聲音克隆與語音合成的結合,是近年來生成式AI在多模態方向上的重要落地場景之一。隨著預訓練模型能力的增強,結合語音識別、音素映射與TTS合成的端到端系統成為初學者可以上手實踐的全流程方案。
圍繞 GPT-SoVITS-v4-TTS 模塊,介紹了其在整合包中的操作方式和各階段工具使用流程。從前置數據處理、模型訓練到最終的音頻生成,逐步拆解系統內部邏輯與交互方式,為理解該類系統架構提供直觀路徑。
文章目錄
- 操作使用
- 應用示例
- 前置數據集獲取工具
- GPT-SoVITS-TTS
- TTS-for-GPT-soVITS
- 開發與應用
操作使用
進入軟件后在 整合包 里可以直接搜索 GPT-SoVITS-v4-TTS 進入該模塊。
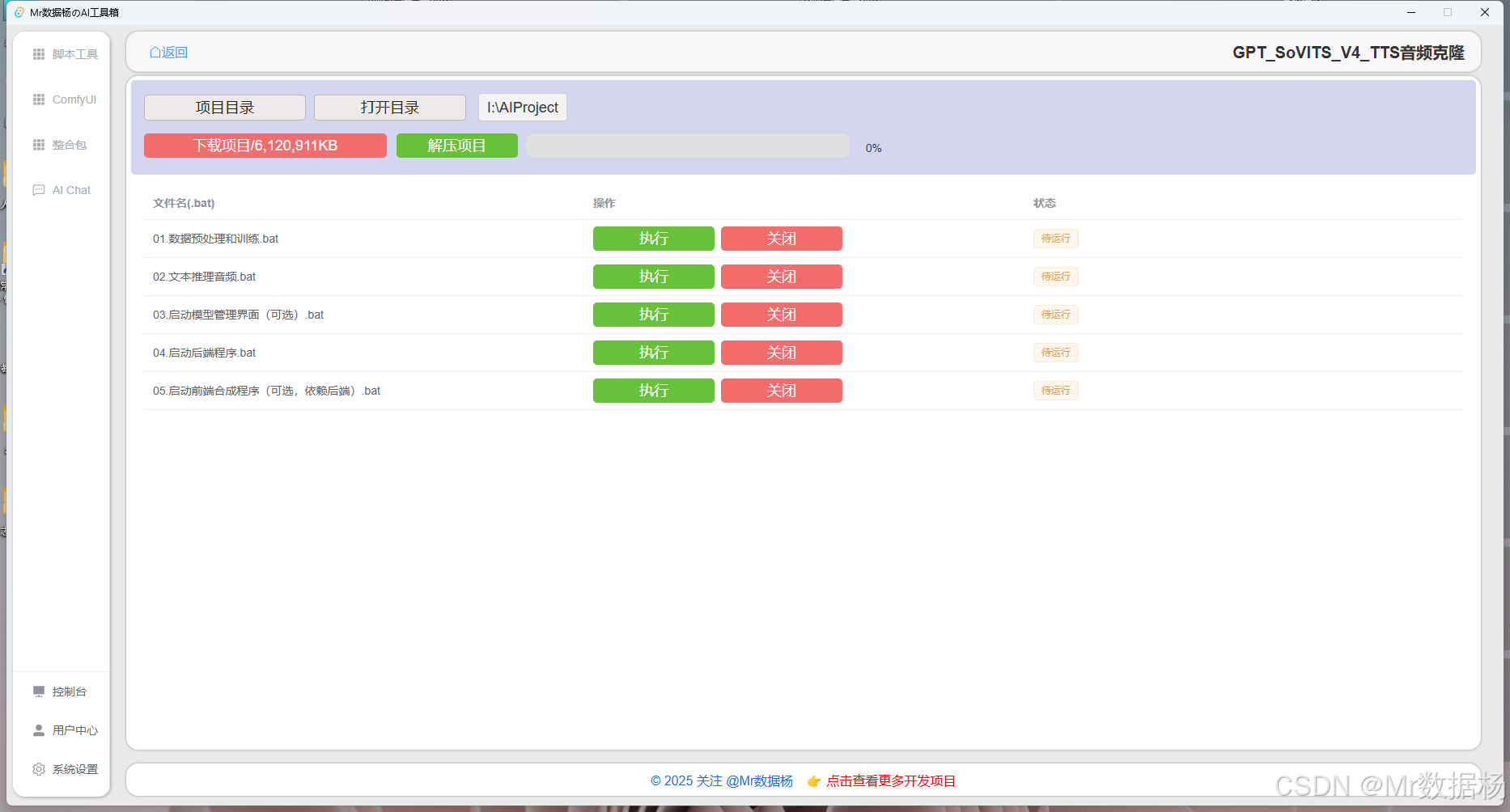
點擊【下載選項卡】可獲取完整項目整合包的下載地址,或直接使用下方鏈接下載。將文件保存至項目目錄下后,點擊解壓按鈕,等待解壓完成即可開始使用。
| - | 說明 |
|---|---|
| 源碼使用教程 | 基于GPT-SoVITS-v4-TTS的音頻文本推理,流式生成 |
| 整合包下載地址 | 基于GPT-SoVITS-v4-TTS的聲音克隆項目整合包 |
項目腳本配置
這些腳本通過 Gradio 提供可視化界面,分別對應 GPT-SoVITS 項目從數據準備、預處理、訓練到推理的各個階段。使用者只需按需點擊對應的 .bat 文件,即可啟動相關功能模塊,無需手動輸入復雜命令,適合初學者快速上手和部署測試。
| 腳本名稱 | 功能說明 |
|---|---|
| 01.獲取和處理訓練數據.bat | 啟動數據預處理模塊,包括語音采樣整理、標注轉換等 |
| 02.文字轉音素預處理.bat | 啟動文本轉音素工具,用于生成訓練所需的音素數據 |
| 03.啟動預訓練管理器(可選).bat | 啟動預訓練參數管理界面,可查看或加載預訓練模型(非必選) |
| 04.啟動訓練任務.bat | 啟動訓練控制臺,執行模型訓練流程 |
| 05.啟動推理功能模塊(TTS、克隆音頻).bat | 啟動推理服務,提供基于 Gradio 的 TTS 與音頻克隆在線體驗界面 |
應用示例
前置數據集獲取工具
在正式開始音頻克隆前,需要先準備一系列工具來獲取和處理數據。
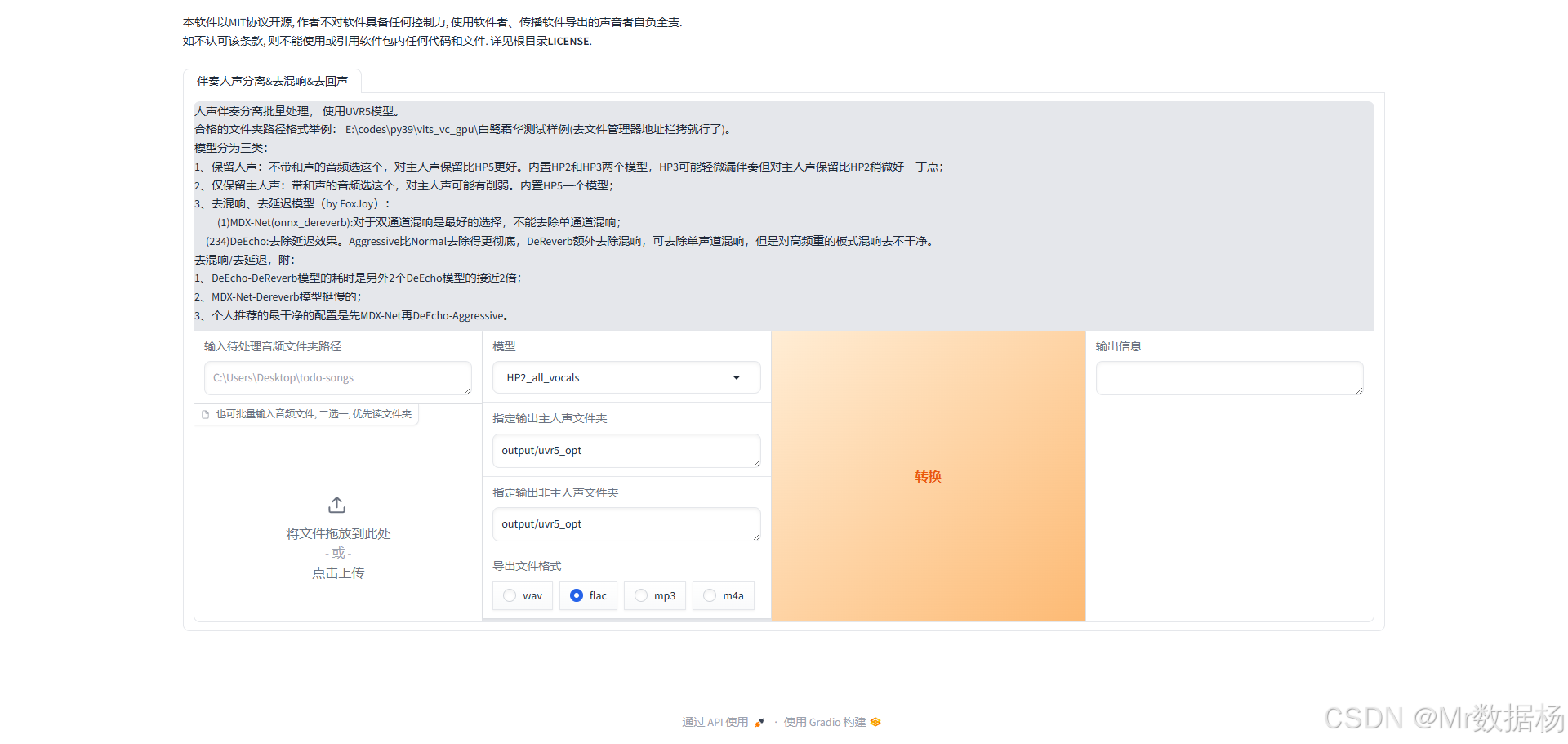
原生和背景分離 UVR5
使用UVR5工具對音頻進行人聲和背景音樂分離,確保后續處理的音頻質量。操作界面非常直觀,初學者只需導入原始音頻文件,選擇對應模型,點擊開始即可分離出干凈的人聲文件。
語音切分工具
將分離后的人聲音頻進一步切分為適合處理的小段。
將分離后的人聲音頻進一步切分為適合處理的小段。輸入路徑選擇UVR5處理后的音頻文件夾,輸出路徑按照角色建立子文件夾,例如:output/角色名/slicer_opt。
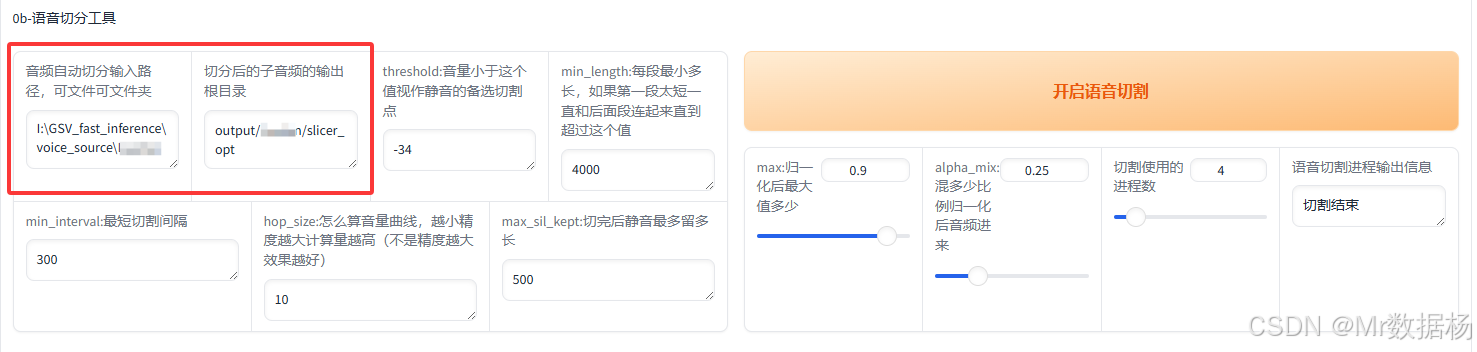
切分工具會自動按語音停頓和靜默間隔切分,降低后續處理難度。
語音降噪工具
切分后的語音片段可能存在背景噪聲,降噪工具可有效提升音質。輸入路徑為切分后的文件夾路徑(如output/角色名/slicer_opt),輸出路徑建議新建子文件夾(如output/角色名/denoise_opt)。

降噪完成后,語音文件清晰度和質量顯著提高,便于后續ASR語音識別。
中文批量離線ASR工具
通過中文批量ASR工具自動識別音頻對應的文本內容。輸入路徑選擇降噪后的音頻文件夾(如output/角色名/denoise_opt),輸出路徑指定為新子文件夾(如output/角色名/asr_opt)。
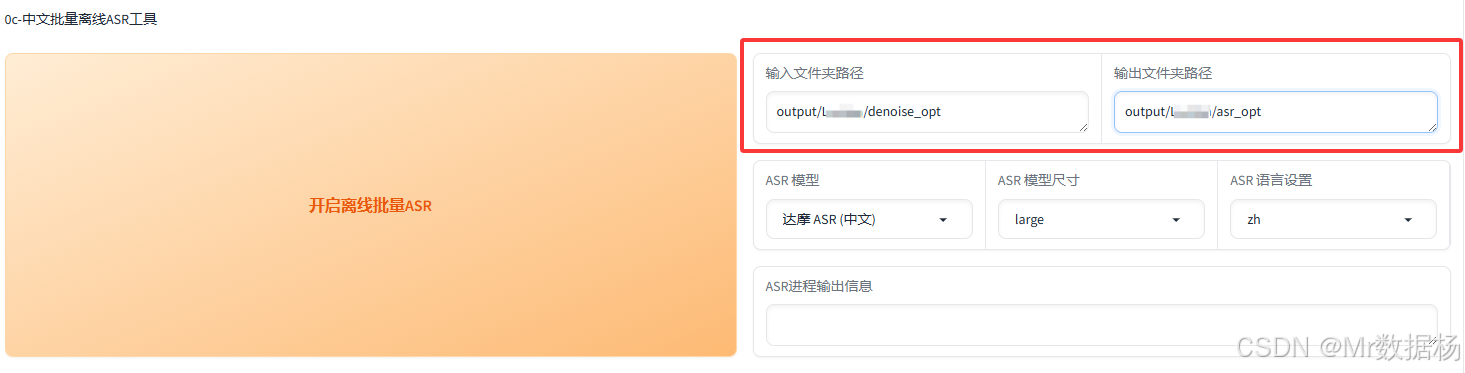
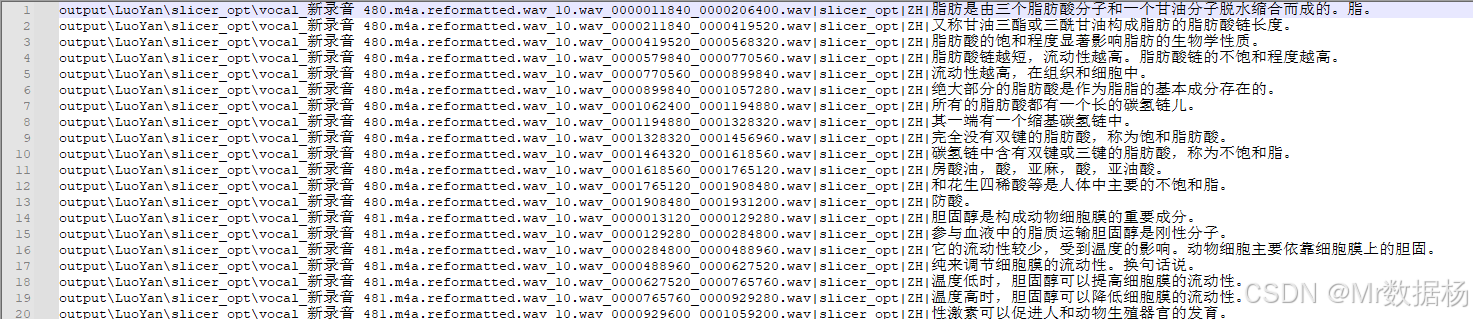
工具會自動生成音頻片段對應的文本識別結果,并生成一個slicer_opt.list文件,便于后續文本校對。
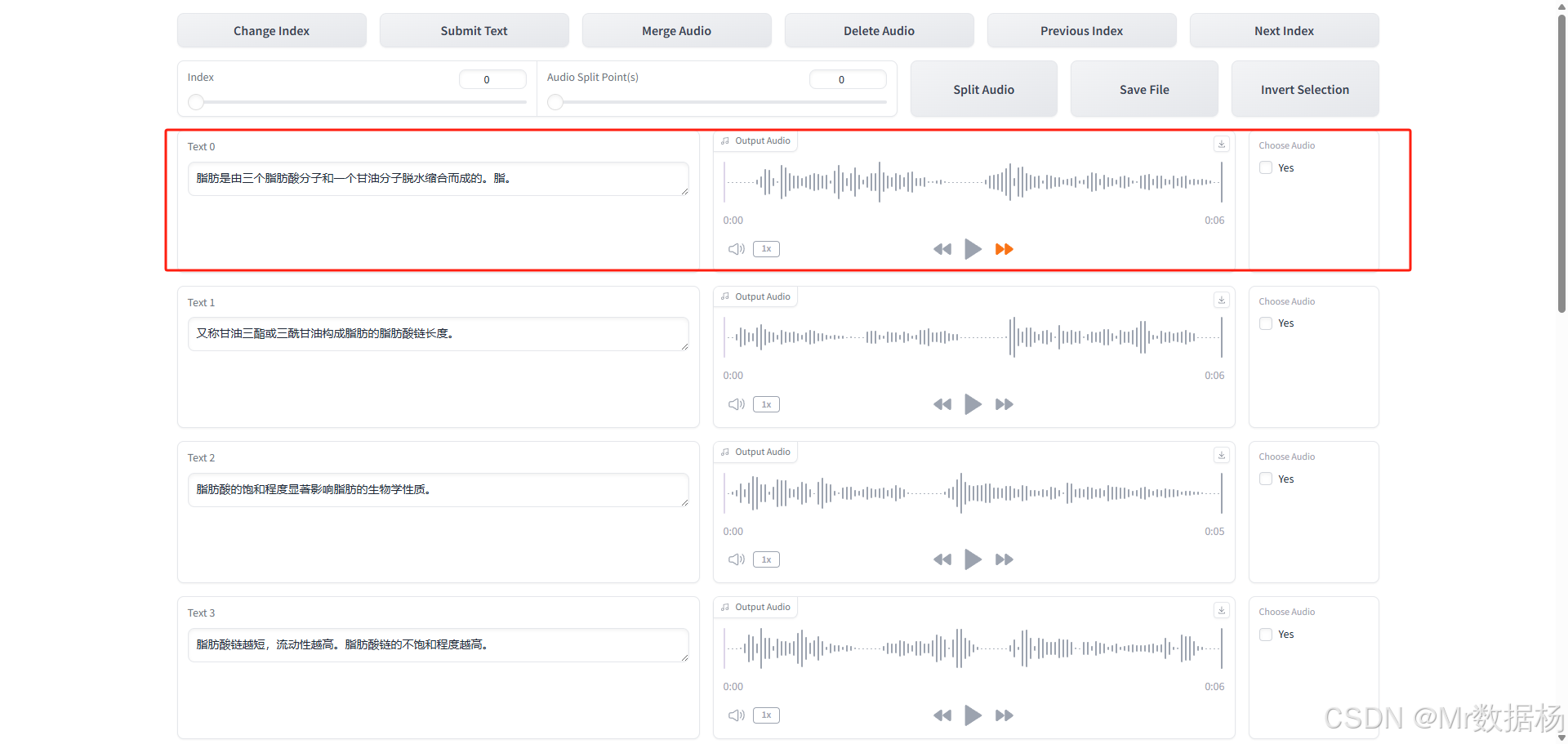
語音文本校對標注工具
ASR識別結果可能存在錯誤,若對精度要求較高,則可手動使用該工具進行逐條文本校對和修正,提升克隆語音的準確性。
GPT-SoVITS-TTS
完成數據準備后,進入模型訓練和語音合成階段。
項目設置
在GPT-SoVITS工具界面設置模型訓練項目的名稱,便于后續區分和管理。

選擇前面已經ASR識別并校對好的文本標記文件,作為訓練數據的基礎。

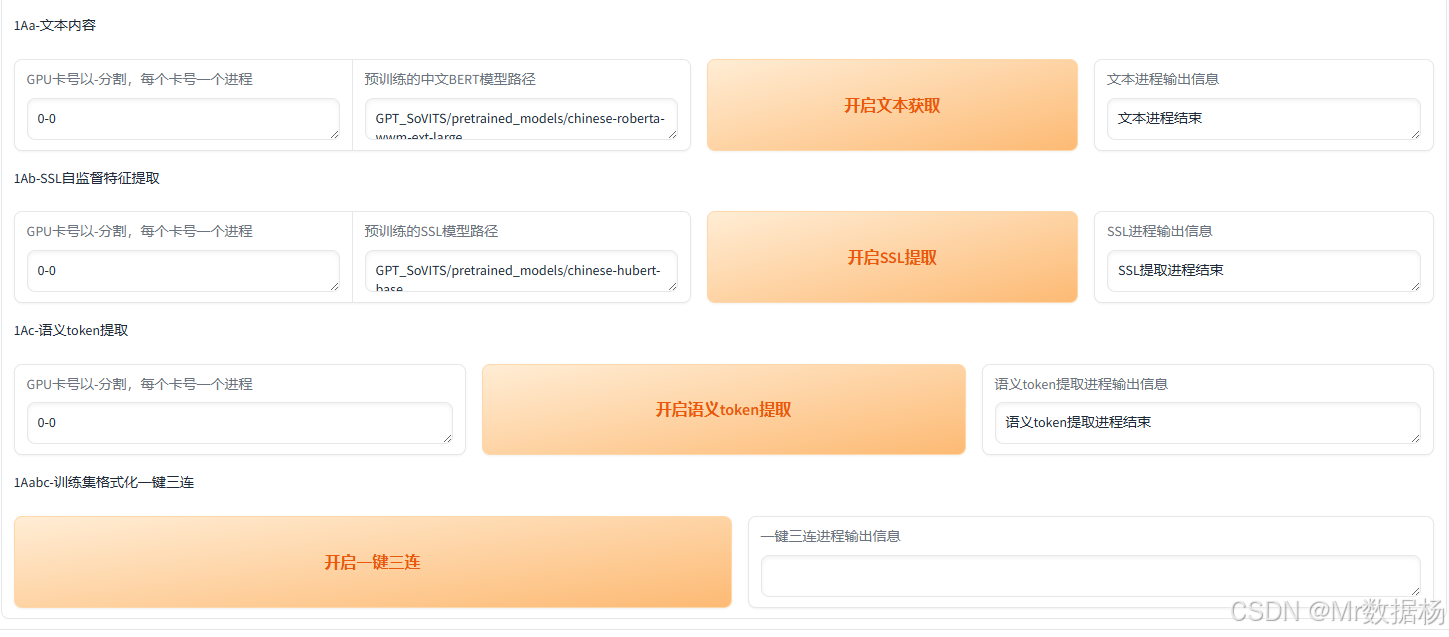
數據格式化
在項目設置完成后,依次執行數據格式化操作,可以直接使用工具中的“一鍵三連”功能快速完成,包括數據的預處理、格式檢查和必要的文件生成。該過程通常比較穩定,不易出現問題。
微調訓練
啟動SoVITS模型訓練,過程中實時觀察訓練日志。訓練完成后,模型文件會自動存放在GPT_weights目錄下,后續用于生成音頻。
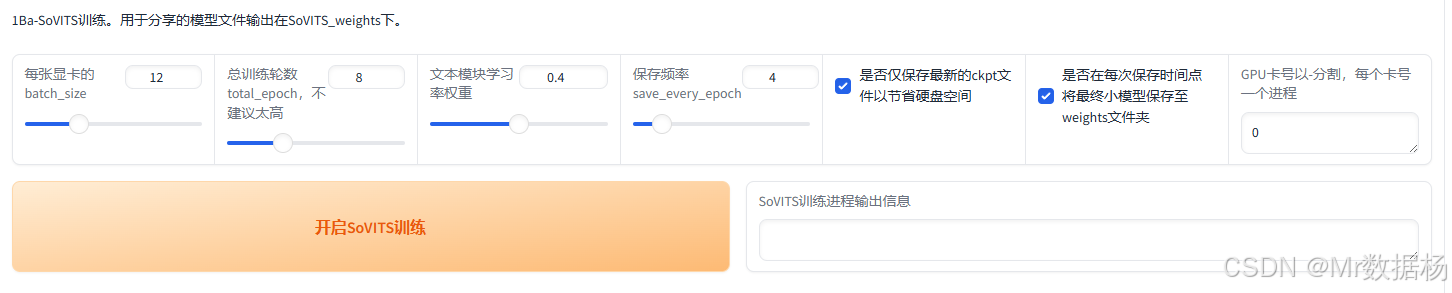
啟動GPT模型訓練,同樣實時觀察訓練進度。訓練成功后,生成的GPT模型文件也會位于GPT_weights目錄。

這兩個步驟的完成對最終克隆效果非常關鍵,確保兩者訓練充分后再進行推理測試。
TTS-for-GPT-soVITS
模型管理
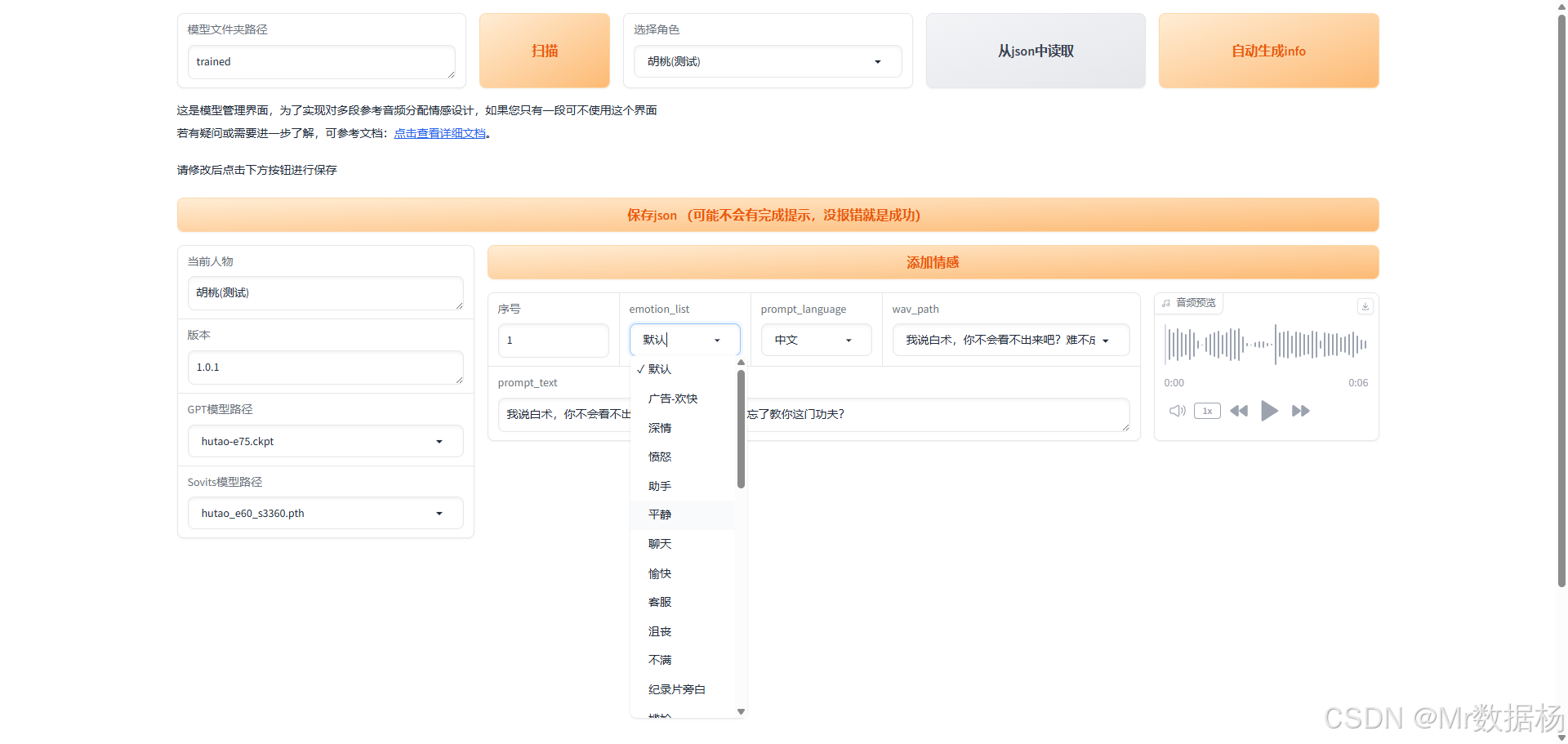
在TTS-for-GPT-soVITS目錄中運行啟動模型管理界面.bat文件,進入界面后點擊"掃描"按鈕,系統將顯示當前用于生成音頻的模型及其相關配置信息。
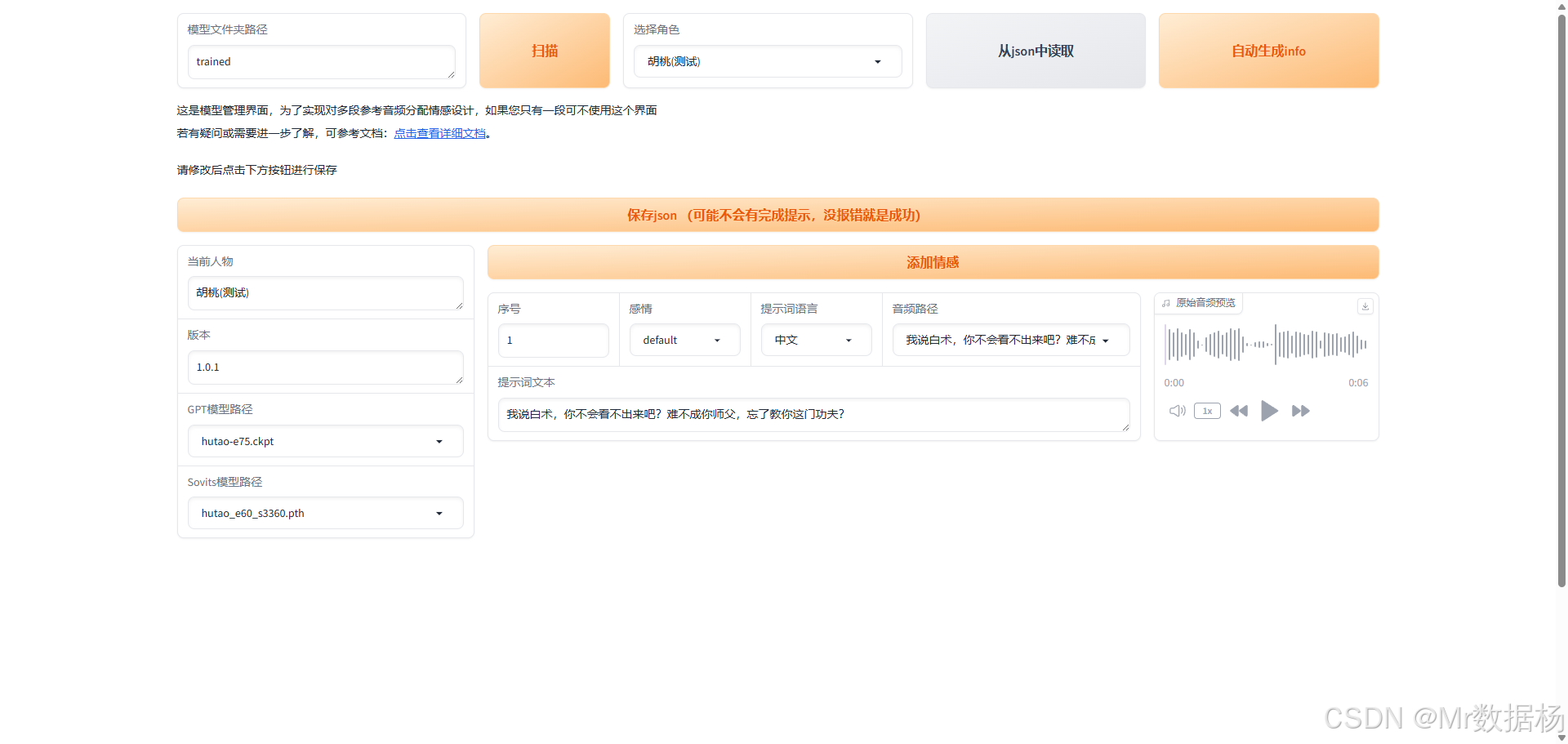
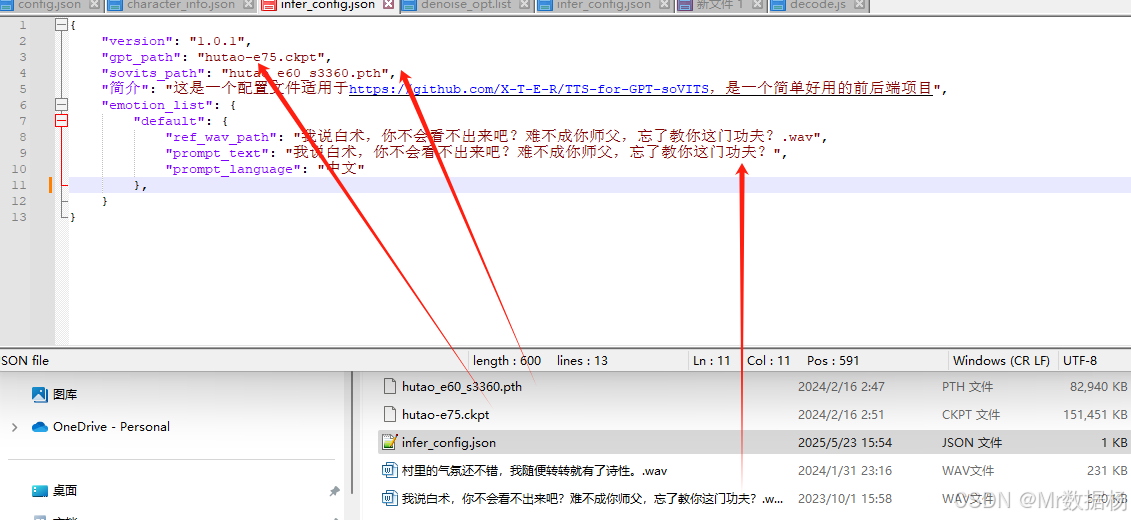
項目的角色配置文件位于根目錄下的 trained/character_info.json,您可以在其中添加下拉菜單的角色名稱選項,其中 default 字段用于指定默認選中的模型。
{"deflaut_character": "胡桃(測試)","characters_and_emotions": {"胡桃(測試)": ["default"],"xxxxx": ["default"],}
}
需要確保 key 值與當前目錄下的文件夾名稱完全匹配。
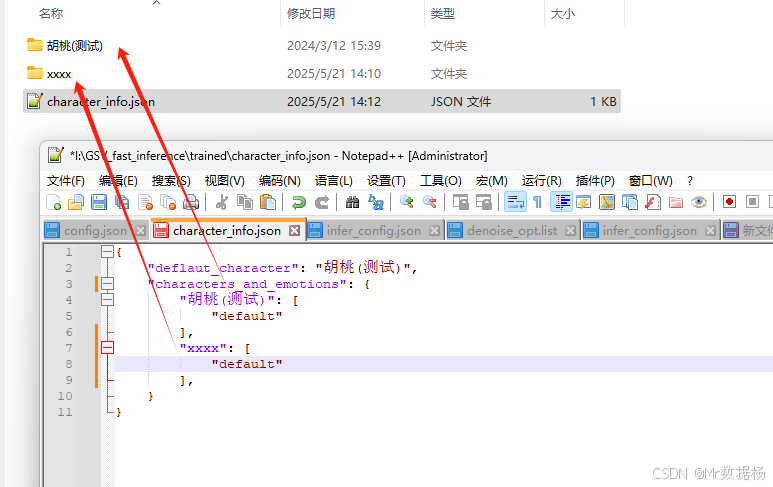
請將 GPT_weights 和 SoVITS_weights 的模型文件加載至此處。
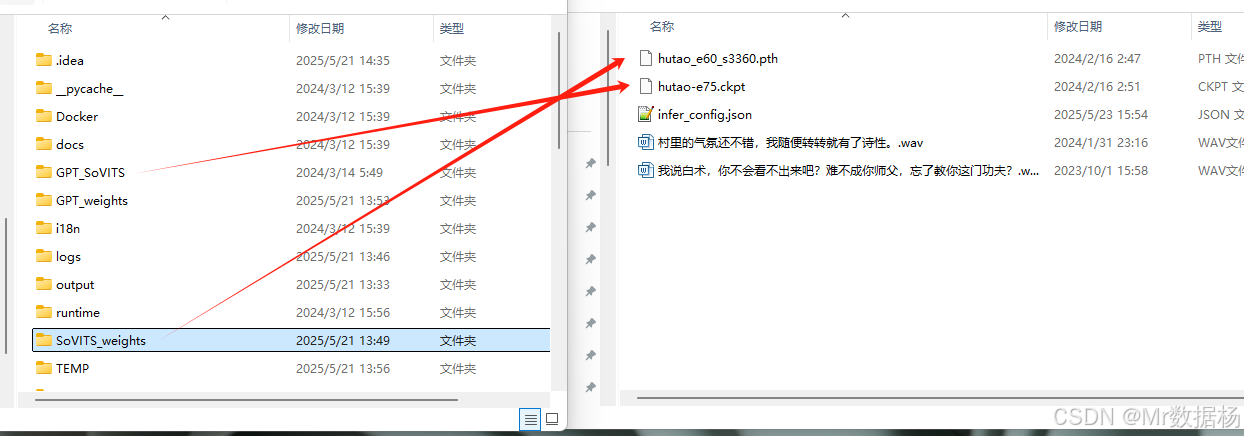
復制兩份切片樣本音頻文件至當前目錄,以音頻文字內容作為文件名。隨后打開 infer_config.json 文件,參照示例配置模型參數及樣本文件路徑。
您還可以通過WebUI界面進行操作,只需確保模型和信息保持一致即可。
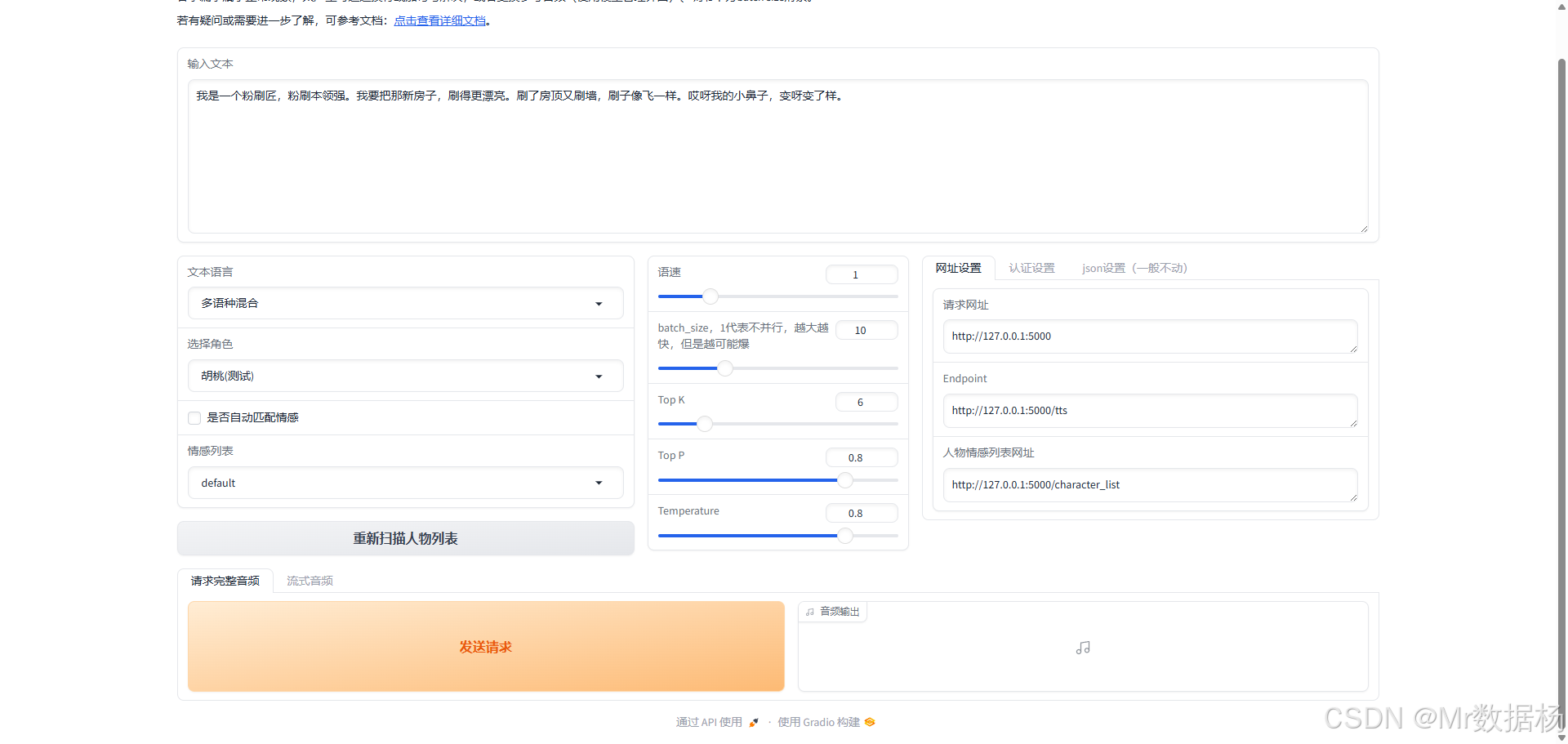
啟動后端服務
成功啟動后,系統將顯示接口地址提示信息。請保持當前啟動窗口處于開啟狀態。
ver instead.* Running on all addresses (0.0.0.0)* Running on http://127.0.0.1:5000* Running on http://172.19.0.1:5000
INFO:werkzeug:Press CTRL+C to quit
啟動前端合成程序
系統啟動后,用戶可立即進行音頻合成操作,該功能同時支持流式處理和文件合成兩種模式。
開發與應用
軟件使用以及綜合參考資料內容可以查閱
| 文章鏈接 | 內容描述 |
|---|---|
| AIGC工具平臺Tauri+Django環境開發,支持局域網使用 | 圖形桌面工具使用教程,詳細介紹 Tauri+Django 環境的開發方法,支持局域網部署與使用。 |
| AIGC工具平臺Tauri+Django常見錯誤與解決辦法 | 常見錯誤與解決辦法,針對 Tauri+Django 環境下可能遇到的問題提供實用的解決方案。 |
| AIGC工具平臺Tauri+Django內容生產介紹和使用 | 包含當前主流新媒體領域常用的音頻、視頻剪輯,以及內容一鍵生產功能。 |
| AIGC工具平臺Tauri+Django開源ComfyUI項目介紹和使用 | 工作流相關內容講解,涵蓋文件管理、文件匯總、軟件使用教程及開發指導,附帶模型下載資源。 |
| AIGC工具平臺Tauri+Django開源git項目介紹和使用 | 開源git項目內容講解,涵蓋項目整合包、算法模型、測試指導、項目應用,附帶項目整合包下載。 |
View 處理Input事件pipeline)

 拆機刷入Armbian固件)







)



![[JVM] JVM內存調優](http://pic.xiahunao.cn/[JVM] JVM內存調優)
:Netty基本開發與改進【心跳、粘包與拆包、閑置連接】)



