
數據科學必備技能:填補缺失值(Imputing Missing Values)
在數據分析和機器學習項目中,缺失值(Missing Values) 是非常常見的問題。缺失的數據如果處理不當,會嚴重影響模型的訓練效果,甚至導致模型性能大幅下降。因此,掌握缺失值填補的方法,是數據科學工作中非常重要的一步。
本文將基于一張圖,詳細介紹幾種常見且實用的缺失值填補方法,并結合實際例子進行講解。
1. 定量分析:用平均值填補
如果缺失的是定量變量(Quantitative Variable),如數值型數據:年齡、身高、收入等,常用均值(mean)進行填補。
原理:均值可以代表數據的整體水平,用均值填補可以盡量減少數據波動帶來的影響。
示例:
假設你有一組數據:
| 年齡 |
|---|
| 25 |
| 27 |
| NaN |
| 29 |
| 31 |
缺失了一個年齡值,可以先計算現有數據的平均值:
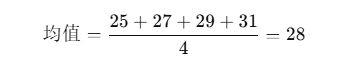
然后將缺失值填補為28。
代碼示例(Python + Pandas):
import pandas as pddf = pd.DataFrame({'Age': [25, 27, None, 29, 31]})
df['Age'].fillna(df['Age'].mean(), inplace=True)
print(df)
2. 定性分析:用眾數填補
如果缺失的是定性變量(Categorical Variable),如性別、城市類別、顏色等,常用眾數(mode)進行填補。
原理:眾數是出現次數最多的類別,使用眾數可以最大限度保持數據分布的一致性。
示例:
假設你的數據如下:
| 城市 |
|---|
| 北京 |
| 上海 |
| NaN |
| 北京 |
| 廣州 |
北京出現次數最多,因此缺失值可以填補為“北京”。
代碼示例(Python + Pandas):
import pandas as pddf = pd.DataFrame({'City': ['北京', '上海', None, '北京', '廣州']})
df['City'].fillna(df['City'].mode()[0], inplace=True)
print(df)
3. 使用模型預測填補缺失值
對于缺失值較多、或者缺失值和其他特征有明顯相關性的情況,可以使用預測模型來填補缺失值。例如,使用 K近鄰(KNN)、決策樹、線性回歸等算法。
3.1 K近鄰(KNN)填補
KNN可以根據數據中與缺失值樣本最相似的其他樣本的特征,預測其可能的取值。
原理簡述:
-
找到與缺失樣本最接近的K個完整樣本;
-
取這K個樣本中對應特征的均值(定量)或眾數(定性)作為填補值。
代碼示例(Python + sklearn):
import numpy as np
import pandas as pd
from sklearn.impute import KNNImputerdf = pd.DataFrame({'Height': [1.7, 1.8, np.nan, 1.6, 1.75],'Weight': [65, 80, 70, 60, 75]
})imputer = KNNImputer(n_neighbors=2)
df_filled = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)
print(df_filled)
拓展內容:其他常用填補策略
除了以上三種常見方法,還有一些高級處理方法:
-
插值法(Interpolation):適用于時間序列數據,比如線性插值、樣條插值等。
-
基于多重插補(MICE):多次預測缺失值,減少單次預測誤差。
-
直接刪除缺失行/列:如果缺失比例非常高,可以考慮刪除相關樣本或特征。
-
添加缺失值指示變量:為缺失的位置添加0/1標記,作為額外特征喂給模型。
選擇哪種方法,需要根據數據特點、業務需求、模型要求綜合判斷。
總結
| 場景 | 填補方法 |
|---|---|
| 定量分析(數值型) | 平均值填補 |
| 定性分析(類別型) | 眾數填補 |
| 缺失復雜、相關性強 | 建模預測填補 |
掌握缺失值處理的正確姿勢,可以有效提升數據質量,保證后續分析和建模的準確性。在實際工作中,建議結合探索性數據分析(EDA)對缺失情況進行全面了解后,制定最適合的填補策略。
如果你覺得本文有幫助,歡迎點贊、收藏或留言交流~



















