隨著信息技術的飛速發展,搜索引擎作為信息獲取的重要工具,扮演著不可或缺的角色。阿里云 AI 搜索開放平臺以其強大的技術支持和靈活的開放性,持續為用戶提供高效的搜索解決方案。
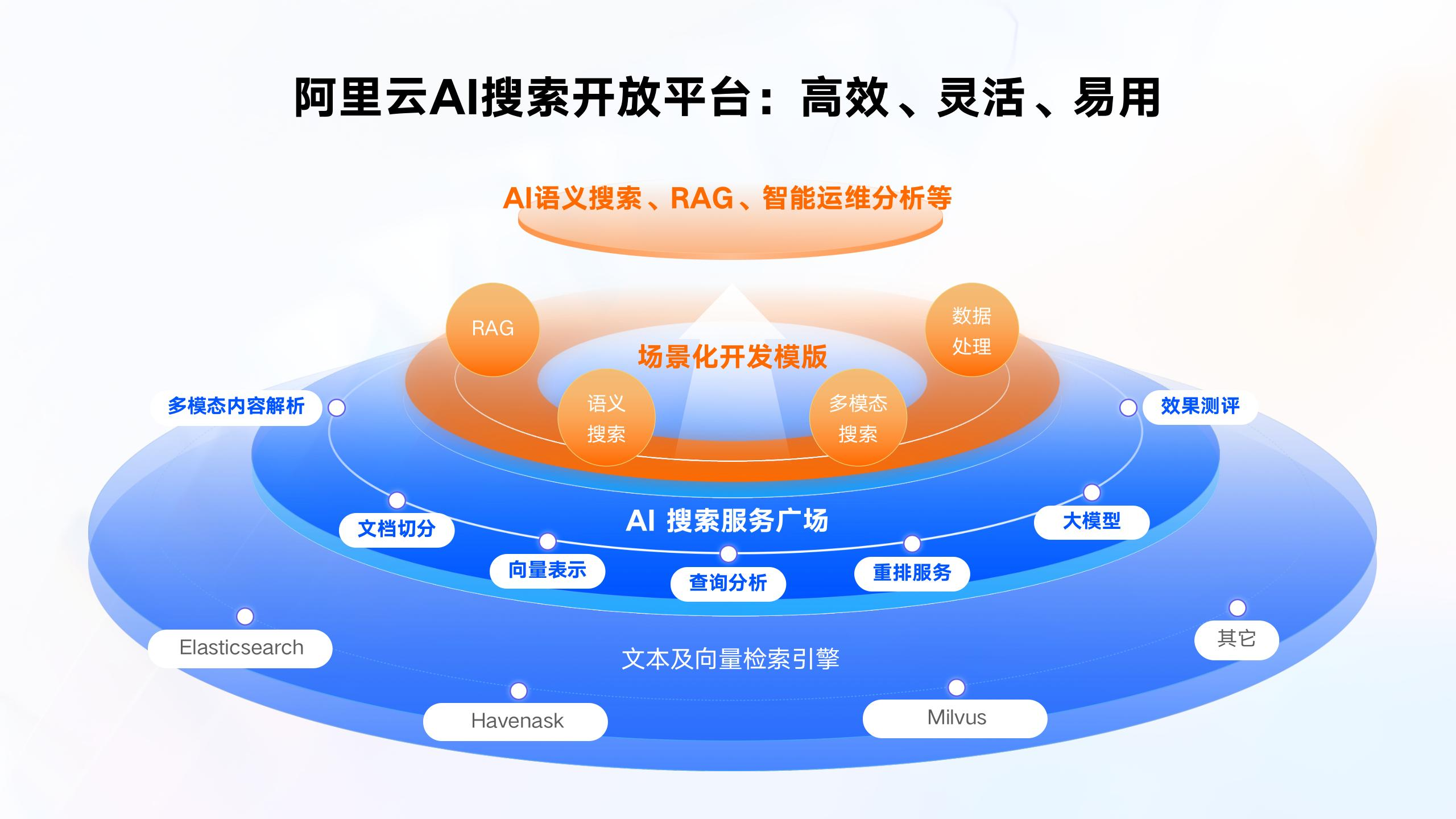
一、阿里云 AI 搜索開放平臺
一站式的 AI 搜索開放平臺作為阿里云 AI 搜索整個產品體系核心,提供豐富的 AI 搜索組件化服務。兼容主流開發框架 LangChain和 LlamaIndex,支持搜索專屬大模型、百煉等大模型服務,以及 Elasticsearch、Havenask 等開源引擎。用戶可靈活調用多模態數據解析、大語言模型、效果測評等數十個服務,實現智能搜索、檢索增強生成(RAG)、多模態搜索等場景的搭建。
核心優勢:
- 多模態搜索 支持文本、圖像、文檔聯合檢索,覆蓋 PDF、DOC、圖片等格式,可提取結構化內容(如標題、表格、代碼),并結合多模態大模型理解圖片語義。
- 大模型深度集成 提供 Qwen3、QwQ、DeepSeek、GTE 多語言文本向量化模型等大語言模型,支持語義分析、NL2SQL 轉換、對話生成,降低模型幻覺率,提升問答準確性。
- 全鏈路組件化服務 內置文檔解析、切片、向量化、查詢分析、排序、效果評估等20+原子化服務能力,可靈活組合搭建智能搜索、RAG或推薦系統。
- 多場景支持 覆蓋電商搜索、智能客服、知識庫問答、多模態內容檢索等場景,提供行業適配模板(如電商排序策略、醫療文檔分析)。
應用場景:
- 智能客服:
基于 RAG(檢索增強生成)技術,結合 Qwen3、QwQ 等大模型,構建企業專屬智能客服系統,通
過私有知識庫與聯網搜索能力,提供精準、安全的問答服務。
- 對話式搜索:
提供基于 LLM 的對話式搜索服務,支持自然語言交互與多模態結果展示,適用于搜索引擎、問答機器
人等場景。
- 知識圖譜增強:
通過文檔解析、向量化與 RAG 技術,構建并優化企業知識圖譜,實現語義化查詢與關聯分析。
- 個性化推薦
結合用戶行為數據、向量化推薦與排序服務,實現電商、內容平臺等場景的精準推薦。
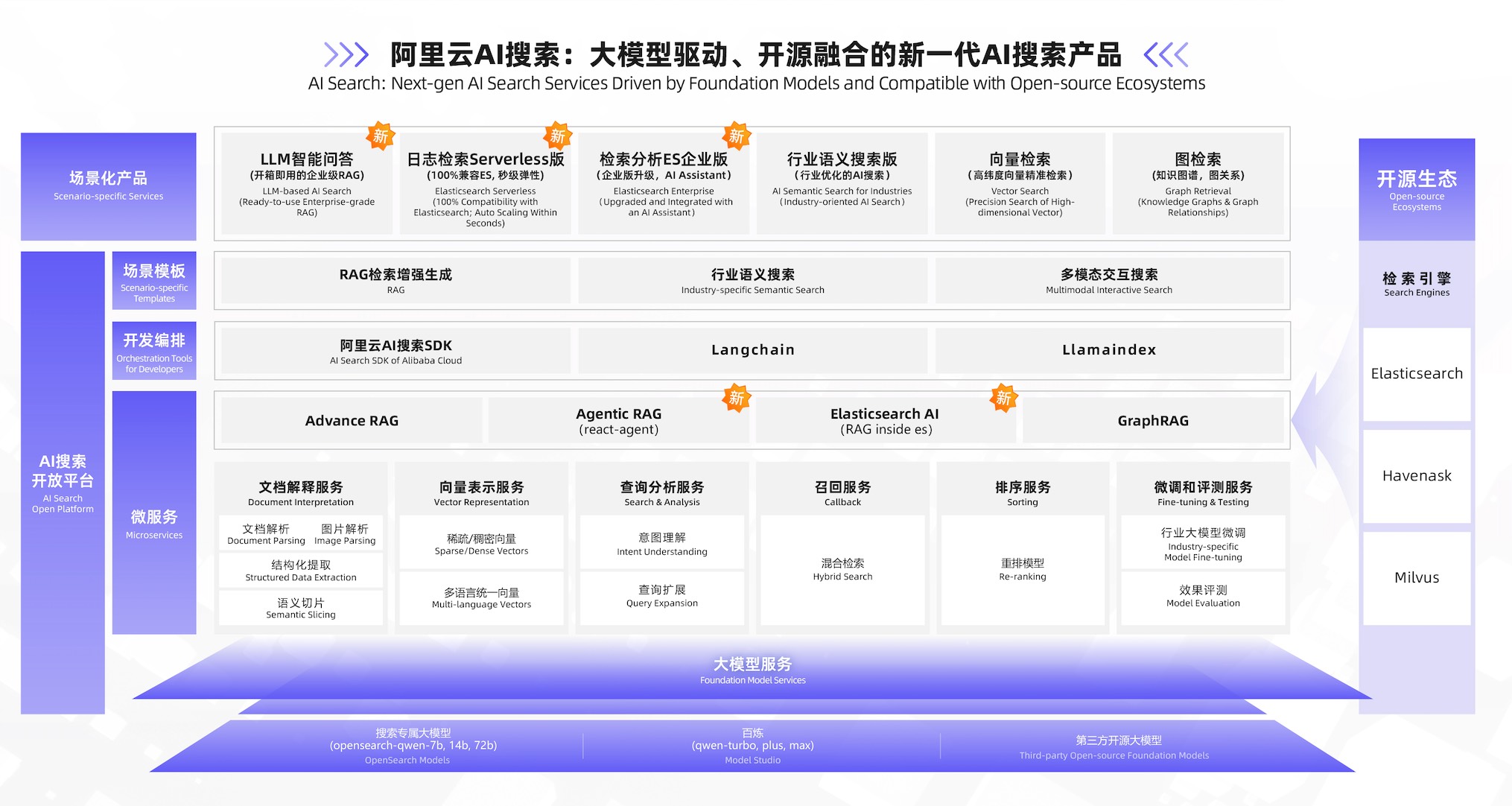
二、產品能力介紹
無論是文檔解析、圖片理解還是 OCR 識別,AI 搜索開放平臺都能高效處理多類型數據,憑借行業分析、意圖識別與排序算法,顯著提升特定業務場景下的搜索效率與準確性。此外,基于大模型的自動測評功能,涵蓋無幻覺率、準確率和相關性等指標,幫助開發者不斷優化搜索體驗。
1. 文檔解析服務
支持文檔、圖片分鐘級解析,針對 PDF、DOC、HTML、TXT 等文檔,能夠區分多種版式,從非結構化文檔中
提取出標題、分段等邏輯層級結構,以及文本、表格、圖片、代碼等信息,去除頁眉、頁腳、識別上標、下標
等信息,以結構化的格式輸出。
2. 圖片解析服務
針對架構圖、分析圖表等圖片數據,提供圖片內容理解服務,可基于多模態大模型對圖片內容進行解析理解以及文字識別,也可基于 OCR 能力對圖片文字進行識別,將文字信息提取出來,用于圖片檢索及問答等場景。
3. 文檔切片服務
提供通用文檔切片服務,可基于文檔語義、段落結構以及指定規則進行切分,以便提升后續文檔處理及檢索效率,輸出的切片樹可在檢索召回時進行上下文補全。
4. 多語言向量模型
- 文本向量化提供將文本數據轉化為稠密向量形式表達的服務,支持多款不同語言、輸入長度、輸出維度的文本向量模型,可用于信息檢索、文本分類、相似性比較等場景。
- 文本稀疏向量化提供將文本數據轉化為稀疏向量形式表達的服務,稀疏向量存儲空間更小,常用于表達關鍵詞和詞頻信息,可與稠密向量搭配進行混合檢索,提升最終檢索效果。
- 向量微調服務提供向量模型調優服務,可通過定制訓練向量降維模型,在不帶來過多檢索效果損失的情況下,輔助將高維度向量降低維度,以便提升性價比。
5. 查詢分析服務
提供 Query 內容分析服務,基于大語言模型及 NLP 能力,可對用戶輸入的查詢內容進行意圖識別、相似問題擴展、NL2SQL 處理等,有效提升 RAG 場景中檢索問答效果。
6. 搜索引擎
提供向量檢索、文本檢索引擎,可進行向量&文本內容存儲、構建索引、以及在線向量&文本檢索,開通引擎服務后,可與 AI 搜索開放平臺豐富的API服務組合使用。
7. 排序服務
提供 Query 及 DOC 的相關性排序服務,在 RAG 及搜索場景中,可通過排序服務找到相關性更高的內容并依次返回,引入排序服務可有效提升檢索及大模型生成的準確率。
8. 大模型內容生成服務
提供多種大語言模型服務,包含 DeepSeek 全系模型(含R1/V3及7B/14B蒸餾版本)、通義系列通義千問-Turbo、通義千問-Plus、通義千問-Max大模型。同時內置 OpenSearch- 通義千問 -Turbo 大模型,該模型以 qwen-turbo 大規模語言模型為模型底座,進行有監督的模型微調強化 RAG 檢索增強的能力,降低模型幻覺率。
三、新功能介紹
1. 大模型聯網能力
通過集成大語言模型(LLM)和聯網搜索技術,為用戶提供更智能、更全面的搜索體驗。了解更多
2. GTE 多語言文本向量化模型
GTE 多語言通用文本向量模型(iic/gte_sentence-embedding_multilingual-base),來源于 ModelScope 模型庫,并開放自部署能力,助力企業構建更高并發、更低延遲的多語言搜索與分析系統。了解更多
3. 服務開發能力
服務開發能力,旨在通過集成 dsw 能力并新增 notebook 功能,進一步提升用戶編排效率。了解更多
4. Qwen3 模型
通義最新大模型 Qwen3 是 Qwen 系列中最新一代的大型語言模型,提供了一整套密集和混合專家模型(MoE)。基于廣泛的訓練,Qwen3 在推理、指令跟隨、Agent 能力和多語言支持方面取得了突破性進展。了解更多
5. QWQ 模型
基于 Qwen2.5-32B 模型訓練的 QwQ 推理模型,通過強化學習大幅度提升了模型推理能力。模型數學代碼等核心指標(AIME 24/25、LiveCodeBench)以及部分通用指標(IFEval、LiveBench等)達到DeepSeek-R1 滿血版水平,各指標均顯著超過同樣基于 Qwen2.5-32B 的 DeepSeek-R1-Distill-Qwen-32B。了解更多
四、計費
阿里云 AI 搜索開放平臺均采用按量付費模式,按照服務調用量與模型定制訓練實際消耗的計算時(CU)計費。
部分示例:
| 模型名稱 | 模型ID | 計費單位 | 0-500個單位定價 | 超出500個單位定價 |
| 文檔內容解析 | ops-document-analyze-001 | 元/千tokens | 0.005 | 0.002 |
| 元/張圖片 | 0.006 | |||
| 元/個表格 | 0.012 | |||
| 圖片文本識別 | ops-image-analyze-ocr-001 | 元/次 | 0.08 | 0.02 |
| 文檔切片 | ops-document-split-001 | 元/千tokens | 0.005 | 0.00002 |
| 文本稀疏向量 | ops-text-sparse-embedding-001 | 元/千tokens | 0.006 | 0.0006 |
| 排序服務 | ops-bge-reranker-larger | 元/個docs | 0.001 | 0.00003 |
| ops-text-reranker-001 | 元/個docs | 0.001 | 0.00015 | |
- 更多計費詳情點擊查看
五、結尾
阿里云 AI 搜索旨在幫助用戶簡化搜索應用的構建過程,提供豐富的開箱即用服務,涵蓋多模態數據處理、精準搜索算法、效果測評與場景開發,全面滿足各種搜索需求。
了解更多:阿里云 AI 搜索開放平臺







)); 講解一下語法)
)










Mono中的重要內容(1)延時函數)