系列文章目錄
文章目錄
- 系列文章目錄
- 前言
- 特征圖和注意力圖的尺寸差異原因
- 在Break-a-Scene中的具體實現
- 總結
前言
特征圖 (Latent) 尺寸和注意力圖(attention map)尺寸在擴散模型中有差異,是由于模型架構和注意力機制的特性決定的。
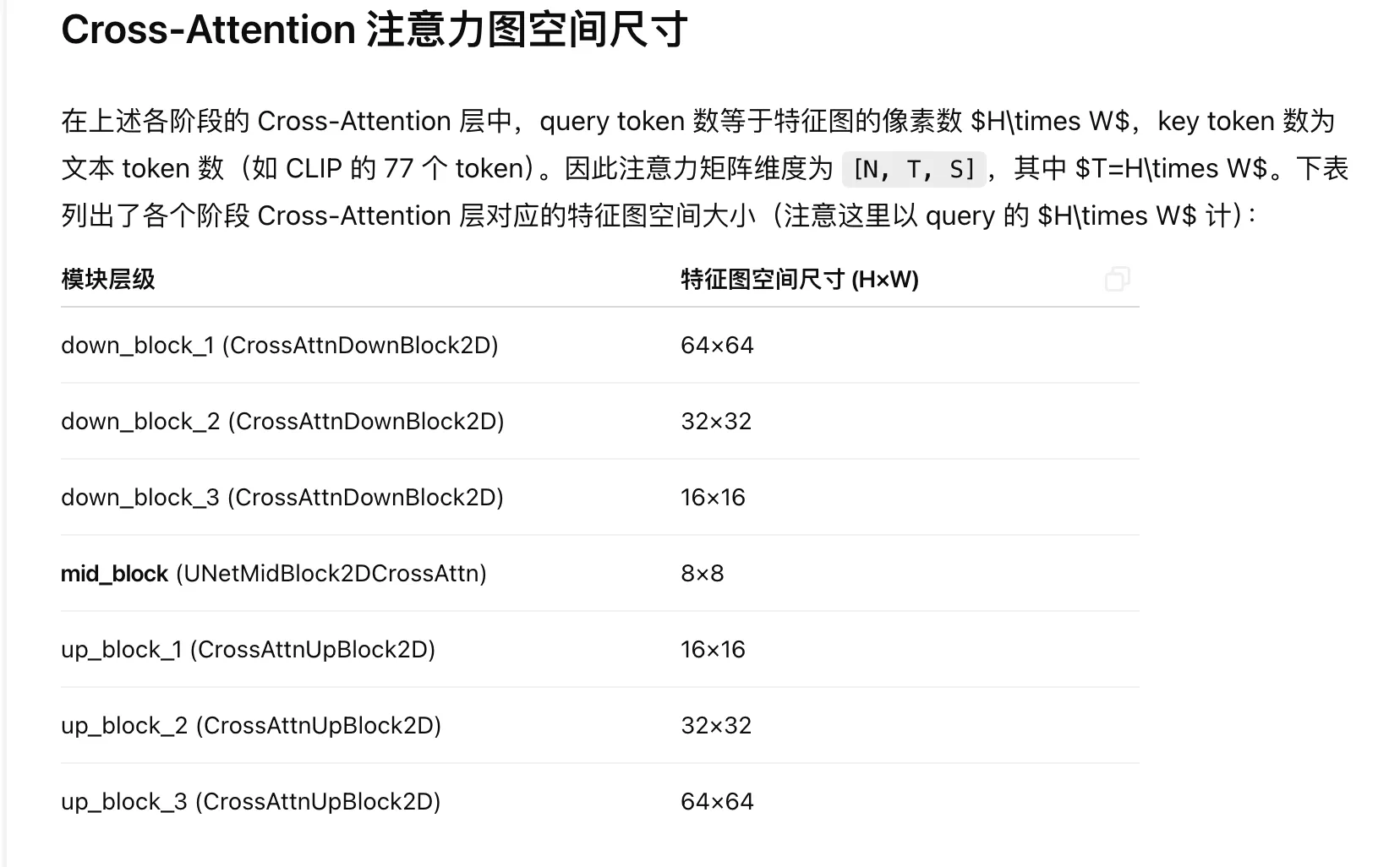
特征圖和注意力圖的尺寸差異原因
-
不同的功能目的
- 特征圖(Feature Maps):承載圖像的語義和視覺特征,維持空間結構
- 注意力圖(Attention Maps):表示不同位置之間的關聯強度,是一種關系矩陣
-
UNet架構中的特征圖尺寸
在U-Net中,特征圖的尺寸在不同層級有變化:- 輸入圖像通常是 512×512 或 256×256
- 下采樣路徑(Encoder):尺寸逐漸縮小 (512→256→128→64→32→16…)
- 上采樣路徑(Decoder):尺寸逐漸增大 (16→32→64→128→256→512…)
在Break-a-Scene代碼中,我們看到特征圖尺寸被下采樣到64×64:
downsampled_mask = F.interpolate(input=max_masks, size=(64, 64)) -
注意力機制中的尺寸計算
注意力機制處理的是"token"之間的關系,其中:- 自注意力(Self-Attention):特征圖中的每個位置視為一個token
- 交叉注意力(Cross-Attention):文本序列中的token與特征圖中的位置建立關聯
如果特征圖尺寸是h×w,則自注意力矩陣的尺寸是(hw)×(hw),這是一個平方關系
在代碼中,注意力圖通常被下采樣到16×16:
GT_masks = F.interpolate(input=batch["instance_masks"][batch_idx], size=(16, 16)) -
計算效率考慮
- 注意力計算的復雜度是O(n2),其中n是token數量
- 對于64×64的特征圖,如果直接計算自注意力,需要處理4096×4096的矩陣
- 為了降低計算量,通常在較低分辨率(如16×16)的特征圖上計算注意力,這樣只需處理256×256的矩陣
在Break-a-Scene中的具體實現
在Break-a-Scene中,這些尺寸差異體現在:
-
兩種不同的損失計算:
a. 掩碼損失(Masked Loss):應用在64×64的 Latent 上
max_masks = torch.max(batch["instance_masks"], axis=1).values downsampled_mask = F.interpolate(input=max_masks, size=(64, 64)) model_pred = model_pred * downsampled_mask target = target * downsampled_maskb. 注意力損失(Attention Loss):應用在16×16的注意力圖上
GT_masks = F.interpolate(input=batch["instance_masks"][batch_idx], size=(16, 16)) agg_attn = self.aggregate_attention(res=16, from_where=("up", "down"), is_cross=True, select=batch_idx) -
注意力存儲的篩選:
在存儲注意力圖時,只保留小尺寸的注意力圖:
def forward(self, attn, is_cross: bool, place_in_unet: str):key = f"{place_in_unet}_{'cross' if is_cross else 'self'}"if attn.shape[1] <= 32**2: # 只保存小于或等于32×32的注意力圖self.step_store[key].append(attn)return attn -
注意力聚合:
在聚合不同層的注意力時,確保只使用匹配目標分辨率的注意力圖:
def aggregate_attention(self, res: int, from_where: List[str], is_cross: bool, select: int):# ...num_pixels = res**2for location in from_where:for item in attention_maps[f"{location}_{'cross' if is_cross else 'self'}"]:if item.shape[1] == num_pixels: # 只選擇匹配分辨率的注意力圖cross_maps = item.reshape(self.args.train_batch_size, -1, res, res, item.shape[-1])[select]out.append(cross_maps)# ...
總結
特征圖和注意力圖尺寸的差異主要是因為:
- 它們在模型中的功能不同
- 注意力計算的計算復雜度要求在較低分辨率上進行
- UNet架構中的不同層級有不同的特征圖尺寸
- 為了平衡精度和計算效率,Break-a-Scene使用不同分辨率的特征圖和注意力圖來計算不同類型的損失
這種設計使得Break-a-Scene能夠有效地學習token與圖像區域之間的對應關系,同時保持計算效率。



)




 的潛在風險與安全使用指南)





)


Java/python/JavaScript/C/C++/GO最佳實現)

)