目錄
- 前言
- 一、 背景與核心概念
- 1-1、多模態大語言模型(MLLMs)的定義
- 二、MLLMs的架構設計
- 2-1、三大核心模塊
- 2-2、架構優化趨勢
- 三、訓練策略與數據
- 3-1、 三階段訓練流程
- 四、 評估方法
- 4-1、 閉集評估(Closed-set)
- 4-2、開集評估(Open-set)
- 4-3、多模態幻覺評估
- 4-4、 多模態綜合能力評估
- 五、擴展方向與技術
- 5-1、模態支持擴展
- 5-2、 交互粒度擴展
- 5-3、語言與文化擴展
- 5-4、 垂直領域擴展
- 5-5、效率優化擴展
- 5-6、 新興技術融合
- 總結
前言
這篇綜述系統梳理了多模態模型的技術棧,從基礎架構到前沿應用,并指出當前瓶頸(如幻覺、長上下文)和解決思路。其核心價值在于(1)方法論:三階段訓練(預訓練→指令微調→對齊)成為主流范式。(2)開源生態:LLaVA、MiniGPT-4等開源模型推動社區發展。(3)跨學科應用:在醫療、機器人等領域的滲透展示通用潛力。一、 背景與核心概念
1-1、多模態大語言模型(MLLMs)的定義
核心思想:以強大的大語言模型(如GPT-4、LLaMA)為“大腦”,通過模態接口(如視覺編碼器)將圖像、音頻、視頻等非文本模態與文本模態對齊,實現跨模態理解和生成。
與傳統多模態模型的區別:
- 規模:MLLMs基于百億參數規模的LLMs,而傳統模型(如CLIP、OFA)參數更小。
- 能力:MLLMs展現涌現能力(如復雜推理、指令跟隨),傳統模型多為單任務專用。
多模態模型發展線如下所示:
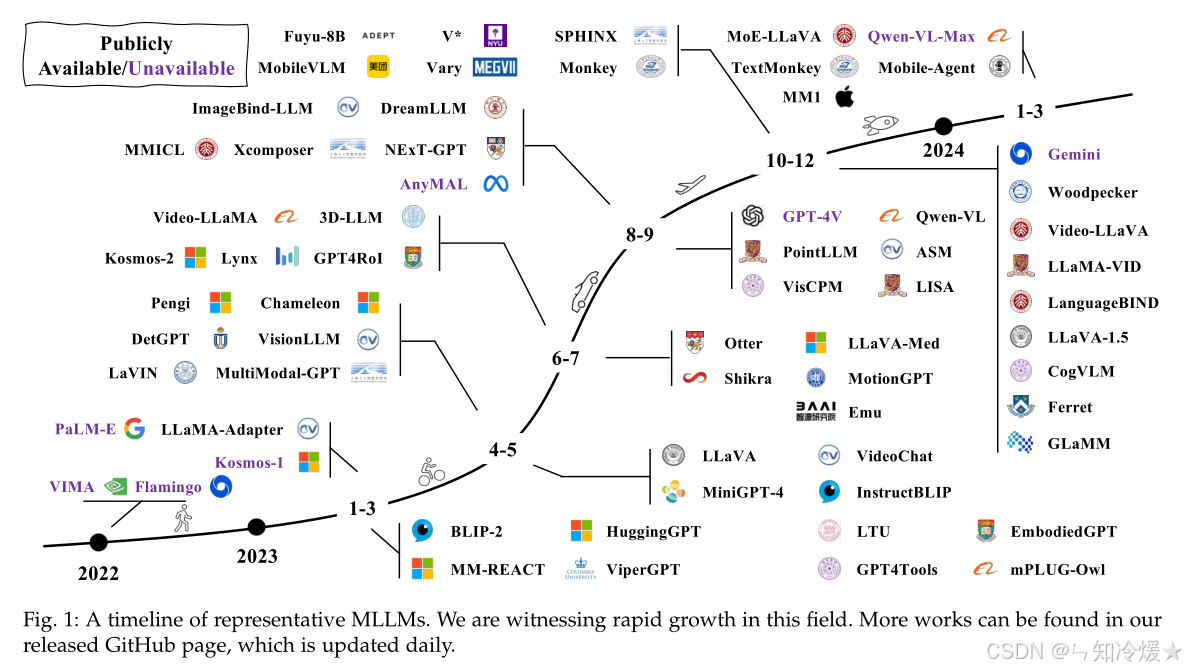
二、MLLMs的架構設計
2-1、三大核心模塊
1、模態編碼器(Modality Encoder)(眼睛/耳朵)
功能:將原始數據(如圖像、音頻、視屏等)轉換為特征表示,使其能夠與文本模態對其。(例如圖像、音視頻編碼器)
常用模型:
-
圖像:CLIP-ViT、EVA-CLIP(更高分辨率支持)、ConvNeXt(卷積架構)。
-
音頻:CLAP、ImageBind(支持多模態統一編碼)。
關鍵發現:輸入分辨率對性能影響顯著(如448x448比224x224更優)。即更高的分辨率可以獲得更加顯著的性能。
如圖所示為常用的圖像編碼器:

2、大語言模型(LLM)(大腦)
功能: 作為MLLM的“大腦”,負責整合多模態信息,執行推理,生成文本輸出。
-
選擇:開源模型(LLaMA-2、Vicuna)或雙語模型(Qwen)。
-
參數規模的影響:從13B→34B參數提升,中文零樣本能力涌現(即使訓練數據僅為英文)。
-
知識注入:領域適配,例如數據微調,或者工具調用,即通過指令微調教會LLM調用外部API。
如圖所示為常用公開的大語言模型:

3、模態接口(Modality Interface):用于對齊不同的模態
可學習接口:
-
Token級融合:如BLIP-2的Q-Former,將視覺特征壓縮為少量Token。
-
特征級融合:如CogVLM在LLM每層插入視覺專家模塊。
**專家模型:**調用現成模型(如OCR工具)將圖像轉為文本,再輸入LLM(靈活性差但無需訓練)。
如圖所示為典型多模態模型架構示意圖:
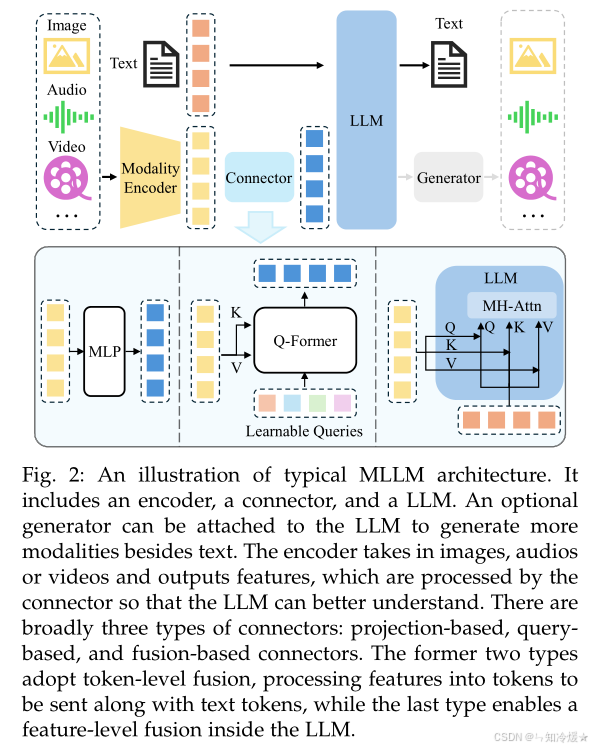
4、模塊協同工作示例(以LLaVA為例)
- 圖像編碼:CLIP-ViT將圖像編碼為視覺特征。
- 特征對齊:通過兩層MLP將視覺特征投影到LLaMA的文本嵌入空間。
- 指令微調:聯合訓練視覺-文本特征,使LLaMA能理解“描述圖像中第三只貓的顏色”。
- 推理生成:LLaMA基于對齊特征生成自然語言響應。
2-2、架構優化趨勢
高分辨率支持:通過分塊(Monkey)、雙編碼器(CogAgent)處理高分辨率圖像。
稀疏化:混合專家(MoE)架構(如MoE-LLaVA)在保持計算成本的同時增加參數量。
三、訓練策略與數據
3-1、 三階段訓練流程
1、預訓練(Pretraining)
目標:將不同模態(如圖像、音頻)的特征映射到統一的語義空間,通過大規模數據吸收通用知識(如物體識別、基本推理)。
數據:大規模粗粒度圖文對(如LAION-5B)或高質量細粒度數據(如GPT-4V生成的ShareGPT4V)。計算圖文相似度,移除相似度太低的樣本。
關鍵技巧:凍結編碼器和LLM,僅訓練接口(防止災難性遺忘)。
如圖所示為預訓練所用的通用數據集:
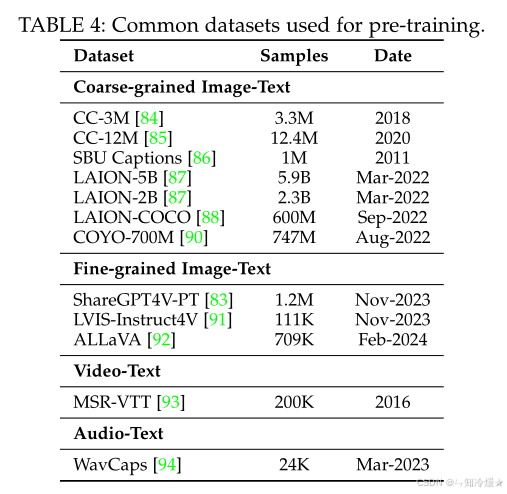
2、指令微調(Instruction Tuning)
目標:使模型能夠理解和執行多樣化的用戶指令(如“描述圖像中的情感”),指令調優學習如何泛化到不可見的任務。
數據構建方法:
- 任務適配:將VQA數據集轉為指令格式(如“Question: <問題> Answer: <答案>”)。
- 自指令生成:用GPT-4生成多輪對話數據(如LLaVA-Instruct)。
發現:
- 指令多樣性(設計不同句式(疑問句、命令句)和任務類型(描述、推理、創作))比數據量更重要。
- 數據質量比數量更重要。
- 包含推理步驟的指令,可以顯著提升模型的性能。
如圖所示描述任務的指令(相關范例):

3、對齊微調(Alignment Tuning)
目標:減少幻覺(確保生成內容與輸入模態一致(如不虛構圖中未出現的物體)),使輸出更符合人類偏好。(簡介、安全,符合倫理)
方法:
- RLHF:通過人類偏好數據訓練獎勵模型,再用PPO優化策略(如LLaVA-RLHF)。
- DPO:直接優化偏好對(無需顯式獎勵模型)。
如圖所示為三種典型學習范式的比較:
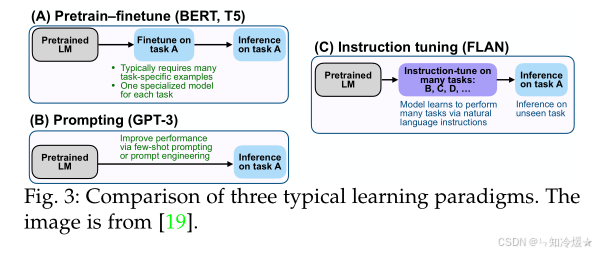
四、 評估方法
4-1、 閉集評估(Closed-set)
定義:在預定義任務和答案范圍內測試模型性能,適用于標準化任務(如分類、問答)。
核心指標:
- 準確率(Accuracy):直接匹配模型輸出與標準答案(如ScienceQA數據集)。
- CIDEr(Consensus-based Image Description Evaluation):衡量生成文本與參考描述的語義相似性(常用于圖像描述任務)。
- BLEU-4:基于詞重疊的機器翻譯指標,適用于短文本生成(如VQA簡短回答)。
4-2、開集評估(Open-set)
定義:評估模型在開放場景下的生成能力(如自由對話、創造性任務),答案不固定。
核心方法:
人工評分(Human Rating):
- 評分維度:相關性、事實性、連貫性、多樣性、安全性。
- 流程:標注員按1-5分對模型輸出打分(如LLaVA的對話能力評估)。
GPT-4評分(GPT-as-a-Judge):
- 方法:用GPT-4對模型輸出評分(示例提示):
Instruction: 請根據相關性(1-5分)和準確性(1-5分)評價以下回答:
問題:<問題>
模型回答:<回答>
- 優點:低成本、可擴展;缺點:依賴GPT-4的偏見和文本理解能力。
4-3、多模態幻覺評估
定義:檢測模型生成內容與輸入模態不一致的問題(如虛構圖中未出現的對象)。
評估方法:
POPE(Polling-based Object Probing Evaluation):
- 流程:生成多項選擇題(如“圖中是否有狗?”),統計模型回答的準確率。
- 指標:準確率、假陽性率(FP)。
CHAIR(Caption Hallucination Assessment with Image Relevance):
步驟:
- 提取生成描述中的所有名詞(如“貓、桌子”)。
- 檢測這些名詞是否在圖像中存在(通過目標檢測模型)。
指標:幻覺率(錯誤名詞占比)。
FaithScore:
方法:將生成文本拆分為原子事實(如“貓是黑色的”),用視覺模型驗證每個事實是否成立。
指標:原子事實準確率。
4-4、 多模態綜合能力評估
(1) 多維度基準測試
1、MME(Multimodal Evaluation Benchmark):
涵蓋能力:感知(物體計數、顏色識別)、認知(推理、常識)。
任務示例:
- 感知任務:“圖中紅色物體的數量?”
- 認知任務:“如果移除支撐桿,積木會倒塌嗎?為什么?”
指標:綜合得分(感知分 + 認知分)。
2、MMBench:
特點:覆蓋20+任務類型(如OCR、時序推理),使用ChatGPT將開放答案匹配到預定義選項。
指標:準確率(標準化為0-100分)。
五、擴展方向與技術
多模態大語言模型的擴展方向主要集中在提升功能多樣性、支持更復雜場景、優化技術效率以及拓展垂直領域應用。以下是具體分類與技術細節
5-1、模態支持擴展
一、 輸入模態擴展
1、3D點云(Point Cloud)
技術:將3D數據(如LiDAR掃描)編碼為稀疏或密集特征。
案例:
- PointLLM:通過投影網絡將點云特征對齊到LLM的文本空間,支持問答(如“房間中有多少把椅子?”)。
- 3D-LLM:結合視覺和3D編碼器,實現跨模態推理(如分析物體空間關系)。
挑戰:3D數據的高維稀疏性、計算開銷大。
2、傳感器融合(Sensor Fusion)
技術:整合多種傳感器數據(如熱成像、IMU慣性測量)。
案例:
- ImageBind-LLM:支持圖像、音頻、深度、熱成像等多模態輸入,通過統一編碼器對齊特征。
應用:自動駕駛(融合攝像頭、雷達、激光雷達數據)。
二、輸出模態擴展
1、多模態生成:
技術:結合擴散模型(如Stable Diffusion)生成圖像、音頻或視頻。
案例:
- NExT-GPT:輸入文本生成圖像+音頻,或輸入視頻生成文本描述+配樂。
- Emu:通過視覺解碼器生成高分辨率圖像,支持多輪編輯(如“將圖中的貓換成狗”)。
指標:生成質量(FID、CLIP Score)、跨模態一致性。
5-2、 交互粒度擴展
一、細粒度輸入控制
1、區域指定(Region-specific):
技術:支持用戶通過框選(Bounding Box)、點擊(Point)指定圖像區域。
案例:
- Ferret:接受點、框或草圖輸入,回答與指定區域相關的問題(如“這個紅框內的物體是什么?”)。
- Shikra:輸出回答時自動關聯圖像坐標(如“左側的狗(坐標[20,50,100,200]在奔跑”)。
2、像素級理解(Pixel-level):
技術:結合分割模型(如Segment Anything)實現掩碼級交互。
案例:
- LISA:通過文本指令生成物體掩碼(如“分割出所有玻璃杯”)。
二、多輪動態交互
歷史記憶增強:
技術:在對話中維護跨模態上下文緩存(如緩存前幾輪的圖像特征)。
案例:
- Video-ChatGPT:支持多輪視頻問答(如“第三秒出現的車輛是什么品牌?”)。
5-3、語言與文化擴展
一、多語言支持
低資源語言適配:
技術:通過翻譯增強(Translate-Train)或跨語言遷移學習。
案例:
- VisCPM:基于中英雙語LLM,用英文多模態數據訓練,通過少量中文數據微調實現中文支持。
挑戰:缺乏非拉丁語系的圖文對齊數據(如阿拉伯語、印地語)。
二、文化適應性
本地化內容生成:
技術:在指令數據中注入文化特定元素(如節日、習俗)。
案例:
- Qwen-VL:支持生成符合中文文化背景的描述(如“端午節龍舟賽”)。
5-4、 垂直領域擴展
一、醫療領域
技術:領域知識注入(如醫學文獻微調)、數據增強(合成病理圖像)。
案例:
- LLaVA-Med:支持胸部X光診斷問答(如“是否存在肺炎跡象?”),準確率超放射科住院醫師平均水平。
挑戰:數據隱私、倫理審查。
二、自動駕駛
技術:多傳感器融合、實時性優化(如模型輕量化)。
案例:
- DriveLLM:結合高精地圖和攝像頭數據,回答復雜駕駛場景問題(如“能否在此路口變道?”)。
三、工業檢測
技術:高分辨率缺陷檢測、小樣本學習。
案例:
- Industrial-VLM:通過文字提示定位產品缺陷(如“檢測電路板上的虛焊點”)。
5-5、效率優化擴展
一、輕量化部署
技術:
- 模型壓縮:量化(INT8)、知識蒸餾(如TinyLLaVA)。
- 硬件適配:針對移動端(如NPU)優化計算圖。
案例:
- MobileVLM:1.4B參數模型可在手機端實時運行,支持圖像描述和簡單問答。
二、混合專家(MoE)架構
技術:稀疏激活,僅調用部分專家模塊處理輸入。
案例:
- MoE-LLaVA:在視覺問答任務中,MoE架構比同參數規模模型準確率提升5%-10%。
5-6、 新興技術融合
一、具身智能(Embodied AI)
技術:將MLLMs與機器人控制結合,實現“感知-推理-行動”閉環。
案例:
- PALM-E:通過視覺-語言模型控制機械臂完成復雜操作(如“把紅色積木放在藍色盒子旁邊”)。
二、增強現實(AR)
技術:實時多模態交互(如語音+手勢+視覺)。
案例:
- AR-LLM:在AR眼鏡中疊加MLLM生成的實時導航提示(如“前方路口右轉”)。
參考文章:
多模態模型綜述文章
Github地址
注意: 原文內容較多,本文僅限部分內容筆記,建議直接閱讀原文。
總結
好困,真的好困。🐑
![[已解決] LaTeX “Unicode character“ 報錯 (中文字符處理)](http://pic.xiahunao.cn/[已解決] LaTeX “Unicode character“ 報錯 (中文字符處理))

智能化專項匯報方案)
!!!學會Python爬蟲輕松賺外快】)

調度邏輯)











)

