思維導圖:
一、Redis集群概述
(一)廣義集群與狹義集群的定義
- ??廣義集群??:指由多個機器組成的分布式系統,例如前面提到的主從模式和哨兵模式。
- ??狹義集群??:Redis提供的集群模式,主要用于解決存儲空間不足的問題。
(二)Redis集群的核心思想
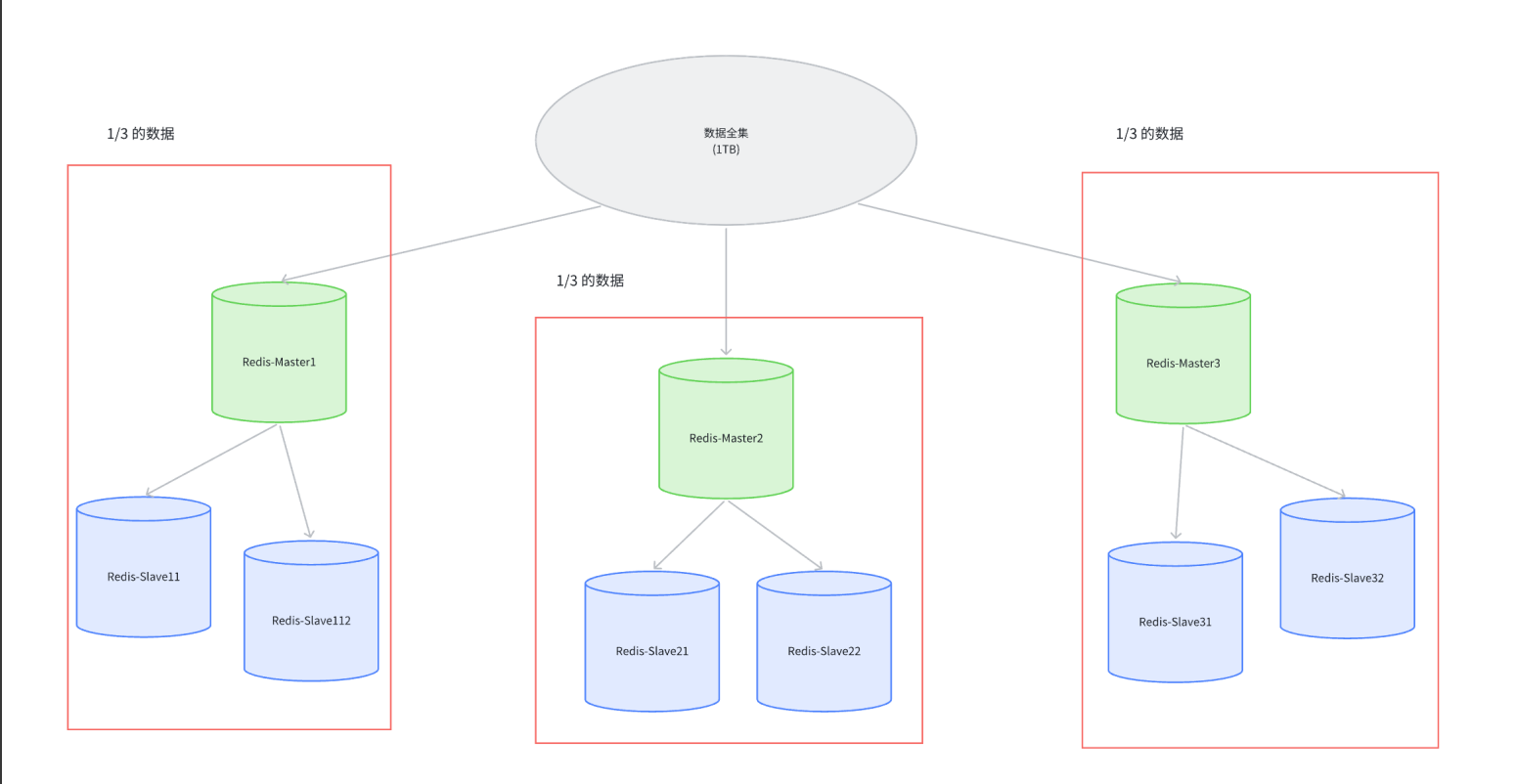
Redis集群通過引入多組Master/Slave架構,每組Master/Slave負責存儲數據全集的一部分,從而實現數據的分布式存儲和高可用性。
圖片中的每一個紅框,都可以稱作一個分片,也就是說,理論上如果數據量進一步增加,只要繼續增加分片的數量即可。
那么接下來的問題就是,給定一個數據,這個數據應該放在哪個分片上呢,取數據的時候又應該到哪個片段讀取?
二、數據分片算法
(一)哈希求余算法
- ??原理??:通過哈希函數對數據key進行映射,得到的整數再對分片數量求余,確定數據所在分片。
節點位置 = hash(key) % 節點數量 - ??缺點??:由于數據的分布是隨機的,在加入一個切片后,所有的數據需要重新分配區間,大量的數據需要遷移。數據遷移成本高,尤其在數據量過大時。
(二)一致性哈希算法
- ??原理??:
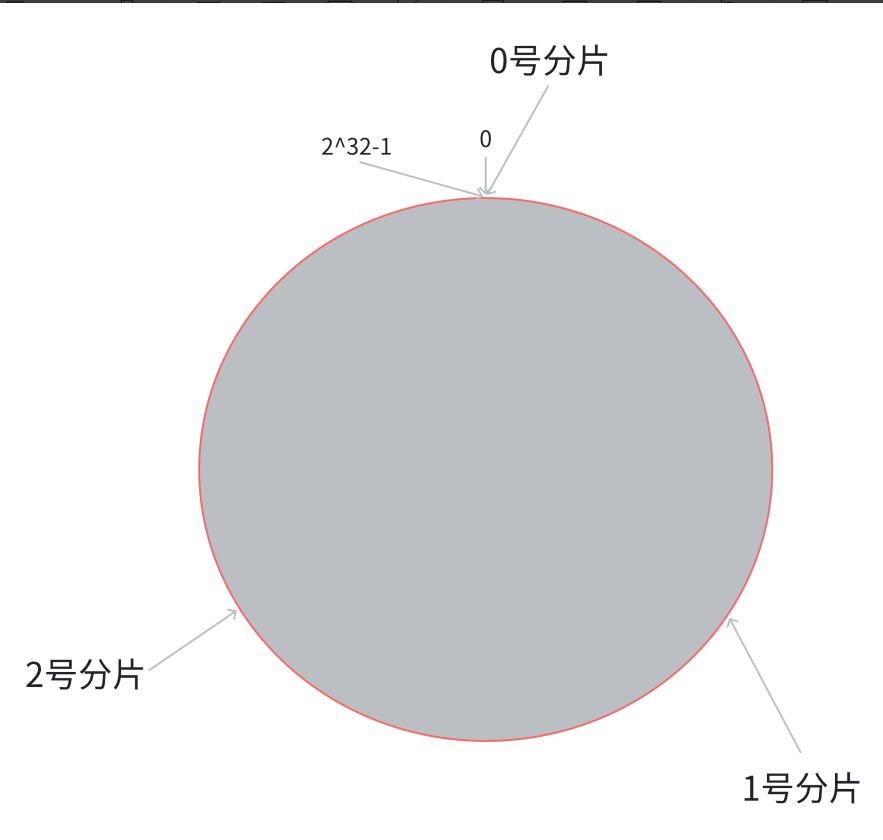
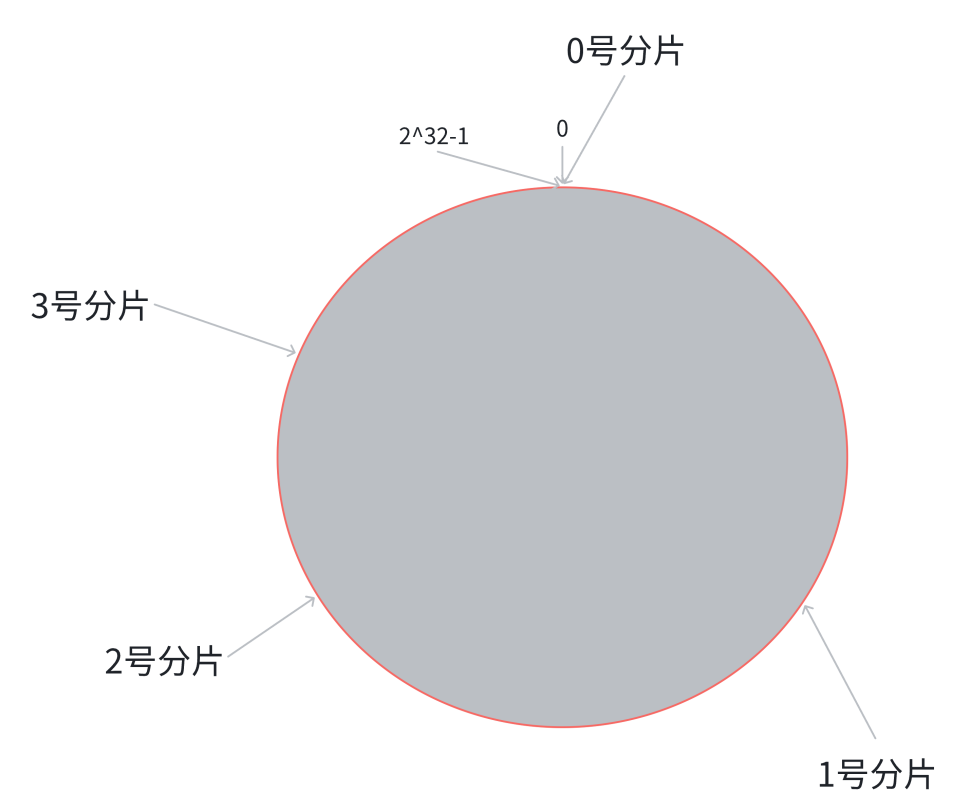
1.將1 ~ 2^32 - 1均勻分布在一個圓環上。

2.將整個圓劃分為三個分片
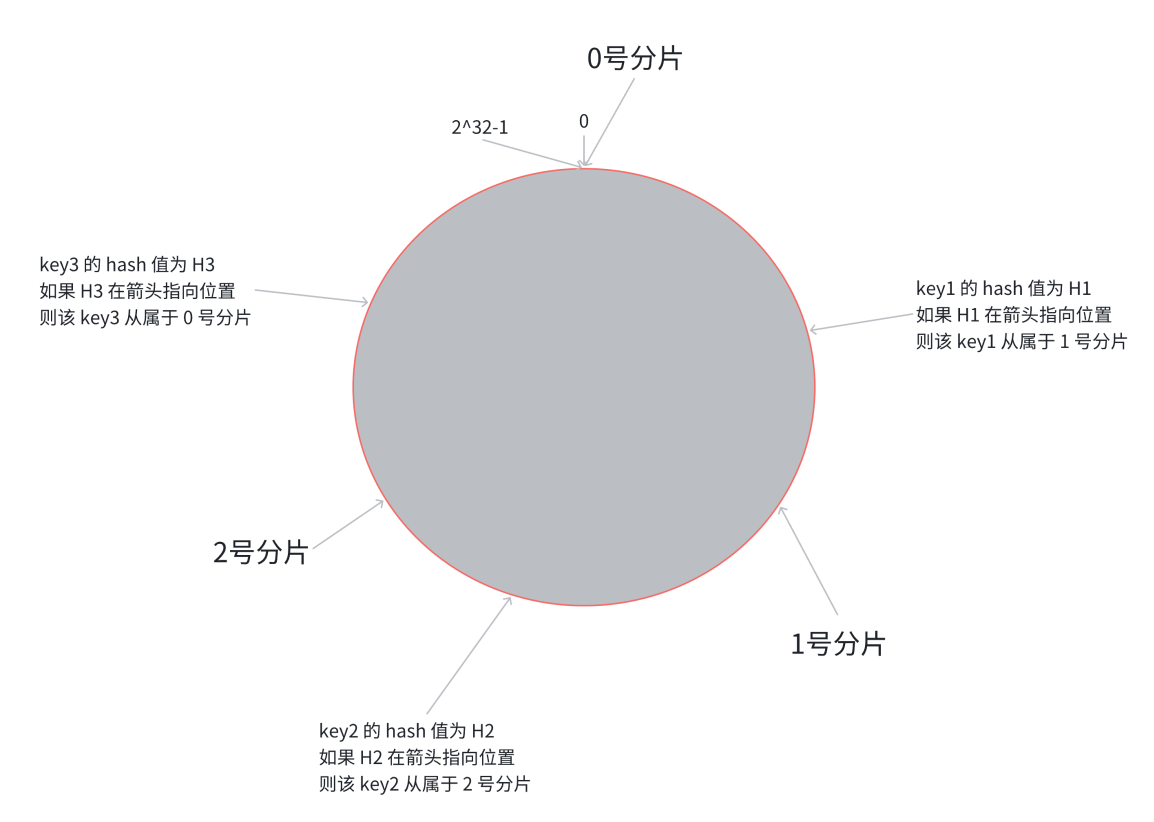
3.找到相應分片的方法就是找到數據的 hash 值,落到某個點,然后順時針旋轉,對應的分片就是所屬分片
- ??缺點??:在這種情況下,如果想進行擴容操作,那就可以在 0 號分片和 2 號分片中間插入 3 號分片,然后把原屬于 0?號 和 2 號的部分數據遷移到 3 號,這樣數據遷移的數量就會大大降低。但是同時也帶來了一個問題,那就是分片的數據不均勻,導致數據傾斜。
(三)哈希槽分區算法
- ??原理??:
- Redis集群采用哈希槽分區算法,將整個數據集劃分為16384個槽位,每個節點負責一部分槽位。
- 假設當前有三個分片,一種可能的分配方式:
- 0號分片: [0, 5461],共5462個槽位。
- 1號分片: [5462, 10923],共5462個槽位。
- 2號分片: [10924, 16383],共5460個槽位。
這里的分片規則是很靈活的,每個分片持有的槽位不一定連續。每個分片的節點使用位圖來表示自己持有哪些槽位。對于16384個槽位來說,需要2048個字節(2KB)大小的內存空間表示。
- 如果需要進行擴容,比如新增一個3號分片,就可以針對原有的槽位進行重新分配。例如一種可能的分配方式:
- 0號分片: [0, 4095],共4096個槽位。
- 1號分片: [5462, 9557],共4096個槽位。
- 2號分片: [10924, 15019],共4096個槽位。
- 3號分片: [4096, 5461] + [9558, 10923] + [15019, 16383],共4096個槽位。
在實際使用Redis集群分片的時候,不需要手動指定哪些槽位分配給某個分片,只需要告訴某個分片應該持有多少個槽位即可,Redis會自動完成后續的槽位分配,以及對應的key搬運的工作。
- ??優點??:擴展性強,數據分布均勻。
數據分片相關問題
-
??Redis集群最多時有16384個分片嗎???
- 雖然理論上可以支持16384個分片,但實際應用中建議不超過1000個分片,以避免數據傾斜和系統不穩定。
- 分片過多會導致服務程序涉及的機器數量激增,增加系統不穩定性。
-
??為什么是16384個槽位???
- 節點間通過心跳包通信,心跳包需包含分片對應的槽位信息。
- 使用位圖表示槽位信息,占用2KB大小,適合頻繁交互的心跳包,減少網絡帶寬消耗。
三、基于Docker在云服務器上搭建Redis集群
(一)創建目錄和配置
- ??YAML文件??:使用Docker Compose定義集群節點和服務配置。
- ??Shell腳本??:批量創建每個節點的配置文件。
(二)創建Redis節點
- 使用Docker創建11個Redis節點(9個集群節點,2個擴容節點)。
(三)創建集群
- 使用
redis-cli --cluster create命令創建集群。 cluster nodes命令查看集群信息。
四、故障轉移機制
(一)故障判定
Redis集群中的故障判定依賴于節點間的心跳包通信。每個節點每秒會隨機向部分節點發送心跳包(避免全量發送導致的指數級增長)。心跳包包含節點ID、所屬分片、包含的槽位等信息。
- ??主觀下線(PFAIL)??
- 當一個節點(如A)向另一個節點(如B)發送ping包后,如果在規定時間內未收到B的pong包回復,A會重置與B的連接并再次發送ping包。
- 若再次發送后仍未收到回復,A就會主觀地認為B下線了,將B標記為PFAIL狀態。
- ??客觀下線(FAIL)??
- 當一個節點將某個節點標記為PFAIL后,它會通過Redis內置的Gossip協議與其他節點進行通信,詢問它們對目標節點狀態的看法。
- 如果超過半數的節點都認為該目標節點處于PFAIL狀態,那么這個目標節點就會被判定為FAIL狀態,此時故障轉移流程將被觸發。
(二)故障遷移
當主節點發生故障被判定為FAIL后,故障遷移過程如下:
- ??從節點參選資格判斷??
- 故障主節點的從節點會根據自身與主節點的數據差異等因素判斷是否有參選資格。
- ??休眠與拉票??
- 具有參選資格的從節點會進入休眠狀態,休眠時間計算方式為:500ms基礎時間+【0 - 500】隨機時間+排名 * 1000ms(offset越大,排名越靠前,即越小)。
- 當某個從節點先醒來后,會向其他節點發送拉票請求,但只有主節點能夠參與投票。
- ??新主節點選舉??
- 當某個從節點的票數超過當前主節點(故障主節點)的半數時,該從節點就會晉升為新主節點。
- 新主節點確定后,會將其信息同步給其他節點,同時哨兵節點會通知客戶端更新連接信息,以確保后續操作指向新的主節點。
(三)集群宕機情況
- 某個分片的主從節點全部掛掉。
- 主節點掛掉且無從節點。
- 超過半數的master節點故障。
五、集群擴容
(一)新主節點加入與槽位重分配
- ??新主節點加入??:將新的Redis節點加入到集群中。
- ??槽位重分配??:通過
redis-cli --cluster reshard命令重新分配槽位,將部分槽位從現有節點遷移到新節點。 - 在這個過程中,對于集群中的key,大部分是不用搬運的,在搬運的過程中,未搬運的key可以被客戶端訪問。對于正在搬運的key,可能就會出現訪問出錯的情況。就比如你正重定向到某個切片,但這個切片上的對應數據已經被搬運走了。所以為了更高的可用性,除了擴容,也可以搭建新的集群(一組新的機器),然后從舊的集群中克隆數據,使用新的集群代替舊的集群。(成本高)
(二)添加從節點
- 給新的主節點添加從節點以提高數據冗余和高可用性。








)





)


![[Java實戰]Spring Boot 整合 Freemarker (十一)](http://pic.xiahunao.cn/[Java實戰]Spring Boot 整合 Freemarker (十一))

