CosyVoice介紹
CosyVoice是阿里開源的一個多語言語音生成大模型,可應用于TTS(Text To Speech) 工具的開發。它支持內置預制語音生成、語音克隆、自然語言控制語音生成等功能。CosyVoice的另一個亮點在于它對生成語音情感和韻律的精細控制,這是通過富文本或自然語言輸入實現的。這種控制機制顯著提高了合成語音的情感表達能力,使得生成的語音更加栩栩如生,充滿情感色彩。這個系統支持中文、英文、日文、粵語和韓語五種語言的語音生成,并且在語音合成的效果上遠超傳統模型。
Github倉庫地址:https://github.com/FunAudioLLM/CosyVoice
官方在線體驗地址:魔搭社區
系統要求
無硬性要求,普通個人電腦也可以運行,不過推理耗時較長,只能用作嘗鮮體驗。如果機器有NVIDIA GPU,可以用NVIDIA CUDA加速。本文部署的機器使用GPUMart的RTX A4000 VPS,其GPU為NVIDIA RTX A4000,其顯存為16GB。
如何部署CosyVoice
步驟1. 克隆項目,安裝依賴
首先克隆官方項目,創建一套獨立的Python虛擬環境。
#因為項目內部引用了Matcha-TTS項目,所以記得使用--recursive參數 git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git#創建Python 3.8+環境并激活 conda create -n cosyvoice python=3.8 conda activate cosyvoice
此時已經激活了虛擬環境,現在下載項目依賴的第三方包。
#在具有美國IP的GPUMart服務器上 pip install -r requirements.txt#如果服務器在國內 pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
步驟2. 接著安裝Pynini
Pynini是一個基于字符串的傳播和轉換的庫,可以用于各種自然語言處理任務,如詞性標注、名詞短語提取和依賴句法分析。
conda install -y -c conda-forge pynini==2.1.5
步驟3. 下載模型
根據文檔要提前下載模型,這里不使用阿里的魔搭包下載,而是使用Git下載,前提是安裝git lfs 插件:
# git模型下載,請確保已安裝git lfs mkdir -p pretrained_models git clone https://www.modelscope.cn/iic/CosyVoice-300M.git pretrained_models/CosyVoice-300M git clone https://www.modelscope.cn/iic/CosyVoice-300M-SFT.git pretrained_models/CosyVoice-300M-SFT git clone https://www.modelscope.cn/iic/CosyVoice-300M-Instruct.git pretrained_models/CosyVoice-300M-Instruct
可選的,您可以下載、解壓 ttsfrd 資源并安裝 ttsfrd 包以獲得更好的文本規范化性能。請注意,此步驟不是必需的。如果您不安裝 ttsfrd 包,我們將默認使用 WeTextProcessing。
git clone https://www.modelscope.cn/iic/CosyVoice-ttsfrd.git pretrained_models/CosyVoice-ttsfrd cd pretrained_models/CosyVoice-ttsfrd/ unzip resource.zip -d . pip install ttsfrd-0.3.6-cp38-cp38-linux_x86_64.whl
步驟4. 啟動服務
模型文件非常大,又需要等待較長時間才能下載完成。完成后,使用以下命令啟動服務:
python3 webui.py --port 50000 --model_dir pretrained_models/CosyVoice-300M
有個要注意的地方,如果需要從外網訪問,需要把webui.py文件中
demo.launch(server_port=args.port)
改成
demo.launch(server_port=args.port, server_name="0.0.0.0")
如果是本機訪問可以忽略。這在最新的版本里不存在,默認是支持外網訪問的。這時訪問局域網IP加端口號50000就能訪問到這個由gradio庫搭建的WebUI 網頁應用了。
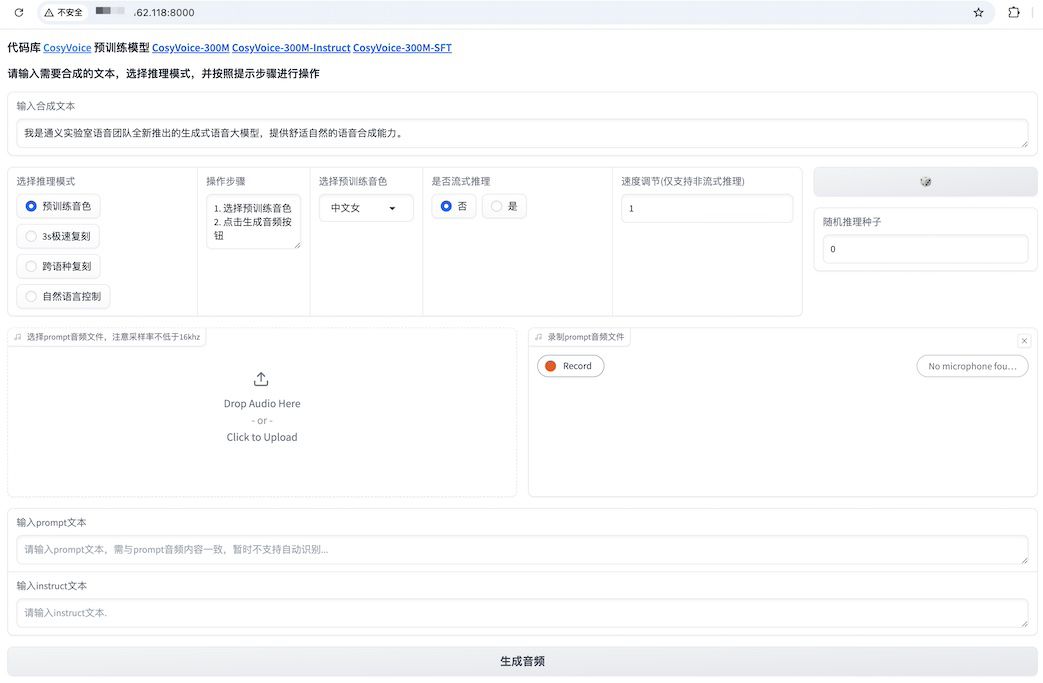
如何使用CosyVoice
方法1. 在Web UI中使用
以語音克隆為例,第一步上傳原素材的音頻文件(可能需要處理以使效果更好),第二步輸入原素材的音頻文件對應的字幕,第三步輸入想要的生成的語音的文案,最后一步點擊生成,耐心等待。
在使用語音克隆功能時,除了提供文本,還需要提供一段示范性的語音樣本,用于大模型模仿音色、語調、朗讀習慣等。語音樣本的質量對最終生成效果影響非常大。對于輸入的樣本語音,同樣可以做一些前置處理。例如長度截取(官方建議語音樣本在3-10s,過長需要耗費更多的推理性能)、降噪處理等。
方法2. Python編程調用
如果需要基于模型做應用開發,或者調整更多細節參數,就需要對模型提供的API進行封裝和二次開發。對于零樣本/跨語言推理,請使用CosyVoice-300M模型。對于 sft 推理,請使用CosyVoice-300M-SFT模型。對于指令推理,請使用CosyVoice-300M-Instruct模型。首先,添加third_party/Matcha-TTS到您的PYTHONPATH。
export PYTHONPATH=third_party/Matcha-TTS
from cosyvoice.cli.cosyvoice import CosyVoice
from cosyvoice.utils.file_utils import load_wav
import torchaudiocosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-SFT')
# sft usage
print(cosyvoice.list_avaliable_spks())
# change stream=True for chunk stream inference
for i, j in enumerate(cosyvoice.inference_sft('你好,我是通義生成式語音大模型,請問有什么可以幫您的嗎?', '中文女', stream=False)):torchaudio.save('sft_{}.wav'.format(i), j['tts_speech'], 22050)cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M')
# zero_shot usage, <|zh|><|en|><|jp|><|yue|><|ko|> for Chinese/English/Japanese/Cantonese/Korean
prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
for i, j in enumerate(cosyvoice.inference_zero_shot('收到好友從遠方寄來的生日禮物,那份意外的驚喜與深深的祝福讓我心中充滿了甜蜜的快樂,笑容如花兒般綻放。', '希望你以后能夠做的比我還好呦。', prompt_speech_16k, stream=False)):torchaudio.save('zero_shot_{}.wav'.format(i), j['tts_speech'], 22050)
# cross_lingual usage
prompt_speech_16k = load_wav('cross_lingual_prompt.wav', 16000)
for i, j in enumerate(cosyvoice.inference_cross_lingual('<|en|>And then later on, fully acquiring that company. So keeping management in line, interest in line with the asset that\'s coming into the family is a reason why sometimes we don\'t buy the whole thing.', prompt_speech_16k, stream=False)):torchaudio.save('cross_lingual_{}.wav'.format(i), j['tts_speech'], 22050)cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-Instruct')
# instruct usage, support [laughter][breath]
for i, j in enumerate(cosyvoice.inference_instruct('在面對挑戰時,他展現了非凡的勇氣與智慧。', '中文男', 'Theo \'Crimson\', is a fiery, passionate rebel leader. Fights with fervor for justice, but struggles with impulsiveness.', stream=False)):torchaudio.save('instruct_{}.wav'.format(i), j['tts_speech'], 22050)















)


