VIT與GPT 模型與語言生成:從 GPT-1 到 GPT4
本教程將介紹 GPT 系列模型的發展歷程、結構原理、訓練方式以及人類反饋強化學習(RLHF)對生成對齊的改進。內容涵蓋 GPT-1、GPT-2、GPT-3、GPT-3.5(InstructGPT)、ChatGPT 與 GPT-4,并簡要提及 Vision Transformer 的演化。
1. GPT 模型的原理
Transformer 架構中包含 Encoder 與 Decoder 兩部分。
- 如果我們只需要處理輸入(如 BERT),可以去掉 Decoder;
- 如果我們只生成輸出(如 GPT),可以只保留 Decoder。
GPT 是一種只使用 Transformer Decoder 堆疊結構的模型,其訓練目標是根據前文預測下一個詞,即語言建模任務:
給定前綴 { x 1 , x 2 , . . . , x t } \{x_1, x_2, ..., x_t\} {x1?,x2?,...,xt?},模型預測 x t + 1 x_{t+1} xt+1?。
2. GPT 與 ELMo/BERT 的比較
| 模型 | 參數量 | 架構 | 特點 |
|---|---|---|---|
| ELMo | 94M | 雙向 RNN | 上下文嵌入 |
| BERT | 340M | Transformer Encoder | 掩碼語言模型 + 下一句預測 |
| GPT | 可變(取決于版本) | Transformer Decoder | 自回歸語言模型 |
GPT 使用自回歸機制,一個詞一個詞地生成結果,適合生成任務。
3. GPT-1:生成式預訓練語言模型
GPT-1 的兩大創新:
- 利用海量無標注文本進行預訓練(語言建模);
- 對具體任務進行監督微調(分類、情感分析、蘊含等)。
這種預訓練 + 微調范式,開啟了 NLP 模型訓練的新方向。
預訓練目標是最大化:
log ? P ( t 1 , t 2 , . . . , t n ) = ∑ i = 1 n log ? P ( t i ∣ t 1 , . . . , t i ? 1 ) \log P(t_1, t_2, ..., t_n) = \sum_{i=1}^{n} \log P(t_i | t_1, ..., t_{i-1}) logP(t1?,t2?,...,tn?)=i=1∑n?logP(ti?∣t1?,...,ti?1?)
微調目標是最大化:
log ? P ( y ∣ x 1 , x 2 , . . . , x n ) \log P(y | x_1, x_2, ..., x_n) logP(y∣x1?,x2?,...,xn?)
其中 y y y 是標簽。
特定于任務的輸入轉換:為了在微調期間對模型的體系結構進行最小的更改,將特定下游任務的輸入轉換為有序序列
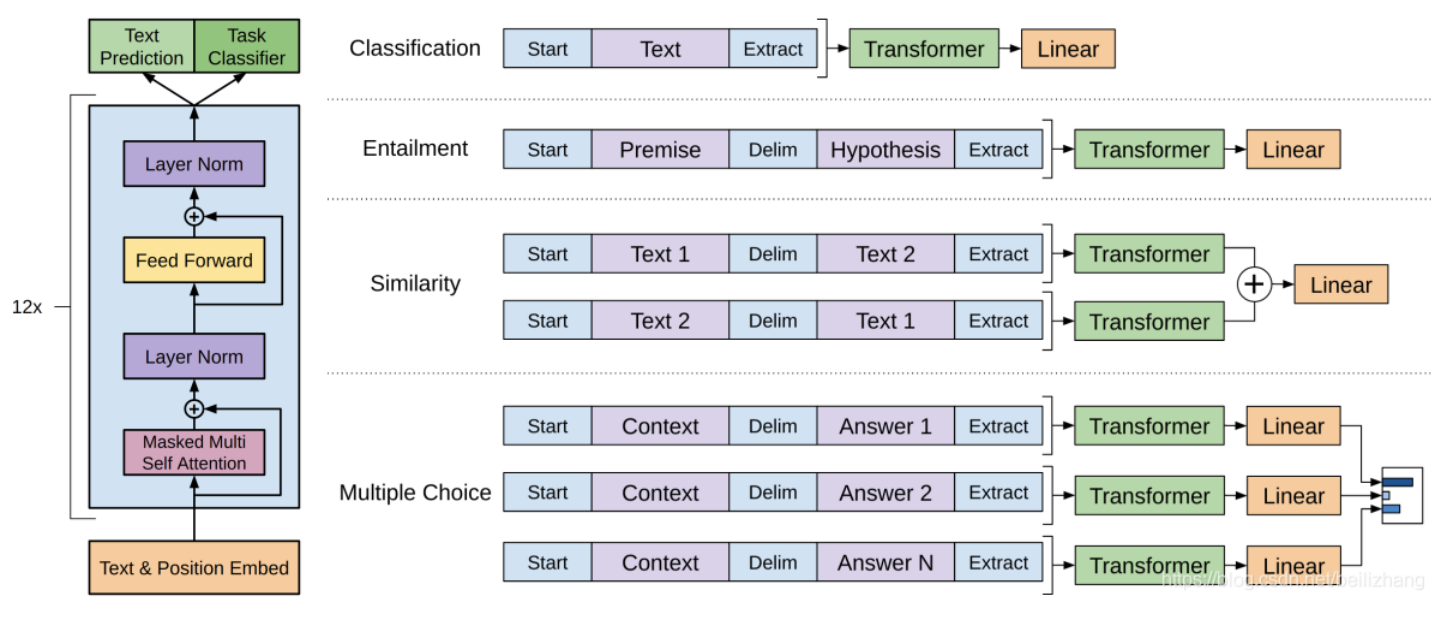
4. GPT-2:無監督多任務學習
GPT-2 擴展了 GPT-1:
- 更大的數據集(從 6GB 增長至 40GB);
- 更多的參數(117M → 1542M);
- 任務無需專門微調結構,只需修改輸入格式,即可處理不同任務。
這一版本提出了“語言模型是無監督的多任務學習者”這一重要觀點。
5. GPT-3:大規模語言模型與 Few-shot 能力
GPT-3 使用了 1750 億參數,訓練數據量達 45TB,計算資源非常龐大(28.5 萬 CPU,1 萬 GPU)。
其突破包括:
- 強大的 Few-shot / One-shot / Zero-shot 能力;
- 不再依賴下游微調,輸入任務示例即可生成高質量輸出。
其架構仍為標準 Transformer Decoder,無重大結構創新。
6. GPT-3.5 / InstructGPT:人類對齊
InstructGPT 引入了 人類反饋強化學習(RLHF),旨在讓模型更符合用戶意圖:
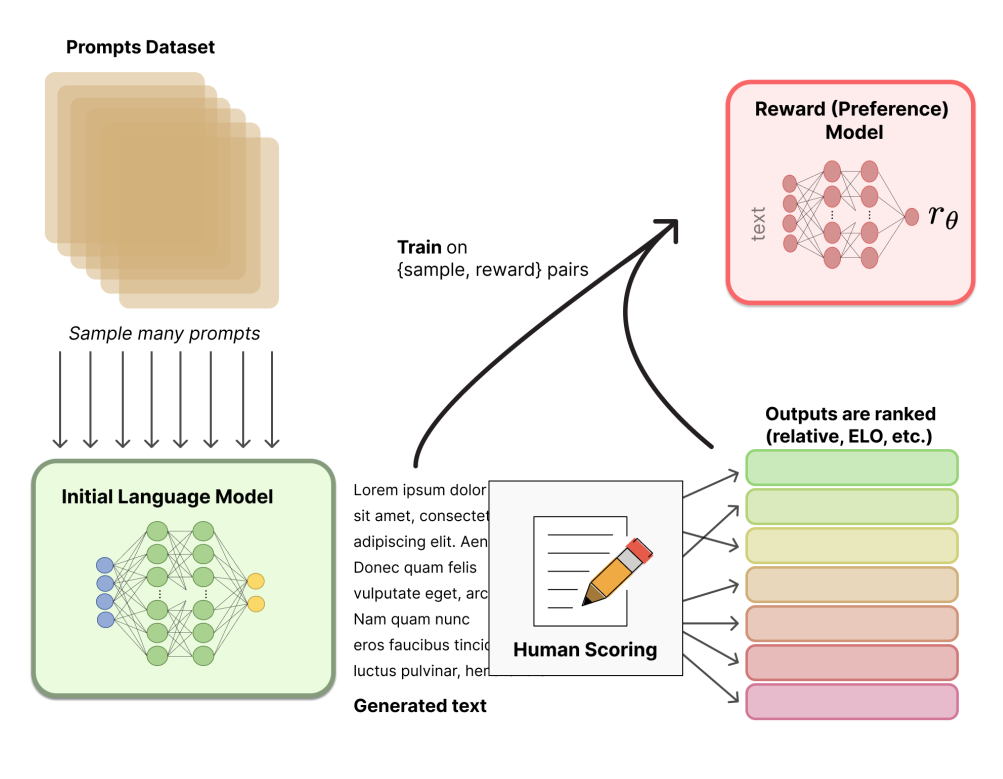
主要流程分為三階段:
-
語言模型預訓練(如 GPT-3);
RLHF一般使用預訓練的LMs作為起點(例如,使用GPT-3)
這些預訓練的模型可以根據額外的文本或條件進行微調,但這并不總是必要的。(人類增強文本可以用來調整人類的偏好)
-
獎勵模型訓練(由人工標注生成輸出的排序);
Gathering data and training a Reward Model (RM)
- RLHF中的RM:接受文本序列并返回代表人類偏好的標量獎勵
- RM的訓練集:通過對提示進行采樣并將其傳遞給初始LM以生成新文本,然后由人工注釋器對其進行排序。
- 注意:標注對LM的輸出進行排序,而不是直接給它們打分。
-
通過強化學習優化模型(使用 PPO 算法)。
-
示例提示
-
通過初始LM和RL策略(初始LM的副本)傳遞它
-
將策略的輸出傳遞給RM來計算獎勵,并使用初始LM和策略的輸出來計算移位懲罰
-
采用獎懲結合的方式,通過PPO (Proximal policy)更新
-
結果是模型更加安全、有用且真實。
7. ChatGPT:對話能力與人類協作訓練
ChatGPT 是 InstructGPT 的“對話版”,與用戶進行多輪交流。
其訓練包括:
- 初始監督微調:AI 教練扮演用戶和助手角色生成對話;
- 獎勵模型訓練:對話中多個回復由 AI 教練排序評分;
- 最終強化學習:使用 PPO 方法優化回復。
它與 GPT-3.5 共享核心技術,但訓練數據格式專為對話優化。
ChatGPT 的訓練概述
ChatGPT 是 InstructGPT 的“兄弟模型”,主要目標是理解提示并生成詳細回復。兩者使用相同的 RLHF 方法,但 數據構造方式略有不同。
ChatGPT 的訓練數據分兩部分:
① 初始監督微調數據(Supervised Fine-tuning)
-
訓練師(AI Trainers)模擬對話角色:
“The trainers acted as both users and AI assistants…”
即,訓練師扮演用戶與助手兩個角色,人工構造對話數據集。
-
參考模型生成建議(model-written suggestions)**:
幫助訓練師撰寫回復,提高效率。 -
InstructGPT 數據集也被轉換為對話格式并混入**新數據集中。
② 獎勵模型數據(Reward Model,比較排序數據)
-
從 AI 訓練師與模型的對話中提取**:
“Took conversations that AI trainers had with the chatbot”
-
隨機抽取模型生成的回答**,訓練師對多個候選答案進行排序打分,構成獎勵數據。
總結:ChatGPT 相比 InstructGPT 的不同點
| 階段 | InstructGPT | ChatGPT |
|---|---|---|
| 微調數據 | 任務式指令對 | 多輪對話,訓練師模擬雙方 |
| 獎勵數據 | 人類寫的參考回復 | 人類對多輪對話排序打分 |
8. GPT-4:多模態與推理能力提升
GPT-4 相較于 GPT-3.5 主要提升:
- 更強的創造力與推理能力;
- 多模態輸入(文本+圖像);
- 更長的上下文處理能力(約 25,000 字);
- 在專業考試中達到人類水平。
其方法未完全公開,但大體基于 ChatGPT 和 InstructGPT 技術演進。
9. Emergent Ability 與 CoT
Emergent Ability(涌現能力) 是指模型規模達到一定程度后,出現新的、未顯式訓練出的能力。
突發能力是指模型從原始訓練數據中自動學習和發現新的高級特征和模式的能力。
Chain of Thought(CoT) 是一種通過 prompt 引導模型“逐步推理”的技巧,可大幅提升邏輯與數學任務表現。
生成思維鏈(一系列中間推理步驟)可以顯著提高llm執行復雜推理的能力
10. Prompt Engineering 簡介
Prompt 工程是通過設計輸入提示來提升 LLM 輸出質量的方法。
一個好的 Prompt 通常包含:
- 角色設定(如你是老師);
- 場景背景(如我們在深度學習課堂);
- 明確指令(解釋 prompt engineering);
- 響應風格(應通俗易懂)。
常見方法包括:
- Chain of Thought;
- Self-consistency;
- Knowledge prompt 等。
11. GPT 系列演化總結
| 模型 | 技術路線 | 特點 |
|---|---|---|
| GPT-1 | 預訓練 + 微調 | 引入生成式語言模型思想 |
| GPT-2 | 更大模型 | Few-shot、多任務泛化能力 |
| GPT-3 | 巨量參數 | 零樣本/少樣本遷移能力 |
| GPT-3.5 | RLHF | 對齊人類意圖 |
| ChatGPT | 對話優化 | 多輪對話、任務跟蹤 |
| GPT-4 | 多模態 + 長上下文 | 強邏輯推理、創造力 |
12. 未來方向:多模態與通用智能
未來的發展趨勢將包括:
- 更強的多模態處理能力(語言 + 圖像 + 音頻);
- 更長文本記憶;
- 與人類交互更自然的代理;
- 融合強化學習、知識圖譜等異構技術;
- 向通用人工智能(AGI)邁進。
GPT 是這一進化路線上的關鍵步驟。
13. Vision Transformer 的動機與背景
傳統 CNN 利用局部感受野和共享權重處理圖像,但難以建模全局依賴。
Transformer 本是為 NLP 設計,但其強大的全局建模能力被引入圖像領域,催生了 Vision Transformer (ViT)。
核心觀點:將圖像切成 Patch,類比 NLP 中的 token,再用 Transformer 編碼序列。
ViT 不再依賴卷積結構,是一種純基于 Transformer 的視覺模型。
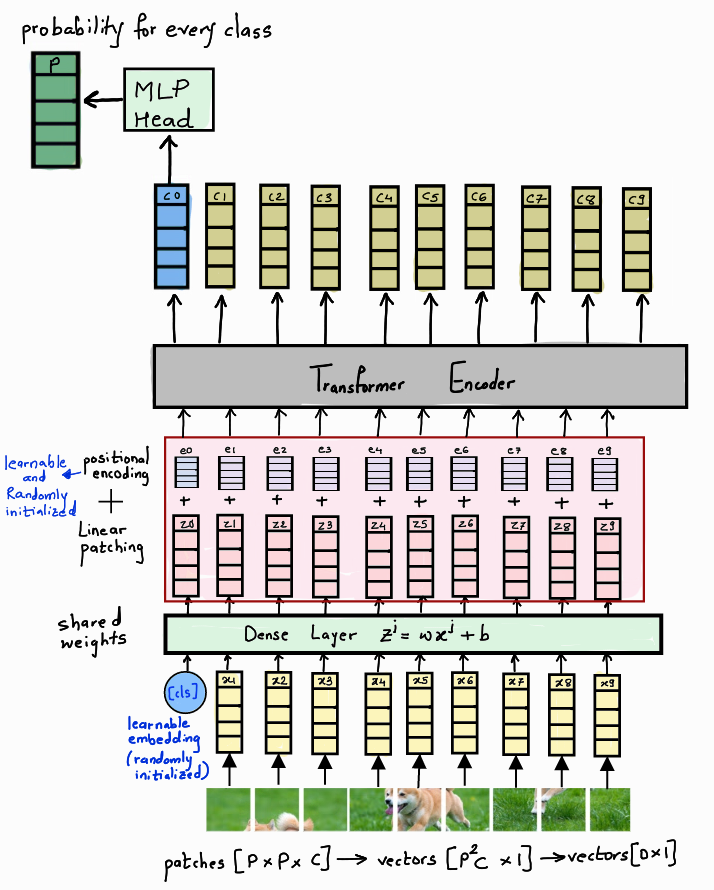
14. Vision Transformer 的核心構成(圖像 → patch → 向量序列)
ViT 輸入處理流程如下:
- 輸入圖像大小為 H × W × C H \times W \times C H×W×C;
- 將圖像劃分為 N N N 個 Patch,每個 Patch 為 P × P P \times P P×P;
- 展平每個 Patch 為長度為 P 2 ? C P^2 \cdot C P2?C 的向量;
- 每個 Patch 映射為 D D D 維表示(通過全連接);
- 加入可學習的位置編碼;
- 在序列前添加一個
[CLS]token,作為圖像的全局表示; - 輸入標準 Transformer Encoder。
最終分類結果由 [CLS] token 表示。
15. 多頭注意力在 ViT 中的作用
與 NLP 中一樣,ViT 中每個 token 都會計算 Query、Key、Value:
Q = X W Q , K = X W K , V = X W V Q = XW_Q,\quad K = XW_K,\quad V = XW_V Q=XWQ?,K=XWK?,V=XWV?
然后進行多頭注意力(Multi-Head Attention):
Attention ( Q , K , V ) = softmax ( Q K T d ) V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d}} \right) V Attention(Q,K,V)=softmax(d?QKT?)V
多個頭并行計算后拼接,再映射到原始維度:
MultiHead ( X ) = Concat ( head 1 , . . . , head h ) W O \text{MultiHead}(X) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W_O MultiHead(X)=Concat(head1?,...,headh?)WO?
注意力機制使模型可以捕捉圖像各區域之間的長距離依賴。
16. 位置編碼在 ViT 中的關鍵性
因為 Transformer 本身對輸入順序不敏感,ViT 必須引入 位置編碼(Positional Encoding) 以告知 patch 的相對或絕對位置信息。
在 ViT 原始論文中,位置編碼是 可學習的向量,維度與 patch 向量一致。
ViT 輸入為:
z 0 = [ x class ; x p 1 ; x p 2 ; … ; x p N ] + E pos z_0 = [x_{\text{class}}; x_p^1; x_p^2; \dots; x_p^N] + E_{\text{pos}} z0?=[xclass?;xp1?;xp2?;…;xpN?]+Epos?
其中 x p i x_p^i xpi? 表示第 i i i 個 patch 的向量表示, E pos E_{\text{pos}} Epos? 是位置嵌入。
17. 類比 NLP 模型:ViT 與 BERT 輸入結構對照
ViT 完全借鑒了 BERT 的編碼形式:
- 使用
[CLS]token 獲取圖像全局信息; - patch 類比為 token;
- 添加位置編碼。
| 模型 | 輸入單位 | [CLS] | 位置編碼 | Transformer 層 |
|---|---|---|---|---|
| BERT | token | 是 | 有 | Encoder Stack |
| ViT | patch | 是 | 有 | Encoder Stack |
因此,ViT 可視為一種圖像版本的 BERT。
18. ViT 應用于圖像分類任務(Encoder-only 模型)
ViT 的應用以圖像分類為代表性任務。
其完整流程:
- 圖像 → Patch → 向量序列;
- 加入位置編碼;
- 輸入多層 Transformer Encoder;
- 提取
[CLS]輸出向量; - 使用全連接層進行分類預測。
ViT 是 Encoder-only 模型,不包含 Decoder,與 BERT 類似。
19. ViT 模型的訓練策略與挑戰
訓練 ViT 時的挑戰:
-
數據依賴性強,若使用小數據集(如 CIFAR-10),效果不如 CNN;
在JFT大數據集上才能略微強過ResNet
-
訓練時間長,對正則化要求高;
-
無歸納偏置(不像 CNN 有平移不變性等先驗),導致訓練初期收斂慢。
解決方法包括:
- 使用 大規模預訓練(如 ImageNet-21k);
- 引入 混合訓練策略(如 Token Labeling、MixToken);
- 結合 CNN 結構(Hybrid ViT)。
20. 總結:ViT 與 GPT 的共同趨勢
ViT 和 GPT 雖應用領域不同,但都體現了 Transformer 的優勢:
- 使用統一的序列建模結構;
- 可用于多種下游任務(分類、生成、匹配);
- 都展現出隨著模型規模擴大,性能提升的趨勢;
- 需要大量數據與計算支持;
- 都引發了通用 AI 架構探索的熱潮。
ViT 的出現標志著 Transformer 正式從 NLP 擴展至視覺領域,推動了多模態融合的發展。


)





)

缺省的運行時組件檢視器)







)
