全部內容梳理
目標檢測的兩個任務:
預測標簽 邊界框
語義分割 實力分割
一個是類別 一個是實例級別
分類任務把每個圖像當作一張圖片看待 所有解決方法是先生成候選區域 再進行分類
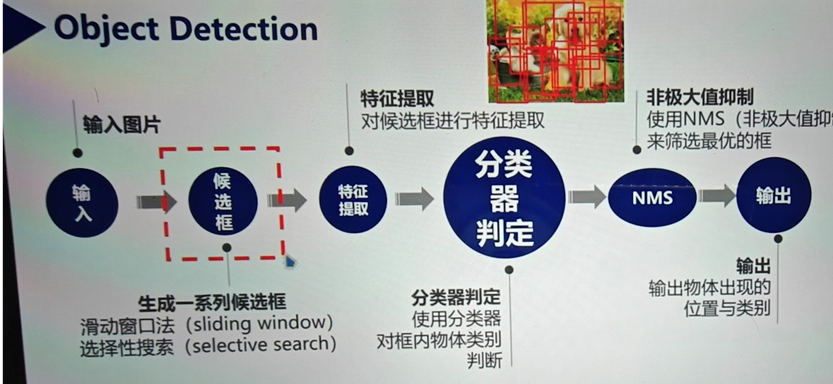
置信度:
包括對類別和邊界框預測的自信程度
輸出分類和IOU分數的乘積
雙階段代表R-CNN FAST R-CNN
分類 閾值判斷
回歸 擬合最優
錨定框是可能的候選區域
具體的
是否包含物體
判斷類別
微調邊界框
coco格式 json文件

YOLO格式 類別 x,y,w,h
驗證集:用于驗證模型效果的數據,評價模型學的好不好,選擇超參數。
直接通過測試集進行檢測,那么模型是以測試集為目標去優化,相當于作弊
交叉驗證---為了規避掉驗證集選擇的bias(如驗證集上的都是同一類別)
mAP:對每個類別計算AP,取所有類別AP計算平均mAP
對于每個類別,基于預測結果和真實標簽,計算出一個precision-recall曲線
對于每個類別的precision-recall曲線,計算出該曲線下的面積,即AP。
計算所有類別的AP的平均值。
正樣本
類別 邊界框損失
負樣本
類別
softmax單一預測
sigmoid多預測
檢測任務是遍歷的分類任務
常見的優化器
Loss(w,b)容易陷入局部最優
SGD也叫mini-batch,之后的優化算法,一定是建立在SGD之上,容易震蕩
模擬退火,通過隨機擾動避免了局部最優
AdaGrad自適應調整學習率,缺點:學習率會一直減小,最終可能變得過小,導致訓練提前停止
RMSProp是對AdaGrad改進,通過指數加權平均來調整歷史梯度的影響,使學習率減小的更加平滑。
Momentum參數更新不僅取決于當前梯度,還取決于之前的更新的累計動量。
Adam結合了Momentum和RMSProp的優點,通過自適應學習率和動量加速收斂
主干網絡
頸部:對于主干網絡提取的特征信息做進一步融合,增加了魯棒性和特征的表達能力,對多尺度目標檢測和小目標檢測有著重要作用
頭部:卷積層或FC層進行分類和定位
anchor free
對每個像素點預測類別和邊界框
每個位置預測一個框 重疊位置可能無法檢測
anchor box
復雜度高
不靈活
正樣本
正樣本指預測框和真實框IOU大于設定閾值
負樣本指預測框和真實框IOU小于設定閾值
失衡的后果:
負樣本過多會淹沒正樣本 關注負樣本
模型傾向于負樣本預測 漏檢正樣本
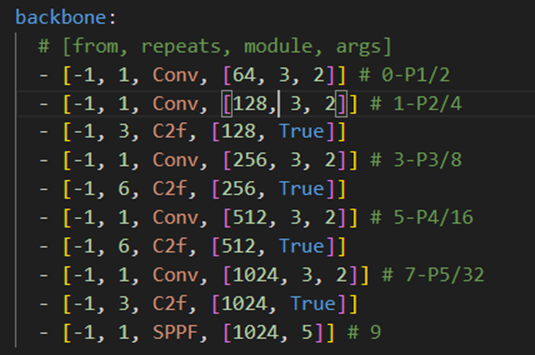
最后一層換成了SPPF
| 模型版本 | 準確率 (Accuracy) | 召回率(Recall) | F1值 (F1 Score) | 每秒浮點運算次數(GFLOPs) | 平均精度均值(mAP) |
| 未改進版本 | 82.3% | 78.5% | 80.1% | 5.6 | 0.468 |
| 改進點一 | 83.6% | 82.5% | 82.8% | 5.7 | 0.479 |
| 改進點二 | 83.4% | 81.7% | 80.3% | 5.6 | 0.468 |
| 改進點一+改進點二 | 85.1% | 83.7% | 84.1% | 5.7 | 0.481 |
對于小波卷積的替換 只需要對寫好小波卷積部分 然后在各個結構中進行替換
同理
標注使用LABELME YOLO格式
使用的主干網絡RESNET101 使用了預訓練權重
批次大小設置為24 訓練輪次100?優化器為 Adam 優化器,初始學習率為0.01

召回率關注的是在所有實際為正的樣本中,模型能夠正確預測出多少,即模型預測正類的完整性
精確率關注的是模型預測為正的樣本中有多少是 真正的正樣本,即模型預測正類的準確性
map是0.5--0.95的平均map?
0.75更能反映小目標
小波變換 正交基 沒有冗余信息
小波變換用于替代短時傅里葉變換 把無限長的基替換為有限長的衰減小波基
短時傅里葉處理不平穩的信號 小波變換克服了短時傅里葉的窗口不變性

小波變換卷積通過小波變換分解為不同的頻率分量 關注不同的頻率
進行小核卷積 進行上采樣 小波基函數類似卷積核
低頻對應全局 高頻對應局部 通過對低頻高頻分別處理 更好的進行多尺度表達
小波變換卷積通過低頻逐漸向高頻過渡 從而實現大尺度物體向小尺度的轉變 低頻的信息具有全局特征 彌補了CNN局部提取的缺陷 高頻特征更好的捕捉了邊緣紋理等 強化了形狀的識別
絕大部分噪音都是圖像的高頻分量,通過低通濾波器來濾除高頻; ?邊緣也是圖像的高頻分量,可以通過添加高頻分量來增強原始圖像的邊緣;
學生網絡接收到的標簽
一種是教師網絡的輸出, 一種是真實的標簽。
硬標簽 獨熱編碼 軟標簽 概率分布
蒸餾溫度 溫度越高越平滑 越可以容忍學生的過失
concat 維度增加 自適應學習
add 信息量增加 殘差連接
卷積如何在計算機中并行計算 轉化為特征向量
深度可分離卷積 空洞卷積 擴大感受野
車道線檢測
線提議單元 為了學習全局特征 類似于貓框
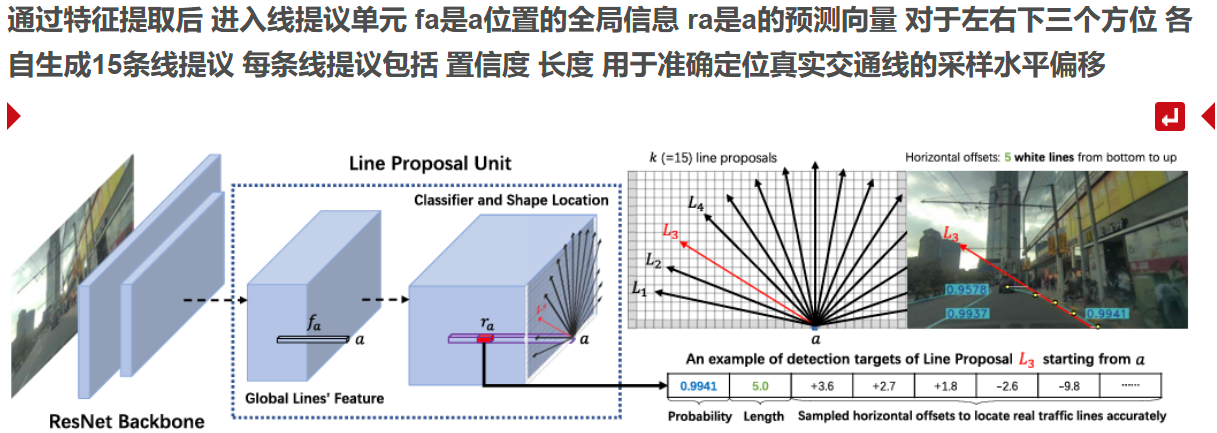
正標簽選擇 小于一個閾值 但一個車道線可以有多個提議
負標簽選擇 與所有車道線都大于閾值
首先是距離判斷正負標簽 其次看分類的分數
像目標檢測一樣 只有正標簽 才有回歸損失
回歸損失 平滑L1損失 避免了過度懲罰小誤差
車道線具有高級語義 也需要低級語義進行定位
高級語義檢測車道線 低級語義定位
RIO聚合上下文
車到先驗
背景前景概率 長度 角度和起點 N個偏移量
線IOU把車道線作為一個
在檢測過程中?
計算焦點損失 類別
相似度損失 距離遠近
訓練時
類別損失 回歸損失 LIOU損失
Lseg輔助分割損失 更好的定位
Laneiou考慮了車道角度
CLRKDNE對檢測頭和FPN進行簡化 推理速度上升60%? 保持了和CLRNET相當的精度
利用教師模型 CLRNet 的中間特征層、先驗嵌入和最終檢測頭 logits 來提升其車道檢測能力?
logits是一個向量 類似軟標簽
![]()
起點和角度
CLRKDNET單個檢測頭 固定先驗參數(教師傳遞,不可迭代)
知識蒸餾分為三個部分
注意力圖蒸餾
讓學生網絡也能關注關鍵特征
先驗知識嵌入和logits蒸餾
學生網絡直接使用起點和角度(RIO精煉后的)L2范數進行損失比較
Logit 蒸餾:Logit 蒸餾關注檢測頭的最終輸出
確保學生有老師的輸出邏輯 參數包括長度 類別 偏移量等
目標檢測
DETR對于真實值 預測值 摒棄了NMS 使用匈牙利算法進行二分圖匹配 并行預測
二分圖匹配考慮 匹配損失 包括類別和回歸
GIOU廣義交并比 考慮了重疊區域 考慮了位置信息
D-fine
對于回歸任務 概率分布 細粒度分布優化
深層向淺層的知識傳遞
傳統的logits模仿和特征模仿在檢測任務下精度低下
從固定的坐標預測變成建模概率分布(殘差方式)
把四個邊分為了n個bin預測每個bin的概率 取最大
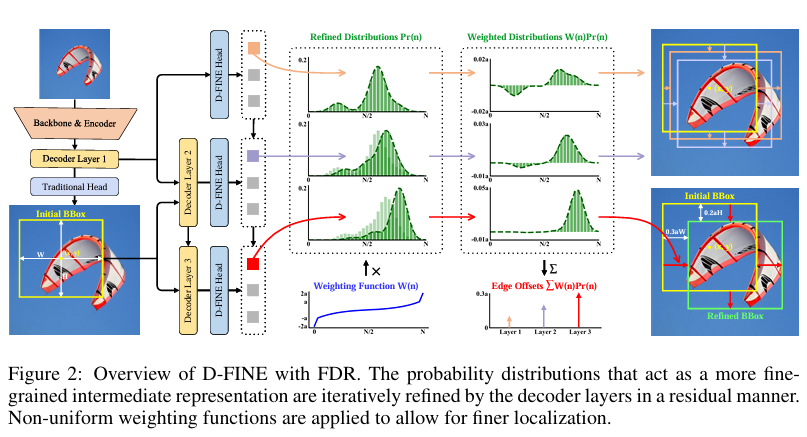
首先第一層預測初步邊界框 初步概率分布?
邊界框作為參考框 后續層對概率分布進行優化
wn通過分段可以對小的偏差更精細調整
DEIM
解決DETR中稀疏監督的問題
增加額外的目標 提高每個圖像中的正樣本數量
YOLO的每個目標和多個貓框相關聯 提供了密集監督
對小目標 密集監督更加重要
增加每張訓練樣本中的額外目標數量
提供監督
保留了020的匹配機制 避免了NMS 防止推理速度變慢
老師提問:
寫的是中文還是英文
核心還是SCI
核心的發表時間會更長
改進點是什么
正常回答
前期成果
對deim進行了改進
學術論文初稿寫好
參數不要動了
課題哪里來的
α:
師兄中科院二區論文和畢業論文的課題上延伸
α:
雨雪條件到惡劣條件
α:
提高了場景適應性
已經進入實驗室進行相關研究 有專業的老師和師兄指導



















