在當今數字經濟時代,實時流數據正成為企業核心競爭力。金融機構需要實時風控系統在欺詐交易發生的瞬間進行攔截;電商平臺需要根據用戶實時行為提供個性化推薦;工業物聯網需要監控設備狀態預防故障。這些場景都要求系統能夠“即時感知、即時分析、即時響應”。
一、什么是實時流數據?
實時流數據是指持續產生、動態變化且需要即時處理的數據流。與傳統批處理模式相比,實時流數據處理能夠在數據產生的同時進行分析和響應,將數據價值的實現時間從“小時/天級”壓縮至“秒/毫秒級”。
核心特征:
-
高吞吐:能夠處理每秒數十萬至數百萬條數據記錄;
-
低延遲:從數據產生到分析結果輸出的端到端延遲通常在秒級以內;
-
無界性:數據持續不斷地產生,理論上沒有終點;
二、流數據的處理流程
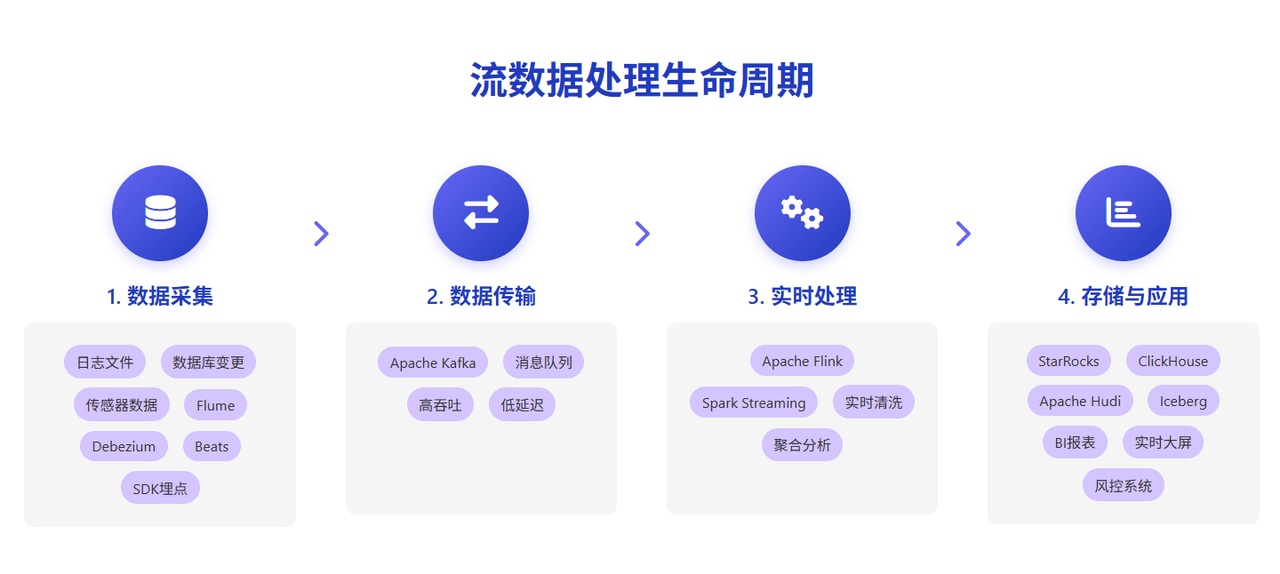
流數據的生命周期通常包含四個環節: 采集→傳輸→處理→存儲/應用。
1. 數據采集
日志文件(如 audit.log)、數據庫變更(如 MySQL 的 Binlog)、傳感器數據等通過工具(如 Flume、Debezium)實時采集。例如, 歡聚集團通過 Beats 組件收集日志,金融場景則依賴 SDK 埋點捕獲交易行為。
2. 數據傳輸
消息隊列(如 Apache Kafka)是流數據的“高速公路”,支持高吞吐、低延遲的傳輸。例如,在實際應用中, 芒果 TV 的實時業務數據通過 Kafka 分發至下游處理系統,而騰訊大數據則依賴 Kafka 構建湖倉一體化的數據管道。
3. 實時處理
流計算引擎(如 Apache Flink、Spark Streaming)對數據進行清洗、聚合或復雜分析。例如, 得物電商通過 Flink 實時消費 Kafka 數據,以微批方式(十秒一次)寫入 StarRocks,滿足高并發查詢需求。
4. 存儲與應用
處理后的數據存入實時數倉(如 StarRocks、ClickHouse)或數據湖(如 Apache Hudi、Iceberg),支撐 BI 報表、實時大屏、風控等場景。例如, 碧桂園物業通過 StarRocks 實現億級數據毫秒級響應,支持企業微信的實時查詢。
三、實時流數據的處理流程
一個完整的實時流數據處理架構通常包含三個關鍵層次:
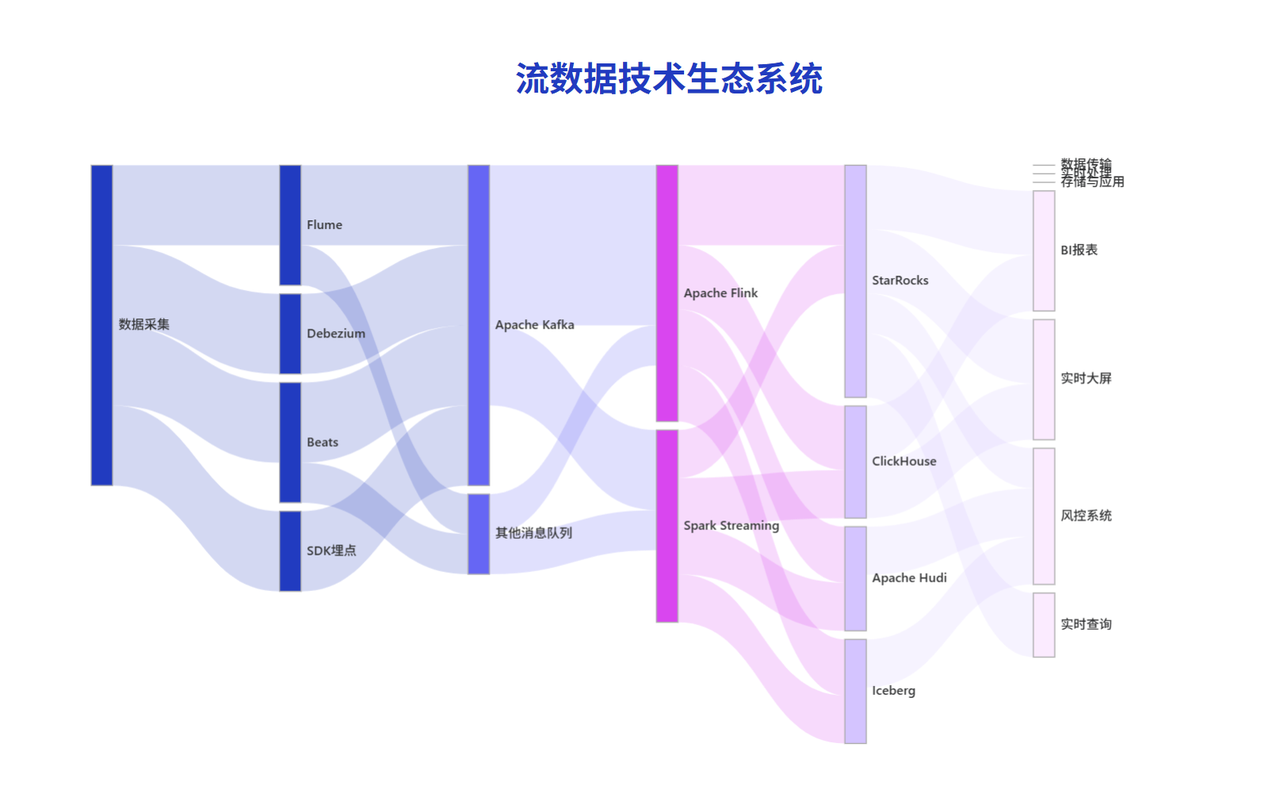
1. 數據采集層
負責高效、可靠地捕獲和傳輸數據流,主流技術包括:
-
Apache Kafka:高吞吐消息隊列,實現數據緩沖和解耦;
-
Flink CDC:變更數據捕獲,實時獲取數據庫變更事件;
-
日志采集工具:如 Fluentd、Logstash 等;
2. 數據處理層
進行實時計算和轉換,核心引擎包括:
-
Apache Flink:低延遲、高吞吐的分布式流處理框架;
-
Spark Streaming:基于微批處理模式的準實時計算引擎;
3. 數據存儲與分析層
存儲處理結果并支持實時查詢分析:
-
OLAP 數據庫:以 StarRocks 為例,作為新一代 MPP 數據庫,其憑借 流批一體能力脫穎而出:
-
實時寫入:通過 Stream Load(微批)、Routine Load(Kafka 直連)實現秒級延遲。
-
動態更新:主鍵模型支持 CDC 數據實時更新,查詢性能較傳統方案提升 3-10 倍。
-
統一分析:聯邦查詢可融合數據湖(如 Hudi)與實時數倉,避免冗余存儲。
-
-
實時 數據倉庫:支持流式數據實時入庫和查詢;
典型應用場景——實時監控與報表
網易郵箱 ——10 億級用戶行為實時風控與高并發查詢
核心痛點
-
資源瓶頸:10 億存量用戶+PB 級日志數據,ClickHouse 與 Kafka 資源壓力過大,導致報警頻發,影響業務連續性。
-
查詢效率低下:跨表查詢需多系統協作,億級數據關聯耗時過長,風控響應無法滿足 99.99% SLA 要求。
-
數據鏈路臃腫:離線與實時數據分儲于 HDFS 與 ClickHouse,開發迭代周期長,難以應對業務快速變化。
解決方案
- 架構升級:引入 StarRocks 作為統一存儲層,聚合 ClickHouse 實時數倉數據,構建流批一體查詢引擎。
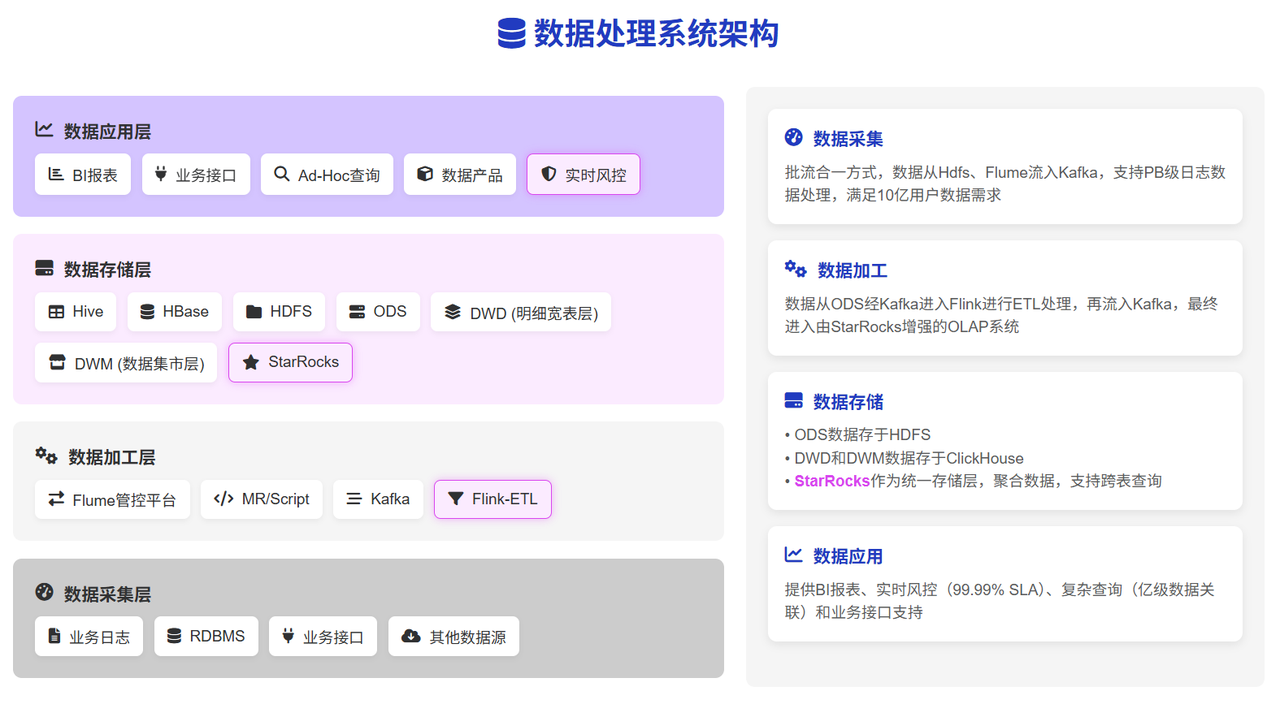
-
模型優化:
-
明細模型存儲全量用戶登錄行為數據,支撐海量數據落盤;
-
聚合模型實現實時風控指標秒級計算(如敏感行為閾值監控);
-
跨表查詢能力簡化漏斗分析,億級大表關聯查詢耗時降至 2 分鐘以內。
-

- 成本優化:替換 ClickHouse 部分場景,減少 30%服務器資源占用。
成果與數據收益
-
性能提升:高并發查詢響應時間從秒級降至 50 毫秒內,風控規則觸發延遲<1 秒;
-
效率突破:復雜跨表查詢效率提升 5 倍,支撐每日 1 萬+數據服務調用;
-
成本降低:運維人力減少 40%,硬件采購成本下降 25%。
四、未來趨勢:流批融合與湖倉一體化
2025 年的技術演進呈現兩大方向:
1. 流批一體存儲
數據湖(如 Hudi、 Apache Paimon)與實時數倉(StarRocks)的邊界逐漸模糊,通過統一存儲減少冗余。例如, 同程旅行用 Paimon+StarRocks 替代 Kudu,實現全鏈路實時。
2. Serverless 與云原生
云原生湖倉(如 StarRocks 3.0)支持多源數據聯邦分析,彈性擴縮容降低成本。未來湖倉將趨向“數據庫化”,以簡化流程并賦能 AI。
結語
從日志分析到金融風控,從實時推薦到物聯網運維,流數據的價值在于將“數據滯后”轉化為“即時行動”。隨著流批一體和 湖倉一體化技術的成熟,2025 年的實時流數據計算正邁向更高效、更普惠的新紀元。
文本識別-Java項目實踐)



單例模式)
)


:從愿景到落地的精益開發路徑——Rally的全流程管理實踐)
函數 | 4.3、apply() 與 call() 方法)




)

)
)

