集成學習方法之隨機森林
- 1 集成學習
- 2 隨機森林的算法原理
- 2.1 Sklearn API
- 2.2 示例
1 集成學習
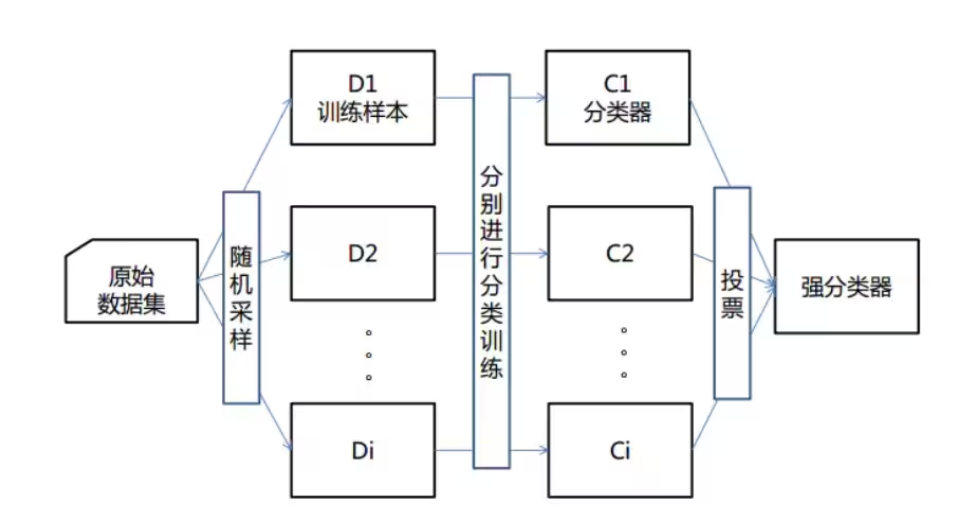
機器學習中有一種大類叫集成學習(Ensemble Learning),集成學習的基本思想就是將多個分類器組合,從而實現一個預測效果更好的集成分類器。集成算法可以說從一方面驗證了中國的一句老話:三個臭皮匠,賽過諸葛亮。集成算法大致可以分為:Bagging,Boosting 和 Stacking 三大類型。
(1)每次有放回地從訓練集中取出 n 個訓練樣本,組成新的訓練集;
(2)利用新的訓練集,訓練得到M個子模型;
(3)對于分類問題,采用投票的方法,得票最多子模型的分類類別為最終的類別;
2 隨機森林的算法原理
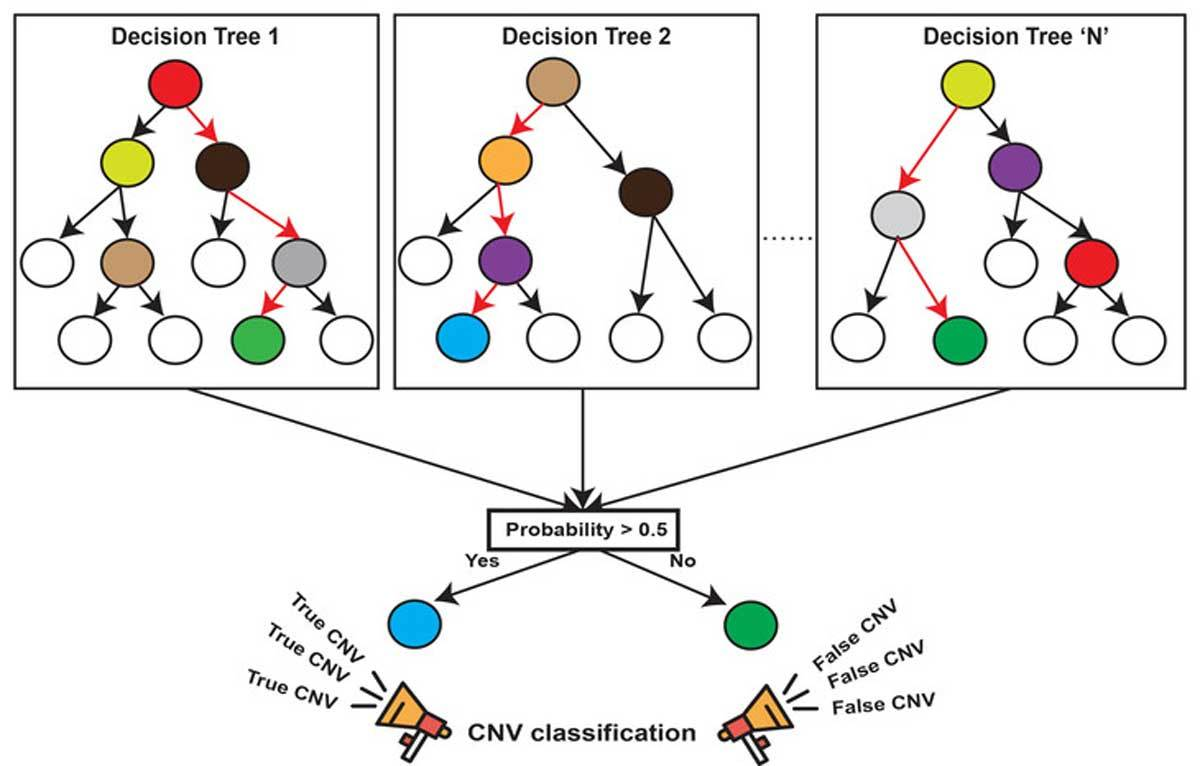
隨機森林就屬于集成學習,是通過構建一個包含多個決策樹(通常稱為基學習器或弱學習器)的森林, 每棵樹都在不同的數據子集和特征子集上進行訓練,最終通過投票或平均預測結果來產生更準確和穩健的預測。這種方法不僅提高了預測精度,也降低了過擬合風險,并且能夠處理高維度和大規模數據集
特點:
- 隨機: 特征隨機,訓練集隨機
- 樣本:對于一個總體訓練集T,T中共有N個樣本,每次有放回地隨機選擇n個樣本。用這n個樣本來訓練一個決策樹。
- 特征:假設訓練集的特征個數為d,每次僅選擇k(k<d)個來構建決策樹。
- 森林: 多個決策樹分類器構成的分類器, 因為隨機,所以可以生成多個決策樹
- 處理具有高維特征的輸入樣本,而且不需要降維
- 使用平均或者投票來提高預測精度和控制過擬合
2.1 Sklearn API
class sklearn.ensemble.RandomForestClassifier參數:
n_estimators int, default=100
森林中樹木的數量。(決策樹個數)criterion {“gini”, “entropy”}, default=”gini” 決策樹屬性劃分算法選擇當criterion取值為“gini”時采用 基尼不純度(Gini impurity)算法構造決策樹,當criterion取值為 “entropy” 時采用信息增益( information gain)算法構造決策樹.max_depth int, default=None 樹的最大深度。
2.2 示例
坦尼克號乘客生存
代碼如下:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.feature_extraction import DictVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
import joblib
def train():# 數據集加載titanic=pd.read_csv(r"..\22day4.25機器學習\src\titanic\titanic.csv")# 數據集處理#獲取關鍵特征titanic=titanic[['age','pclass','sex','survived']]# 將其中的缺省值賦值為這個列的平均值titanic["age"].fillna(titanic["age"].mean(),inplace=True)# 獲取特征值和目標值x=titanic[['age','pclass','sex']]y=titanic[['survived']].to_numpy()# 將x轉化為字典x=x.to_dict(orient='records')# 字典向量化vac=DictVectorizer(sparse=True)x=vac.fit_transform(x).toarray()# 劃分數據集x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=22,shuffle=True)# 標準化transfer=StandardScaler()x_train=transfer.fit_transform(x_train)x_test=transfer.transform(x_train)print(x_test.shape,y_test.shape)# 模型建立model=RandomForestClassifier(n_estimators=10,max_depth=4)# 訓練模型model.fit(x_train,y_train)# 模型評估score=model.score(x_test,y_test)print(score)# 保存模型joblib.dump(model,r"..\23day5.8\src\model\rf.pkl")joblib.dump(transfer,r"..\23day5.8\src\model\rf_transfer.pkl")joblib.dump(vac,r"..\23day5.8\src\model\rf_vac.pkl")
def detect():model=joblib.load(r"..\23day5.8\src\model\rf.pkl")transfer=joblib.load(r"..\23day5.8\src\model\rf_transfer.pkl")vac=joblib.load(r"..\23day5.8\src\model\rf_vac.pkl")x_test=[{'age':24,'pclass':'1st','sex':"male"}]x_test=vac.transform(x_test).toarray()# print(x_test)x_test=transfer.transform(x_test)prd=model.predict(x_test)print(prd)
if __name__=="__main__":train()# predict()detect()






高頻面試題)



Java虛擬線程與傳統線程對比)

)


)

![httpx[http2] 和 httpx 的核心區別及使用場景如下](http://pic.xiahunao.cn/httpx[http2] 和 httpx 的核心區別及使用場景如下)
