[ACmix的框架原理]


1.1 ACMix的基本原理
ACmix是一種混合模型,結合了自注意力機制和卷積運算的優勢。它的核心思想是,傳統卷積操作和自注意力模塊的大部分計算都可以通過1x1的卷積來實現。ACmix首先使用1x1卷積對輸入特征圖進行投影,生成一組中間特征,然后根據不同的范式,即自注意力和卷積方式,分別重用和聚合這些中間特征。這樣,ACmix既能利用自注意力的全局感知能力,又能通過卷積捕獲局部特征,從而在保持較低計算成本的同時,提高模型的性能。
ACmix模型的主要改進機制可以分為以下兩點:
1. 自注意力和卷積的整合:將自注意力和卷積技術融合,實現兩者優勢的結合。 2. 運算分解與重構:通過分解自注意力和卷積中的運算,重構為1×1卷積形式,提高了運算效率。
1.1.1 自注意力和卷積的整合
文章中指出,自注意力和卷積的整合通過以下方式實現:
特征分解:自注意力機制的查詢(query)、鍵(key)、值(value)與卷積操作通過1x1卷積進行特征分解。?運算共享:卷積和自注意力共享相同的1x1卷積運算,減少了重復的計算量。?特征融合:在ACmix模型中,卷積和自注意力生成的特征通過求和操作進行融合,加強了模型的特征提取能力。?模塊化設計:通過模塊化設計,ACmix可以靈活地嵌入到不同的網絡結構中,增強網絡的表征能力。
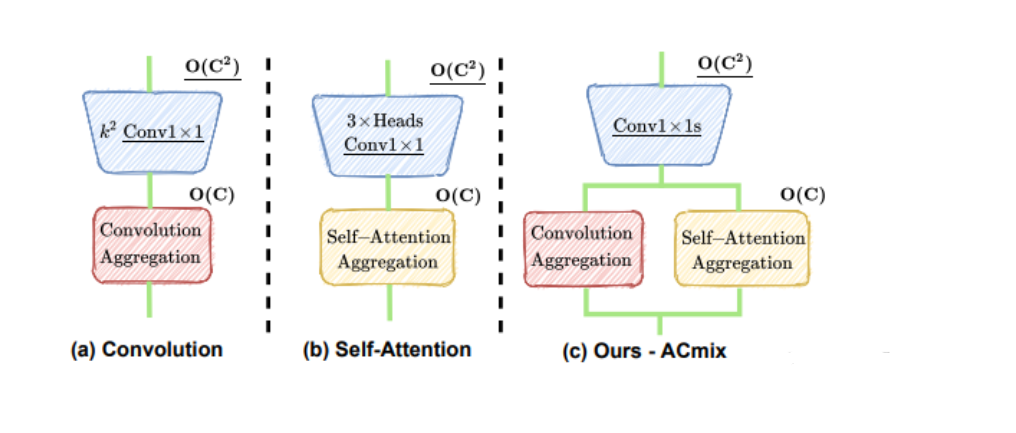
這張圖片展示了ACmix中的主要概念,它比較了卷積、自注意力和ACmix各自的結構和計算復雜度。圖中:
(a) 卷積:展示了標準卷積操作,包含一個
![]()
的1x1卷積,表示卷積核大小和卷積操作的聚合。
(b) 自注意力:展示了自注意力機制,它包含三個頭部的1x1卷積,代表多頭注意力機制中每個頭部的線性變換,以及自注意力聚合。
(c) ACmix(我們的方法):結合了卷積和自注意力聚合,其中1x1卷積在兩者之間共享,旨在減少計算開銷并整合輕量級的聚合操作。
整體上,ACmix旨在通過共享計算資源(1x1卷積)并結合兩種不同的聚合操作,以優化特征通道上的計算復雜度。
1.1.2 運算分解與重構
在ACmix中,運算分解與重構的概念是指將傳統的卷積運算和自注意力運算拆分,并重新構建為更高效的形式。這主要通過以下步驟實現:
分解卷積和自注意力:將標準的卷積核分解成多個1×1卷積核,每個核處理不同的特征子集,同時將自注意力機制中的查詢(query)、鍵(key)和值(value)的生成也轉換為1×1卷積操作。?重構為混合模塊:將分解后的卷積和自注意力運算重構成一個統一的混合模塊,既包含了卷積的空間特征提取能力,也融入了自注意力的全局信息聚合功能。?提高運算效率:這種分解與重構的方法減少了冗余計算,提高了運算效率,同時降低了模型的復雜度。
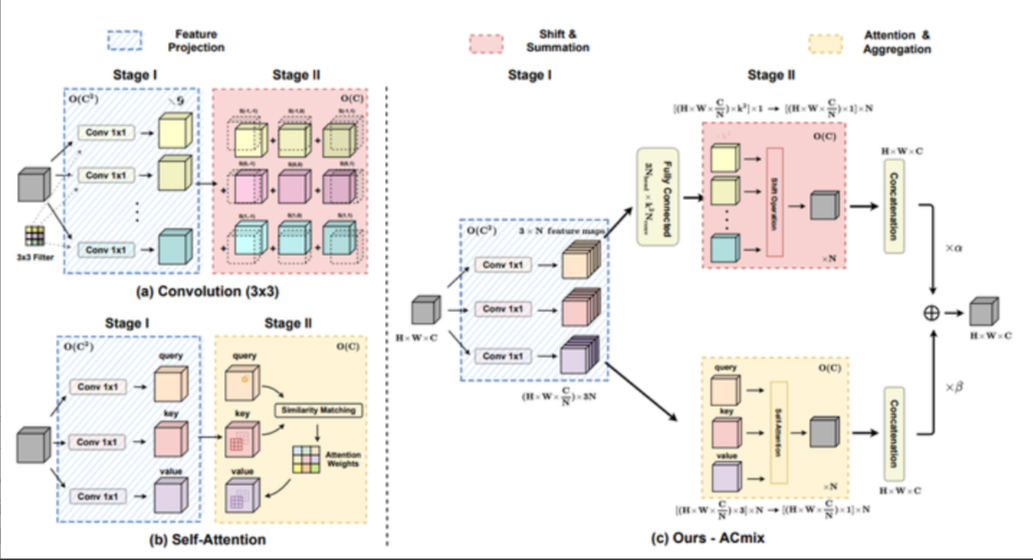
這張圖片展示了ACmix提出的混合模塊的結構。圖示包含了:
(a) 卷積:3x3卷積通過1x1卷積的方式被分解,展示了特征圖的轉換過程。
(b)自注意力:輸入特征先轉換成查詢(query)、鍵(key)和值(value),使用1x1卷積實現,并通過相似度匹配計算注意力權重。
(c) ACmix:結合了(a)和(b)的特點,在第一階段使用三個1x1卷積對輸入特征圖進行投影,在第二階段將兩種路徑得到的特征相加,作為最終輸出。
右圖顯示了ACmix模塊的流程,強調了兩種機制的融合并提供了每個操作塊的計算復雜度。
【yolov11框架介紹】
2024 年 9 月 30 日,Ultralytics 在其活動 YOLOVision 中正式發布了 YOLOv11。YOLOv11 是 YOLO 的最新版本,由美國和西班牙的 Ultralytics 團隊開發。YOLO 是一種用于基于圖像的人工智能的計算機模
Ultralytics YOLO11 概述
YOLO11 是Ultralytics YOLO 系列實時物體檢測器的最新版本,以尖端的精度、速度和效率重新定義了可能性。基于先前 YOLO 版本的令人印象深刻的進步,YOLO11 在架構和訓練方法方面引入了重大改進,使其成為各種計算機視覺任務的多功能選擇。
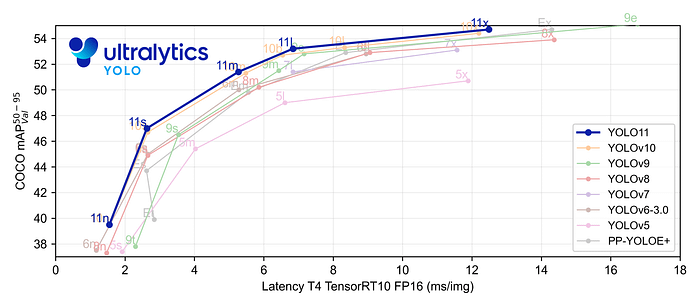
Key Features 主要特點
- 增強的特征提取:YOLO11采用改進的主干和頸部架構,增強了特征提取能力,以實現更精確的目標檢測和復雜任務性能。
- 針對效率和速度進行優化:YOLO11 引入了精致的架構設計和優化的訓練管道,提供更快的處理速度并保持準確性和性能之間的最佳平衡。
- 使用更少的參數獲得更高的精度:隨著模型設計的進步,YOLO11m 在 COCO 數據集上實現了更高的平均精度(mAP),同時使用的參數比 YOLOv8m 少 22%,從而在不影響精度的情況下提高計算效率。
- 跨環境適應性:YOLO11可以無縫部署在各種環境中,包括邊緣設備、云平臺以及支持NVIDIA GPU的系統,確保最大的靈活性。
- 支持的任務范圍廣泛:無論是對象檢測、實例分割、圖像分類、姿態估計還是定向對象檢測 (OBB),YOLO11 旨在應對各種計算機視覺挑戰。
 ?
?
與之前的版本相比,Ultralytics YOLO11 有哪些關鍵改進?
Ultralytics YOLO11 與其前身相比引入了多項重大進步。主要改進包括:
- 增強的特征提取:YOLO11采用改進的主干和頸部架構,增強了特征提取能力,以實現更精確的目標檢測。
- 優化的效率和速度:精細的架構設計和優化的訓練管道可提供更快的處理速度,同時保持準確性和性能之間的平衡。
- 使用更少的參數獲得更高的精度:YOLO11m 在 COCO 數據集上實現了更高的平均精度(mAP),參數比 YOLOv8m 少 22%,從而在不影響精度的情況下提高計算效率。
- 跨環境適應性:YOLO11可以跨各種環境部署,包括邊緣設備、云平臺和支持NVIDIA GPU的系統。
- 支持的任務范圍廣泛:YOLO11 支持多種計算機視覺任務,例如對象檢測、實例分割、圖像分類、姿態估計和定向對象檢測 (OBB)
【測試環境】
windows10 x64
ultralytics==8.3.0
torch==2.3.1
【改進流程】
1. 新增ACmix.py實現骨干網絡(代碼太多,核心模塊源碼請參考改進步驟.docx)
2. 文件修改步驟
修改tasks.py文件
創建模型配置文件
yolo11-ACmix.yaml內容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, ACmix, []] # 17 (P3/8-small) 小目標檢測層輸出位置增加注意力機制- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)- [-1, 1, ACmix, []] # 21 (P4/16-medium) 中目標檢測層輸出位置增加注意力機制- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 24 (P5/32-large)- [-1, 1, ACmix, []] # 25 (P5/32-large) 大目標檢測層輸出位置增加注意力機制# 注意力機制我這里其實是添加了三個但是實際一般生效就只添加一個就可以了,所以大家可以自行注釋來嘗試, 上面三個僅建議大家保留一個, 但是from位置要對齊.# 具體在那一層用注意力機制可以根據自己的數據集場景進行選擇。# 如果你自己配置注意力位置注意from[17, 21, 25]位置要對應上對應的檢測層!- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)3. 驗證集成
使用新建的yaml配置文件啟動訓練任務:
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('yolo11-ACmix.yaml') ?# build from YAML and transfer weights# Train the modelresults = model.train(data='coco128.yaml',epochs=100, imgsz=640, batch=8, device=0, workers=1, save=True,resume=False)成功集成后,訓練日志中將顯示ACmix模塊的初始化信息,表明已正確加載到模型中。
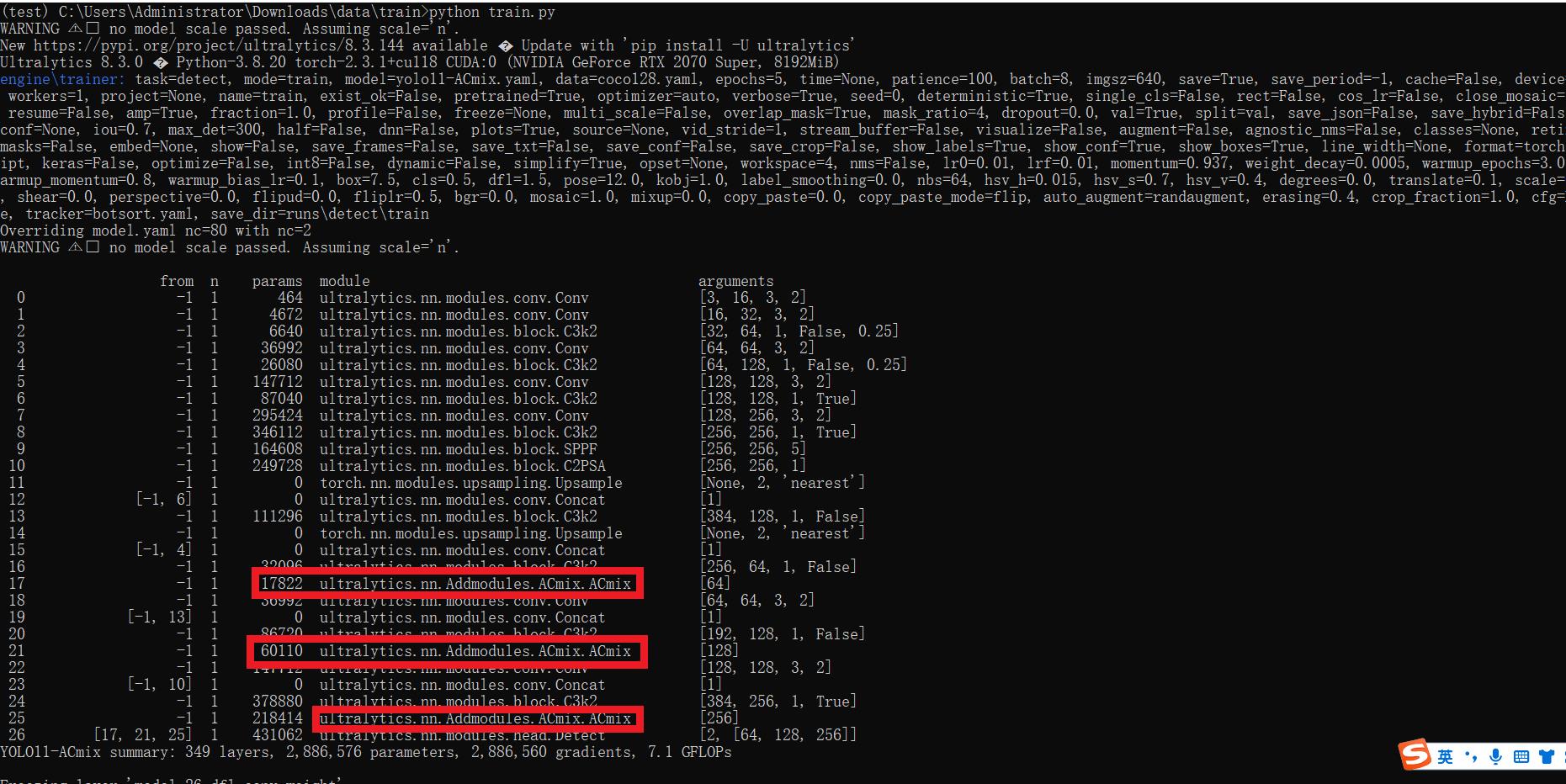
【訓練說明】
第一步:首先安裝好yolov11必要模塊,可以參考yolov11框架安裝流程,然后卸載官方版本pip uninstall ultralytics,最后安裝改進的源碼pip install .
第二步:將自己數據集按照dataset文件夾擺放,要求文件夾名字都不要改變
第三步:分別打開train.py,coco128.yaml和模型參數yaml文件修改必要的參數,最后執行python train.py即可訓練
【提供文件】
├── [官方源碼]ultralytics-8.3.0.zip
├── train/
│ ├── coco128.yaml
│ ├── dataset/
│ │ ├── train/
│ │ │ ├── images/
│ │ │ │ ├── firc_pic_1.jpg
│ │ │ │ ├── firc_pic_10.jpg
│ │ │ │ ├── firc_pic_11.jpg
│ │ │ │ ├── firc_pic_12.jpg
│ │ │ │ ├── firc_pic_13.jpg
│ │ │ ├── labels/
│ │ │ │ ├── classes.txt
│ │ │ │ ├── firc_pic_1.txt
│ │ │ │ ├── firc_pic_10.txt
│ │ │ │ ├── firc_pic_11.txt
│ │ │ │ ├── firc_pic_12.txt
│ │ │ │ ├── firc_pic_13.txt
│ │ └── val/
│ │ ├── images/
│ │ │ ├── firc_pic_100.jpg
│ │ │ ├── firc_pic_81.jpg
│ │ │ ├── firc_pic_82.jpg
│ │ │ ├── firc_pic_83.jpg
│ │ │ ├── firc_pic_84.jpg
│ │ ├── labels/
│ │ │ ├── firc_pic_100.txt
│ │ │ ├── firc_pic_81.txt
│ │ │ ├── firc_pic_82.txt
│ │ │ ├── firc_pic_83.txt
│ │ │ ├── firc_pic_84.txt
│ ├── train.py
│ ├── yolo11-ACmix.yaml
│ └── 訓練說明.txt
├── [改進源碼]ultralytics-8.3.0.zip
├── 改進原理.docx
└── 改進流程.docx?【常見問題匯總】
問:為什么我訓練的模型epoch顯示的map都是0或者map精度很低?
回答:由于源碼改進過,因此不能直接從官方模型微調,而是從頭訓練,這樣學習特征能力會很弱,需要訓練很多epoch才能出現效果。此外由于改進的源碼框架并不一定能夠保證會超過官方精度,而且也有可能會存在遠遠不如官方效果,甚至精度會很低。這說明改進的框架并不能取得很好效果。所以說對于框架改進只是提供一種可行方案,至于改進后能不能取得很好map還需要結合實際訓練情況確認,當然也不排除數據集存在問題,比如數據集比較單一,樣本分布不均衡,泛化場景少,標注框不太貼合標注質量差,檢測目標很小等等原因
【重要說明】
我們只提供改進框架一種方案,并不保證能夠取得很好訓練精度,甚至超過官方模型精度。因為改進框架,實際是一種比較復雜流程,包括框架原理可行性,訓練數據集是否合適,訓練需要反正驗證以及同類框架訓練結果參數比較,這個是十分復雜且漫長的過程。
![[DS]使用 Python 庫中自帶的數據集來實現上述 50 個數據分析和數據可視化程序的示例代碼](http://pic.xiahunao.cn/[DS]使用 Python 庫中自帶的數據集來實現上述 50 個數據分析和數據可視化程序的示例代碼)




)













——類類的結構分析)