨特價值。
-
模型融合:?RNN常作為Transformer架構中的組件,如編碼器的補充層。
?
?
?



_列表過濾、列表排序)

)










)


