?博主介紹:CSDN畢設輔導第一人、全網粉絲50W+,csdn特邀作者、博客專家、騰訊云社區合作講師、CSDN新星計劃導師、Java領域優質創作者,博客之星、掘金/華為云/阿里云/InfoQ等平臺優質作者、專注于Java技術領域和學生畢業項目實戰,高校老師/講師/同行前輩交流?
技術范圍:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬蟲、數據可視化、小程序、安卓app、大數據、物聯網、機器學習等設計與開發。
主要內容:免費功能設計、開題報告、任務書、中期檢查PPT、系統功能實現、代碼編寫、論文編寫和輔導、論文降重、長期答辯答疑輔導、騰訊會議一對一專業講解輔導答辯、模擬答辯演練、和理解代碼邏輯思路。
🍅文末獲取源碼聯系🍅
👇🏻?精彩專欄推薦訂閱👇🏻?不然下次找不到喲
2022-2024年最全的計算機軟件畢業設計選題大全:1000個熱門選題推薦?
Java項目精品實戰案例《100套》
Java微信小程序項目實戰《100套》
大數據項目實戰《100套》
Python項目實戰《100套》
感興趣的可以先收藏起來,還有大家在畢設選題,項目以及論文編寫等相關問題都可以給我留言咨詢,希望幫助更多的人?


系統介紹:
汽車行業大數據分析系統是一款集成了數據采集、處理、分析和可視化的高級平臺。該系統能夠通過高效的數據倉庫技術進行存儲和管理。利用先進的分析算法,系統可以對車輛性能進行深入分析,該系統還具備強大的可視化功能,通過圖表、報表等形式直觀展示分析結果,使非技術人員也能輕松理解和利用大數據帶來的價值。汽車行業大數據分析系統是推動企業數字化轉型、增強競爭力的關鍵工具。


通過本系統能夠將用戶的信息管理工作規范化、簡單化,從而提高管理工作的效率。本論文主要包括系統首頁、個人中心、用戶、汽車信息、汽車論壇、系統管理等功能;在windows10的系統環境下,采用的編程語言為java和springboot框架,將mysql作為后臺數據庫來實現汽車行業大數據分析管理流程中的各種需求。
? ? 程序上交給用戶進行使用時,需要提供程序的操作流程圖,這樣便于用戶容易理解程序的具體工作步驟,現如今程序的操作流程都有一個大致的標準,即先通過登錄頁面提交登錄數據,通過程序驗證正確之后,用戶才能在程序功能操作區頁面操作對應的功能。
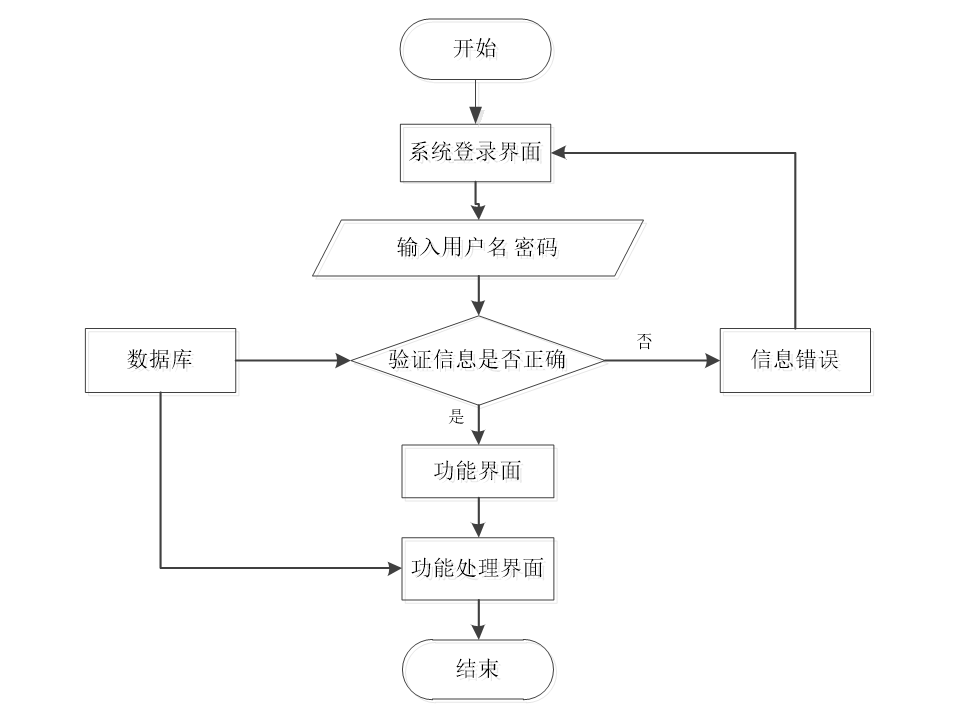 ?
? 程序操作流程圖
? ? ? 首先前端通過Vue和axios發送HTTP請求到后端的登錄接口。在后端接收登錄請求的Controller會使用`@RequestParam Map<String, Object> params`來接收前端傳遞的用戶參數,用戶名和密碼。然后后端根據接收到的參數創建一個查詢條件封裝對象MyBatis的EntityWrapper用于構建查詢條件。接著在業務層,調用相應的service方法來查詢數據庫中是否存在匹配的用戶信息。這個查詢方法Login()會將前端傳遞的對象參數傳遞到后臺的DAO層,進行數據庫的交互操作。如果存在符合條件的用戶,則會返回相關的用戶信息。最后在后端控制器中將查詢結果封裝成響應體,通過`return R.ok().put("data", userService.selecView(ew))`將用戶信息返回給前端。前端收到響應后,可以通過調用Vue、ElementUI等組件來渲染登錄結果,例如顯示用戶信息或者跳轉到相應的頁面。
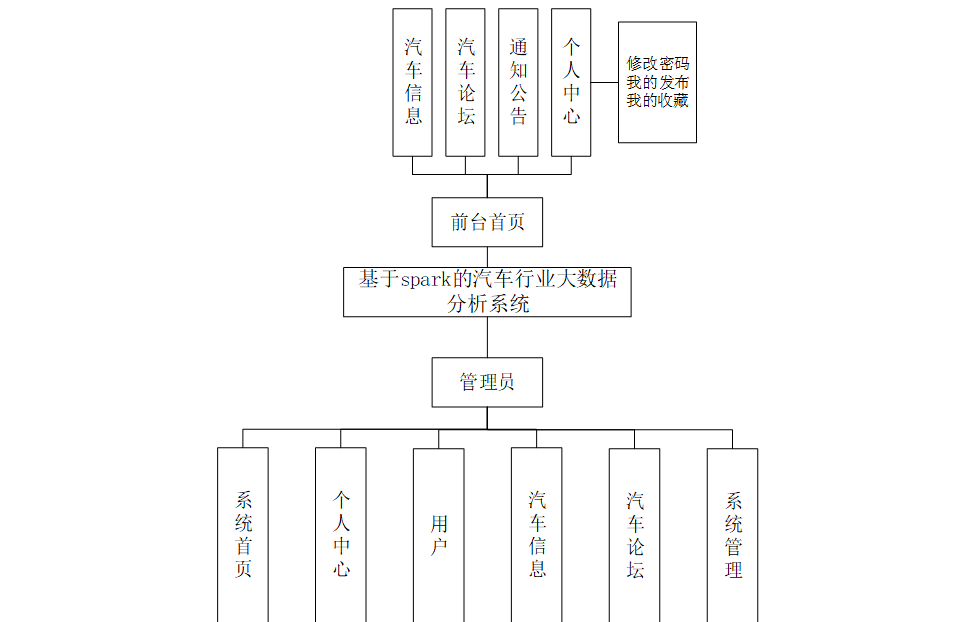
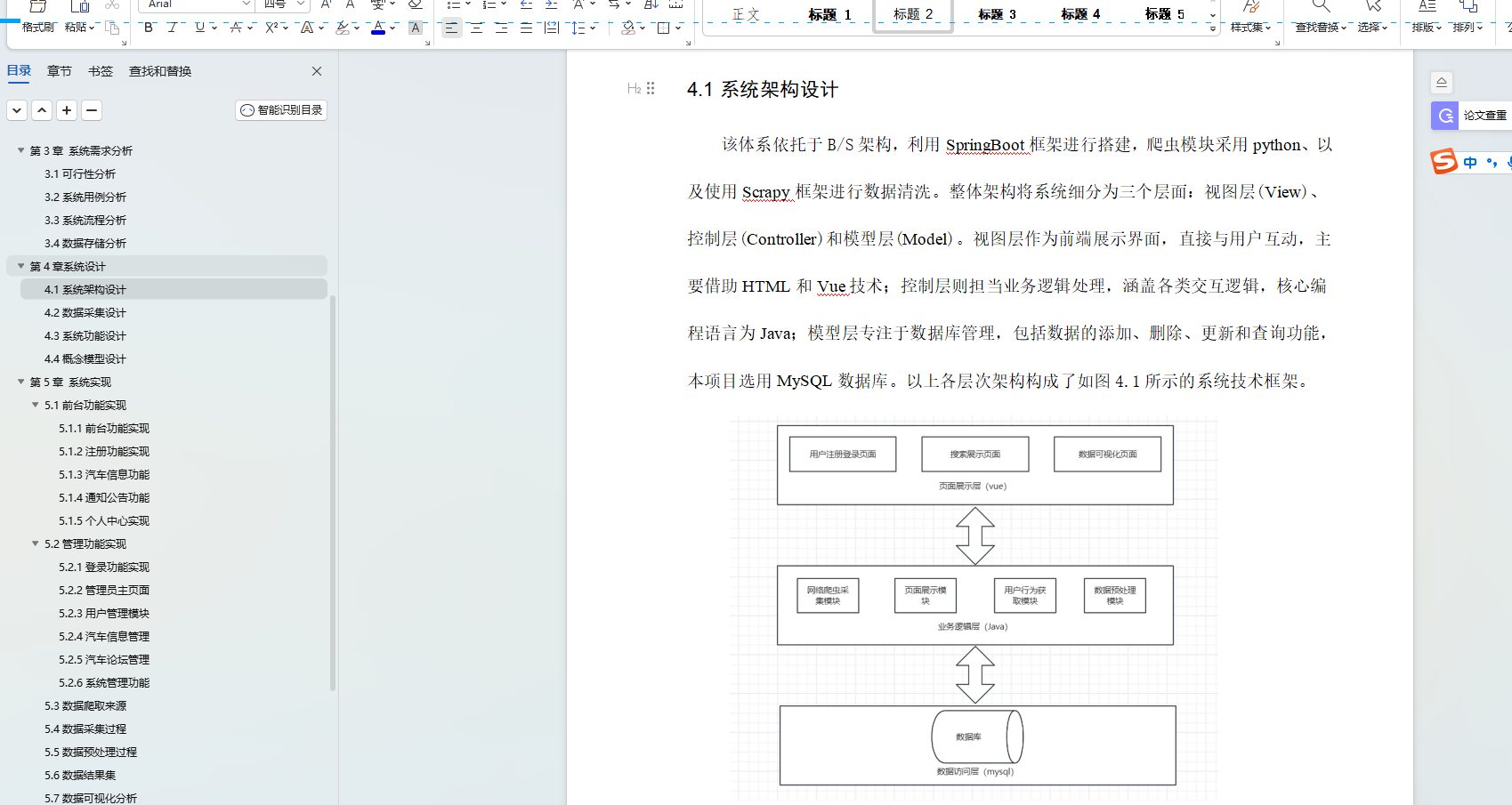
系統架構設計
系統架構設計是軟件開發過程中至關重要的一環。首先是模型層(Model),模型層通常對應著數據庫或者其他數據源,它負責與數據庫進行交互,執行各種數據操作,并將處理后的數據傳遞給控制器層。模型層的設計應該簡潔清晰,盡可能減少與視圖和控制器的耦合,以提高代碼的可維護性和可重用性。
其次是視圖層(View)通常是通過網頁、移動應用界面或者其他用戶界面來展示數據。視圖層與用戶交互,接受用戶的輸入,并將輸入傳遞給控制器層進行處理。在MVC三層架構中,視圖層應該盡量保持簡單,只負責數據的展示和用戶交互,不涉及業務邏輯的處理,以保持視圖層的清晰度和可復用性,最后是控制器層(Controller),每個層都有特定的職責和功能,通過分層架構設計,實現代碼模塊化,為軟件開發提供了一種有效的架構模式。系統架構如圖4-1所示。

詳細視頻演示
請文末卡片dd我獲取更詳細的演示視頻
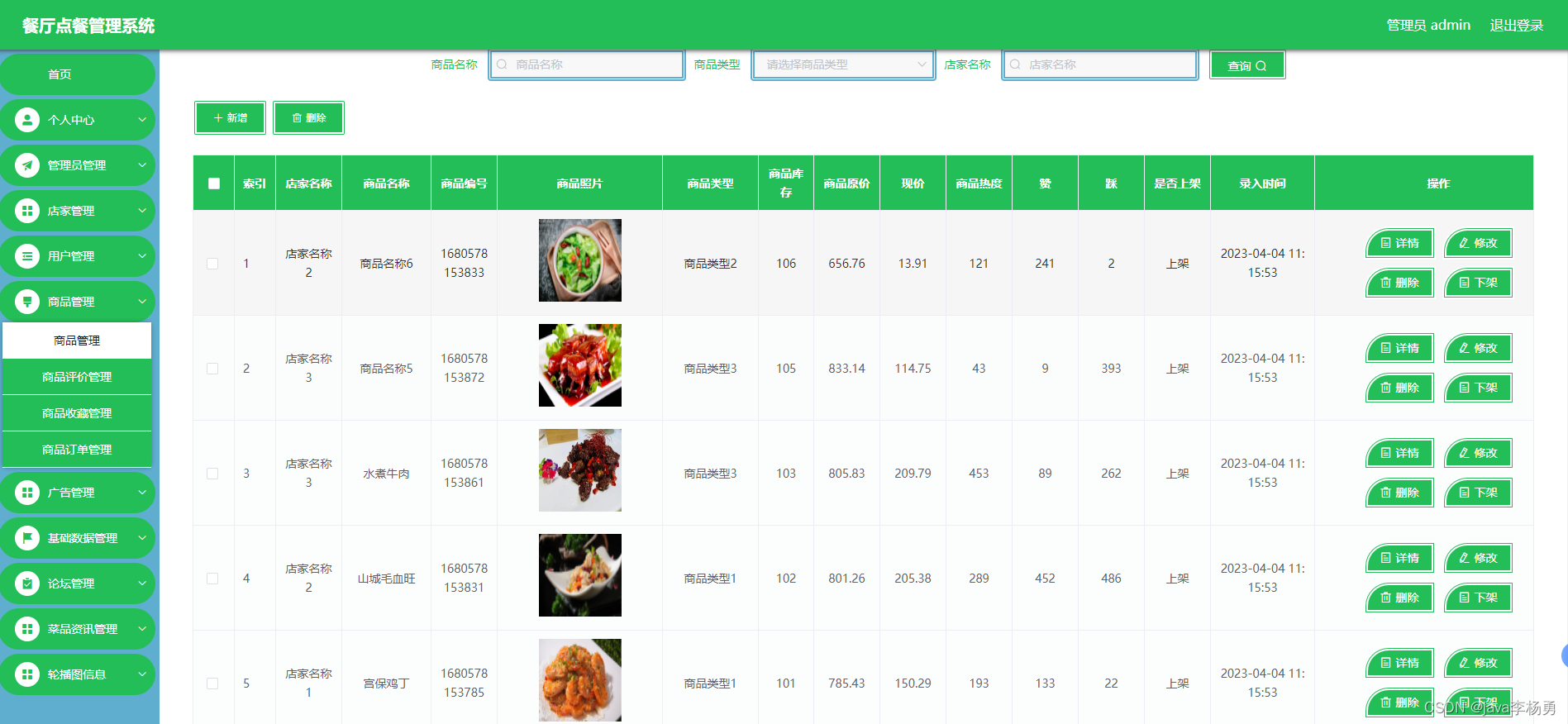
功能截圖:
? ? ? 在系統前臺首頁,調用`$route(newValue)`方法監聽路由變化,根據當前的路由地址來確定活動菜單的索引,并且根據路由的哈希部分(即URL的`#`后面的部分)來判斷是否需要滾動頁面到頂部或者某個特定元素的位置。如果不是首頁,會將頁面滾動到指定元素處,否則滾動到頁面頂部。另外通過`headportrait()`方法用于更新組件渲染點前用戶頭像。在用戶登錄后,后端返回了新的用戶信息,需要及時更新頁面上的用戶頭像信息。
? 在系統前臺首頁,調用`$route(newValue)`方法監聽路由變化,根據當前的路由地址來確定活動菜單的索引,并且根據路由的哈希部分(即URL的`#`后面的部分)來判斷是否需要滾動頁面到頂部或者某個特定元素的位置。如果不是首頁,會將頁面滾動到指定元素處,否則滾動到頁面頂部。另外通過`headportrait()`方法用于更新組件渲染點前用戶頭像。在用戶登錄后,后端返回了新的用戶信息,需要及時更新頁面上的用戶頭像信息。

在上一章中,已經本論文中的汽車行業大數據分析系統進行了全面的設計。接下來第五章對本汽車行業大數據分析系統的實現過程進行說明,包括對該汽車行業大數據分析系統所需的開發環境、運行環境的說明以及對上一章中提到的各種內容的實現。
5.1前臺功能實現
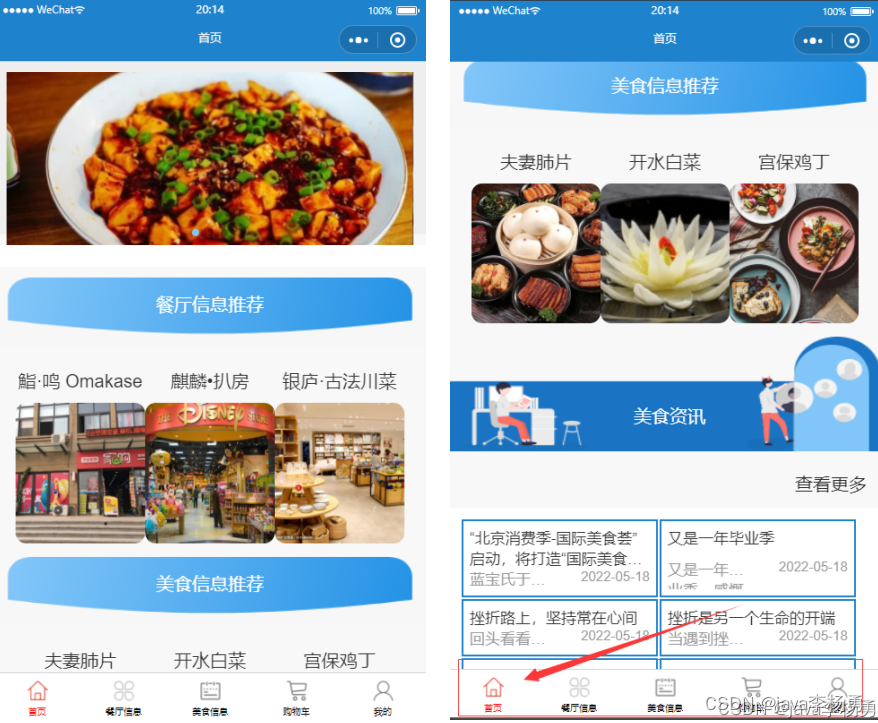
當人們打開系統的網址后,首先看到的就是首頁界面。在這里,人們能夠看到系統的導航條,通過導航條導航進入各功能展示頁面進行操作。系統首頁界面如圖5-1所示:

圖5-1?系統首頁界面
在注冊程中,用戶在Vue前端填寫必要信息(如用戶名、密碼等)并提交。前端將這些信息通過HTTP請求發送到Java后端。后端處理這些信息,檢查用戶名是否唯一,并將新用戶數據存入MySQL數據庫。完成后,后端向前端發送注冊成功的確認,前端隨后通知用戶完成注冊。這個過程實現了新用戶的數據收集、驗證和存儲。系統注冊頁面如圖5-2所示:

圖5-2系統注冊頁面
汽車信息:在汽車信息頁面的輸入欄中輸入車名或評分進行查詢,可以查看到汽車詳細信息;并根據需要進行收藏操作;汽車信息頁面如圖5-3所示:

圖5-3汽車信息詳細頁面
通知公告:在通知公告頁面的輸入欄中輸入標題進行查詢,可以查看到通知公告詳細信息,并根據需要進行點贊或收藏操作;通知公告頁面如圖5-4所示:

圖5-4通知公告詳細頁面
個人中心:在個人中心頁面可以對修改密碼、我的發布、我的收藏進行詳細操作;如圖5-5所示:

圖5-5個人中心界面
5.2管理功能實現
在登錄流程中,用戶首先在Vue前端界面輸入用戶名和密碼。這些信息通過HTTP請求發送到Java后端。后端接收請求,通過與MySQL數據庫交互驗證用戶憑證。如果認證成功,后端會返回給前端,允許用戶訪問系統。這個過程涵蓋了從用戶輸入到系統驗證和響應的全過程。如圖5-6所示。

圖5-6?管理員登錄界面
管理員進入主頁面,主要功能包括對系統首頁、個人中心、用戶、汽車信息、汽車論壇、系統管理等進行操作。管理員主頁面如圖5-7所示:

圖5-7管理員主界面
用戶功能在視圖層(view層)進行交互,比如點擊“查詢、添加或刪除”按鈕或填寫用戶信息表單。這些用戶信息表單動作被視圖層捕獲并作為請求發送給相應的控制器層(controller層)。控制器接收到這些請求后,調用服務層(service層)以執行相關的業務邏輯,例如驗證輸入數據的有效性和與數據庫的交互。服務層處理完這些邏輯后,進一步與數據訪問對象層(DAO層)交互,后者負責具體的數據操作如查看、修改或刪除用戶信息,并將操作結果返回給控制器。最終,控制器根據這些結果更新視圖層,以便用戶功能可以看到最新的信息或相應的操作反饋。如圖5-8所示:

圖5-8用戶界面
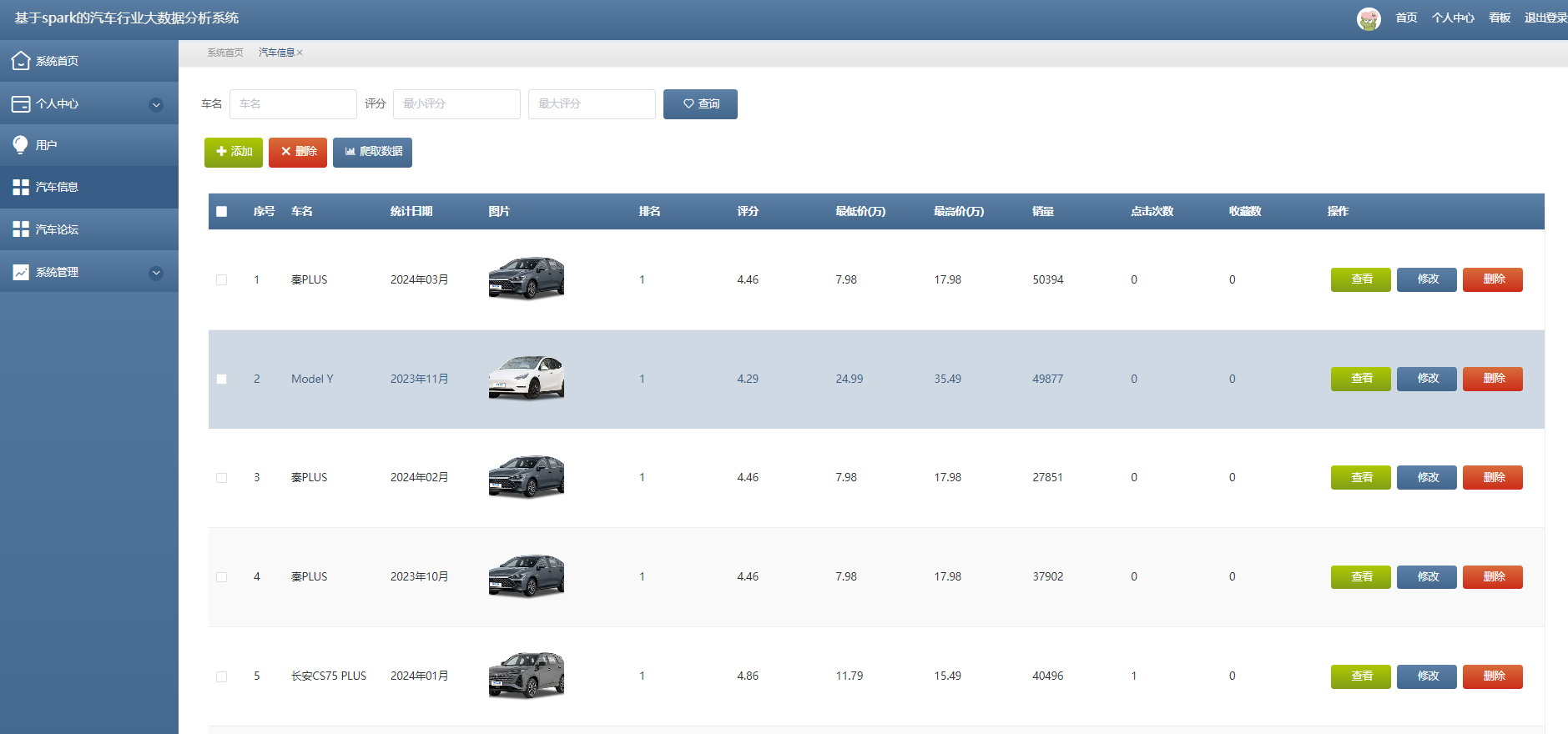
汽車信息功能在視圖層(view層)進行交互,比如點擊“查詢、添加、爬取數據或刪除”按鈕或填寫汽車信息表單。這些汽車信息表單動作被視圖層捕獲并作為請求發送給相應的控制器層(controller層)。控制器接收到這些請求后,調用服務層(service層)以執行相關的業務邏輯,例如驗證輸入數據的有效性和與數據庫的交互。服務層處理完這些邏輯后,進一步與數據訪問對象層(DAO層)交互,后者負責具體的數據操作如查看、修改或刪除汽車信息,并將操作結果返回給控制器。最終,控制器根據這些結果更新視圖層,以便汽車信息功能可以看到最新的信息或相應的操作反饋。如圖5-9所示:

圖5-9汽車信息界面
管理員點擊汽車論壇,在汽車論壇頁面輸入帖子標題進行查詢或刪除汽車論壇信息列表;并對汽車論壇詳細信息進行查看、修改、查看評論或刪除操作;如圖5-10所示:

圖5-10汽車論壇界面
管理員點擊系統管理,在系統簡介頁面輸入標題進行查詢系統簡介信息列表;并對系統簡介詳細信息進行查看、修改操作;如圖5-11所示:

圖5-11系統簡介界面
5.3數據信息采集
定義一個Scrapy爬蟲類`QichexinxiSpider`,用于爬取指定網站的汽車信息。`name`定義了爬蟲的名稱,`spiderUrl`指定了目標網站的URL,`start_urls`將目標網站的URL按分號拆分成一個列表,作為爬取的起始URL。`protocol`和`hostname`用于定義協議和主機名,暫時為空。`realtime`用于指定是否實時獲取數據,初始化為False。代碼如下所示。
class QichexinxiSpider(scrapy.Spider):
????name = 'qichexinxiSpider'
????spiderUrl = 'https://cars.app.autohome.com.cn/carext/recrank/all/getrecranklistpageresult2?from=2&pm=2&pluginversion=11.58.5&model=1&channel=0&pageindex={}&pagesize=20&typeid=1&subranktypeid=1&levelid=0&price=0-9000&date=2024-03'
????start_urls = spiderUrl.split(";")
????protocol = ''
????hostname = ''
????realtime = False
使用parse方法中進行一些初始化操作和判斷條件。首先,通過urlparse函數解析self.spiderUrl得到URL的協議和主機名,并將其分別賦值給self.protocol和self.hostname。 然后,通過platform.system().lower()獲取當前操作系統的名稱,并將其轉換為小寫字母,保存在plat變量中。 接著,判斷條件如果不是實時爬取(self.realtime為False)并且當前操作系統是Linux或Windows,建立數據庫連接,并將連接對象賦值給connect變量。獲取數據庫的游標對象,并將其賦值給cursor變量,調用table_exists函數檢查數據庫中是否存在名為'5nw5u40i_Shangpinxinxi '的表,如果存在就執行關閉游標和連接,調用temp_data函數,最后返回代碼如下所示。
# 列表解析
def parse(self, response):
????_url = urlparse(self.spiderUrl)
????self.protocol = _url.scheme
????self.hostname = _url.netloc
????plat = platform.system().lower()
????if not self.realtime and (plat == 'linux' or plat == 'windows'):
????????connect = self.db_connect()
????????cursor = connect.cursor()
????????if self.table_exists(cursor, '381f1kqr_qichexinxi') == 1:
????????????cursor.close()
????????????connect.close()
????????????self.temp_data()
????????????return
????data = json.loads(response.body)
????try:
????????list = data["result"]["list"]
使用Scrapy爬蟲的回調函數,進行解析詳情頁面,從response的meta中獲取字段對象fileds,最后對其進行賦值和處理。代碼如圖6-16所示。
try:
????fields["tjriqi"] = emoji.demojize(self.remove_html(str( item.get("test", "")+"2024年03月" )))
except:
????pass
try:
????fields["seriesname"] = emoji.demojize(self.remove_html(str( item["seriesname"] )))
except:
????pass
try:
????fields["seriesimage"] = emoji.demojize(self.remove_html(str( item["seriesimage"] )))
except:
????pass
try:
????fields["ranknum"] = int( item["rankNum"])
except:
????pass
try:
????fields["scorevalue"] = float( item["scorevalue"])
except:
????pass
try:
????fields["zdprice"] = float( item["priceinfo"].split('-')[0])
except:
????pass
try:
????fields["zgprice"] = float( item["priceinfo"].split('-')[1].replace('萬',''))
except:
????pass
try:
5.4數據預處理
在基于大數據的商品推薦系統開發中,數據集處理是至關重要的環節。以下是我詳細的數據集處理流程:首先,通過各種渠道搜集寵物商品信息數據集,這可能涉及抓取在線寵物商品信息平臺的數據、接收資料,以及整合寵物商品公告等。這些數據應涵蓋寵物商品的核心詳情,例如價格走勢統計、店鋪商品統計、寵物食品總數、用戶總數、寵物食品、商品品牌統計、適用品種統計等。
接著,獲取到數據集后,重要的一環是執行數據清洗和預處理步驟。數據清洗的目的是保證數據質量和完整性,涉及消除重復記錄、處理未填充的值、修正不準確的信息等。預處理階段則涵蓋數據的格式統一、標準化和轉化操作,以適應后續的分析需求。這一過程中,我利用pandas庫來進行數據洞察,并結合Scrapy架構進行高效的數據采集和清洗,從而保證數據的精確度和實用性。為了數據的可靠存儲和擴展能力,選用MySQL數據庫系統。
為了建立與MySQL數據庫的連接,我將使用root用戶,其密碼設定為123456,目標數據庫名為spider5nw5u40i。采用pandas的read_sql方法,可以從數據庫中提取所需的數據。具體代碼實現代碼如下所示。
def pandas_filter(self):
????engine = create_engine('mysql+pymysql://root:123456@localhost/spider381f1kqr?charset=UTF8MB4')
????df = pd.read_sql('select * from qichexinxi limit 50', con = engine)
首先檢查DataFrame對象df是否存在重復的行,使用'df.drop_duplicates()'函數刪除對象中重復行。調用'df.isnull()'函數檢測對象df'中的缺失值。隨后調用'df.dropna()'函數刪除具有缺失值的行。'df.fillna(value='暫無')'函數將對象df中的缺失值替換為指定的值'暫無'。代碼如下所示。
def pandas_filter(self):
????engine = create_engine('mysql+pymysql://root:123456@localhost/spider381f1kqr?charset=UTF8MB4')
????df = pd.read_sql('select * from qichexinxi limit 50', con = engine)
????# 重復數據過濾
????df.duplicated()
????df.drop_duplicates()
????#空數據過濾
????df.isnull()
????df.dropna()
????# 填充空數據
????df.fillna(value = '暫無')
????# 異常值過濾
????# 濾出 大于800 和 小于 100 的
????a = np.random.randint(0, 1000, size = 200)
????cond = (a<=800) & (a>=100)
????a[cond]
????# 過濾正態分布的異常值
????b = np.random.randn(100000)
????# 3σ過濾異常值,σ即是標準差
????cond = np.abs(b) > 3 * 1
????b[cond]
????# 正態分布數據
????df2 = pd.DataFrame(data = np.random.randn(10000,3))
????# 3σ過濾異常值,σ即是標準差
????cond = (df2 > 3*df2.std()).any(axis = 1)
????# 不滿?條件的?索引
????index = df2[cond].index
????# 根據?索引,進?數據刪除
????df2.drop(labels=index,axis = 0)
生成一個包含80個介于0到1000之間的隨機整數的數組a,然后定義了一個布爾條件cond,用于篩選滿足a在100到800之間的元素。生成一個包含10萬個符合標準正態分布的隨機數的數組b,定義一個布爾條件cond,用于篩選滿足b的絕對值大于3的元素。
創建一個形狀為10000行3列的DataFrame df2,其中的數據是符合標準正態分布的隨機數。定義一個布爾條件cond,用于篩選在df2中任意一列的值大于三倍標準差的行。該行代碼使用索引操作df2[cond].index,獲取滿足條件cond的行的索引。刪除具有指定索引的行,并返回更新后的對象df2。
移除HTML標簽,首先,檢查html參數是否為None,如果是則返回空字符串。然后使用正則表達式模式匹配HTML標簽的正則表達式(<[^>]+>),并通過re.sub函數將匹配到的HTML標簽替換為空字符串。最后使用strip函數去除字符串兩端的空白字符,并返回處理后的結果。代碼如下所示。
# 去除多余html標簽
def remove_html(self, html):
????if html == None:
????????return ''
????pattern = re.compile(r'<[^>]+>', re.S)
????return pattern.sub('', html).strip()
在初始化數據庫鏈接流程時,首要任務是從配置文件中提取必要的連接參數,這些參數涵蓋了數據庫的種類標識、服務器地址、端口、登錄憑證,如用戶名和密碼。如果數據庫名稱未明確指定,系統會嘗試從self.databaseName屬性中尋找。接下來,根據所識別的數據庫類型動態選擇適配的連接技術。例如,如果確認是MySQL,會選擇pyMySQL庫進行無縫對接;反之,如果不是MySQL,程序將同樣采用pyMySQL庫來建立連接。最終,這段代碼將執行并返回一個有效的連接對象,記作connect,整個過程邏輯嚴謹且高效。以下是具體實現的代碼段如下所示:
將處理好的數據進行數據存儲,定義一個包含插入語句的sql字符串,目標數據庫表是Shangpinxinxi,列名包括id、jobname、salary等,從表5nw5u40i_Shangpinxinxi中選擇符合條件的數據,將這些數據插入到目標表中,代碼段如圖6-22所示。
# 數據庫連接函數
def db_connect(self):
????# 從配置文件中獲取數據庫連接信息
????type = self.settings.get('TYPE', 'mysql') ?# 數據庫類型,默認為 MySQL
????host = self.settings.get('HOST', 'localhost') ?# 數據庫主機地址,默認為 localhost
????port = int(self.settings.get('PORT', 3306)) ?# 數據庫連接端口,默認為 3306,需轉換為整數類型
????user = self.settings.get('USER', 'root') ?# 數據庫用戶名,默認為 root
????password = self.settings.get('PASSWORD', '123456') ?# 數據庫密碼,默認為 123456
????try:
????????# 從類屬性中獲取數據庫名
????????database = self.databaseName
????except:
????????database = self.settings.get('DATABASE', '') ?# 從配置文件中獲取數據庫名,默認為空字符串
????# 根據數據庫類型選擇不同的數據庫連接方式
????if type == 'mysql':
????????# MySQL 數據庫連接方式
????????connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
????else:
????????# MSSQL 數據庫連接方式
????????connect = pymssql.connect(host=host, user=user, password=password, database=database)
????
????# 返回數據庫連接對象
????return connect ?
5.5數據結果集
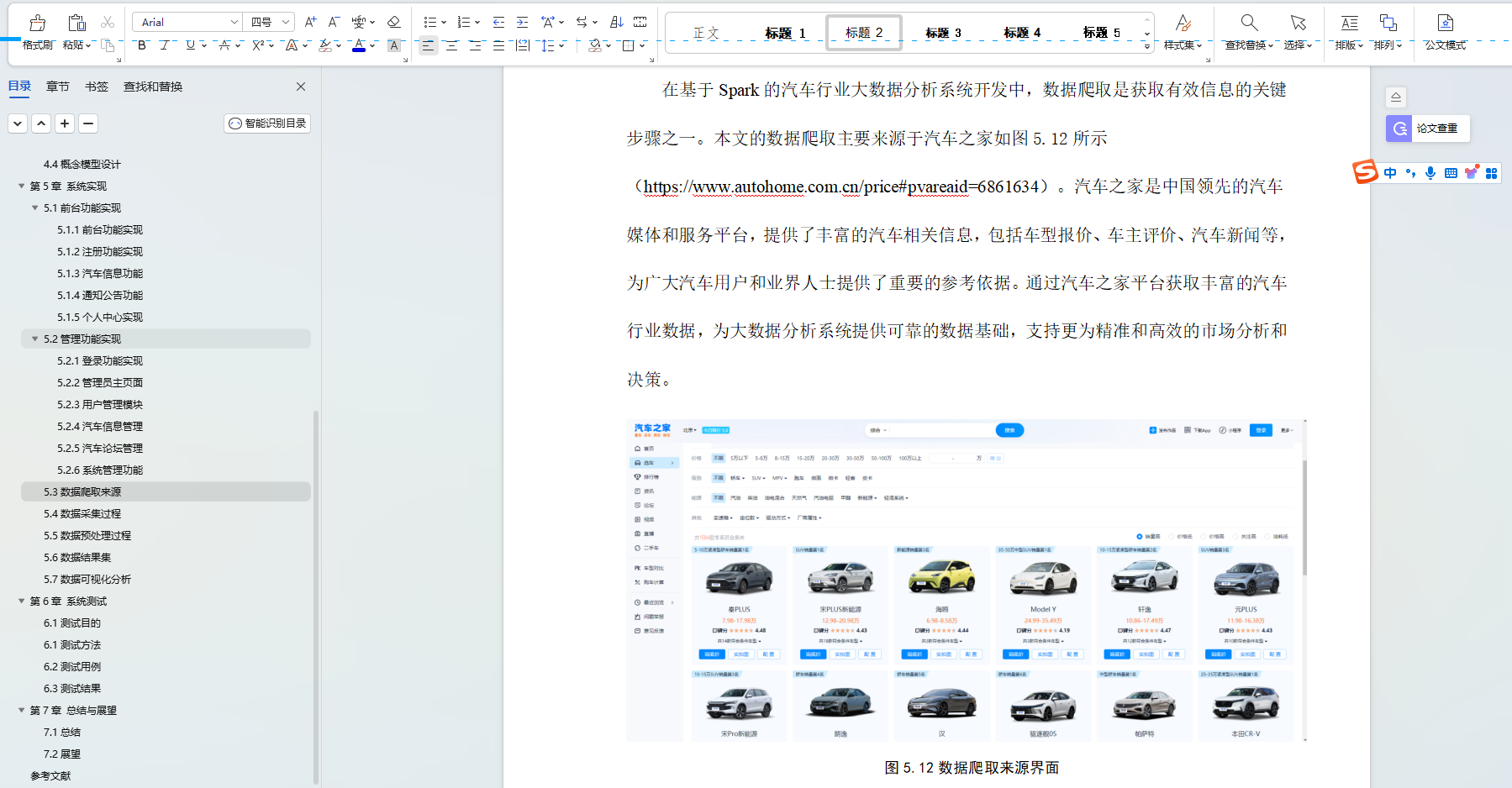
通過爬取https://cars.app.autohome.com.cn網站數據集。數據如圖5-12,5-13所示

圖5-12?數據集

圖5-13?數據集
經過數據預處理,將爬取數據存儲到數據庫中如圖5-14所示。

圖5-14?數據庫存儲汽車信息數據
5.6數據可視化分析?
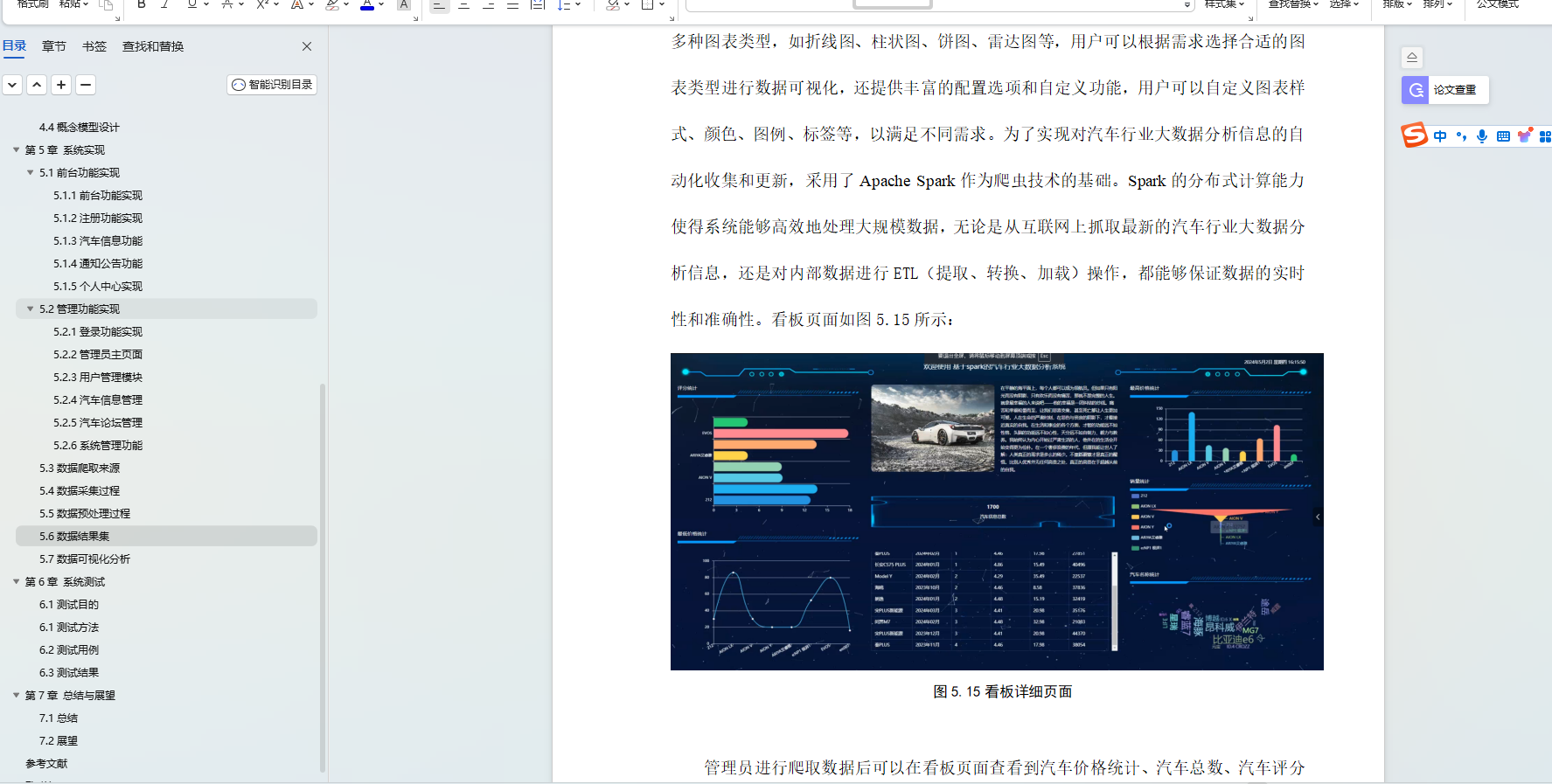
管理員進行爬取數據后可以在看板頁面查看到評分統計、最低價格統計、汽車信息、最高價格統計、銷量統計、汽車信息統計等實時的分析圖進行可視化管理;看板大屏選擇了Echart作為數據可視化工具,它是一個使用JavaScript實現的開源可視化庫,能夠無縫集成到Web應用中。Echart的強大之處在于其豐富的圖表類型和高度的定制化能力,使得管理人員可以通過直觀的圖表清晰地把握汽車行業大數據分析的各項運營數據。為了實現對汽車行業大數據分析信息的自動化收集和更新,采用了Apache Spark作為爬蟲技術的基礎。Spark的分布式計算能力使得系統能夠高效地處理大規模數據,無論是從互聯網上抓取最新的汽車行業大數據分析信息,還是對內部數據進行ETL(提取、轉換、加載)操作,都能夠保證數據的實時性和準確性。在大數據分析方面,系統采用了Hadoop框架。Hadoop是一個能夠處理大數據集的分布式存儲和計算平臺,它的核心是HDFS(Hadoop Distributed File System)和MapReduce計算模型。通過Hadoop,我們可以對收集到的大量數據進行存儲和分析。看板頁面如圖5-14所示:

圖5-14看板詳細頁面
管理員進行爬取數據后可以在看板頁面查看到汽車價格走勢統計、汽車總數、用戶總數、汽車品牌統計、適用車型統計等實時的分析圖進行可視化管理;看板大屏選擇了Echart作為數據可視化工具,它是一個使用JavaScript實現的開源可視化庫,能夠無縫集成到Java Web應用中。Echart的強大之處在于其豐富的圖表類型和高度的定制化能力,使得管理人員可以通過直觀的圖表清晰地把汽車價格走勢統計的各項運營數據展現出來。
如圖所示,展示了汽車價格走勢,包括了汽車的價格、品牌、車型等信息,幫助管理人員直觀地了解汽車市場的價格趨勢和銷售情況。

圖5-15看板詳細頁面
如圖所示,展示了當前系統的汽車信息總數。

圖5-16看板詳細頁面
如圖所示,展示了汽車信息的最高價格統計排名。

圖5-17看板詳細頁面
如圖所示,展示了汽車品類適用品種統計,統計出各個汽車品類用品的數詞云圖。

圖5-18看板詳細頁面
可以看出,對于大部分用戶在選購汽車時都會選擇常見的車型,而對于特定品牌或型號的汽車需求相對均衡。為了實現對汽車價格走勢統計的自動化收集和更新,我采用了Apache Spark作為爬蟲技術的基礎。Spark的分布式計算能力使得系統能夠高效地處理大規模數據,無論是從互聯網上抓取最新的價格,還是對內部數據進行ETL(提取、轉換、加載)操作,都能夠保證數據的實時性和準確性。在大數據分析方面,系統采用了Hadoop框架。Hadoop是一個能夠處理大數據集的分布式存儲和計算平臺,它的核心是HDFS(Hadoop Distributed File System)和MapReduce計算模型。通過Hadoop,可以對收集到的大量汽車數據進行存儲和分析,包括價格走勢、銷量統計等,為企業提供數據支持和決策參考。。
論文參考:
1 緒 ?論
1.1研究背景與意義
1.2系統研究現狀
1.3 論文主要工作內容
2 系統關鍵技術
2.1 java簡介
2.2 MySQL數據庫
2.3 B/S結構
2.4 SpringBoot框架
2.5 VUE框架
3 系統分析
3.1 系統可行性分析
3.1.1 技術可行性
3.1.2 操作可行性
3.1.3 經濟可行性
3.1.4 法律可行性
3.2 系統性能分析
3.3 系統功能分析
3.4 系統流程分析
3.4.1 數據開發流程
3.4.2 用戶登錄流程
3.4.3 系統操作流程
3.4.4 添加信息流程
3.4.5 修改信息流程
3.4.6 刪除信息流程
4 系統設計
4.1 系統概要
4.2 系統結構設計
4.3數據庫設計
4.3.1 數據庫設計原則
4.3.3 數據庫表設計
4.4 系統時序圖
4.4.1 注冊時序圖
4.4.2 登錄時序圖
4.4.3 管理員修改用戶信息時序圖
4.4.4 管理員管理系統信息時序圖
5 系統的實現
5.1前臺功能實現
5.1.1系統首頁頁面
5.1.2個人中心
5.2后臺管理員功能實現
6 系統測試
6.1 測試環境
6.2 測試目的
6.3 測試概述
6.4 單元測試
6.4.1 注冊測試
6.4.2 登錄測試
6.5 集成測試
結 ?論
參考文獻
致 ?謝
代碼實現:
/*** 登錄相關*/
@RequestMapping("users")
@RestController
public class UserController{@Autowiredprivate UserService userService;@Autowiredprivate TokenService tokenService;/*** 登錄*/@IgnoreAuth@PostMapping(value = "/login")public R login(String username, String password, String role, HttpServletRequest request) {UserEntity user = userService.selectOne(new EntityWrapper<UserEntity>().eq("username", username));if(user != null){if(!user.getRole().equals(role)){return R.error("權限不正常");}if(user==null || !user.getPassword().equals(password)) {return R.error("賬號或密碼不正確");}String token = tokenService.generateToken(user.getId(),username, "users", user.getRole());return R.ok().put("token", token);}else{return R.error("賬號或密碼或權限不對");}}/*** 注冊*/@IgnoreAuth@PostMapping(value = "/register")public R register(@RequestBody UserEntity user){
// ValidatorUtils.validateEntity(user);if(userService.selectOne(new EntityWrapper<UserEntity>().eq("username", user.getUsername())) !=null) {return R.error("用戶已存在");}userService.insert(user);return R.ok();}/*** 退出*/@GetMapping(value = "logout")public R logout(HttpServletRequest request) {request.getSession().invalidate();return R.ok("退出成功");}/*** 密碼重置*/@IgnoreAuth@RequestMapping(value = "/resetPass")public R resetPass(String username, HttpServletRequest request){UserEntity user = userService.selectOne(new EntityWrapper<UserEntity>().eq("username", username));if(user==null) {return R.error("賬號不存在");}user.setPassword("123456");userService.update(user,null);return R.ok("密碼已重置為:123456");}/*** 列表*/@RequestMapping("/page")public R page(@RequestParam Map<String, Object> params,UserEntity user){EntityWrapper<UserEntity> ew = new EntityWrapper<UserEntity>();PageUtils page = userService.queryPage(params, MPUtil.sort(MPUtil.between(MPUtil.allLike(ew, user), params), params));return R.ok().put("data", page);}/*** 信息*/@RequestMapping("/info/{id}")public R info(@PathVariable("id") String id){UserEntity user = userService.selectById(id);return R.ok().put("data", user);}/*** 獲取用戶的session用戶信息*/@RequestMapping("/session")public R getCurrUser(HttpServletRequest request){Integer id = (Integer)request.getSession().getAttribute("userId");UserEntity user = userService.selectById(id);return R.ok().put("data", user);}/*** 保存*/@PostMapping("/save")public R save(@RequestBody UserEntity user){
// ValidatorUtils.validateEntity(user);if(userService.selectOne(new EntityWrapper<UserEntity>().eq("username", user.getUsername())) !=null) {return R.error("用戶已存在");}userService.insert(user);return R.ok();}/*** 修改*/@RequestMapping("/update")public R update(@RequestBody UserEntity user){
// ValidatorUtils.validateEntity(user);userService.updateById(user);//全部更新return R.ok();}/*** 刪除*/@RequestMapping("/delete")public R delete(@RequestBody Integer[] ids){userService.deleteBatchIds(Arrays.asList(ids));return R.ok();}
}推薦項目:
基于大數據爬蟲+數據可視化的農村產權交易與數據可視化平臺
基于SpringBoot+數據可視化+大數據二手電子產品需求分析系統
基于SpringBoot+數據可視化+協同過濾算法的個性化視頻推薦系統
基于大數據+爬蟲+數據可視化的的亞健康人群數據可視化平臺
基于SpringBoot+大數據+爬蟲+數據可視化的的媒體社交與可視化平臺
基于大數據+爬蟲+數據可視化+SpringBoot+Vue的智能孕嬰護理管理與可視化平臺系統
基于大數據+爬蟲+數據可視化+SpringBoot+Vue的虛擬證券交易平臺
基于大數據+爬蟲技術+數據可視化的國漫推薦系統
基于大數據爬蟲+Hadoop+數據可視化+SpringBoo的電影數據分析與可視化平臺
基于python+大數據爬蟲技術+數據可視化+Spark的電力能耗數據分析與可視化平臺
基于SpringBoot+Vue四川自駕游攻略管理系統設計和實現
基于SpringBoot+Vue+安卓APP計算機精品課程學習系統設計和實現
基于Python+大數據城市景觀畫像可視化系統設計和實現
基于大數據+Hadoop的豆瓣電子圖書推薦系統設計和實現
基于微信小程序+Springboot線上租房平臺設計和實現-三端
2022-2024年最全的計算機軟件畢業設計選題大全
基于Java+SpringBoot+Vue前后端分離手機銷售商城系統設計和實現
基于Java+SpringBoot+Vue前后端分離倉庫管理系統設計實現
基于SpringBoot+uniapp微信小程序校園點餐平臺詳細設計和實現
基于Java+SpringBoot+Vue+echarts健身房管理系統設計和實現
基于JavaSpringBoot+Vue+uniapp微信小程序實現鮮花商城購物系統
基于Java+SpringBoot+Vue前后端分離攝影分享網站平臺系統?
基于Java+SpringBoot+Vue前后端分離餐廳點餐管理系統設計和實現
基于Python熱門旅游景點數據分析系統設計與實現
項目案例:?




 ?
?

為什么選擇我
?博主是CSDN畢設輔導博客第一人兼開派祖師爺、博主本身從事開發軟件開發、有豐富的編程能力和水平、累積給上千名同學進行輔導、全網累積粉絲超過50W。是CSDN特邀作者、博客專家、新星計劃導師、Java領域優質創作者,博客之星、掘金/華為云/阿里云/InfoQ等平臺優質作者、專注于Java技術領域和學生畢業項目實戰,高校老師/講師/同行前輩交流和合作。?
源碼獲取:
大家點贊、收藏、關注、評論啦 、查看👇🏻獲取聯系方式👇🏻
?精彩專欄推薦訂閱:在下方專欄👇🏻
2022-2024年最全的計算機軟件畢業設計選題大全:1000個熱門選題推薦?
Java項目精品實戰案例《100套》
Java微信小程序項目實戰《100套》
Python項目實戰《100套》




![[git]如何關聯本地分支和遠程分支](http://pic.xiahunao.cn/[git]如何關聯本地分支和遠程分支)


:實際案例)




:AI如何重塑開發者協作)

)




】Spring接入Web環境!本篇開始研究SpringMVC的使用!SpringMVC數據響應和獲取請求數據)