目錄
一、軟件包管理器——yum
1.Linux下安裝程序的方式
2.什么是yum
3.查找軟件包
4.安裝軟件
5.本地與服務器端進行文件互傳
6.卸載軟件?
二、Linux的編輯器——vim?
1.基本概念
2.vim下各個模式之間的切換
3.vim在命令行模式下的命令匯總
4.vim在底行模式下的命令匯總
5.關于vim的配置
三、Linux中的編譯器——gcc和g++
1.gcc和g++的作用
2.gcc和g++的語法
3.預處理
4.編譯
5.匯編
6.鏈接
7.動靜態庫
四、Linux中的調試器——gdb
1.背景知識
2.gdb命令的匯總
五、Linux——自動化構建工具
1.背景知識
2.依賴關系和依賴方法
3.多文件編譯
4.如何編寫makefile
5.項目清理
一、軟件包管理器——yum
1.Linux下安裝程序的方式
在Linux環境下安裝軟件的方式有以下幾個方式:
1)源碼安裝,直接下載源代碼,讓它自行編譯運行形成可執行程序。
2)軟件包安裝,下載rpm安裝包,通過rpm包獲取資源安裝。
3)包管理器安裝,通過yum安裝(推薦),ubuntu(apt)這個方式類似于我們手機上的應用商店。(這個方式可以解決包的依賴問題)
2.什么是yum
定義:
YUM(Yellowdog Updater, Modified)?是基于 RPM(Red Hat Package Manager)的軟件包管理工具,主要用于?Red Hat 系列 Linux 系統(如 RHEL、CentOS、Fedora 等),用于自動化安裝、更新、卸載軟件包,以及管理軟件包之間的依賴關系,一次性解決安裝的問題。
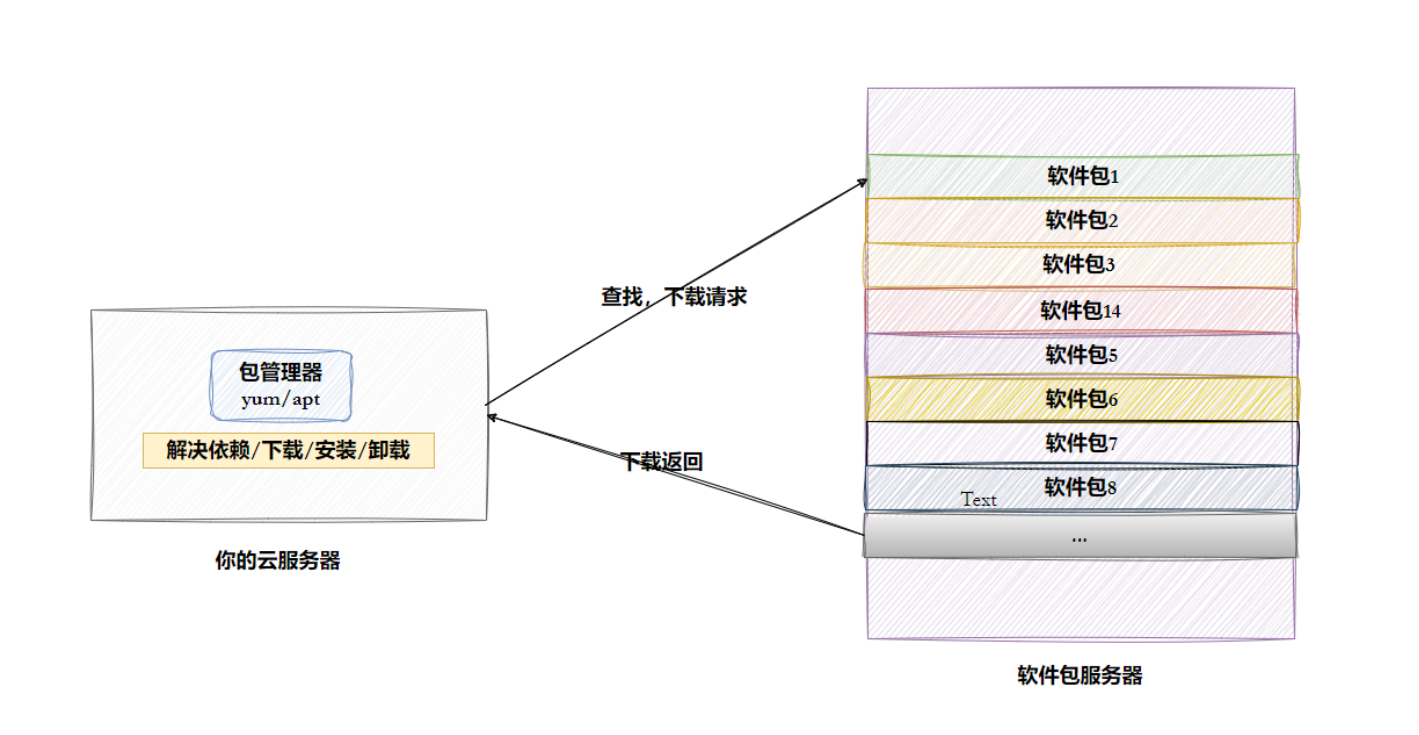
敲黑板:一個云服務器在同一時間只允許一個yum進行安裝,不能在同一時刻安裝多個軟件。
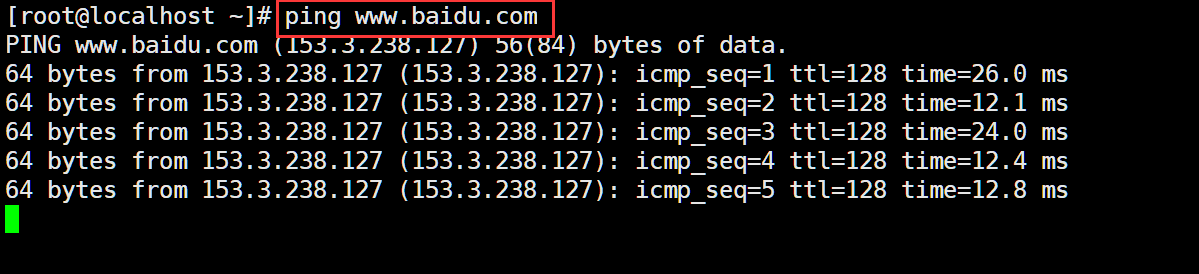
溫馨提示:在通過yum進行安裝時,我們首先要保證服務器或虛擬機是處在聯網狀態的,可以通過下面這個命令來驗證是否聯網,如果沒有打印任何信息則沒有連上網,需要檢查網絡配置。
3.查找軟件包
我們可以通過以下命令來查看可以下載的軟件:
yum list
注意事項:
1)軟件包名稱:主版本號.次版本號.源程序發行號-軟件包的發行號.主機平臺.cpu架構。
2)"x86_64"后綴表示64位系統的安裝包,"i686"后綴表示32位系統安裝包,選擇包時要和系統匹配。
3)"el7"表示操作系統發行版的版本,“el7"表示的是"centos7/redhat7”,“el6"表示"centos6/redhat6”。
4)最后一列表示的是“軟件源”的名稱,類似于“小米應用商店”,“華為應用商店”這樣的概念。
這里拿lrzsz做一個說明:
先解釋一下這個軟件包是什么:lrzsz可以將Windows當中的文件上傳到Linux當中,也可以將Linux當中的文件下載到Windows當中,實現云服務器和本地機器之間進行信息互傳。
yum list | grep lrzsz
4.安裝軟件
指令:sudo yum install? 軟件名
例如:我們要安裝的lrzsz
# Centos$ sudo yum install -y lrzsz# Ubuntu$ sudo apt install -y lrzsz敲黑板:
1)由于安裝軟件是在系統目錄下,所以我們需要使用sudo或者直接是用root賬戶去安裝
2)yum安裝軟件只能裝完這一個再去裝下一個,不然會報錯的。
5.本地與服務器端進行文件互傳
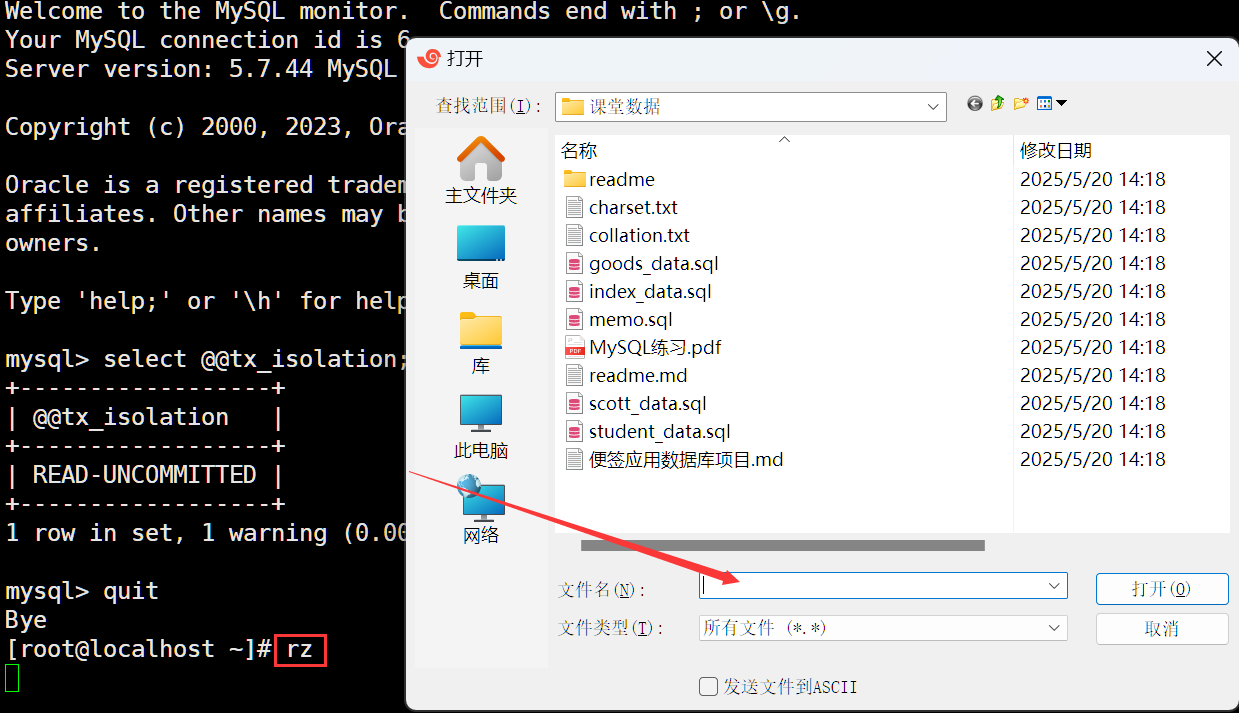
我們安裝好了lrzsz,那么我們就可以進行本地和服務器之間進行互傳。
指令:rz
通過這個命令可以實現本地向服務器傳文件。
指令:sz
通過這個指令可以實現從服務向本地導文件。
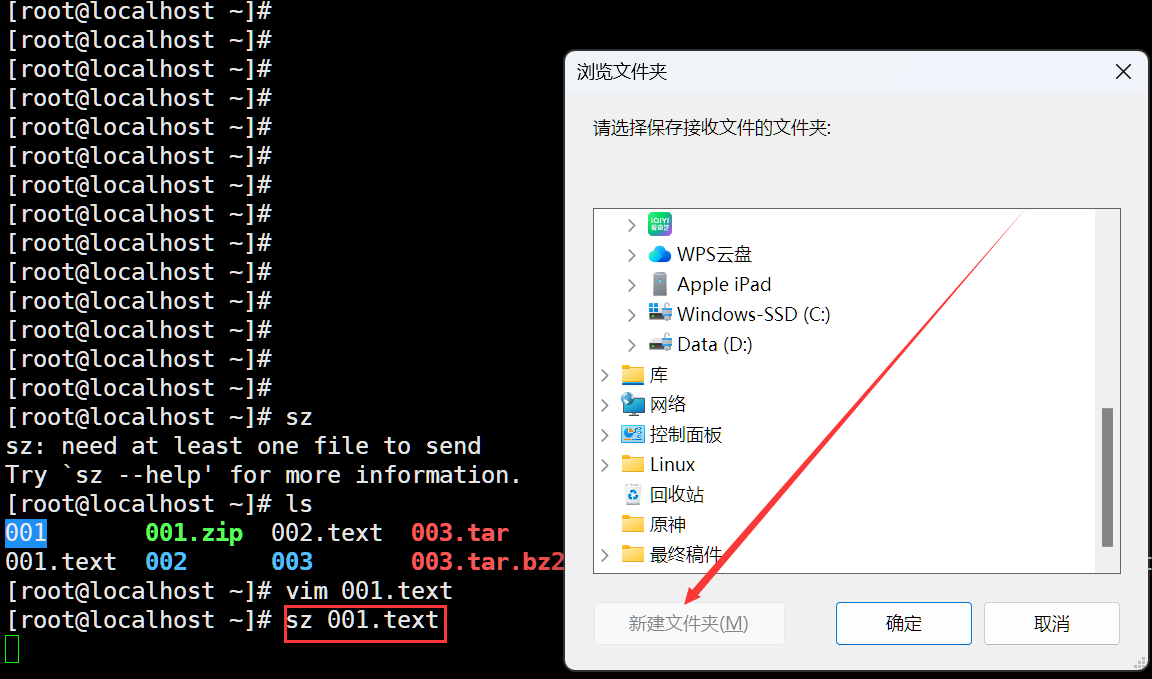
6.卸載軟件?
指令:sudo yum remove 軟件名
# Centos
sudo yum remove [-y] lrzsz# Ubuntu
sudo apt remove [-y] lrzsz
通過這個命令可以卸載軟件,中途需要按下"y"來確認。
二、Linux的編輯器——vim?
1.基本概念
我們這里介紹最常用的幾種模式,分別是命令模式、插?模式和底?模式,各模式的功能區分如下:
1)正常/普通/命令模式(Normal mode)?
控制屏幕光標的移動,字符、字或?的刪除,移動復制某區段及進?Insert mode下,或者到 last line mode
2)插入模式(Insert mode)
只有在Insert mode下,才可以做?字輸?,按「ESC」鍵可回到命令?模式。該模式是我們后面用的最頻繁的編輯模式。
3)末行模式(Last line mode)
?件保存或退出,也可以進??件替換,找字符串,列出行號等操作。 在命令模式下,*shift+:*即可進?該模式。要查看你的所有模式:打開vim,底?模式直接輸? :help vim-modes
2.vim下各個模式之間的切換
指令:vim 文件名
vim test.c我們在進入vim后,默認是在命令行模式,需要敲擊(i/a/o)進入插入模式。
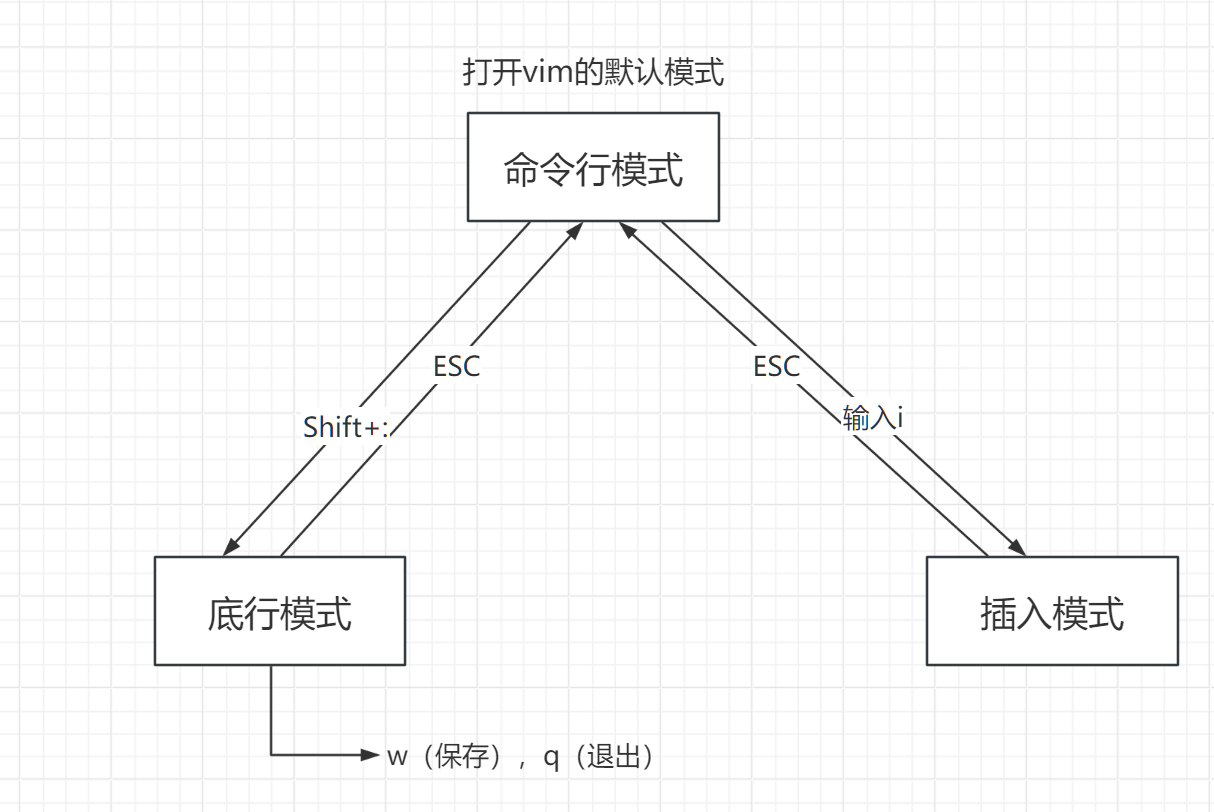 【命令模式】切換至【插入模式】
【命令模式】切換至【插入模式】
1)輸入「i」:在當前光標處進入插入模式。
2)輸入「a」:在當前光標的后一位置進入插入模式。
3)輸入「o」:在當前光標處新起一行進入插入模式。
【命令模式】切換至【底行模式】
1)輸入[Shift+;」 即可,實際上就是輸入「:」
【插入模式】或【底行模式】切換至【命令模式)
1)插入模式或是底行模式切換至命令模式都是直接按一下「Esc」鍵即可。
3.vim在命令行模式下的命令匯總
移動光標:
vim可以直接用鍵盤上的光標來上下左右移動,但正規的vim是用小寫英文字母「h」、「j」「k」、「I」,分別控制光標左、下、上、右移一格
1)按「G」:移動到文章的最后
2)按「$」:移動到光標所在行的“行尾
3)按「^」:移動到光標所在行的“行首
4)按「w」:光標跳到下個字的開頭
5)按「e」:光標跳到下個字的字尾
6)按「b」:光標回到上個字的開頭
7)按「#」:光標移到該行的第#個位置,如:5l,56l
8)按[gg]:進入到文本開始
9)按[shift+g]:進入文本末端
10)按「ctrl」+「b」:屏幕往“后”移動一頁
11)按「ctrl」+「f」:屏幕往“前”移動一頁
12)按「ctrl」+「u」:屏幕往“后”移動半頁
13)按「ctrl」+「d」:屏幕往“前”移動半頁
刪除文字:
1)「x」:每按一次,刪除光標所在位置的一個字符
2)「#x」:例如,「6x」表示刪除光標所在位置的“后面(包含自己在內)”6個字符
3)「X」:大寫的X,每按一次,刪除光標所在位置的“前面”一個字符
4)「#X」:例如,「20X」表示刪除光標所在位置的“前面”20個字符
5)「dd」:刪除光標所在行
6)「#dd」:從光標所在行開始刪除#行
復制:
1)「yW」:將光標所在之處到字尾的字符復制到緩沖區中。
2)「#yW」:復制#個字到緩沖區
3)「yy」:復制光標所在行到緩沖區。
4)「#yy」: 例如,「6yy」表示拷貝從光標所在的該行“往下數”6行文字。
6)「p」:將緩沖區內的字符貼到光標所在位置。注意:所有與“y”有關的復制命令都必須與“p”配合才能完成復制與粘貼功能。
替換:
1)「r」:替換光標所在處的字符。
2)「R」:替換光標所到之處的字符,直到按下「ESC」鍵為止。
撤銷上一次操作:
1)「u」:如果您誤執行一個命令,可以馬上按下「u」,回到上一個操作。按多次“u”可以執行多次回復。
2)「ctrl+r」:撤銷的恢復
更改:
1)「cw」:更改光標所在處的字到字尾處
2)「c#w」:例如,「c3w」表示更改3個字
跳至指定行:
1)「ctrl」+「g」列出光標所在行的行號。
2)「#G」:例如,「15G」,表示移動光標至文章的第15行行首。
4.vim在底行模式下的命令匯總
這里跳至底行的方法是,一直Esc(避免你不知道是在哪一個模式下),再按【:】進入底行模式。
行號設置:
1)「set nu」:輸入后,會在文件中的每一行前面列出行號。
2)「set nonu」:取消行號。
跳至某一行:
「#」:「#」號表示一個數字,在冒號后輸入一個數字,再按回車鍵就會跳到該行了,如輸入數字
15,再回車,就會跳到文章的第15行。
查找字符:
1)「/關鍵字」:先按「/」鍵,再輸入您想尋找的字符,如果第一次找的關鍵字不是您想要的,可以一直按「n」會往后尋找到您要的關鍵字為止。
2)「?關鍵字」:先按「?」鍵,再輸入您想尋找的字符,如果第一次找的關鍵字不是您想要的,可
以一直按「n」會往前尋找到您要的關鍵字為止。
保存文件:
[w」:在冒號輸入字母「w」就可以將文件保存起來
離開vim:
1)「q」:按「q」就是退出,如果無法離開vim,可以在「q」后跟一個「!」強制離開vim。
2)「wq」:一般建議離開時,搭配「w」一起使用,這樣在退出的時候還可以保存文件。
5.關于vim的配置
vim的配置是一人一份的,一個用戶配置的是自己的并不影響別人。每個人雖然用的是同一個vim程序,但是大家用的是vim不同的配置(每個用戶在自己的家目錄下都有屬于自己的配置文件)
我們需要創建.vimrc文件,并在自己的.vimrc文件中添加一系列的命令,充當于vim的配置文件。所謂的vim的基本配置,就是修改自己的vimrc!
如果是自己配置的話比較麻煩,所以這里提供一個碼云上面的自動一鍵配置vim的命令。
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh
配置完成之后:
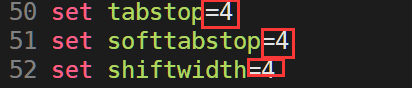
但是要注意的是,這個的默認縮進是兩個空格,我們可以打開.vimrc來配置。?
三、Linux中的編譯器——gcc和g++
1.gcc和g++的作用
gcc和g++分別是c和c++的編譯器,它們在執行編譯時,有如下幾個步驟:
1)預處理(進行宏替換/去注釋/條件編譯/頭文件展開等)
2)編譯(生成匯編)
3)匯編(生成機器可識別代碼)
4)連接(生成可執行文件或庫文件)
2.gcc和g++的語法
格式:gcc/g++ 選項 文件
| 選項 | 功能描述 |
|---|---|
-c | 僅編譯不鏈接,生成目標文件 (.o) |
-S | 生成匯編代碼文件 (.s) |
-E | 僅進行預處理,不編譯 |
-o <file> | 指定輸出文件名為<file> |
-g | 生成調試信息,用于 GDB 調試 |
-O0 | 不進行優化(默認) |
-O1 | 基本優化 |
-O2 | 更高級優化(推薦) |
-O3 | 最高級優化(可能增加編譯時間) |
-Os | 優化代碼大小 |
3.預處理
作用:頭文件展開,去注釋,宏替換,條件編譯
指令:
gcc -E hello.c -o hello.i 說明:
選項“-E”,該選項的作用是讓 gcc 在預處理結束后停止編譯過程。
選項“-o””是指目標文件,“.i”文件為已經過預處理的C原始程序。

4.編譯
作用:
在這個階段中,gcc 首先要檢查代碼的規范性、是否有語法錯誤等,以確定代碼的實際要做的工作,在檢查無誤后,gcc 把代碼翻譯成匯編語言。
?指令:
gcc -S hello.i -o hello.s 說明:
用戶可以使用-S選項來進行查看,該選項只進行編譯而不進行匯編,生成匯編代碼。
-o選項是指目標文件,“xxx.s”文件為已經過翻譯的原始程序。
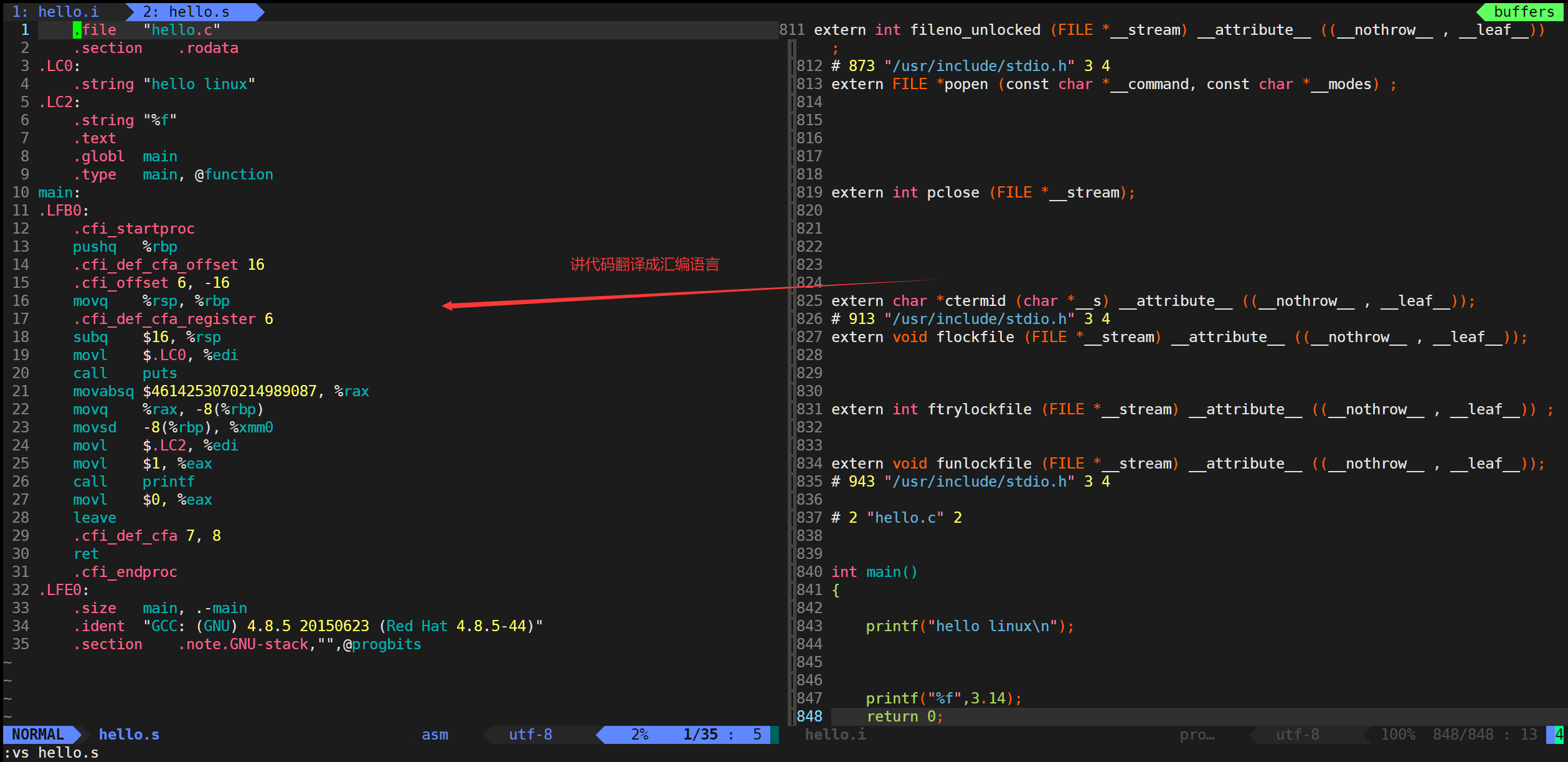
5.匯編
作用:將匯編代碼轉變為二進制碼。
指令:
gcc -c hello.s -o hello.o
說明:
匯編階段是把編譯階段生成的“xxx.s”文件轉成目標文件。
使用-c選項就可以得到匯編代碼轉化為“xxx.o”的二進制目標代碼了。
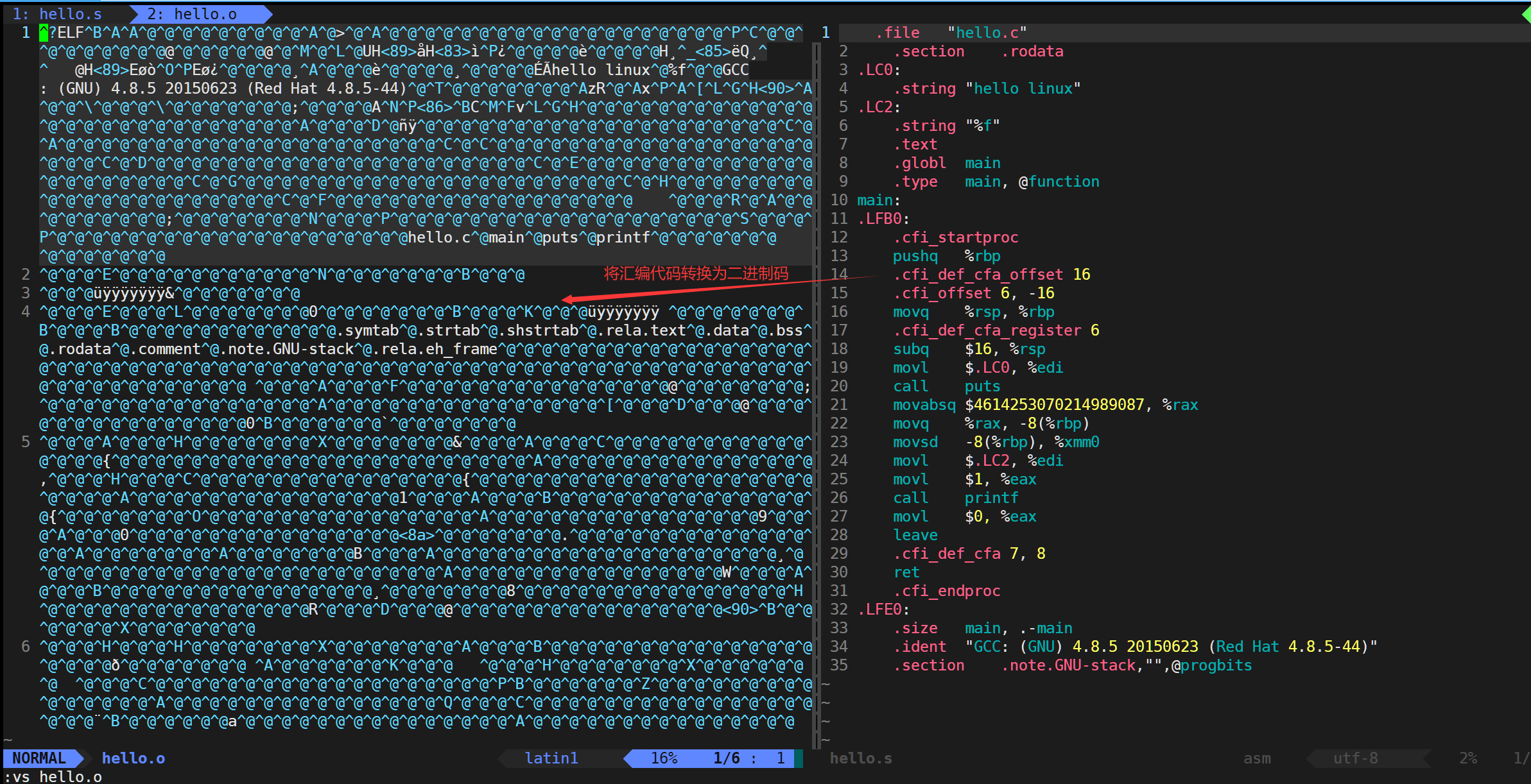
6.鏈接
作用:鏈接就是將生成的各個“xxx.o”文件進行鏈接,生成可執行文件。
指令:
gcc hello.o -o hello
說明:
gcc/g++不帶-E、-S、-c選項時,就默認生成預處理、編譯、匯編、鏈接全過程后的文件。
若不用-o選項指定生成文件的文件名,則默認生成的可執行文件名為a.out。
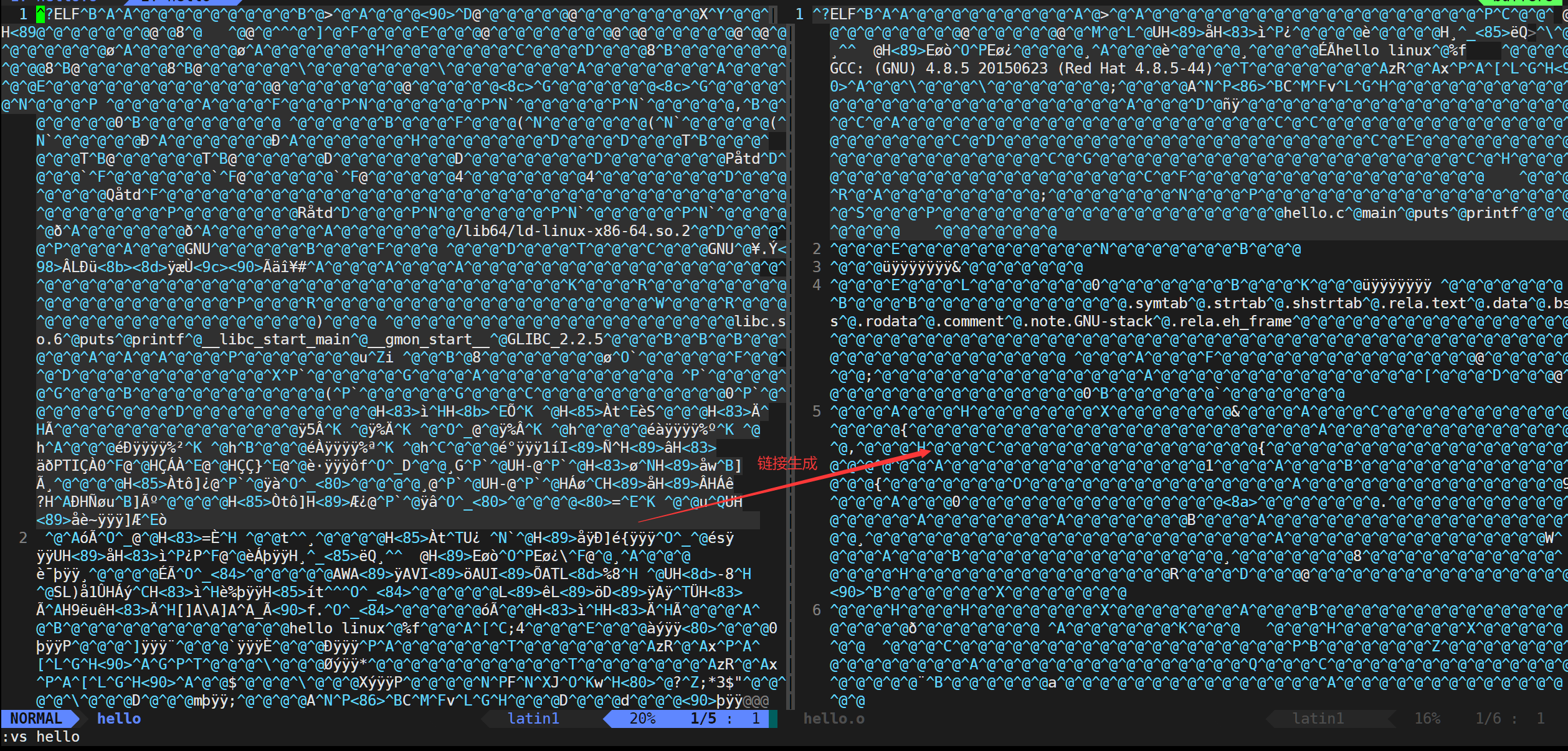
敲黑板:鏈接產生的文件也是二進制的。
7.動靜態庫
函數庫可以分成動態庫和靜態庫:
1)靜態庫是指編譯鏈接時,把庫文件的代碼全部加入到可執行文件中,因此生成的文件比較大,但在運行時也就不再需要庫文件了。其后綴名一般為“.a”
2)動態庫與之相反,在編譯鏈接時并沒有把庫文件的代碼加入到可執行文件中,而是在程序執行時由
運行時鏈接文件加載庫,這樣可以節省系統的開銷。動態庫一般后綴名為“.so”
有動靜態庫,那么就有了動靜態鏈接:
動態鏈接:
優點:節省空間,易于更新,靈活性高。
缺點:依賴外部環境,加載時間長,不同程序可能依賴同一庫的不同版本,可能會引發版本沖突問題。
靜態鏈接:
優點:獨立性強,加載速度快,便于我們調試。
缺點:占用空間大,更新維護困難,資源浪費。
我們是用gcc和g++鏈接時默認是動態鏈接的,可以通過file指令查看:

我們還可以通過ldd來查看所依賴的庫。

敲黑板:?
Linux下,動態庫XXX.so,靜態庫XXX.a
Windows下,動態庫XXX.dll,靜態庫XXX.lib
那么我們如何實現靜態鏈接呢?
這里我們在編譯時只需要帶上-static的選項即可。

我們還可以查看一下兩種鏈接方式的文件大小的區別:
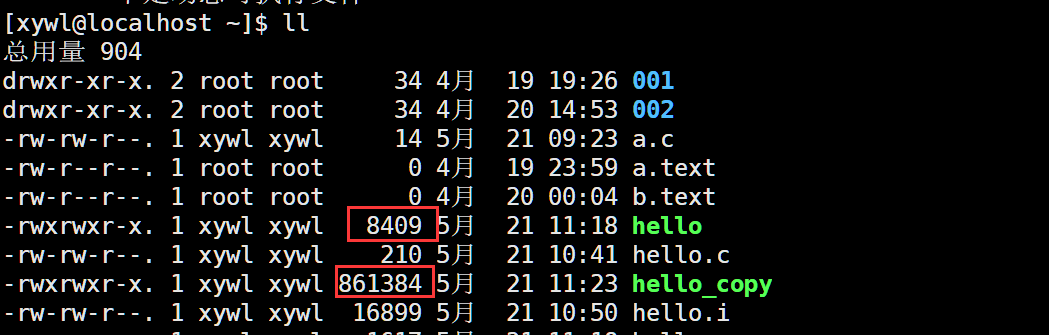
很明顯,靜態鏈接方式的文件更大,說明了動態鏈接節省空間。
四、Linux中的調試器——gdb
1.背景知識
程序的發布模式有兩種,分別是debug模式和release模式,而調試只能在debug模式下。
Linux 的gcc和g++編譯出來的二進制程序,默認是release模式,所以默認是不支持調試的。
如果是想實現調試則需要在生成二進制程序時,加上-g選項。
 我們也可以對比一下在relesase和debug模式下兩個可執行程序的大小。
我們也可以對比一下在relesase和debug模式下兩個可執行程序的大小。

我們發現在debug模式下還是要比release模式下的可執行程序的大一些。
2.gdb命令的匯總
基本上都是用過即可。
進出gdb:
進入:gdb 二進制文件
退出:ctrl+d或quit 調試命令
調試:
1)run/r:運行代碼(啟動調試)
2)next/n:逐過程調試。
3)step/s:逐語句調試。
4)until 行號:跳轉至指定行。
5)finish:執行完當前正在調用的函數后停下來(不能是主函數)
6)continue/c:運行到下一個斷點處。
7)set var 變量=x:修改變量的值為x。
顯示:
1)list/l n:顯示從第n行開始的源代碼,每次顯示10行,若n未給出則默認從上次的位置往下顯示。
2)list 函數名:顯示該函數的源代碼。
3)print/p 變量:打印變量的值。
4)print/p &變量:打印變量的地址。
5)print/p 表達式:打印表達式的值,通過表達式可以修改變量的值。
6)display 變量:將變量加入常顯示(每次停下來都顯示它的值)。
7)display &變量:將變量的地址加入常顯示。
8)undisplay 編號:取消指定編號變量的常顯示。
9)bt:查看各級函數調用及參數。
10)info/i locals:查看當前棧幀當中局部變量的值。
斷點:
1)break/b n:在第n行設置斷點。
2)break/b 函數名:不在某函數體內第一行設置斷點。
3)info breakpoint/b:查看已打斷點信息。
4)delete/d 編號:刪除指定編號的斷點。
5)disable 編號:禁用指定編號的斷點。
6)enable 編號:啟用指定編號的斷點。
五、Linux——自動化構建工具
1.背景知識
1)會不會寫makefile,從一個側面說明了一個人是否具備完成大型工程的能力。
2)一個工程中的源文件不計數,其按類型、功能、模塊分別放在若干個目錄中,makefile定義了一系列的規則來指定,哪些文件需要先編譯,哪些文件需要后編譯,哪些文件需要重新編譯,甚至于進行更復雜的功能操作
3)makefile帶來的好處就是--“自動化編譯”,一旦寫好,只需要一個make命令,整個工程完全自動編譯,極大的提高了軟件開發的效率。
4)make是一個命令工具,是一個解釋makefile中指令的命令工具,一般來說,大多數的IDE都有這個命令,比如:Delphi的make,VisualC++的nmake,Linux下GNU的make。可見,makefile都成為了一種在工程方面的編譯方法。
5)make是一條命令,makefile是一個文件,兩個搭配使用,完成項目自動化構建。
2.依賴關系和依賴方法
我們在寫makefile一定要首先理解各個文件之間的依賴的關系以及它們之間的依賴方法。
依賴關系:文件A的變化會影響到文件B,那么我們就稱文件B依賴于文件A。
比如:文件hello.o是由文件hello.c文件通過預處理、編譯以及匯編產生的,所以hello.c的改變會影響到hello.o,也就是hello.o依賴hello.c。
依賴方法:如果文件B依賴于文件A,那么通過文件A得到文件B的方法,就是文件B依賴于文件A的依賴方法。
比如:hello.o依賴于hello.c,而hello.c通過gcc -c hello.c -o test.o指令就可以得到test.o,那么hello.o依賴于hello.c的依賴方法就是gcc -c hello.c -o test.o。
3.多文件編譯
如果我們有很多個源文件需要編譯,應該怎么辦呢?

這里我們可以使用常用的方法,直接使用gcc。
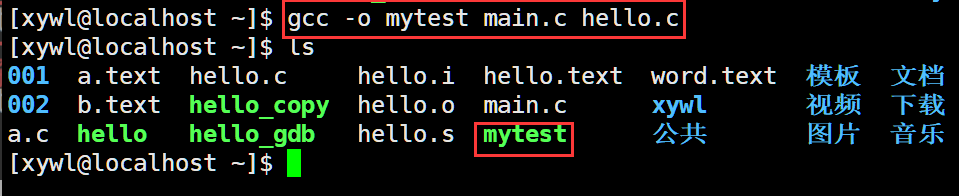
我們講行多文件編譯的時候一般不使源文件直接生成可執行程序,而是先用每個源文件各自生成自己的二講制文件,然后重將這些一進制文件通過鏈接生成可執行程序。


那么我們為什么要這么做呢?
因為如果我們修改了其中的一個源文件,那么我們再生成可執行是就需要重新再把所有的源文件進行編譯鏈接。而如果是把各個源文件生成各個二進制文件,那么修改后只需要把修改的文件重新編譯生成二進制文件,然后在把二進制文件鏈接。
但是隨著源文件的數量增加,我們如果還是以之前的方式就會極其的惡心,這個時候我們就需要用到make和makefile來大大減少工作量。
4.如何編寫makefile
第一步:在源文件所在目錄下創建了一個makefile/Makefile文件

第二步:編寫makefile文件
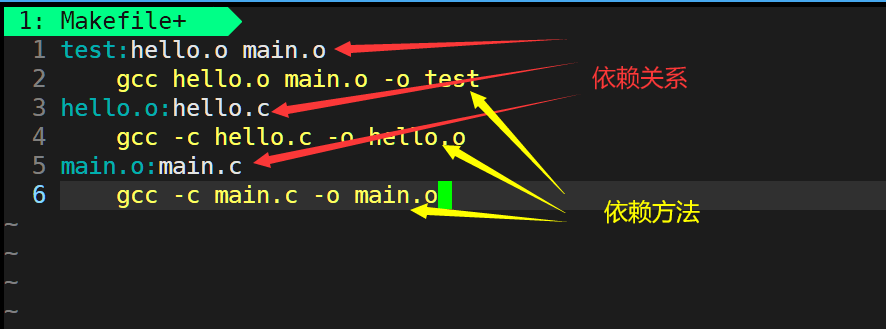
保存并退出后,make執行后便可以得到我們想要的文件。

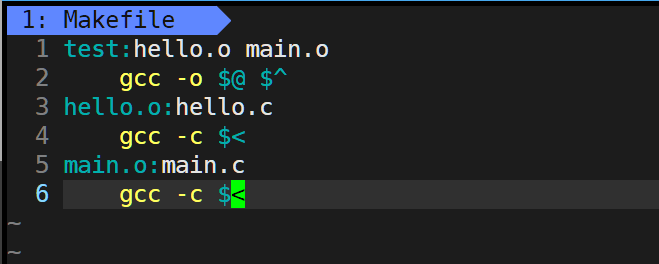
makefile中的技巧寫法:
| 符號 | 含義 |
|---|---|
$@ | 當前規則的目標文件名。 |
$< | 第一個依賴文件的名稱。 |
$^ | 所有依賴文件的列表,以空格分隔(去重)。 |
上面代碼的簡寫:
make的工作原理:
1)make會在當前目錄下找名字叫“Makefile”或“makefile”的文件。
2)如果找到,它會找文件中的第一個目標文件(target),在上面的例子中,他會找到 myproc 這個文件,并把這個文件作為最終的目標文件。
3)如果 myproc 文件不存在,或是 myproc 所依賴的后面的 myproc.o 文件的文件修改時間要比 myproc 這個文件新(可以用 touch 測試),那么,他就會執行后面所定義的命令來生成myproc 這個文件。
4)如果 myproc 所依賴的 myproc.o 文件不存在,那么 make 會在當前文件中找目標為myproc.o 文件的依賴性,如果找到則再根據那一個規則生成 myproc.o文件。(這有點像一個堆棧的過程)
5)當然,你的C文件和H文件是存在的啦,于是make會生成 myproc.o 文件,然后再用myproc.o 文件聲明 make 的終極任務,也就是執行文件 hello 了。
6)這就是整個make的依賴性,make會一層又一層地去找文件的依賴關系,直到最終編譯出第一個目標文件。
7)在找尋的過程中,如果出現錯誤,比如最后被依賴的文件找不到,那么make就會直接退出,并報錯,而對于所定義的命令的錯誤,或是編譯不成功,make根本不理。
8)make只管文件的依賴性,即,如果在我找了依賴關系之后,冒號后面的文件還是不在,那么對不起,我就不工作啦。
5.項目清理
在執行完后,有可能我們需要刪除之前的執行的結果文件再執行新的文件,那么我們應該如何實現和執行相似的過程呢?
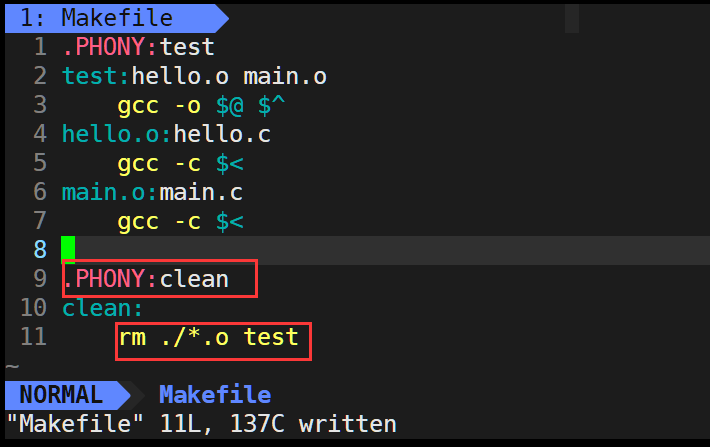
這樣寫好之后我們只要make clean就可執行之前寫的代碼。

敲黑板:
一般將這種clean的目標文件設置為偽目標,用.PHONY修飾,偽目標的特性是:總是被執行。
-sql重點問題)


![[BUG]Debian/Linux操作系統中 安裝 curl等軟件顯示無候選安裝(E: 軟件包 curl 沒有可安裝候選)](http://pic.xiahunao.cn/[BUG]Debian/Linux操作系統中 安裝 curl等軟件顯示無候選安裝(E: 軟件包 curl 沒有可安裝候選))

)




,用戶簽到與統計(Bitmap),網站UV統計(HyperLogLog))





)


