參考https://zhuanlan.zhihu.com/p/569527564?
Attention Is All You Need?(Transformer) 是當今深度學習初學者必讀的一篇論文。
一.?Attention Is All You Need (Transformer) 論文精讀
1. 知識準備
機器翻譯,就是將某種語言的一段文字翻譯成另一段文字。
由于翻譯沒有唯一的正確答案,用準確率來衡量一個機器翻譯算法并不合適,因此,機器翻譯的數據集通常會為每一條輸入準備若干個參考輸出。統計算法輸出和參考輸出之間的重復程度,就能評價算法輸出的好壞了。這種評價指標叫做BLEU Score。這一指標越高越好。
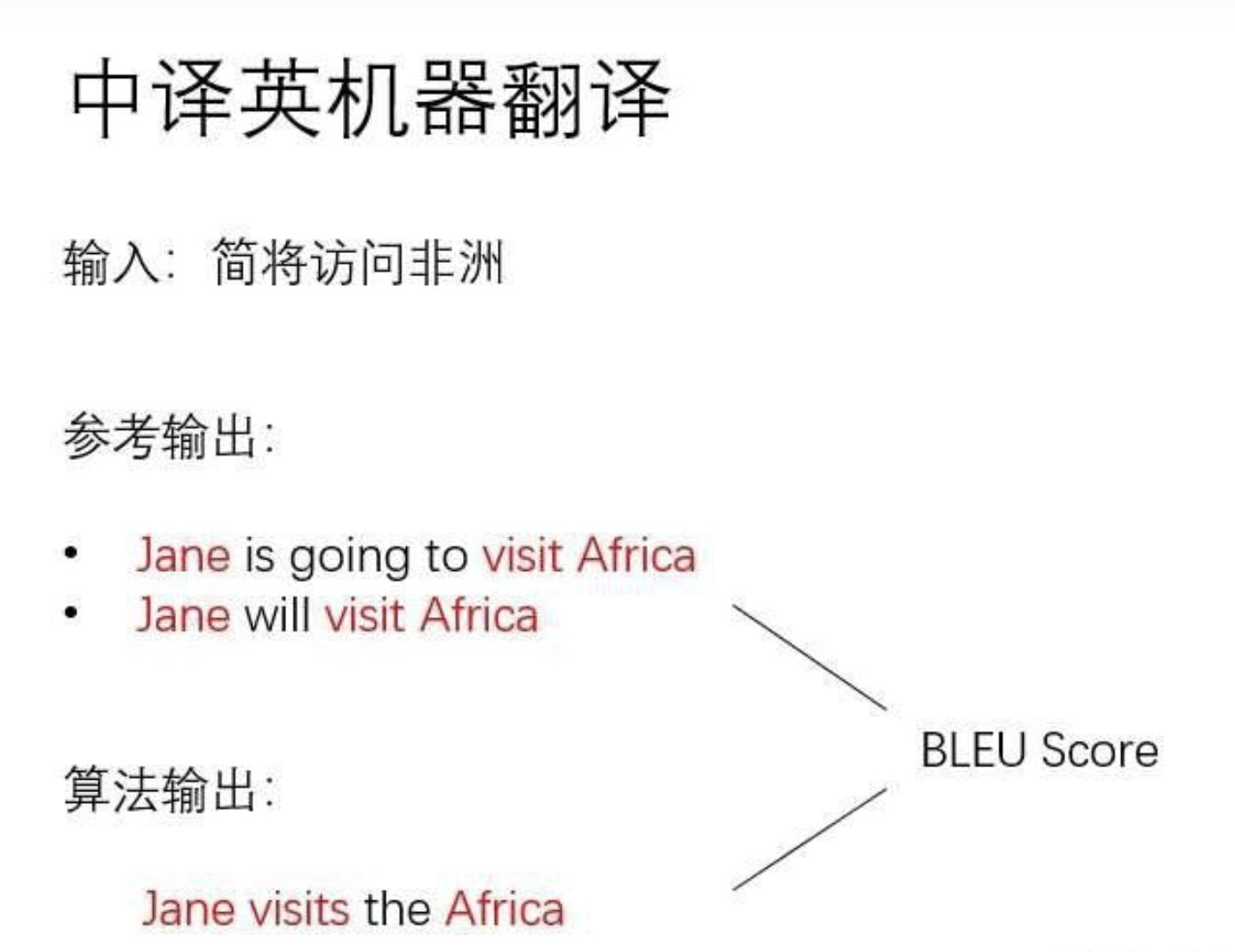
在深度學習時代早期,人們使用RNN(循環神經網絡) 來處理機器翻譯任務。一段輸入先是會被預處理成一個token序列。RNN會對每個token逐一做計算,并維護一個表示整段文字整體信息的狀態。根據當前時刻的狀態,RNN可以輸出當前時刻的一個token。
所謂token,既可以是一個單詞、一個漢字,也可能是一個表示空白字符、未知字符、句首字符的特殊字符。
具體來說,在第t輪計算中,輸入時上一輪的狀態? ?以及這一輪的輸入token
,輸出這一輪的狀態
以及這一輪的輸出token ?
。
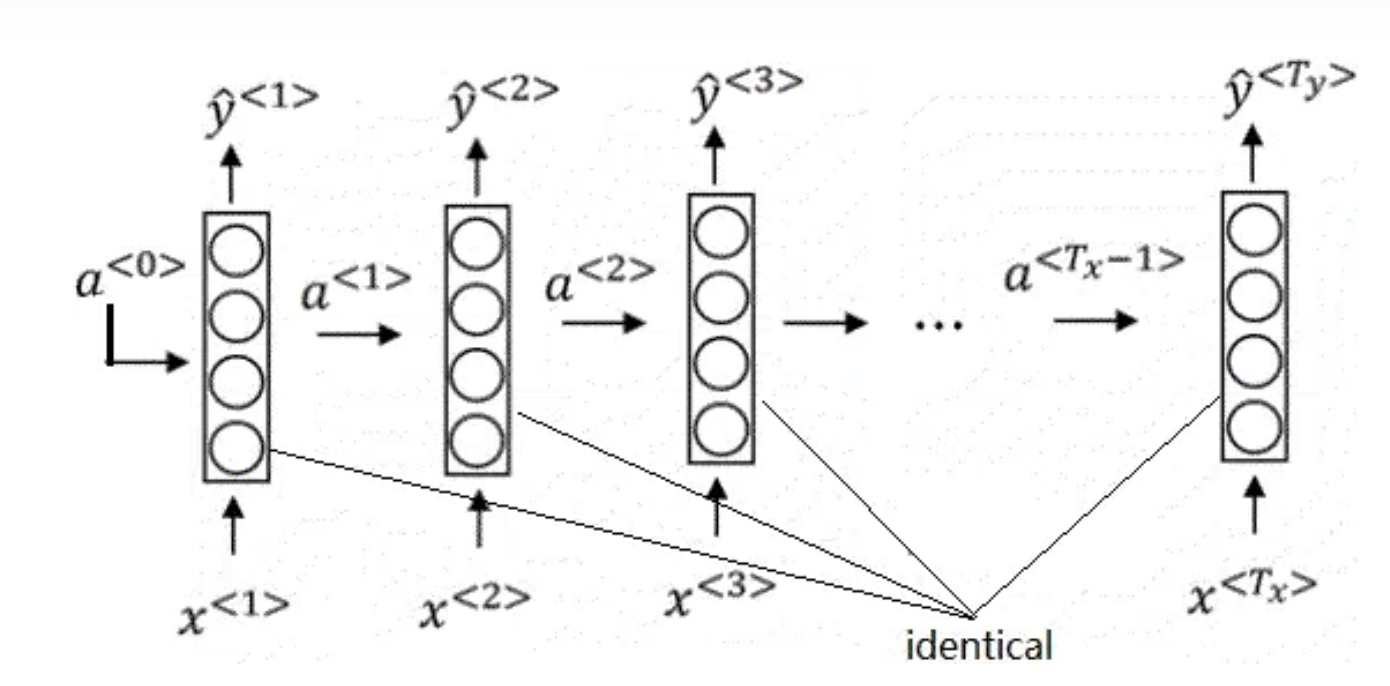
這種簡單的RNN架構僅適用于輸入和輸出等長的任務。然而,大多數情況下,機器翻譯的輸出和輸入都不是等長的。因此,人們使用了一種新的架構。前半部分的RNN只有輸入,后半部分的RNN只有輸出(上一輪的輸出會當作下一輪輸入以補充信息)。兩個部分通過一個狀態?來傳遞信息。把該狀態看成輸入信息的一種編碼的話,前半部分可以叫做“編碼器”,后半部分可以叫做“解碼器”。這種架構因而被稱為“編碼器-解碼器”架構。
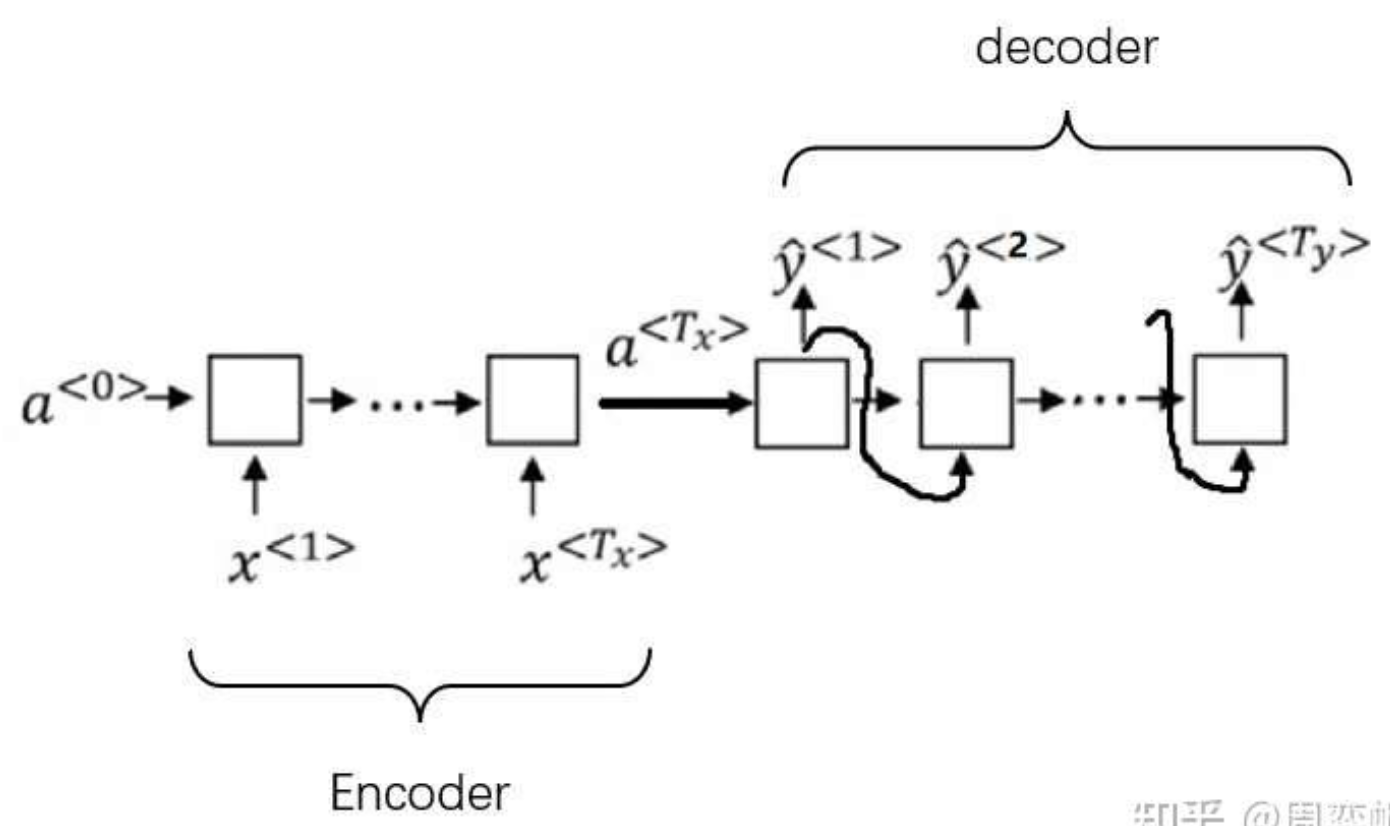
這種架構存在著不足:編碼器和解碼器之間只通過一個隱狀態來傳遞信息。在處理較長文章時,這種架構的表現不夠理想。為此,有人提出了基于注意力的架構。這種架構依然使用了編碼器和解碼器,只不過解碼器的輸入時編碼器的狀態的加權和,而不再是一個簡單的中間狀態。每一個輸出對每一個輸入的權重叫做注意力,注意力的大小取決于輸出和輸入的相關關系。這種架構優化了編碼器和解碼器之間的信息交流方式,在處理長文章更加有效。
盡管注意力模型的表現已經足夠優秀,但所有基于RNN的模型都面臨同樣的問題:RNN本輪的狀態的輸入狀態取決于上一輪的輸出狀態,這使RNN的計算必須串行執行。因此,RNN的訓練通常比較緩慢。
在這背景下,拋棄RNN, 只使用注意力機制的Transformer橫空出世了。
2.摘要與引言
摘要傳遞的信息非常簡練:
- 當前最好的架構師基于注意力的“encoder- decoder”架構。這些架構都使用了CNN和RNN。這篇文章提出的transformer架構僅使用了注意力機制,而無需使用CNN和RNN
- 兩項機器翻譯的實驗表明,這種架構不僅精度高,而且訓練時間大幅度縮短。
引言讀一段回顧了RNN架構。以LSTM和GRU為代表的RNN在多項序列任務中取得頂尖的成果。許多研究仍在拓寬循環語言模型和“encoder- decoder”架構的能力邊界。
第二段就開始講RNN的不足了。RNN要維護一個隱狀態,該隱狀態取決于上一時刻的隱狀態。這中內在串行計算特質阻礙了訓練時的并行計算(特別是訓練序列較長時,每一個句子占用的存儲更多,batch size變小,并行度降低)。有許多研究都在嘗試解決這一問題。但是串行計算的本質是無法改變的。
上一段暗示了Transformer 的第一個設計動機:提升訓練的并行度。第三段講了“Transformer”的另一個設計動機:注意力機制。注意力機制是當時最頂尖的模型中不可或缺的組件。這一機制可以讓每對輸入輸出關聯起來,而不用像那么早使用一個隱狀態傳遞信息的“encoder- decoder”模型一樣,收到序列距離的限制。然而,幾乎所有的注意力機制都用在RNN上的。
既然注意力機制能夠無視序列的先后順序,捕捉序列間的關系,為什么不只用這種機制來構造一個適用一個適用于并行計算的模型呢?因此,在這篇文章中作者提出了Transformer架構。這一架構規避了RNN的使用,完全使用注意力機制來捕捉輸入輸出序列之間的依賴關系。這種架構不僅訓練得更快了,表現還更強了。
通過摘要和引言,我們基本理解了Transformer架構的設計動機。作者想克服RNN不能并行的缺點,又想充分利用沒有串行限制的注意力機制,于是就提出了一個只有注意力機制的模型。模型訓練出來了,結果出乎預料地好,不僅訓練速度大幅加快,模型的表現也吵夠了當時所有的其他模型。
3.注意力機制
文章在介紹Transformer的架構時,時自頂向下介紹的。但是,一開始我們并不了解Transformer的各個模塊,理解整體框架時會有不少的阻礙。因此,我們可以自底向上地來學習Transformer架構。
4.注意力計算的一個例子
其實,“注意力”這個名字取的非常不易于理解。這個機制應該叫做“全局信息查詢”。這一次“注意力”計算,其實就跟去數據庫做了一次查詢一樣。假設,我們現在有這樣一個以人名為Key(鍵),以年齡為Value(值)的數據庫:
{張三: 18,張三: 20,李四: 22,張偉: 19 }
現在有一個query(查詢),問所有叫張三的人的年齡平均值是多少。讓我們寫程序的話,我們會把字符串“張三”和所有Key做比較,找出所有張三的value,把這些年齡值相加,取一個平均數。這個平均數是(18+20)/2 =19。
但是,很多時候,我們的查詢并不是那么明確。比如,我們可能想查詢一下所有姓張的人的年齡平均值。這次,我們不是去比較key=張三,而是比較key[0]?==張。這個平均數應該是(18+20+19)/3=19。
或許,我們查詢會更模糊一點,模糊到無法用簡單的判斷語句來完成,因此,最通用的方法是,把query和key各建模成一個向量。之后,對query和key之間算一個相似度(比如向量內積),以這個相似度為權重,算value的加權和。這樣,不管多么抽象的查詢,我們都可以把query和key建模成向量,用向量相似度代替查詢的判斷語句,用加權和代替直接取值再求平均值。“注意力”,其實指的就是這里的權重。
把這種新方法套入剛才那個例子里,我們先把所有key建模成向量,可能可以得到這樣的一個新數據庫:
{[1, 2, 0]: 18, # 張三[1, 2, 0]: 20, # 張三 [0, 0, 2]: 22, # 李四[1, 4, 0]: 19 # 張偉 }
假設key[0]==1表示姓張。我們的查詢“所有姓張的人的年齡平均值”就可以表示成向量【1,0,0】。用這個query和所有key算出的權重是:
dot([1, 0, 0], [1, 2, 0]) = 1
dot([1, 0, 0], [1, 2, 0]) = 1
dot([1, 0, 0], [0, 0, 2]) = 0
dot([1, 0, 0], [1, 4, 0]) = 1之后,我們該用這些權重算平均值了。注意,算平均值時,權重的和應該是1,因此,我們可以用soft Max把這些權重歸一化一下,再算value的加權和。
softmax([1, 1, 0, 1]) = [1/3, 1/3, 0, 1/3]
dot([1/3, 1/3, 0, 1/3], [18, 20, 22, 19]) = 19?這樣,我們就用向量運算代替了判斷語句,完成了數據庫的全局信息查詢。那三個1/3就是query對每個key的注意力。
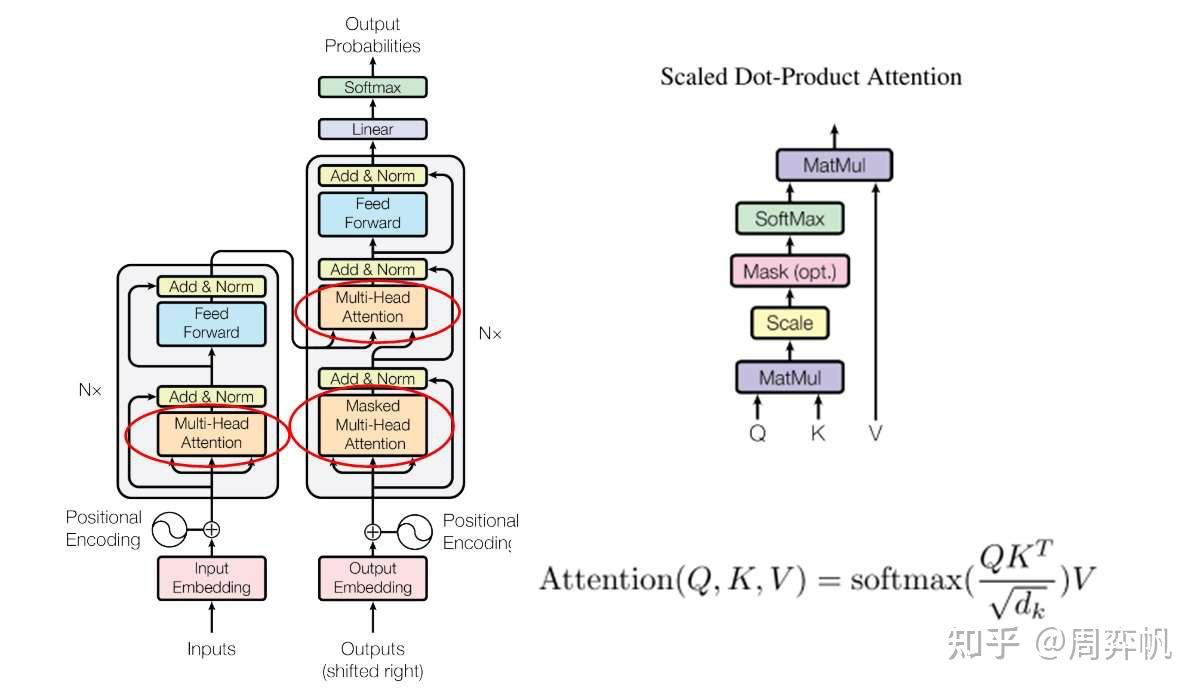
5. Scaled Dot-Product Attention
我們剛剛完成的計算差不多就是Transformer里的注意力,這種計算在論文里叫放縮點乘注意力(Scaled Dot-Product Attention)。它的公式是:
我們先來看看Q,K,V在剛剛那個例子里究竟是什么,K比較好理解,K就是key向量的數組,也就是
K = [[1, 2, 0], [1, 2, 0], [0, 0, 2], [1, 4, 0]]同樣,V就是value向量的數組。而在我們剛剛那個例子里,value都是實數。實數其實也就是可以看成長度為1的向量。因此,那個例子的V應該是:
V = [[18], [20], [22], [19]]
在我們剛剛的例子里,我們只多了一次查詢。因此,準確來說,我們的操作應該寫成:
?
其中,query q就是【1,0,0】
實際上,我們可以一次做多組query。把所有q打包成矩陣Q,就得到了公式:
就是query和key向量的長度。由于query和key要做點乘,這兩種向量的長度必須一致。value向量的長度倒是可以不一致,論文里把value向量的長度叫做
。在我們這個例子里,
=1,
=3
為什么要用一個和成比例的項來縮放
呢?softmax 在絕對值較大的區域梯度較小,梯度下降的速度比較慢,因此,我們要讓softmax的點乘數值盡可能小。而一般在
較大時,也就是向量較長時,點乘數值會比較大。除以一個和
相關的量能夠防止點乘的值過大。
剛才也提到,其實是在算query和key相似度,而算相似度并不只有求點乘這一種方式。另一種常用的注意力函數叫做加性注意力,它用一個單層神經網絡來計算兩個向量的相似度。相比之下,點乘注意力算起來快一些。出于性能上的考量,論文使用了點乘注意力。
6.自注意力
自注意力是3.2.3節里提及的內容。我認為,學完注意力的原理后,立刻去學自注意力能夠更快地理解注意力機制。當然,論文里并沒有對自注意力進行過多的引入,初學者學起來會非常困難。因此,這里我參考《深度學習專項》里的介紹方式,用一個更具體的例子介紹了自注意力。
大致明白了注意力機制其實就是“全局信息查詢”,并掌握了注意力的公式后,我們來以Transformer的自注意力為例,進一步理解注意力的意義。
自注意力模塊目的是為了每一個輸入token生成一個向量表示,該表示不僅能反應token本身的性質,還能反應token在局子里特有的性質。比如翻譯“簡訪問非洲”這句話時,第三個字“問”在中文里很多個意思,比如詢問、慰問等。我們想為它生成一個表示,知道它在句子中的具體意思。而在例句中,“問”字組詞組成了“訪問”,所以它應該取“詢問”這個意思,而不是“慰問”。“詢問”就是“問”字在這句話里的表示。
讓我們看看自注意力模塊具體時怎么生成這種表示的。自注意力的輸入是3個矩陣Q,K,V。準確來說,這些矩陣是向量的數組,也就是每一個token的query,key, value向量構成的數組。自注意力模塊會為每一個token輸出一個向量表示A。是第t個token在這句話里向量表示。
讓我們還是以剛剛那個句子“簡訪問非洲”為例,看一下自注意力怎么計算的。現在,我們想計算。
表示的是“問”字在句子里的確切含義。為了獲取
,我們可以問這樣一個可以用數學表達的問題:“和‘問’字組詞的字的詞嵌入式什么?”。這個問題就是第三個token的query向量
。
和“問”字組詞的字,很肯能是一個動詞。恰好,每一個token的key?就表示這個token的詞性;每一個token的value?
,就是這個token的嵌入。

這樣,我們就可以根據每個字的詞性(key),盡量去找動詞(和query比較相似的key),求出權重(query和key做點乘再做softmax),對所有value求一個加權平均,就差不多能回答問題了。
經計算,,
可能會比較相關,即這兩個向量的內積比較大。因此,最終算出來的
約等于
,即問題“哪個字和‘問‘ 字組詞了?的答案是第二個訪字。
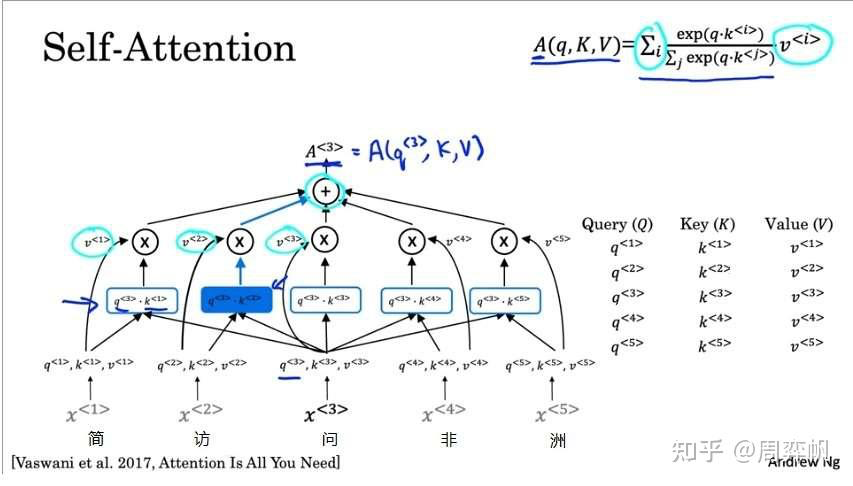
這是?的計算過程。準確來說,
.類似地,
到
都是用這個公式來計算。把所有A的計算合起來,把q合起來,得到的公式就是注意力的公式。
從上一節中,我們知道了注意力其實就是全局信息查詢,而在這一節,我們知道了注意力的一種應用:通過讓一句話中每個單詞去向其他單詞查詢信息,我們能為每一個單詞生成一個更有意義的向量表示。
可是,我們還留了一個問題沒解決:每個單詞的query,key, value 是怎么得來的?這就要看transformer里的另一種機制---多頭注意力。
7. 多頭注意力
在自注意力中,每一個單詞的query,key, value應該只和該單詞本身有關。因此,這三個向量都應該由單詞的詞嵌入得到。另外,每個單詞的query,key, value不應該是人工指定的,而應該是可學習的。因此,我們可以用可學習的參數來描述從詞嵌入到 query,key, value的變換過程。綜上,自注意力的輸入Q,K,V因該用下面的公式計算:
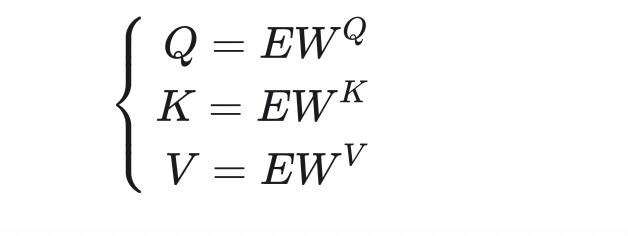
其中,E是詞嵌入矩陣,也就是每個單詞的詞嵌入的數組;是可學習的參數矩陣。在Transformer中,大部分中間向量的長度都用
表示,詞嵌入的長度也是
。因此,設輸入的句子長度為n, 則E的形狀是
,?
的形狀是
, ?
?的形狀是
。
就像卷積層能夠用多個卷積核生成多個通道的特征一樣,我們也用多組生成多組自注意力結果。這樣,每個單詞的自注意力表示會更豐富一點,這種機制就叫做多頭注意力。把多頭注意力用在自注意力上的公式為:
Transformer似乎默認所有向量都是行向量,參數矩陣都寫成了右乘而不是常見的左乘。
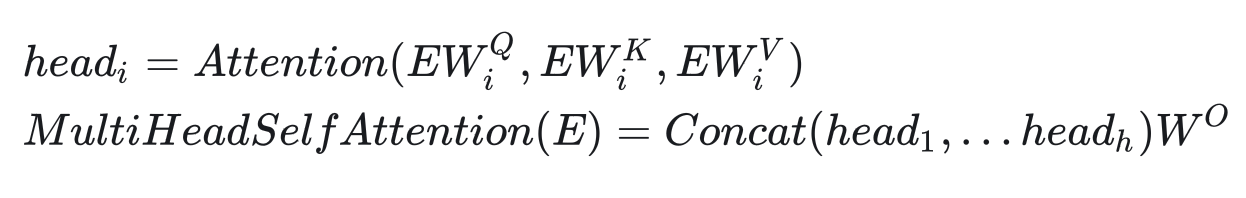
其中,h是多頭自注意力的“頭”數,?是另一個參數矩陣。多頭注意力模塊的輸入輸出向量的長度都是
。因此,
的形狀是
(自注意力的輸出長度是
,有h個輸出)。在論文中,Transformer的默認參數配置如下:

?實際上,多頭注意力機制不僅僅可以用在計算自注意力上。推廣一下,如果把多頭自注意力的輸入E 拆成三個矩陣Q,K,V,則多頭注意力的公式為:
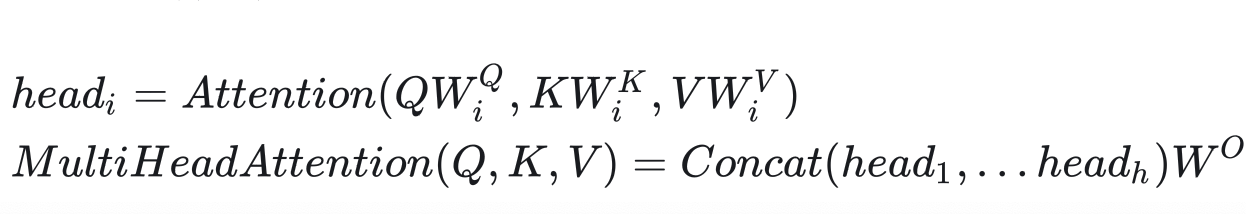
8. Transformer模型架構?
看懂了注意力機制,可以回過頭閱讀3.1節學習Transformer的整體架構了。
論文里的圖1是transformer 的架構圖:
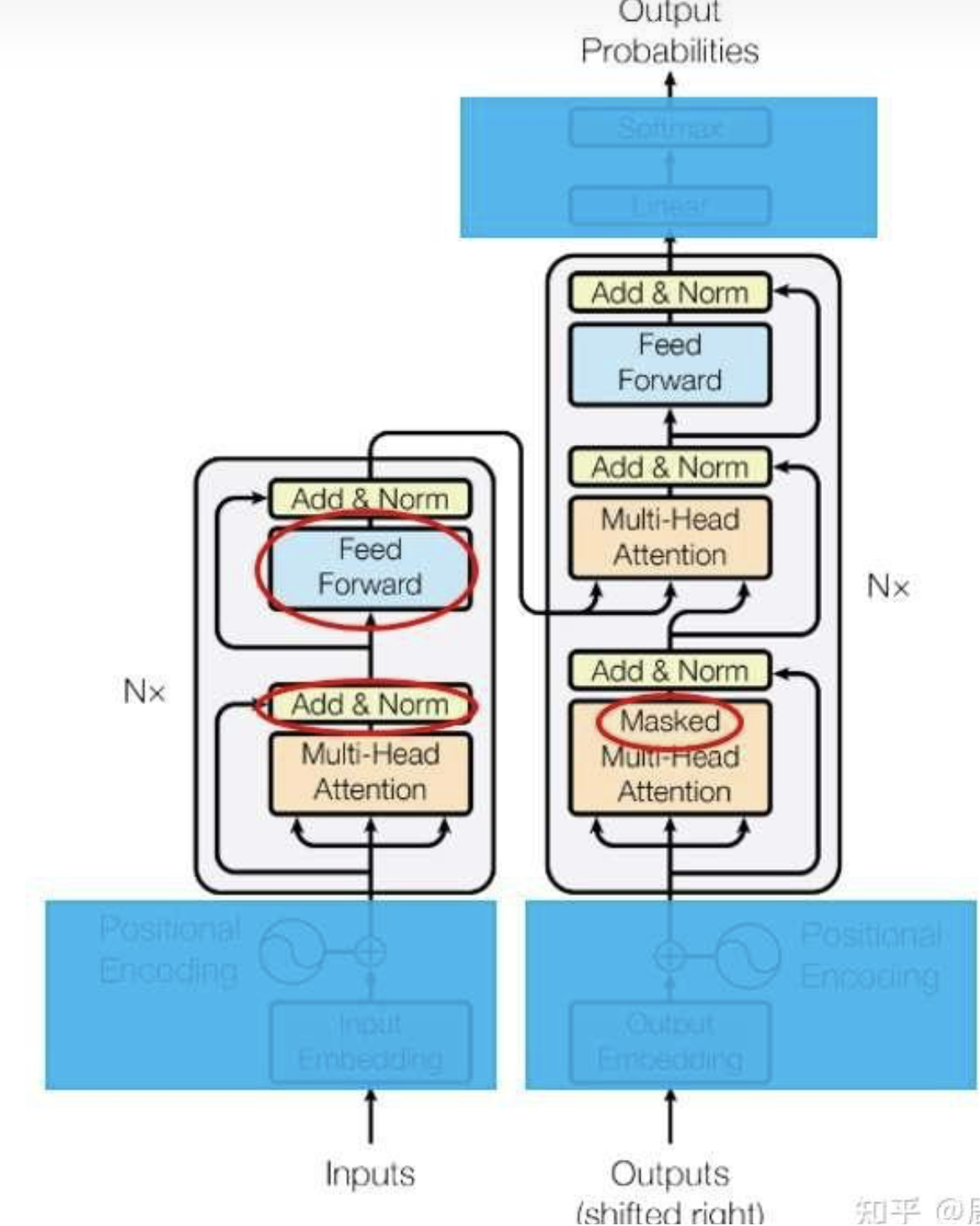
三個疑問:
1. Add & Norm
2. Feed Forward
3. 為什么一個多頭注意力前面加了Masked
我們來一次看懂這三個模塊。
9. 殘差連接?
Transformer使用了和ResNet 類似的殘差連接,即設模塊本身的映射F(x),則模塊輸出為Normalization(F(x)+x)。和ResNet不同,Transformer使用的歸一化方法是LayerNorm。
另外要注意的是,殘差連接有一個要求:輸入x和輸出F(x)+x的維度必須等長,在Transformer中,包含所有詞嵌入在內的向量長度都是
10.前饋網絡
架構圖中的前饋網絡(Feed Forward)其實就是一個全連接網絡。具體來說,這個子網絡由兩個線性層組成,中間用ReLU作為激活函數。
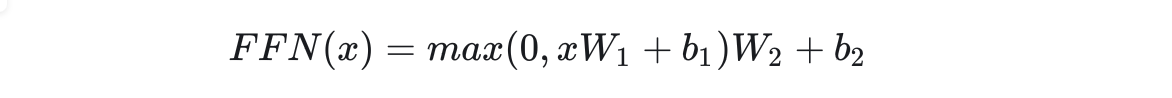
中間的隱藏層維度數記做?。?
=2048
11.?整體架構與掩碼多頭注意力
現在,我們基本能看懂模型的整體架構了。只有讀懂了整個模型的運行原理,我們才能搞懂多頭注意力前面的masked哪來的。
論文第3章開頭介紹了模型的運行原理。和多數強力的序列轉換模型一樣,Transformer使用了encoder-decoder的架構。早期基于RNN的序列轉換模型在生成序列時一般會輸入前i個單詞,輸出 i+1個單詞。

?而Transformer 不同。對于輸入序列,它會被編碼器編碼成中間表示
.給定z的前提下,解碼器輸入
,輸出
預測。
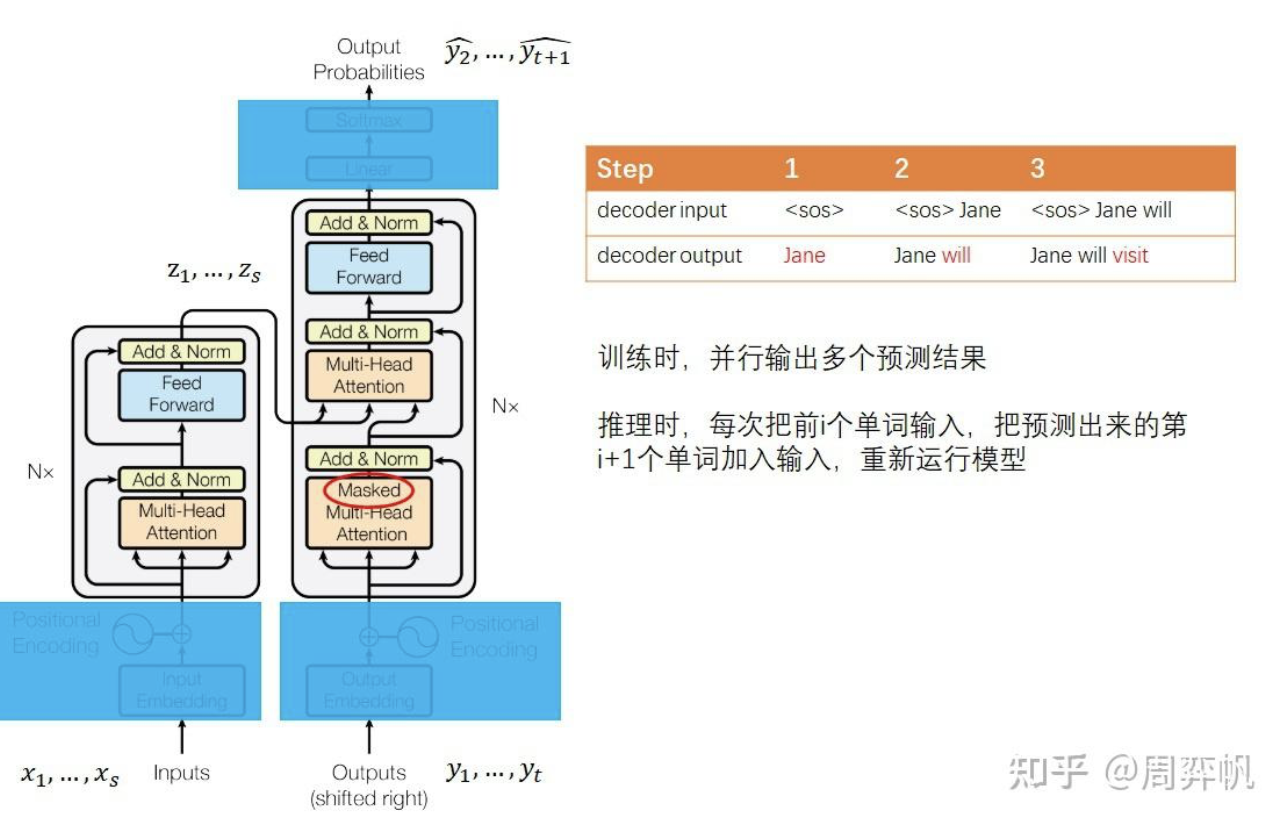
Transformer 默認會并行地輸出結果。而在推理時,序列必須得串行生成。直接調用Transformer的并行輸出邏輯會產生非常多的冗余運算量。推理的代碼實現可以進行優化。
具體來說,輸入序列x會經過N=6個結構相同的層。每層有多個子層組成。第一個子層是多頭注意力層,準確來說,是多頭自注意力。這一層可以為每一個輸入單詞體恤更有意義的表示。之后數據會經過前饋網絡子層。最終,輸出編碼結果z。
得到z后,要用解碼器輸出結果了。解碼器的輸入時當前已經生成的序列,該序列會經過掩碼(masked)多頭自注意力子層。我們先不管這個掩碼是什么意思,暫且把它當成普通的多頭自注意力層。它的作用和編碼器中的一樣,用于提取出更有意義的表示。
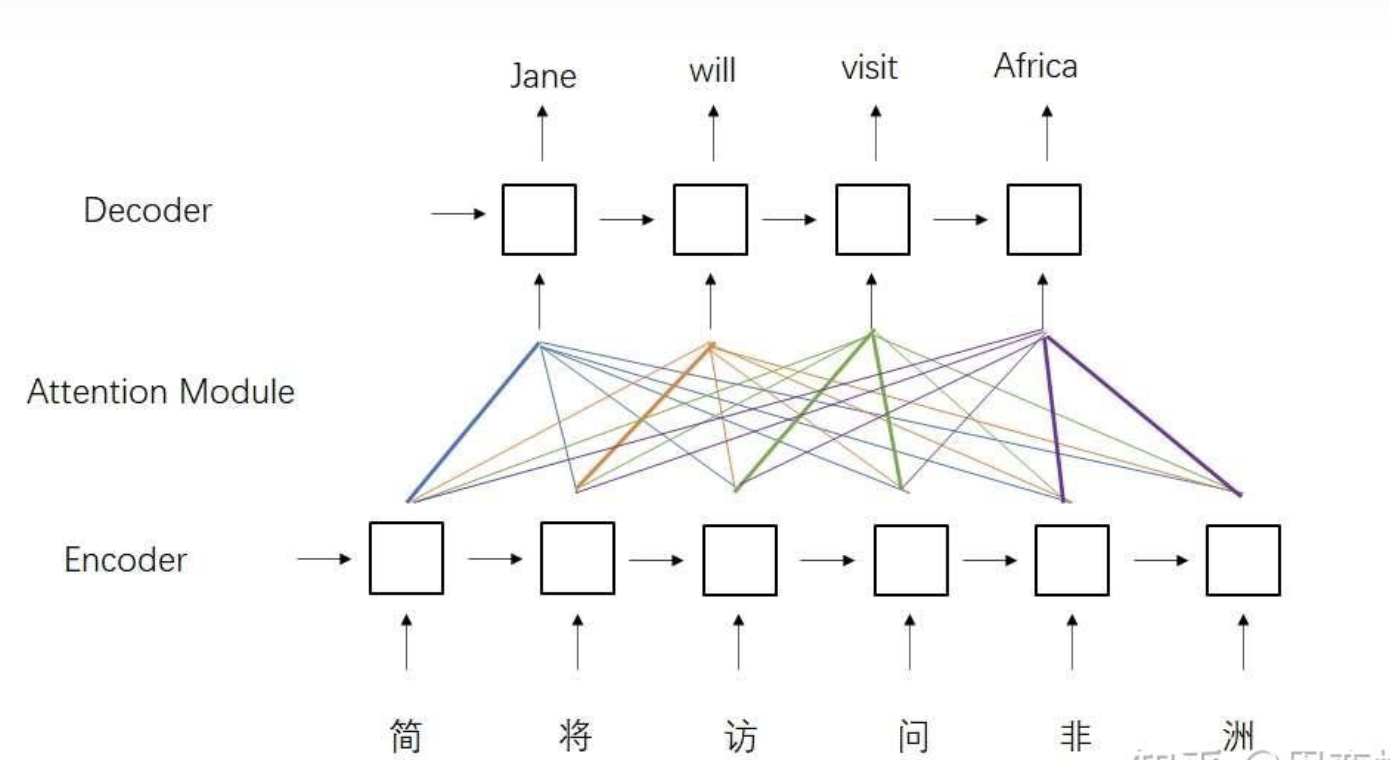
接下來,數據還會經過一個多頭注意力層。這個層比較特別,它的K,V來自z,Q來自上一層的輸出。為什么會有這樣的設計呢?這種設計來自于早期的注意力模型。如下圖所示,在早期的注意力模型中,每一個輸出單詞都會與每一個輸入單詞求一個注意力,以找到每一個輸出單詞最相關的某幾個輸入單詞。用注意力公式來表達的話,Q就是輸出單詞,K, V就是輸入單詞。
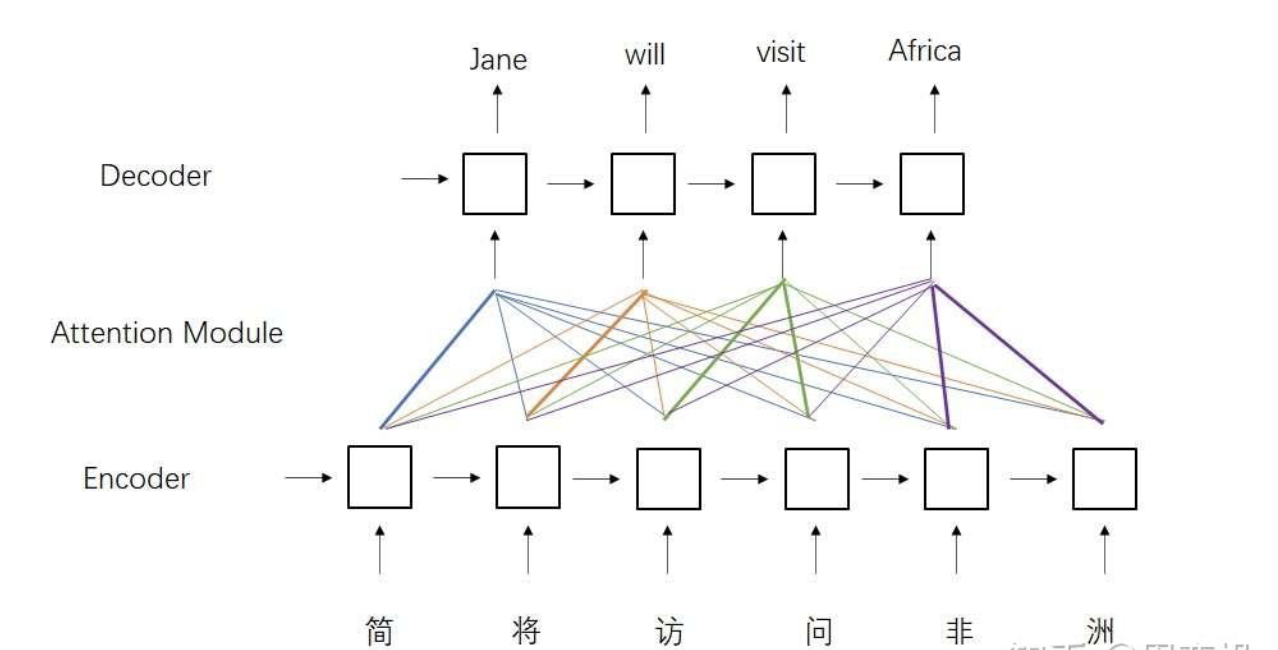
經過第二個多頭注意力層后,和編碼器一樣,數據會經過一個前饋網絡。最終,網絡并行輸出各個時刻的下一個單詞。
這種并行計算有一個要注意的地方。在輸出第t+1個單詞時,模型不應該提前知道t+1時刻之后的信息。因此,應該只保留t時刻之前的信息,遮住后面的輸入。這可以通過添加掩碼實現。添加掩碼一個不嚴謹示例如下表:
 ?
?
這就是為什么編碼器的多頭自注意力層前面有一個masked。在論文中,mask是通過令注意力公式 的softmax的輸入為實現的(softmax的輸入為
,注意力權重就幾乎為0,被遮住的輸出也幾乎全部為0)。每個mask都是一個上三角矩陣。
12. 嵌入層
看完了Transformer主干結構,再來看看輸入輸出做了哪些前后處理。
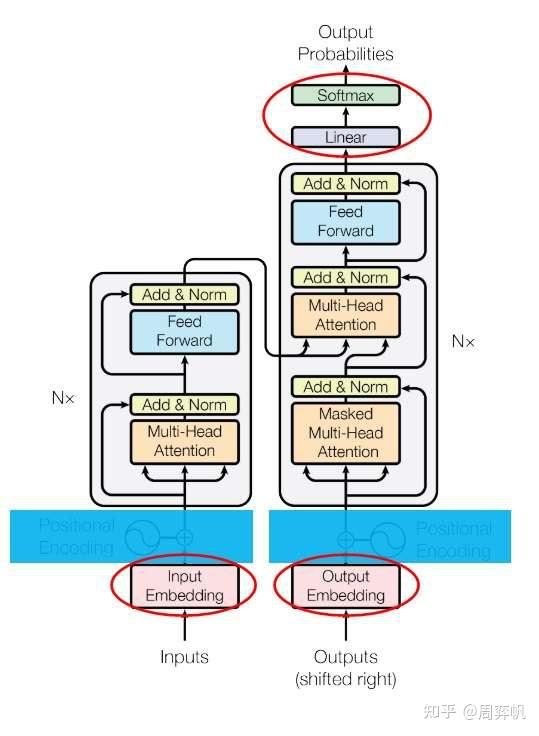
和其他大多數序列轉換任務一樣,Transformer主干結構的輸入輸出都是詞嵌入序列。詞嵌入,其實就是一個把one-hot向量轉換成有意義的向量的轉換矩陣。在transformer中,解碼器的嵌入層和輸出層是共享權重的---輸出線性層表示的線性變換是嵌入層的逆變換,其目的是把網絡輸出的嵌入再轉換回one-hot向量。如果某任務的輸入和輸出是同一種語言,那么編碼器的嵌入層和編碼層的嵌入層也可以共享權重。
論文中寫道:“輸入輸出的嵌入層和softmax前的線性層共享權重”。這個描述不夠清楚。如果輸入和輸出的不是同一種語言,比如輸入中文輸出英文,那么共享一個詞嵌入是沒有意義的。?
嵌入矩陣的權重乘了。
由于模型要預測一個單詞,輸出的線性層后面還有一個常規的softmax操作。
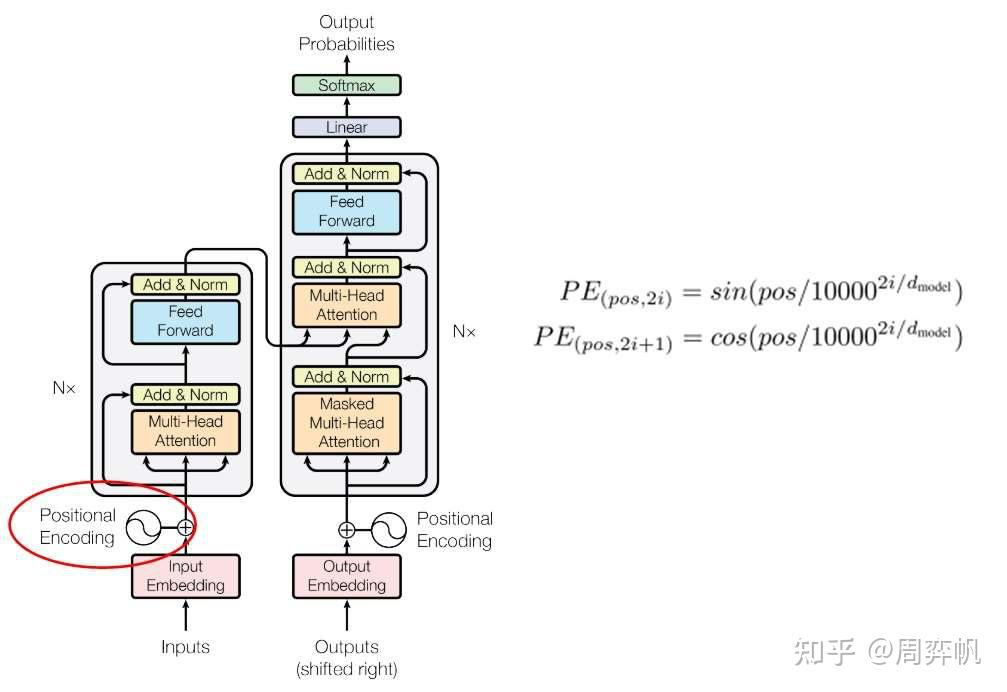
13. 位置編碼
現在,Transformer的結構圖還剩一個模塊沒有讀---位置編碼。無論是RNN還是CNN,都能自然地利用到序列的先后順序這一信息。然而,Transformer的主干網絡并不能利用到序列順序信息。因此,Transformer使用了一種叫做位置編碼的機制,對編碼器和解碼器的嵌入輸入做了一些修改,以向模型提供序列順序信息。
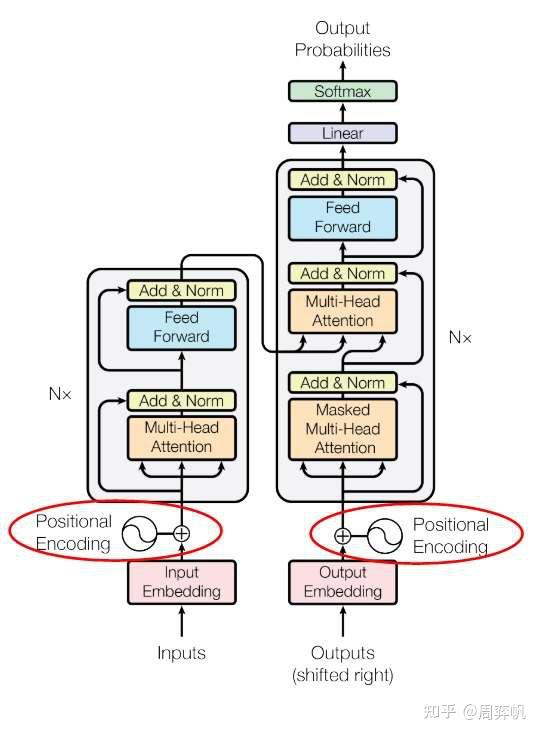
嵌入層的輸出是一個向量數組,即詞嵌入向量的序列。設數組的位置叫pos,向量的某一維叫i。
維度向量索引(i) 的理解:
首先位置編碼的結構:
位置編碼向量是一個長度為?d_model(例如 512)的向量,其中:
-
偶數索引位置(0,2,4,...)使用正弦函數計算:
PE(pos, 2i) = sin(...) -
奇數索引位置(1,3,5,...)使用余弦函數計算:
PE(pos, 2i+1) = cos(...) -
這里的i就是維度索引,它表示的是位置編碼向量中“邏輯維度組”。
為什么需要維度索引i?
位置編碼的關鍵思想是:不同維度對應不同“頻率”的位置信息:
- 較小的i值->較低的頻率->捕捉長距離位置關系
- 較大的i值->較高的頻率->捕捉短距離位置關系
想象位置編碼矩陣(序列長度 x 模型維度):
位置0: [sin(i=0), cos(i=0), sin(i=1), cos(i=1), ...]
位置1: [sin(i=0), cos(i=0), sin(i=1), cos(i=1), ...]
...
- 每一列對應一個特定的i值
- 同一i的sin/cos對編碼相似的位置關系特性
- 不同i提供不同“分辨率”的位置信息
加上位置pos
位置序列: [0, 1, 2]位置編碼矩陣: 位置0: [PE(0,0), PE(0,1), PE(0,2), PE(0,3)] 位置1: [PE(1,0), PE(1,1), PE(1,2), PE(1,3)] 位置2: [PE(2,0), PE(2,1), PE(2,2), PE(2,3)]
關鍵特性
-
絕對位置表示:每個整數位置對應唯一編碼
-
順序保持:位置1的編碼介于位置0和位置2之間
-
相對距離:位置差越大,編碼差異越大
-
可擴展性:理論上可處理任意長度序列(受限于數值精度)
我們為每一個向量里的每一個數添加一個實數編碼,?這種編碼方式要滿足以下性質:
1. 對于同一個pos不同的i, 即對于一個詞嵌入向量的不同元素,它們的編碼要各不相同。
2. 對于向量的同一個維度處,不同pos的編碼不同。且pos間要滿足相對關系,即
。
要滿足這兩種性質的話,我們可以輕松地設計一種編碼函數:
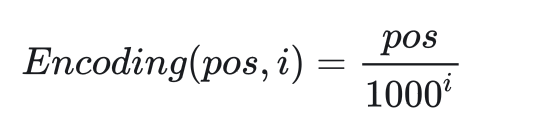
即對于每一個位置i,用小數點后的3個十進制數位來表示不同的pos,pos之間也滿足相對關系。
但是,這種編碼不利于網絡學習。我們更希望所有編碼都差不多大小,且都位于0~1之間。為此,Transformer使用了三角函數作為編碼函數。這種位置編碼(Positional Encoding, PE)的公式如下。
![]()
i不同,則三角函數的周期不同。同pos不同周期的三角函數值不重復。這滿足上面的性質1。另外,根據三角函數的和角公式:
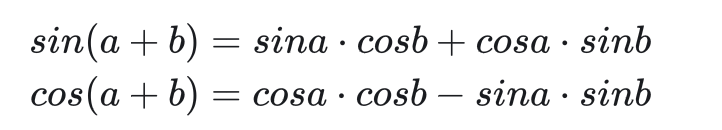
?f(pos + k )是 f(pos) 的一個線性函數,即不同的pos之間有相對關系。這滿足性質2。
本文作者也嘗試了用可學習的函數作為位置編碼函數。實驗表明,二者的表現相當。作者還是使用了三角函數作為最終的編碼函數,這是因為三角函數能夠外推到任意長度的輸入序列,而可學習的位置編碼只能適應訓練時的序列長度。
14. 為什么用自注意力
在論文的第四章,作者用自注意力層對比了循環層和卷積層,探討了自注意力的一些優點。
自注意力層是一種和循環層和卷積層等效的計算單元。它們的目的都是把一個向量序列映射成另一個向量序列,比如說編碼器把x映射成中間表示。論文比較了三個指標:每一層的計算復雜度、串行操作的復雜度、最大路徑長度。

前兩個指標很容易懂,第三個指標最大路徑長度需要解釋一下。最大路徑長度表示數據從某個位置傳遞到另一個位置的最大長度。比如對邊長為n的圖像做普通卷積操作,卷積核大小為3*3, 要做n/3次卷積才能把信息叢左上角的像素傳播到右下角的像素。設卷積核變長為k,則最大路徑長度。如果是空洞卷積的話,像素第一次卷積的感受也是3*3,第二次是5*5,第三次是9*9,以此類推,感受也會指數級增長,這種卷積最大路徑長度為
我們可以從這三個指標分別探討自注意力的好處。首先看序列操作的復雜度。如引言所寫,循環層最大的問題是不能并行訓練,序列計算復雜度是。而自注意力層和卷積一樣可以完全并行。
再看每一層的復雜度。設n是序列長度,d是詞嵌入向量長度。其他架構的復雜度有,而自注意力是d。一般模型的d會大于n,自注意力的計算復雜度也會低一些。
最后是最大路徑長度。注意力本來就是全局查詢操作,可以在O(1的時間里完成所有元素間信息的傳遞。它的信息傳遞速度遠勝卷積層和循環層。
為了降低每層的計算復雜度,可以改進自注意力層的查詢方式,讓每個元素查詢最近的個元素。本文僅提出了這一想法,并沒有做相關實驗。
?15. 實驗與結果
本工作測試了“英語-德語”和“英語-法語”兩項翻譯任務。使用論文的默認模型配置,在8張P100上只需12小時就能把模型訓練完。本工作使用了Adam優化器,并對學習率調度有一定的優化。模型有兩種正則化方式:1)每個子層后面有Dropout,丟棄概率0.1;2)標簽平滑(Label Smoothing)。Transformer在翻譯任務上勝過了所有其他模型,且訓練時間大幅縮短。
論文同樣展示了不同配置下Transformer的消融實驗結果。
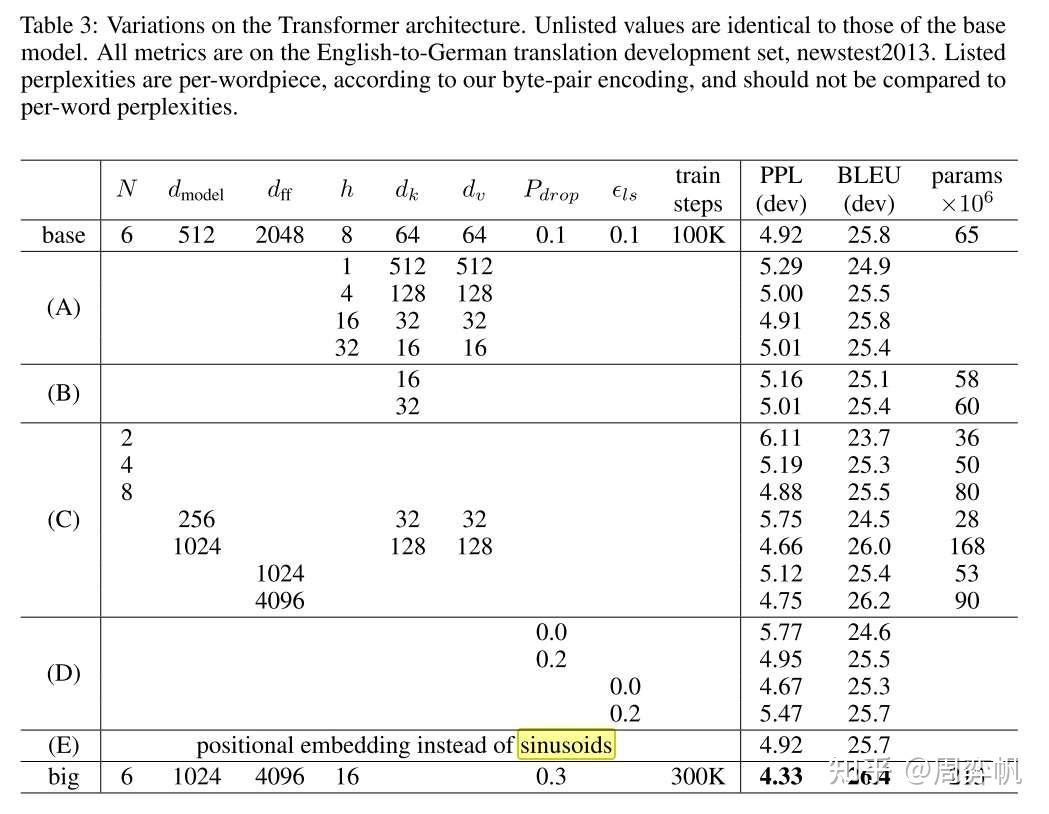
實驗A表明,計算量不變的前提下,需要謹慎地調節h和的比例,太大太小都不好。這些實驗也說明,多頭注意力比單頭是要好的。
實驗B表明,增加可以提升模型性能。作者認為,這說明計算key, value相關性是比較困難的,如果用更精巧的計算方式來代替點乘,可能可以提升性能。
實驗C, D表明,大模型是更優的,且dropout是必要的。
如正文所寫,實驗E探究了可學習的位置編碼。可學習的位置編碼的效果和三角函數幾乎一致。
?16. 總結
為了改進RNN不可并行的問題,這篇工作提出了Transformer這一僅由注意力機制構成的模型。Transformer的效果非常出色,不僅訓練速度快了,還在兩項翻譯任務上勝過其他模型。
作者也很期待Transformer在其他任務上的應用。對于序列長度比較大的任務,如圖像、音頻、視頻,可能要使用文中提到的只關注局部的注意力機制。由于序列輸出時仍然避免不了串行,作者也在探究如何減少序列輸出的串行度。
現在來看,Transformer是近年來最有影響力的深度學習模型之一。它先是在NLP中發揚光大,再逐漸擴散到了CV等領域。文中的一些預測也成為了現實,現在很多論文都在討論如何在圖像中使用注意力,以及如何使用帶限制的注意力以降低長序列導致的計算性能問題。
我認為,對于深度學習的初學者,不管是研究什么領域,都應該仔細學習Transformer。在學Transformer之前,最好先了解一下RNN和經典的encoder-decoder架構,再學習注意力模型。有了這些基礎,讀Transformer論文就會順利很多。讀論文時,最重要的是看懂注意力公式的原理,再看懂自注意力和多頭注意力,最后看一看位置編碼。其他一些和機器翻譯任務相關的設計可以不用那么關注
二. PyTorch Transformer 英中翻譯超詳細教程
1. 數據集準備
https://github.com/P3n9W31/transformer-pytorch?項目中找到了一個較小的中英翻譯數據集。數據集只有幾KB大小,中英詞表只有10000左右,比較適合做Demo。如果要實現更加強大實用的模型,則需要換更大的數據集。但相應地,你要多花費更多的時間來訓練。
該數據集由cn.txt,?en.txt,?cn.txt.vocab.tsv,?en.txt.vocab.tsv這四個文件組成。前兩個文件包含相互對應的中英文句子,其中中文已做好分詞,英文全為小寫且標點已被分割好。后兩個文件是預處理好的詞表。語料來自2000年左右的中國新聞,其第一條的中文及其翻譯如下:
目前 糧食 出現 階段性 過剩 , 恰好 可以 以 糧食 換 森林 、 換 草地 , 再造 西部 秀美 山川 。
the present food surplus can specifically serve the purpose of helping western china restore its woodlands , grasslands , and the beauty of its landscapes .
詞表則統計了各個單詞的出現頻率。通過使用詞表,我們能實現單詞和序號的相互轉換(比如中文里的5號對應“的”字,英文里的5號對應"the")。詞表的前四個單詞是特殊字符,分別為填充字符、頻率太少沒有被加入詞典的詞語、句子開始字符、句子結束字符。
<PAD>?? ?1000000000
<UNK>?? ?1000000000
<S>?? ?1000000000
</S>?? ?1000000000
的?? ?8461
是?? ?2047
和?? ?1836
在?? ?1784
<PAD>?? ?1000000000
<UNK>?? ?1000000000
<S>?? ?1000000000
</S>?? ?1000000000
the?? ?13680
and?? ?6845
of?? ?6259
to?? ?4292?
i_seq = torch.linspace(0, max_seq_len - 1, max_seq_len)
j_seq = torch.linspace(0, d_model - 2, d_model // 2)
pos, two_i = torch.meshgrid(i_seq, j_seq)?
2. Transformer 模型
準備好數據后,接下來就要進行這個項目最重要的部分--- Transformer 模型實現了。 我將按照代碼的執行順序,從前往后,自底向上介紹Transformer的各個模塊,Positional Encoding, MultiHead Attention,Encoder&Decoder,最后介紹如何把各個模塊拼到一起。
2.1 Positional Encoding
模型一開始是Embedding 層加一個Positional Encoding。Embedding在PyTorch里已經有實現了。
求Positional Encoding,其實就是求一個二院函數的許多函數值構成的矩陣。對于二元函數PE(po s, i),我們要求出時所有的函數值,其中,seqlen是該序列的長度,
是每一個詞向量的長度。
理論上來說,每個句子的序列長度seqlen是不固定的。但是,我們可以提前預處理一個seqlen很大的Positional Encoding矩陣。每次有句子輸入進來,根據這個句子和序列長度,去預處理好的矩陣里取一小塊出來即可。?
?為了并行地求pe,我們要初始化一個二維網絡,表示自變量pos, i。生成網絡可以用下面的代碼實現。
i_seq = torch.linspace(0, max_seq_len - 1, max_seq_len)
j_seq = torch.linspace(0, d_model - 2, d_model // 2)
pos, two_i = torch.meshgrid(i_seq, j_seq)
這段代碼的理解:
i_seq:位置序列(pos)
torch.linspace(0, max_seq_len - 1, max_seq_len) - 生成從0 到 max_seq_len -1 的等間隔序列
- 長度= max_seq_len(序列總長度)
- 示例:若max_seq_len = 3??-> [0.0, 1.0, 2.0]
- 物理意義:每個token在序列中的位置索引
j_seq:維度索引序列(i)
torch.linspace(0, d_model - 2, d_model // 2)- 生成從0到d_model-2的等間隔序列
- 長度 = d_model // 2 (位置編碼維度的一半)
- 示例: 若d_model = 4 -> [0.0, 2.0] (因為 4// 2 =2個點)
- 物理意義:位置編碼向量索引(對應公式中的i)
網絡生成 torch.meshgrid?
pos, two_i = torch.meshgrid(i_seq, j_seq)- 功能: 創建兩個網絡矩陣,將兩個ID序列擴展為2D網絡
- 輸出:
-
pos:形狀為?(max_seq_len, d_model//2)?的矩陣# 示例:max_seq_len=3, d_model=4 → j_seq=[0.0,2.0] [[0., 0.], # 第一行全部填充i_seq[0][1., 1.], # 第二行全部填充i_seq[1][2., 2.]] # 第三行全部填充i_seq[2]
-
two_i:形狀為?(max_seq_len, d_model//2)?的矩陣[[0., 2.], # 第一列填充j_seq[0][0., 2.], # 第二列填充j_seq[1][0., 2.]] # 第三列填充j_seq[1](復制行)
利用這個函數的返回結果,我們可以把pos, two_i套入論文的公式,并行地分別算出奇偶位置的 PE 值。
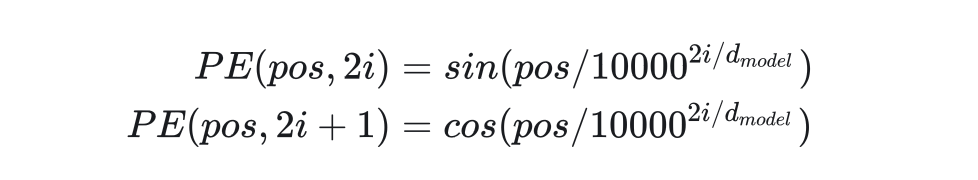
pe_2i = torch.sin(pos / 10000**(two_i / d_model))
pe_2i_1 = torch.cos(pos / 10000**(two_i / d_model))
有了奇偶處的值,現在的問題是怎么把它們優雅地拼到同一個維度上。我這里先把它們堆成了形狀為seq_len, d_model/2, 2的一個張量,再把最后一維展平,就得到了最后的pe矩陣。這一操作等于新建一個seq_len, d_model形狀的張量,再把奇偶位置處的值分別填入。
pe = torch.stack((pe_2i, pe_2i_1), 2).reshape(1, max_seq_len, d_model)最后,要注意一點。只用?self.pe = pe?記錄這個量是不夠好的。我們最好用?self.register_buffer('pe', pe, False)?把這個量登記成?torch.nn.Module?的一個存儲區(這一步會自動完成self.pe = pe)。這里涉及到 PyTorch 的一些知識了。
PyTorch 的?Module?會記錄兩類參數,一類是?parameter?可學習參數,另一類是?buffer不可學習的參數。把變量登記成?buffer?的最大好處是,在使用?model.to(device)?把一個模型搬到另一個設備上時,所有?parameter?和?buffer?都會自動被搬過去。另外,buffer和?parameter?一樣,也可以被記錄到?state_dict?中,并保存到文件里。register_buffer?的第三個參數決定了是否將變量加入?state_dict。由于 pe 可以直接計算,不需要記錄,可以把這個參數設成?False。
預處理好pe后,用起來就很方便了。每次讀取輸入的序列長度,從中取一段出來即可。
另外,Transformer給嵌入層乘了個系數。為了方便起見,我把這個系數放到了Positional Encoding類里面。
class PositionalEncoding(nn.Module):def __init__(self, d_model: int, max_seq_len: int):super().__init__()# Assume d_model is an even number for convenienceassert d_model % 2 == 0i_seq = torch.linspace(0, max_seq_len - 1, max_seq_len)j_seq = torch.linspace(0, d_model - 2, d_model // 2)pos, two_i = torch.meshgrid(i_seq, j_seq)pe_2i = torch.sin(pos / 10000**(two_i / d_model))pe_2i_1 = torch.cos(pos / 10000**(two_i / d_model))pe = torch.stack((pe_2i, pe_2i_1), 2).reshape(1, max_seq_len, d_model)self.register_buffer('pe', pe, False)def forward(self, x: torch.Tensor):n, seq_len, d_model = x.shapepe: torch.Tensor = self.peassert seq_len <= pe.shape[1]assert d_model == pe.shape[2]rescaled_x = x * d_model**0.5return rescaled_x + pe[:, 0:seq_len, :]2.2 Scaled Dot-Product Attention?
下一步是多頭注意力層,為了實現多頭注意力,我們先要實現Transformer里經典的注意力計算。而在講注意力計算之前,我們還要補充一下Transformer中有關mask的一些知識。
Transformer里的mask?
Transformer 最大的特點就是能夠并行訓練。給定翻譯好的第1~n個詞語,它默認會并行地預測第2~(n+1)個下一個詞語。為了模擬串行輸出的情況,第個詞語不應該看到第個詞語之后的信息。
| 輸入信息 | 輸出 |
|---|---|
| (y1, --, --, --) | y2 |
| (y1, y2, --, --) | y3 |
| (y1, y2, y3, --) | y4 |
| (y1, y2, y3, y4) | y5 |
為了實現這一功能,Transformer在decoder里使用了掩碼。掩碼取1表示這個地方的數是有效的,取0表示這個地方的數是無效的。Decoder里的這種掩碼應該是一個上三角全1矩陣。
掩碼是在注意力計算中生效的。對于掩碼取0的區域,其softmax前的值取負無窮。這是因為,對于softmax
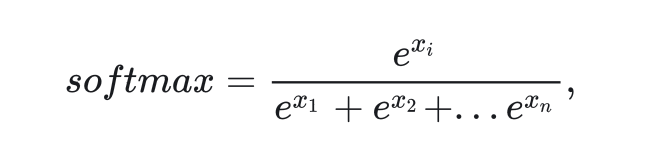
令 可以讓它在softmax分母里不產生任何貢獻。
以上是論文里提到的mask,它用來模擬Decoder的串行推理。而在代碼實現中,還有其他地方會產生mask。在生成一個batch的數據時,要給句子填充<pad>。這個特殊字符也沒有實際意義,不應該對計算產生任何貢獻。因此,有<pad>的地方mask也應該為0。
注意力計算
由于注意力計算沒有任何的狀態,因此它應該寫成一個函數,而不是一個類。我們可以輕松地用PyTorch代碼翻譯注意力計算的公式,我們可以輕松地用 PyTorch 代碼翻譯注意力計算的公式。(注意,我這里的 mask 表示哪些地方要填負無窮,而不是像之前講的表示哪些地方有效)
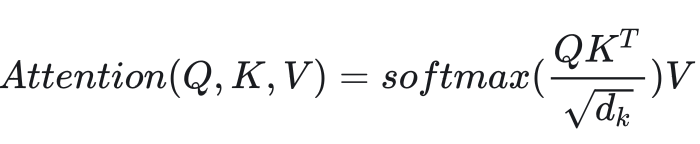
def attention(q: torch.Tensor,k: torch.Tensor,v: torch.Tensor,mask: Optional[torch.Tensor] = None):'''Note: The dtype of mask must be bool'''# q shape: [n, heads, q_len, d_k]# k shape: [n, heads, k_len, d_k]# v shape: [n, heads, k_len, d_v]assert q.shape[-1] == k.shape[-1]d_k = k.shape[-1]# tmp shape: [n, heads, q_len, k_len]tmp = torch.matmul(q, k.transpose(-2, -1)) / d_k**0.5if mask is not None:tmp.masked_fill_(mask, -MY_INF)tmp = F.softmax(tmp, -1)# tmp shape: [n, heads, q_len, d_v]tmp = torch.matmul(tmp, v)return tmp這里有一個很坑的地方。引入了?<pad>?帶來的 mask 后,會產生一個新的問題:可能一整行數據都是失效的,softmax 用到的所有??可能都是負無窮?.
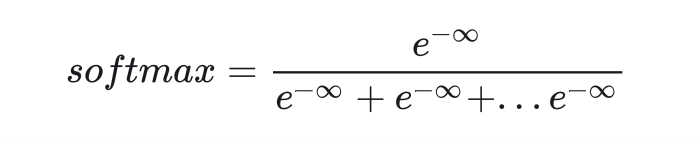
這個數是沒有意義的。如果用torch.inf來表示無窮大,就會令exp(torch.inf)=0,最后 softmax 結果會出現 NaN,代碼大概率是跑不通的。
但是,大多數 PyTorch Transformer 教程壓根就沒提這一點,而他們的代碼又還是能夠跑通。拿放大鏡仔細對比了代碼后,我發現,他們的無窮大用的不是?torch.inf,而是自己隨手設的一個極大值。這樣,exp(-MY_INF)得到的不再是0,而是一個極小值。softmax 的結果就會等于分母的項數,而不是 NaN,不會有數值計算上的錯誤。
Muti-Head Attention
?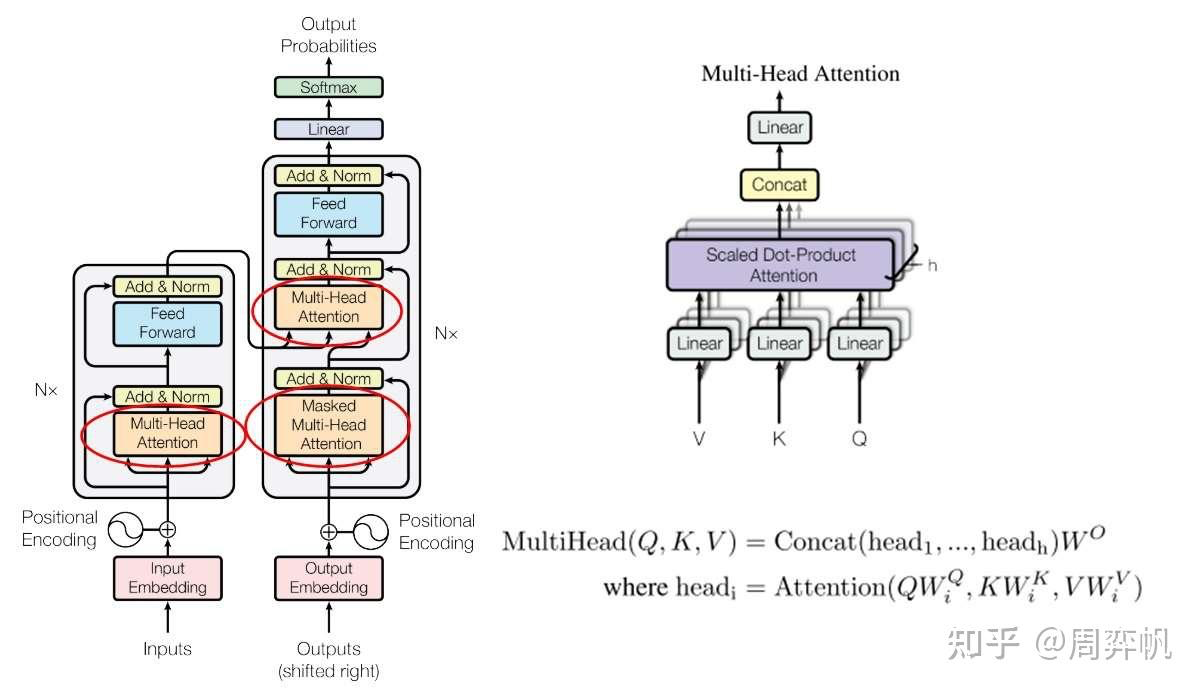
有了注意力計算,就可以實現多頭注意力層了。多頭注意力層時有學習參數的,它應該寫成一個類。
class MultiHeadAttention(nn.Module):def __init__(self, heads: int, d_model: int, dropout: float = 0.1):super().__init__()assert d_model % heads == 0# dk == dvself.d_k = d_model // headsself.heads = headsself.d_model = d_modelself.q = nn.Linear(d_model, d_model)self.k = nn.Linear(d_model, d_model)self.v = nn.Linear(d_model, d_model)self.out = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)def forward(self,q: torch.Tensor,k: torch.Tensor,v: torch.Tensor,mask: Optional[torch.Tensor] = None):# batch should be sameassert q.shape[0] == k.shape[0]assert q.shape[0] == v.shape[0]# the sequence length of k and v should be alignedassert k.shape[1] == v.shape[1]n, q_len = q.shape[0:2]n, k_len = k.shape[0:2]q_ = self.q(q).reshape(n, q_len, self.heads, self.d_k).transpose(1, 2)k_ = self.k(k).reshape(n, k_len, self.heads, self.d_k).transpose(1, 2)v_ = self.v(v).reshape(n, k_len, self.heads, self.d_k).transpose(1, 2)attention_res = attention(q_, k_, v_, mask)concat_res = attention_res.transpose(1, 2).reshape(n, q_len, self.d_model)concat_res = self.dropout(concat_res)output = self.out(concat_res)return output?這段代碼一處很靈性的地方。在 Transformer 的論文中,多頭注意力是先把每個詞的表示拆成個h頭,再對每份做投影、注意力,最后拼接起來,再投影一次。其實,拆開與拼接操作是多余的。我們可以通過一些形狀上的操作,等價地實現拆開與拼接,以提高運行效率。
具體來說,我們可以一開始就讓所有頭的數據經過同一個線性層,之后在做注意力之前把頭和序列數這兩維轉置一下。這兩步操作和拆開來做投影和注意力時等價的。做完了注意力操作之后,再把兩個維度轉置回來,這和拼接操作時等價的。
?
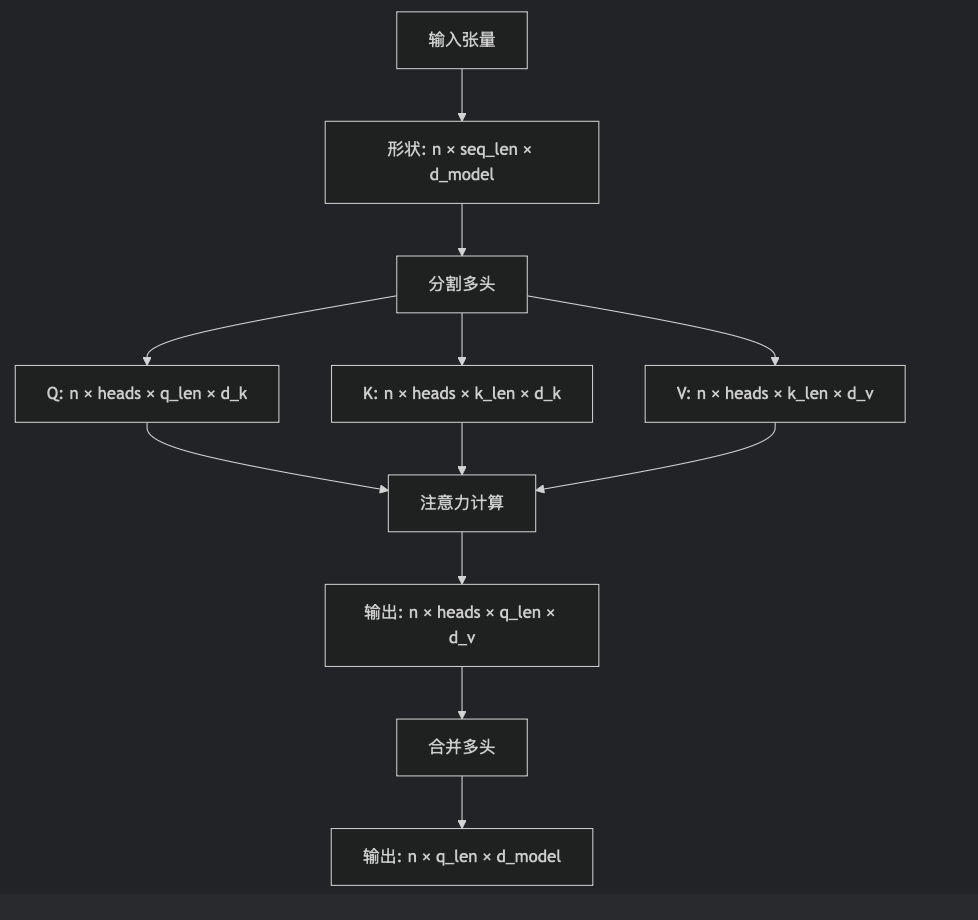
?
前饋網絡?
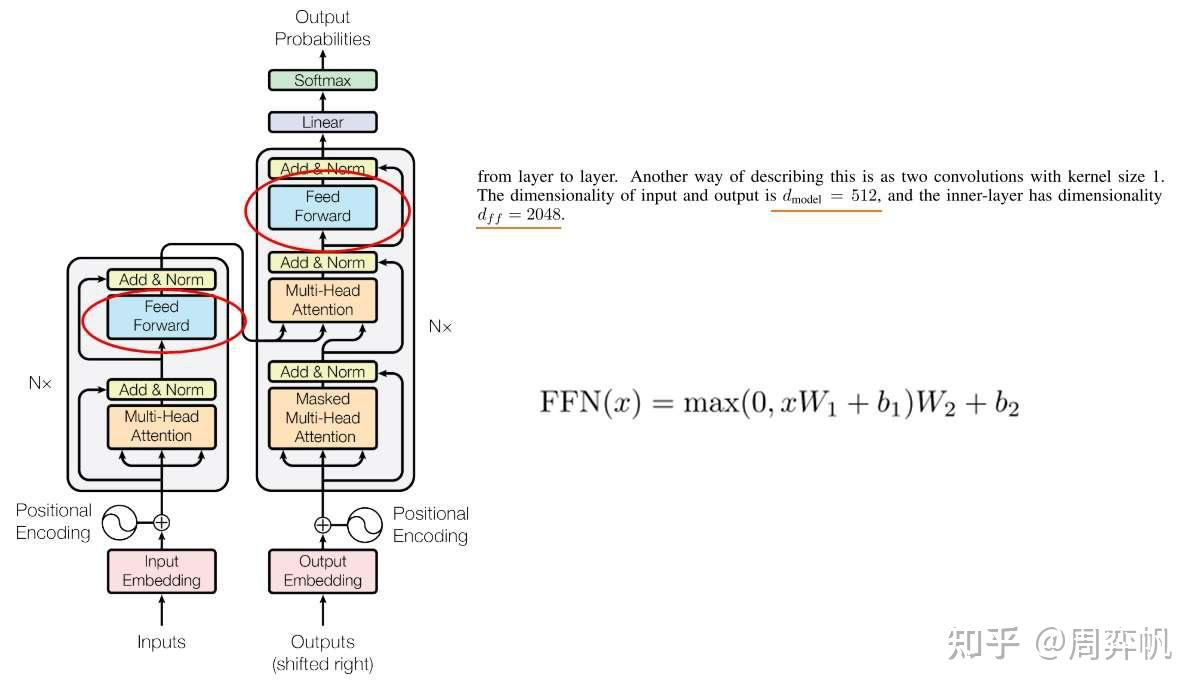
class FeedForward(nn.Module):def __init__(self, d_model: int, d_ff: int, dropout: float = 0.1):super().__init__()self.layer1 = nn.Linear(d_model, d_ff)self.dropout = nn.Dropout(dropout)self.layer2 = nn.Linear(d_ff, d_model)def forward(self, x):x = self.layer1(x)x = self.dropout(F.relu(x))x = self.layer2(x)return xEncoder & Decoder
準備好一切組件后,就可以把模型一層一層搭起來了。先搭好每個 Encoder 層和 Decoder 層,再拼成 Encoder 和 Decoder。?
Encoder 層和 Decoder 層的結構與論文中的描述一致,且每個子層后面都有一個 dropout,和上一層之間使用了殘差連接。歸一化的方法是?LayerNorm。順帶一提,不僅是這些層,前面很多子層的計算中都加入了 dropout。
class EncoderLayer(nn.Module):def __init__(self,heads: int,d_model: int,d_ff: int,dropout: float = 0.1):super().__init__()self.self_attention = MultiHeadAttention(heads, d_model, dropout)self.ffn = FeedForward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)def forward(self, x, src_mask: Optional[torch.Tensor] = None):tmp = self.self_attention(x, x, x, src_mask)tmp = self.dropout1(tmp)x = self.norm1(x + tmp)tmp = self.ffn(x)tmp = self.dropout2(tmp)x = self.norm2(x + tmp)return x
class DecoderLayer(nn.Module):def __init__(self,heads: int,d_model: int,d_ff: int,dropout: float = 0.1):super().__init__()self.self_attention = MultiHeadAttention(heads, d_model, dropout)self.attention = MultiHeadAttention(heads, d_model, dropout)self.ffn = FeedForward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)def forward(self,x,encoder_kv: torch.Tensor,dst_mask: Optional[torch.Tensor] = None,src_dst_mask: Optional[torch.Tensor] = None):tmp = self.self_attention(x, x, x, dst_mask)tmp = self.dropout1(tmp)x = self.norm1(x + tmp)tmp = self.attention(x, encoder_kv, encoder_kv, src_dst_mask)tmp = self.dropout2(tmp)x = self.norm2(x + tmp)tmp = self.ffn(x)tmp = self.dropout3(tmp)x = self.norm3(x + tmp)return xEncoder和Decoder就在所有子層前面加了一個嵌入層、一個位置編碼,再把多個子層堆起來而已,其他輸入輸出照搬即可。注意,我們可以給嵌入層輸入pad_idx參數,讓<pad>的計算不對梯度產生貢獻。
class Encoder(nn.Module):def __init__(self,vocab_size: int,pad_idx: int,d_model: int,d_ff: int,n_layers: int,heads: int,dropout: float = 0.1,max_seq_len: int = 120):super().__init__()self.embedding = nn.Embedding(vocab_size, d_model, pad_idx)self.pe = PositionalEncoding(d_model, max_seq_len)self.layers = []for i in range(n_layers):self.layers.append(EncoderLayer(heads, d_model, d_ff, dropout))self.layers = nn.ModuleList(self.layers)self.dropout = nn.Dropout(dropout)def forward(self, x, src_mask: Optional[torch.Tensor] = None):x = self.embedding(x)x = self.pe(x)x = self.dropout(x)for layer in self.layers:x = layer(x, src_mask)return xclass Decoder(nn.Module):def __init__(self,vocab_size: int,pad_idx: int,d_model: int,d_ff: int,n_layers: int,heads: int,dropout: float = 0.1,max_seq_len: int = 120):super().__init__()self.embedding = nn.Embedding(vocab_size, d_model, pad_idx)self.pe = PositionalEncoding(d_model, max_seq_len)self.layers = []for i in range(n_layers):self.layers.append(DecoderLayer(heads, d_model, d_ff, dropout))self.layers = nn.Sequential(*self.layers)self.dropout = nn.Dropout(dropout)def forward(self,x,encoder_kv,dst_mask: Optional[torch.Tensor] = None,src_dst_mask: Optional[torch.Tensor] = None):x = self.embedding(x)x = self.pe(x)x = self.dropout(x)for layer in self.layers:x = layer(x, encoder_kv, dst_mask, src_dst_mask)return x?Transformer類
?
我們一點一點來看。先看初始化函數。初始化函數的輸入其實就是 Transformer 模型的超參數。總結一下,Transformer 應該有這些超參數:
d_model?模型中大多數詞向量表示的維度大小d_ff?前饋網絡隱藏層維度大小n_layers?堆疊的 Encoder & Decoder 層數head?多頭注意力的頭數dropout?Dropout 的幾率
另外,為了構建嵌入層,要知道源語言、目標語言的詞典大小,并且提供pad_idx。為了預處理位置編碼,需要提前知道一個最大序列長度。
照著子模塊的初始化參數表,把參數歸納到__init__的參數表里即可。
class Transformer(nn.Module):def __init__(self,src_vocab_size: int,dst_vocab_size: int,pad_idx: int,d_model: int,d_ff: int,n_layers: int,heads: int,dropout: float = 0.1,max_seq_len: int = 200):super().__init__()self.encoder = Encoder(src_vocab_size, pad_idx, d_model, d_ff,n_layers, heads, dropout, max_seq_len)self.decoder = Decoder(dst_vocab_size, pad_idx, d_model, d_ff,n_layers, heads, dropout, max_seq_len)self.pad_idx = pad_idxself.output_layer = nn.Linear(d_model, dst_vocab_size)def generate_mask(self,q_pad: torch.Tensor,k_pad: torch.Tensor,with_left_mask: bool = False):# q_pad shape: [n, q_len]# k_pad shape: [n, k_len]# q_pad k_pad dtype: boolassert q_pad.device == k_pad.devicen, q_len = q_pad.shapen, k_len = k_pad.shapemask_shape = (n, 1, q_len, k_len)if with_left_mask:mask = 1 - torch.tril(torch.ones(mask_shape))else:mask = torch.zeros(mask_shape)mask = mask.to(q_pad.device)for i in range(n):mask[i, :, q_pad[i], :] = 1mask[i, :, :, k_pad[i]] = 1mask = mask.to(torch.bool)return maskdef forward(self, x, y):src_pad_mask = x == self.pad_idxdst_pad_mask = y == self.pad_idxsrc_mask = self.generate_mask(src_pad_mask, src_pad_mask, False)dst_mask = self.generate_mask(dst_pad_mask, dst_pad_mask, True)src_dst_mask = self.generate_mask(dst_pad_mask, src_pad_mask, False)encoder_kv = self.encoder(x, src_mask)res = self.decoder(y, encoder_kv, dst_mask, src_dst_mask)res = self.output_layer(res)return res再看一下?forward?函數。forward先預處理好了所有的 mask,再逐步執行 Transformer 的計算:先是通過 Encoder 獲得源語言的中間表示encoder_kv,再把它和目標語言y的輸入一起傳入 Decoder,最后經過線性層輸出結果res。由于 PyTorch 的交叉熵損失函數自帶了 softmax 操作,這里不需要多此一舉。
generate_mask?的輸入有 query 句子和 key 句子的 pad mask?q_pad, k_pad,它們的形狀為[n, seq_len]。若某處為 True,則表示這個地方的字符是<pad>。對于自注意力,query 和 key 都是一樣的;而在 Decoder 的第二個多頭注意力層中,query 來自目標語言,key 來自源語言。with_left_mask?表示是不是要加入 Decoder 里面的模擬串行推理的 mask,它會在掩碼自注意力里用到。
一開始,先取好維度信息,定好張量的形狀。在注意力操作中,softmax 前的那個量的形狀是?[n, heads, q_len, k_len],表示每一批每一個頭的每一個query對每個key之間的相似度。每一個頭的mask是一樣的。因此,除heads維可以廣播外,mask 的形狀應和它一樣。
mask_shape=(n,1,q_len,k_len)
再新建一個表示最終 mask 的張量。如果不用 Decoder 的那種 mask,就生成一個全零的張量;否則,生成一個上三角為0,其余地方為1的張量。注意,在我的代碼中,mask 為 True 或1就表示這個地方需要填負無窮。
下面的代碼利用了PyTorch的取下標機制,直接并行地完成了mask賦值。
for i in range(n):mask[i, :, q_pad[i], :] = 1mask[i, :, :, k_pad[i]] = 1
完整代碼如下:
def generate_mask(self,q_pad: torch.Tensor,k_pad: torch.Tensor,with_left_mask: bool = False):# q_pad shape: [n, q_len]# k_pad shape: [n, k_len]# q_pad k_pad dtype: boolassert q_pad.device == k_pad.devicen, q_len = q_pad.shapen, k_len = k_pad.shapemask_shape = (n, 1, q_len, k_len)if with_left_mask:mask = 1 - torch.tril(torch.ones(mask_shape))else:mask = torch.zeros(mask_shape)mask = mask.to(q_pad.device)for i in range(n):mask[i, :, q_pad[i], :] = 1mask[i, :, :, k_pad[i]] = 1mask = mask.to(torch.bool)return mask看完了mask的生成方法后,我們回到前一步,看看mask會在哪些地方被調用。
在 Transformer 中,有三類多頭注意力層,它們的 mask 也不同。Encoder 的多頭注意力層的 query 和 key 都來自源語言;Decoder 的第一個多頭注意力層的 query 和 key 都來自目標語言;Decoder 的第二個多頭注意力層的 query 來自目標語言, key 來自源語言。另外,Decoder 的第一個多頭注意力層要加串行推理的那個 mask。按照上述描述生成mask即可。
def forward(self, x, y):src_pad_mask = x == self.pad_idxdst_pad_mask = y == self.pad_idxsrc_mask = self.generate_mask(src_pad_mask, src_pad_mask, False)dst_mask = self.generate_mask(dst_pad_mask, dst_pad_mask, True)src_dst_mask = self.generate_mask(dst_pad_mask, src_pad_mask, False)encoder_kv = self.encoder(x, src_mask)res = self.decoder(y, encoder_kv, dst_mask, src_dst_mask)res = self.output_layer(res)return res?
訓練
準備好了模型、數據集后,剩下的工作非常愜意,只要隨便調用一下就行了。訓練的代碼如下:
import torch
import torch.nn as nn
import timefrom dldemos.Transformer.data_load import (get_batch_indices, load_cn_vocab,load_en_vocab, load_train_data,maxlen)
from dldemos.Transformer.model import Transformer# Config
batch_size = 64
lr = 0.0001
d_model = 512
d_ff = 2048
n_layers = 6
heads = 8
dropout_rate = 0.2
n_epochs = 60
PAD_ID = 0def main():device = 'cuda'cn2idx, idx2cn = load_cn_vocab()en2idx, idx2en = load_en_vocab()# X: en# Y: cnY, X = load_train_data()print_interval = 100model = Transformer(len(en2idx), len(cn2idx), PAD_ID, d_model, d_ff,n_layers, heads, dropout_rate, maxlen)model.to(device)optimizer = torch.optim.Adam(model.parameters(), lr)citerion = nn.CrossEntropyLoss(ignore_index=PAD_ID)tic = time.time()cnter = 0for epoch in range(n_epochs):for index, _ in get_batch_indices(len(X), batch_size):x_batch = torch.LongTensor(X[index]).to(device)y_batch = torch.LongTensor(Y[index]).to(device)y_input = y_batch[:, :-1]y_label = y_batch[:, 1:]y_hat = model(x_batch, y_input)y_label_mask = y_label != PAD_IDpreds = torch.argmax(y_hat, -1)correct = preds == y_labelacc = torch.sum(y_label_mask * correct) / torch.sum(y_label_mask)n, seq_len = y_label.shapey_hat = torch.reshape(y_hat, (n * seq_len, -1))y_label = torch.reshape(y_label, (n * seq_len, ))loss = citerion(y_hat, y_label)optimizer.zero_grad()loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), 1)optimizer.step()if cnter % print_interval == 0:toc = time.time()interval = toc - ticminutes = int(interval // 60)seconds = int(interval % 60)print(f'{cnter:08d} {minutes:02d}:{seconds:02d}'f' loss: {loss.item()} acc: {acc.item()}')cnter += 1model_path = 'dldemos/Transformer/model.pth'torch.save(model.state_dict(), model_path)print(f'Model saved to {model_path}')if __name__ == '__main__':main()
所有的超參數都寫在代碼開頭。在模型結構上,我使用了和原論文一樣的超參數。
# Config
batch_size = 64
lr = 0.0001
d_model = 512
d_ff = 2048
n_layers = 6
heads = 8
dropout_rate = 0.2
n_epochs = 60
PAD_ID = 0
之后,進入主函數。一開始,我們調用load_data.py提供的API,獲取中英文序號到單詞的轉換詞典,并獲取已經打包好的訓練數據。
def main():device = 'cuda'cn2idx, idx2cn = load_cn_vocab()en2idx, idx2en = load_en_vocab()# X: en# Y: cnY, X = load_train_data()
接著,我們用參數初始化好要用到的對象,比如模型、優化器、損失函數。
print_interval = 100model = Transformer(len(en2idx), len(cn2idx), PAD_ID, d_model, d_ff,n_layers, heads, dropout_rate, maxlen)
model.to(device)optimizer = torch.optim.Adam(model.parameters(), lr)citerion = nn.CrossEntropyLoss(ignore_index=PAD_ID)
tic = time.time()
cnter = 0
再然后,進入訓練循環。我們從X, Y里取出源語言和目標語言的序號數組,輸入進模型里。別忘了,Transformer可以并行訓練。我們給模型輸入目標語言前n-1個單詞,用第2到第n個單詞作為監督標簽。
for epoch in range(n_epochs):for index, _ in get_batch_indices(len(X), batch_size):x_batch = torch.LongTensor(X[index]).to(device)y_batch = torch.LongTensor(Y[index]).to(device)y_input = y_batch[:, :-1]y_label = y_batch[:, 1:]y_hat = model(x_batch, y_input)
得到模型的預測y_hat后,我們可以把輸出概率分布中概率最大的那個單詞作為模型給出的預測單詞,算一個單詞預測準確率。當然,我們要排除掉<pad>的影響。
y_label_mask = y_label != PAD_ID
preds = torch.argmax(y_hat, -1)
correct = preds == y_label
acc = torch.sum(y_label_mask * correct) / torch.sum(y_label_mask)
我們最后算一下loss,并執行梯度下降,訓練代碼就寫完了。為了讓訓練更穩定,不出現梯度過大的情況,我們可以用torch.nn.utils.clip_grad_norm_(model.parameters(), 1)裁剪梯度。
n, seq_len = y_label.shape
y_hat = torch.reshape(y_hat, (n * seq_len, -1))
y_label = torch.reshape(y_label, (n * seq_len, ))
loss = citerion(y_hat, y_label)optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1)
optimizer.step()訓練結果

?
——基礎概念與查看方式)





)












