今天是端午節,端午安康!值此傳統佳節之際,我想和大家分享一篇關于基于大語言模型的時序預測算法——LLMTIME。隨著人工智能技術的飛速發展,利用大型預訓練語言模型(LLM)進行時間序列預測成為一個新興且極具潛力的研究方向。LLMTIME通過將數值數據轉化為文本格式,借助語言模型強大的模式學習能力,實現了對復雜時間序列的高效預測和不確定性建模。
接下來,我將深入對這篇論文展開全面解讀。和以往一樣,我會嚴格依照論文的結構框架,從研究背景、核心論點、實驗設計到最終結論,逐一對文章的各個關鍵部分進行細致剖析 ,力求為大家呈現這篇時間序列預測論文的全貌,挖掘其中的研究價值與創新點。
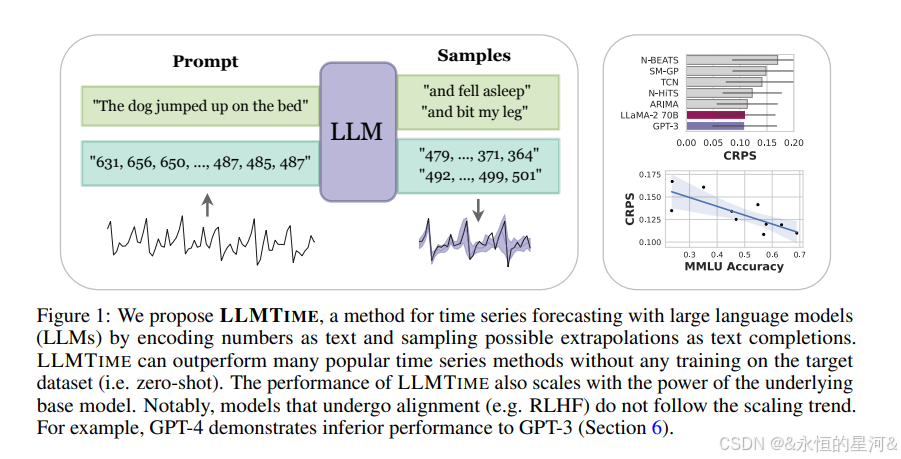
1. Abstract
通過將時間序列編碼為數字字符串,可以將時間序列預測重新表述為文本中的“下一個 token 預測”問題。在這一思路基礎上,本文發現大型語言模型(LLMs),如 GPT-3 和 LLaMA-2,竟然能夠在零樣本(zero-shot)條件下進行時間序列外推,其表現與為下游任務專門設計的時間序列模型相當,甚至更優。為了實現這種性能,提出了一些方法,用于有效地對時間序列數據進行 token 化,并將模型輸出的離散 token 分布轉化為對連續數值的高靈活度密度分布。作者認為,LLMs 在時間序列任務中取得成功,源于它們能夠自然表示多峰分布(multimodal distributions),以及它們在訓練中表現出的對簡潔性和重復性的偏好——這正與許多時間序列中的顯著特征(如周期性趨勢的重復)高度一致。作者還展示了 LLMs 如何無需插值就能自然地處理缺失數據(通過非數值文本進行處理),如何融合文本型輔助信息,以及如何通過問答形式解釋預測結果。雖然發現模型規模的增加通常會帶來時間序列任務性能的提升,但也觀察到 GPT-4 的表現可能低于 GPT-3,原因包括其對數字的 token 化方式不理想,以及其不佳的不確定性校準能力。這些問題可能是由于諸如強化學習人類反饋(RLHF)等對齊干預所造成的。
2.?Introduction
盡管與其他序列建模問題(如文本、音頻或視頻)存在相似之處,時間序列具有兩個特別具有挑戰性的屬性。與視頻或音頻通常具有一致的輸入尺度和采樣率不同,聚合的時間序列數據集通常包含來自截然不同來源的序列,有時還存在缺失值。此外,時間序列預測的常見應用,例如天氣或金融數據,需要從僅包含極少部分可能信息的觀測中進行外推,這使得準確的點預測幾乎不可能,而不確定性估計則尤為重要。盡管大規模預訓練已成為視覺和文本中訓練大型神經網絡的關鍵要素,使性能能夠直接隨著數據可用性擴展而提高,但在時間序列建模中通常并不使用預訓練,因為缺乏共識的無監督目標以及缺少大型、統一的預訓練數據集。因此,在一些流行的基準測試中,簡單的時
完整文章鏈接:LLMTIME: 不用微調!如何用大模型玩轉時間序列預測??





![每日c/c++題 備戰藍橋杯(P1204 [USACO1.2] 擠牛奶 Milking Cows)](http://pic.xiahunao.cn/每日c/c++題 備戰藍橋杯(P1204 [USACO1.2] 擠牛奶 Milking Cows))













