校招面試經常會問大家有沒有過調優的經驗,相信大家的回答基本都是往數據傾斜和小文件問題這兩方面回答,對于數據傾斜相信大部分同學對熱key打散或null值引發的傾斜已經非常熟悉,但這些內容面試官也是聽膩了,希望大家在面試時候講一些高大尚的案例,在描述的時候一定要有背景,有解決方案,最后結果,畢竟數據傾斜不會無故產生,一定是有業務背景的,這里給大家分享一種數據傾斜優化案例。

1.Uid和oaid之間的轉化
在用增的拉新拉回業務中,經常會用到oaid來識別具體的設備是不是公司用戶,所以我們需要將uid→oaid,需求目的:找到當日拉新的uid對應的oaid映射關系
代碼如下:
-
1.從id mapping表中找出uid→oaid的映射關系;
-
2.根據最后一次活躍時間對uid→oaid映射關系去重;
-
3.將算法提供的uid人群圈選出對應的oaid。
原來的sql
selectt1.user_id,oaid_md5
from(selectL.uid user_id,md5(L.oaid) oaid_md5from(selectdistinct uid,oaidfrom(selectuid,oaid,row_number() over (partition by oaidorder bycast(last_active_timestamp as bigint) desc) as rnfromidmapping as GwhereG.p_date =?'20250324'and G.left_type =?'USER_ID'and G.right_type =?'OAID') ttwherett.rn = 1) as Lleft join (selectidfromzuobishebei -- 作弊設備wherep_date =?'{{ds_nodash}}'and supplier =?'cheat') as P on (md5(L.oaid) = P.id)whereP.id is null) t2join (SELECTuser_idFROMlist_ground_truthWHEREp_date =?'20250324') t1 on t1.user_id = t2.user_id
粗略一看,符合正常計算流程和順序,但這段sql出現了明顯的數據傾斜。
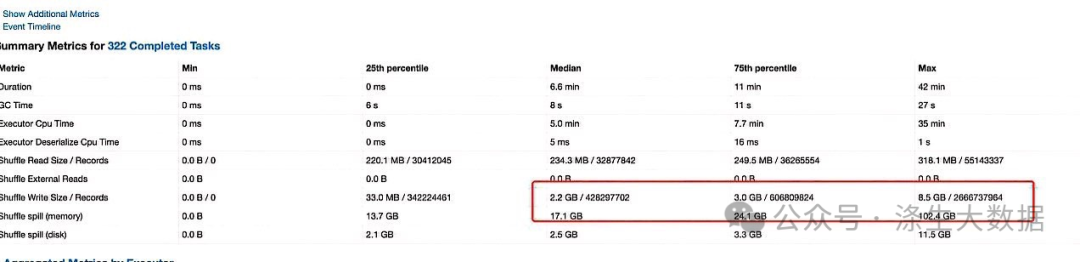
經過排查代碼中有兩塊可能引起傾斜,一個是join,一個row number,先查詢一下uid→oaid映射情況,發現部分的uid映射過10億多的oaid,導致在去重的時候發生了數據傾斜。
解決方案
-
1.使用過濾條件和分組操作減少數據量;
-
2.通過調整連接順序和提前應用過濾條件,減少了中間數據量;
-
3.如果傾斜仍然存在,考慮對傾斜字段進行分區或使用 broadcast join 來進一步優化。
優化后:
SELECTuser_id,md5(paid) AS oaid
FROM(SELECTuser_id,paid,ROW_NUMBER() OVER (PARTITION BY user_idORDER BYCAST(last_active_timestamp AS BIGINT) DESC) AS rnFROM(SELECTt1.user_id,t2.paid,t2.last_active_timestampFROM(SELECTuser_idFROMlist_ground_truthWHEREp_date =?'20250324') t1JOIN (SELECTuid,oaid,G.last_active_timestampFROMidmappingGWHEREG.p_date =?'20250324'AND G.left_type =?'USER_ID'AND G.right_type = ‘ OAID ’GROUP BYG.left_value,G.right_value,G.last_active_timestamp) t2 ON t1.user_id = t2.uid) t3) t1
WHERErn = 1
原始腳本和優化后的腳本在邏輯上保持一致,但重點在于先jion較小的表(idmapping和 list_ground_truth),在進行row number,這樣可以在join時先走map join同時減少row number執行的數據量。


)



![[yolov11改進系列]基于yolov11引入自注意力與卷積混合模塊ACmix提高FPS+檢測效率python源碼+訓練源碼](http://pic.xiahunao.cn/[yolov11改進系列]基于yolov11引入自注意力與卷積混合模塊ACmix提高FPS+檢測效率python源碼+訓練源碼)
![[DS]使用 Python 庫中自帶的數據集來實現上述 50 個數據分析和數據可視化程序的示例代碼](http://pic.xiahunao.cn/[DS]使用 Python 庫中自帶的數據集來實現上述 50 個數據分析和數據可視化程序的示例代碼)




)






