1.網絡優化存在的難點
(1)結構差異大:沒有通用的優化算法;超參數多
(2)非凸優化問題:參數初始化,逃離局部最優
(3)梯度消失(爆炸)
2.網絡優化方法-梯度下降法
(1)批量梯度下降法(bgd)
使用所有樣本進行更新參數
(2)隨機梯度下降法(sgd)
使用一個樣本更新參數
(3)小批量梯度下降法(mbgd)
利用部分樣本更新參數

3.網絡優化算法 -學習率
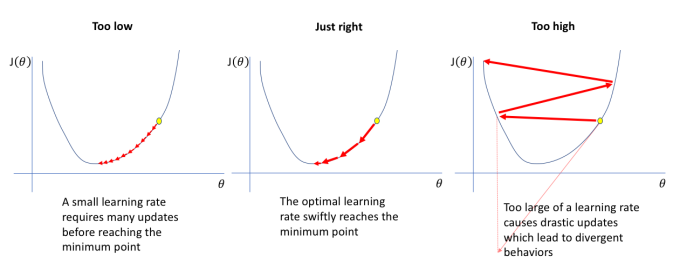
太低導致迭代慢,太高導致迭代遠離局部最優
學習率的改進策略
按迭代次數進行衰減

自適應,根據梯度進行自我調整
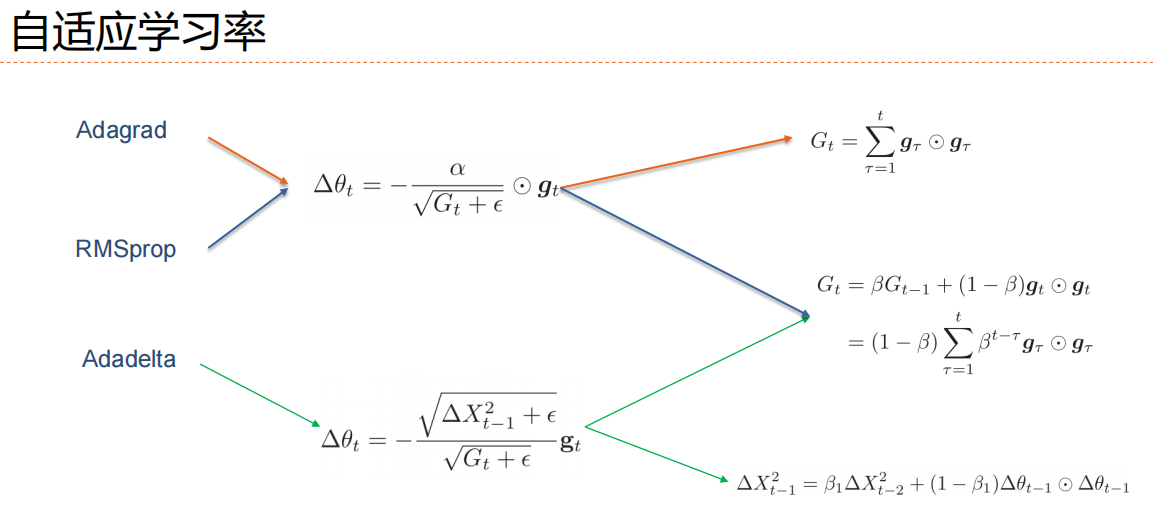
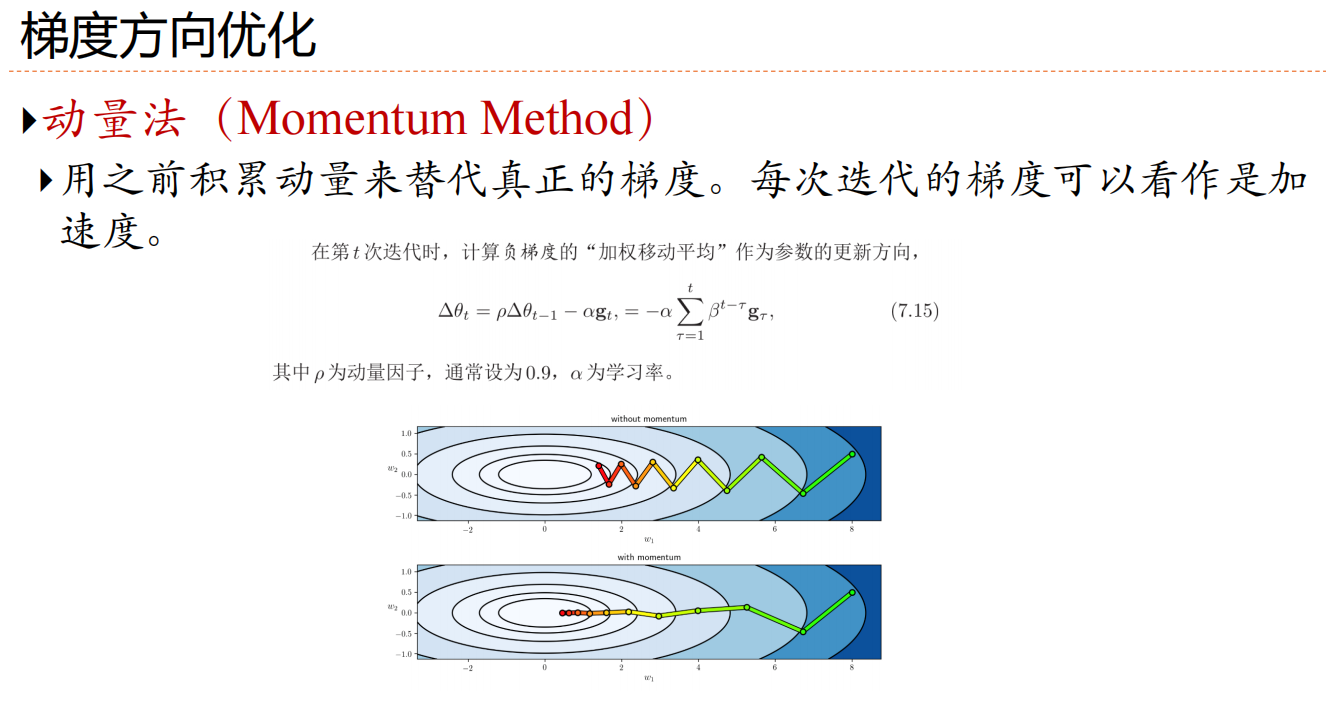
4.網絡優化方法-梯度方向優化
動量法
梯度截斷

5.學習率+梯度優化Adam

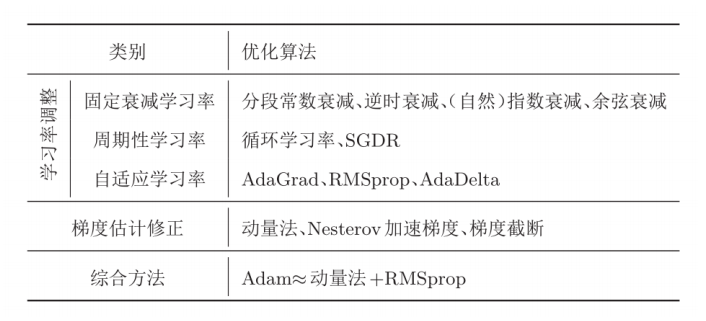
6.參數初始化、數據預處理,逐層歸一化
參數初始化的作用:
- 避免梯度消失 / 爆炸:合理初始化參數(如 Xavier、He 初始化)可維持網絡中梯度的穩定流動,防止因參數值過大或過小導致梯度在反向傳播中消失或爆炸,確保模型能有效學習。
- 加速收斂速度:合適的初始值能讓模型從更優的起點開始迭代,減少訓練過程中陷入局部最優的概率,使模型更快收斂到較優解。
- 保證網絡對稱性破缺:若參數初始化為相同值,網絡各層神經元會學習到相同特征,失去對稱性破缺。隨機初始化可使神經元以不同起點學習,提升網絡表達能力。
- 影響模型泛化能力:不當初始化可能導致模型陷入不良局部最優,而合理初始化能讓模型學習到更具泛化性的特征表示,提升在未知數據上的表現。
數據預處理的作用:
- 提升模型性能:清洗噪聲、處理缺失值等操作可讓數據更 “干凈”,使模型能更好地學習數據中的模式和特征,避免因數據質量問題導致模型訓練效果不佳。
- 保證數據一致性:對數據進行標準化、歸一化等處理,統一數據的尺度和分布,防止不同特征因量綱差異影響模型訓練,確保模型對各特征的學習公平合理。
- 增強數據適用性:通過數據增強(如旋轉、裁剪等)擴充數據集規模和多樣性,減少模型過擬合風險,提升模型在不同場景下的泛化能力。
- 適配模型輸入要求:將原始數據(如圖像、文本等)轉換為模型可接受的格式和維度,例如將圖像 Resize 到固定尺寸、把文本轉換為向量表示,使數據能順利輸入模型進行訓練和推理。
逐層歸一化的作用:
- 緩解內部協變量偏移:通過對每層輸入數據歸一化,穩定數據分布,減少因參數更新導致的分布變化,使模型訓練更穩定。
- 加速訓練收斂:歸一化后的數據分布更易被模型學習,可使用更大學習率,減少梯度震蕩,顯著提升訓練速度。
- 抑制梯度消失 / 爆炸:歸一化維持了梯度傳播的穩定性,避免深層網絡中梯度因數據分布波動而異常,增強網絡訓練可行性。
- 增強模型泛化能力:歸一化過程具有一定正則化效果(如 Batch Norm 的隨機性),可減少過擬合,提升模型對不同輸入的適應性。
- 降低參數初始化敏感性:歸一化后的數據對參數初始值的要求更寬松,無需精細調參即可實現有效訓練。
7.網絡正則化的機理
 ?
?
1.?抑制過擬合
通過約束模型復雜度,避免模型過度擬合訓練數據中的噪聲或局部特征,增強對未知數據的泛化能力。
2.?參數約束與簡化
- L1/L2 正則化:通過在損失函數中添加參數范數懲罰項(如 L1 的絕對值和、L2 的平方和),迫使模型參數趨近于 0(L1 更易產生稀疏解),減少無效特征的影響。
- 權重衰減:類似 L2 正則化,通過限制權重大小,降低模型對輸入微小變化的敏感性。
3.?引入隨機性與噪聲
- Dropout:訓練時隨機丟棄部分神經元,迫使模型學習更魯棒的特征組合,避免依賴特定神經元,類似 “集成學習” 效果。
- 數據增強:通過擴充訓練數據(如旋轉、翻轉圖像),增加輸入多樣性,使模型學習更普適的特征。
4.?約束網絡表示
- Batch Normalization:歸一化層輸入分布,緩解內部協變量偏移,同時因噪聲注入(如批量統計量的隨機性)產生正則化效果。
- 早停(Early Stopping):在驗證集性能未惡化時提前終止訓練,避免模型過度擬合訓練數據的后期迭代。
5.?集成與平滑化
- 標簽平滑(Label Smoothing):將硬標簽(如 one-hot)軟化(如均勻分布),防止模型對某一類別過度自信,增強泛化性。
- 集成學習(如模型平均):結合多個模型的預測結果,降低單一模型的方差,提升穩定性。


)
設計模式)

——第二個小程序(自制shell))





)







