前言
? ? ? ?LLaMA-factory是一個非常有用的開源框架。關于利用llama-factory實現大模型的微調,研究了有一個多月了,終于相對成功的微調了一個QWen的大模型。其中的曲折愿和大家分享!
一、源碼的下載
在github上的網址:
GitHub - hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs & VLMs (ACL 2024)
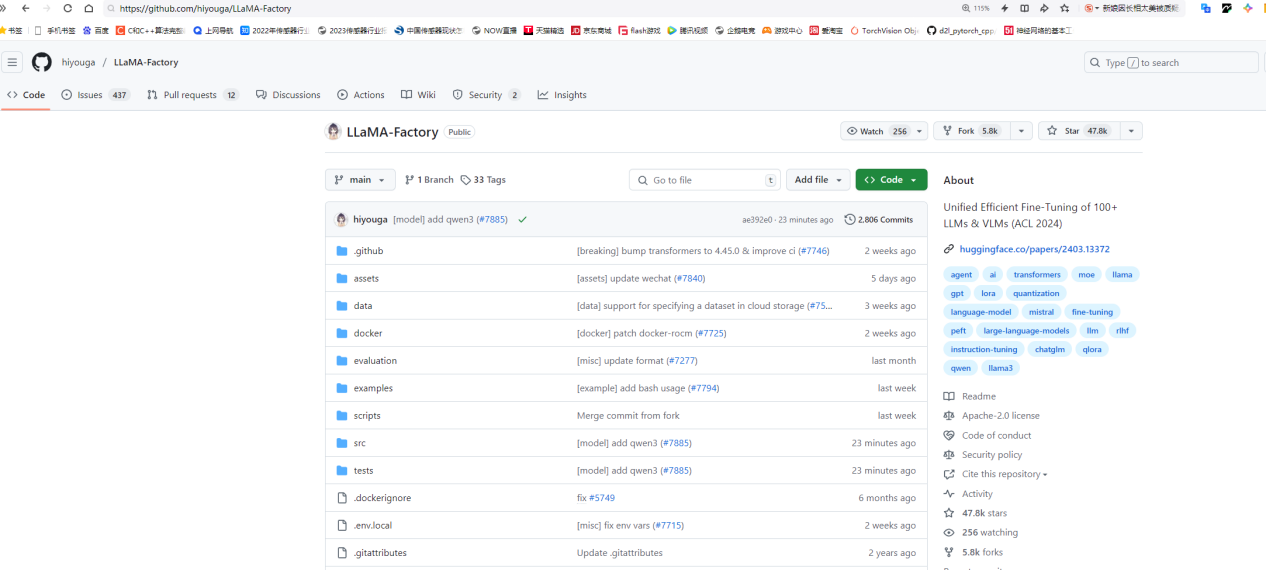
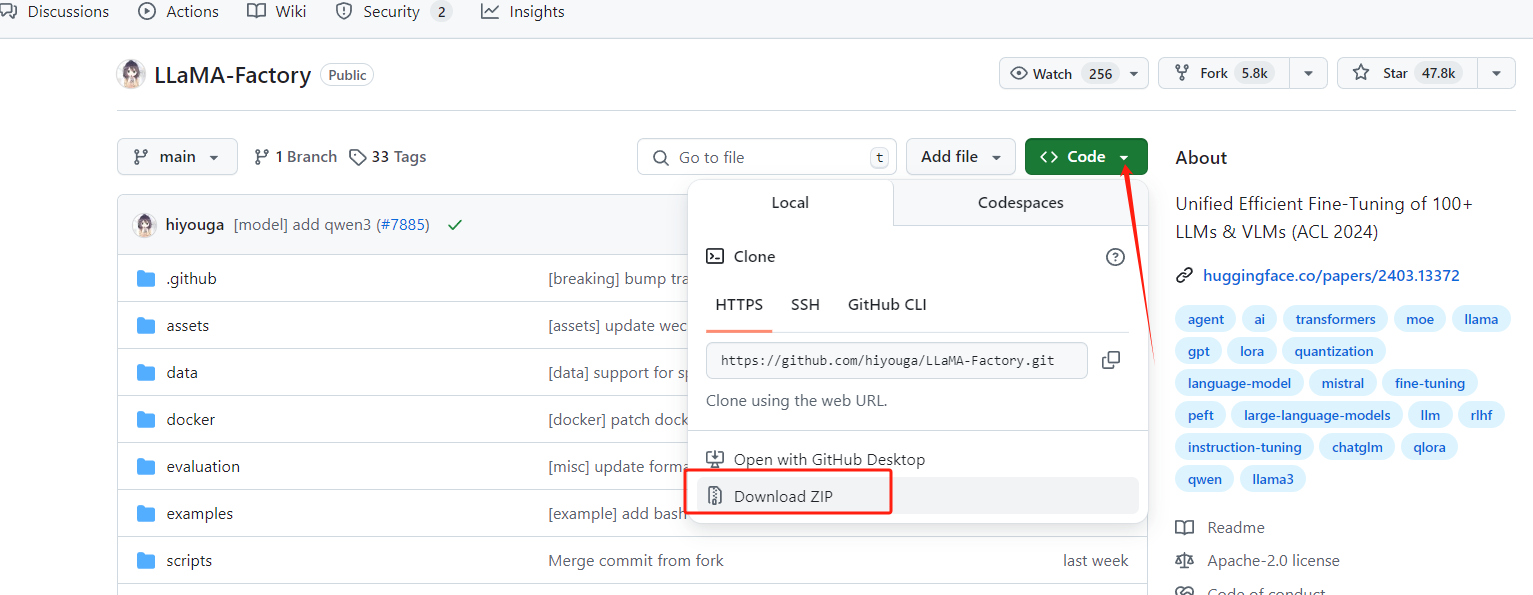
不采用git,直接download,如圖:
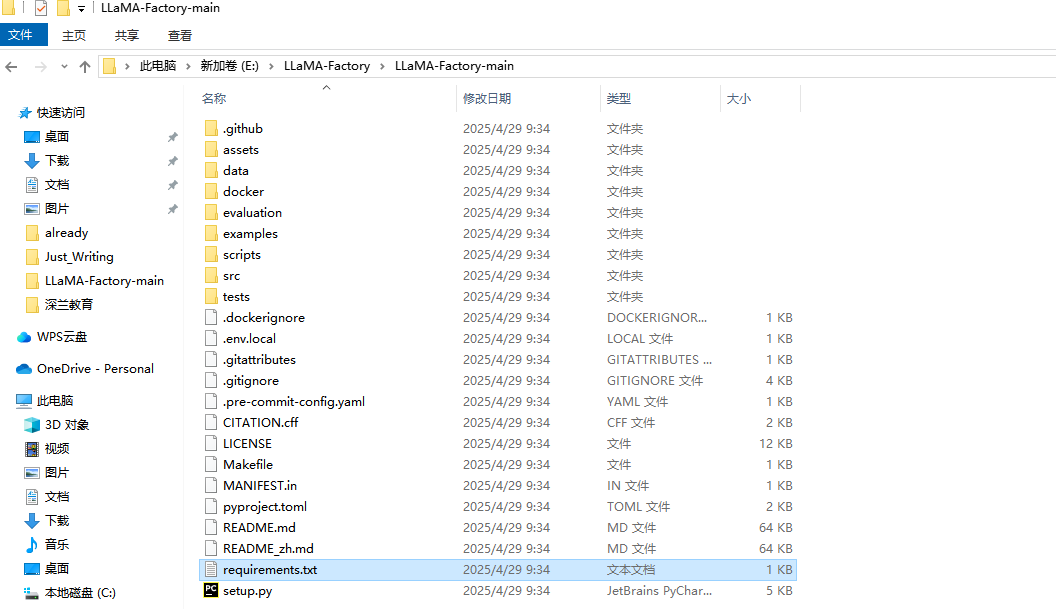
下載完畢后,解壓后的效果如下:
二、在AnaConda配置完成安裝
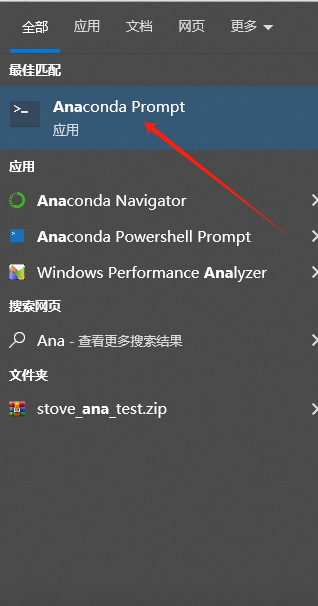
啟動AnaConda的命令行:
查看現有的虛擬環境,如下圖:
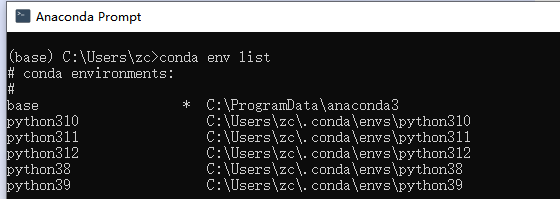
(可見我當前的系統安裝了多個Python版本的環境,這個可以參考我的另外一篇博客:
https://quickrubber.blog.csdn.net/article/details/140995598)
激活Python311
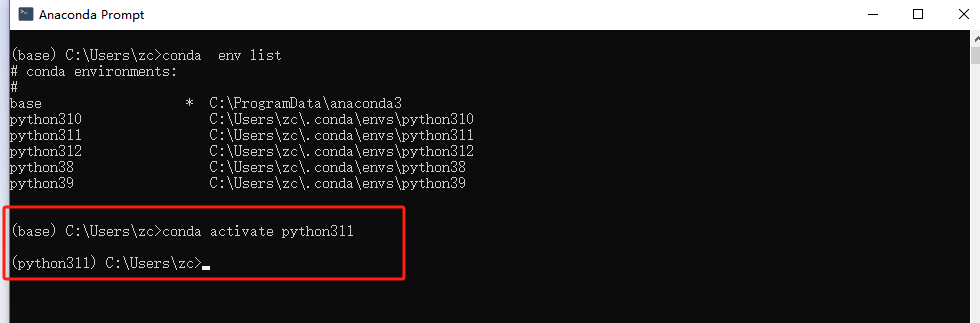
進入LLaMa-Factory的下載目錄,如下圖:
安裝依賴:

下載得速度還是比較快的,然后如下:
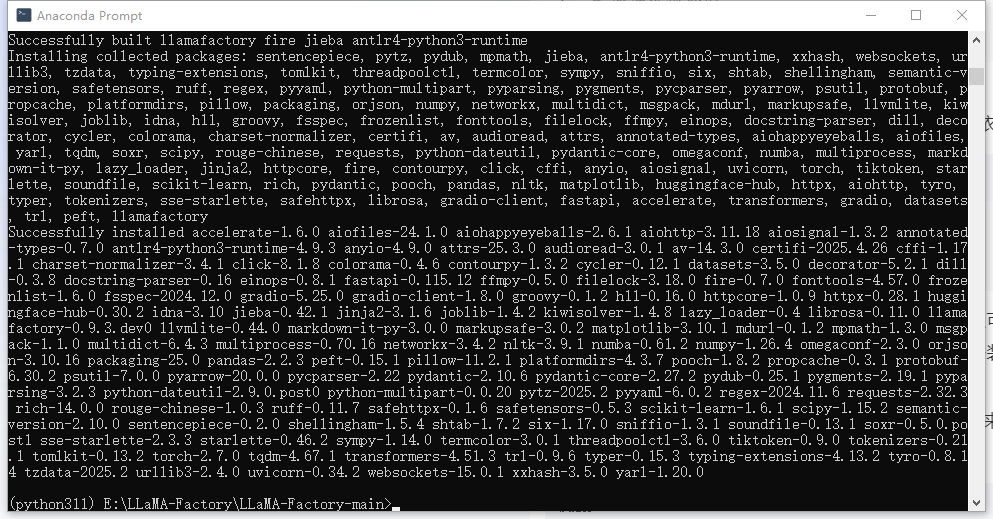
三、啟動LLaMa-factory
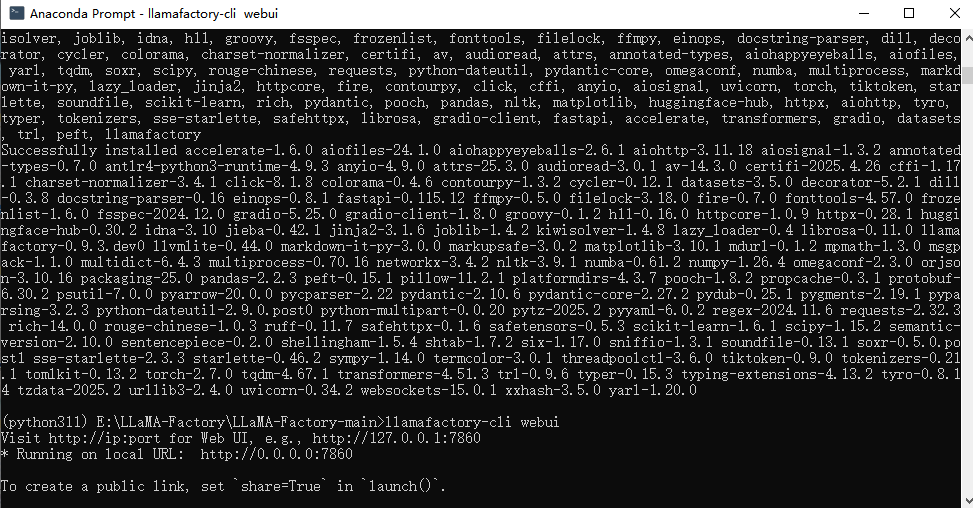
自動打開了瀏覽器(這個啟動過程大約需要十多秒),如下圖:
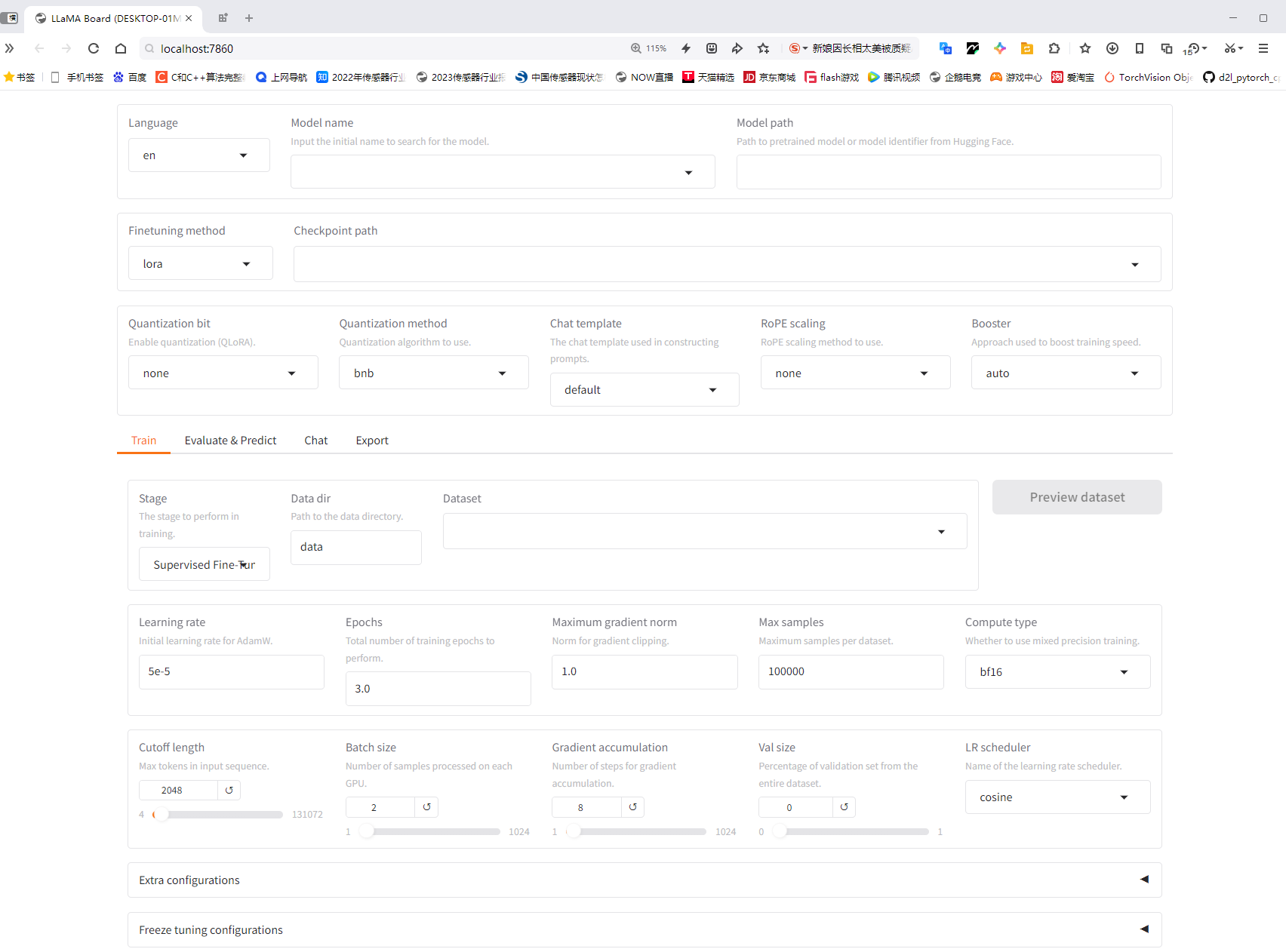
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
嘗試直接掛接Ollama的本地大模型,發現無法成功,具體可以參看我的另一篇博客:
llama-Factory不宜直接掛接Ollama的大模型-CSDN博客
所以,考慮直接采用魔搭社區下載的大模型。
四、訪問本地的千問(QWen)大模型對比微調結果
4.1、從魔搭社區下載大模型文件
采用的還是比較輕量級的QWen2.5:0.5B。
鏈接:魔搭社區
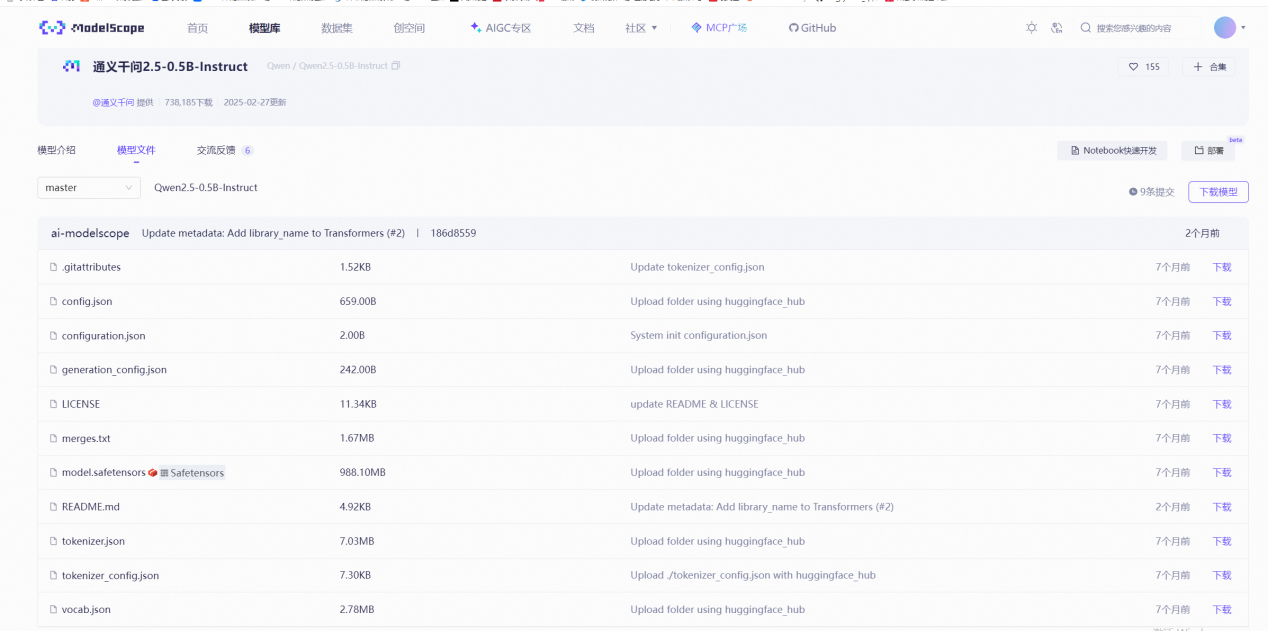
直接逐個下載即可(當然也可用命令行下載,在此不贅述)
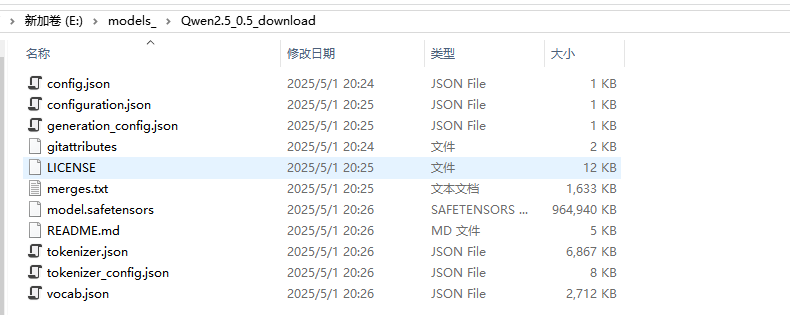
下載完畢后,文件夾中的文件如下:
4.2、PyCharm工程訪問大模型文件實現測試1
代碼如下:
from transformers import AutoModelForCausalLM, AutoTokenizer
#模型文件采用在線的方式進行
#model_name = "Qwen/Qwen2.5-0.5B-Instruct"
model_name=r"E:\models_\Qwen2.5_0.5_before_fine_tuning"model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)instruction = "Produce a list of the top 5 NHL players in 2021."
input_text = ""messages = [{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},{"role": "user", "content": f"Instruction: {instruction}\nInput: {input_text}"}
]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs,max_new_tokens=512
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print("Model output:", response)運行結果如下:
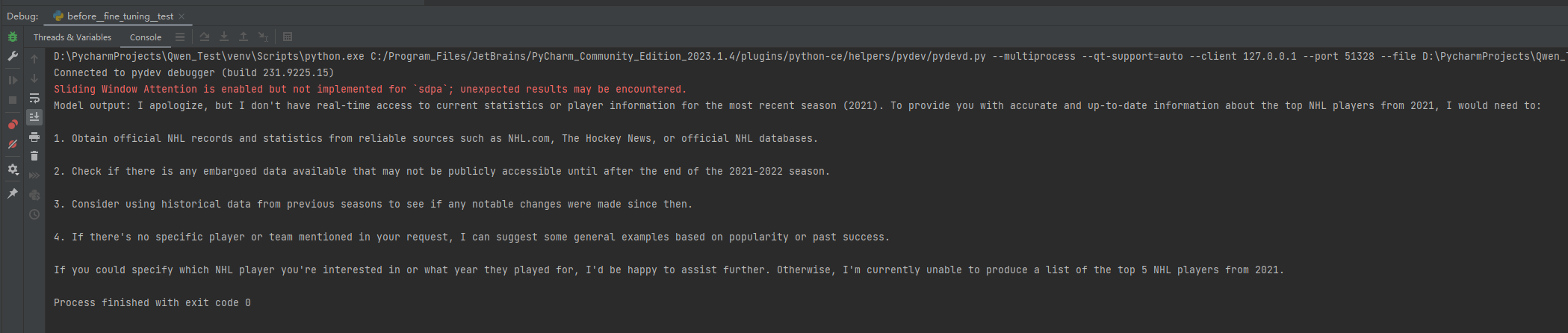
??????????????????????????????????(結果圖1)
4.3、采用LLaMa-factory實現模型的微調
選定模型位置:
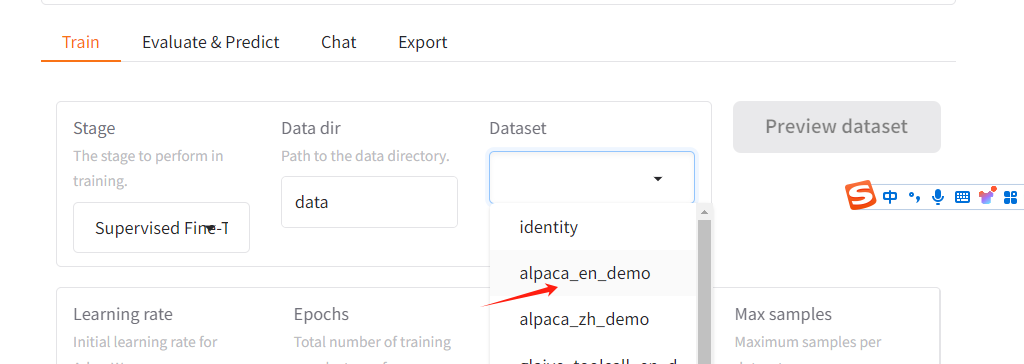
選擇一個llama-factory自帶的一個數據集:
開始訓練:
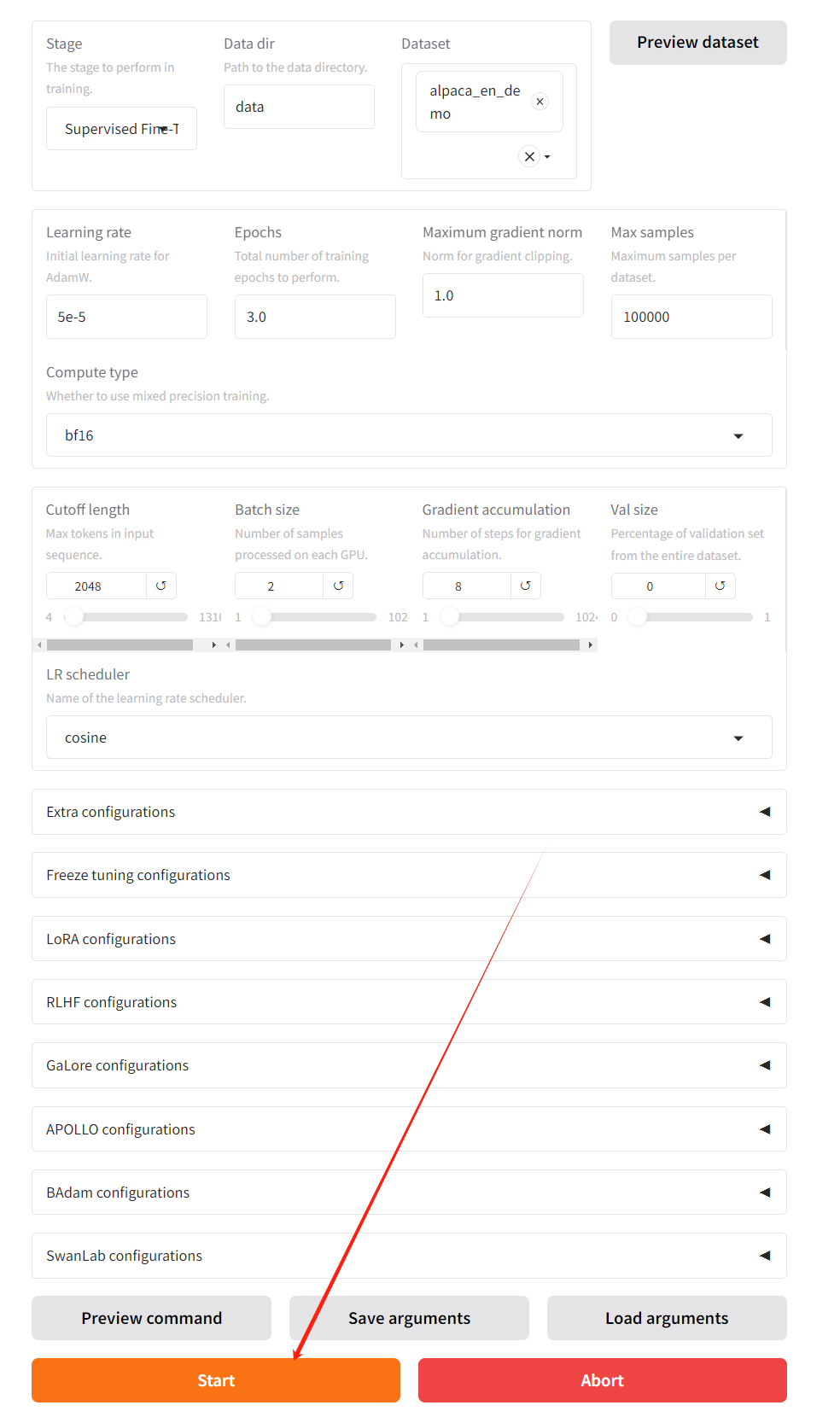
控制臺的訓練顯示1:
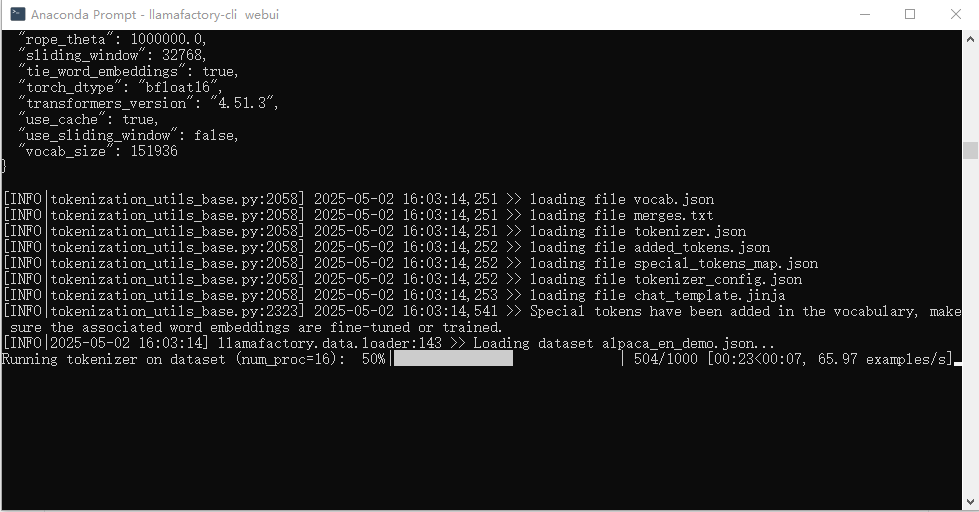
查看資源管理器,發現GPU已100%被占用:
訓練完畢(2080顯卡用時1小時):
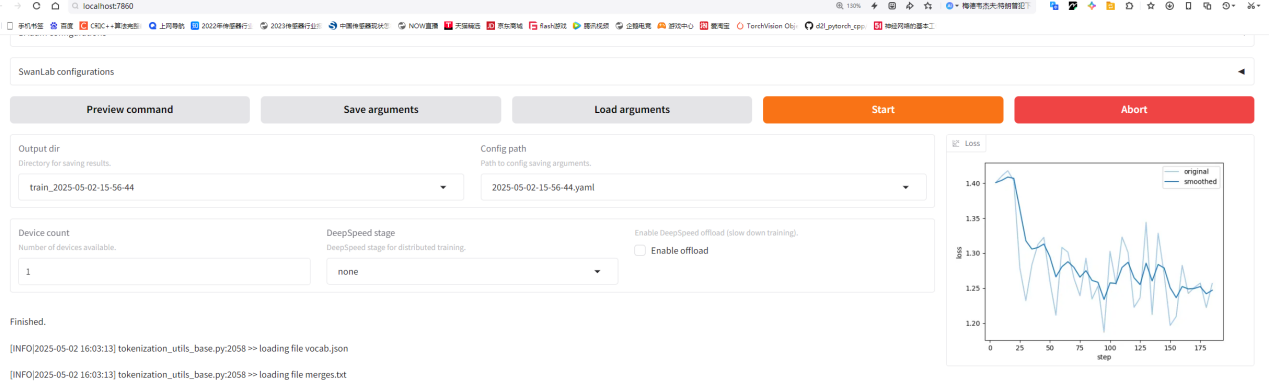
完畢后可以得到一個訓練記錄:
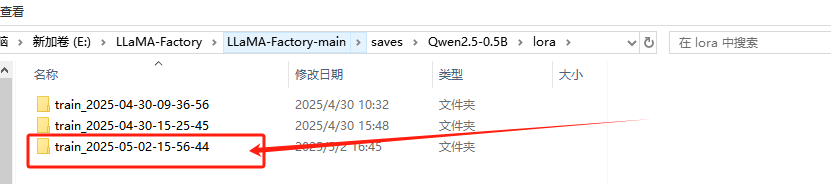
點開文件夾:
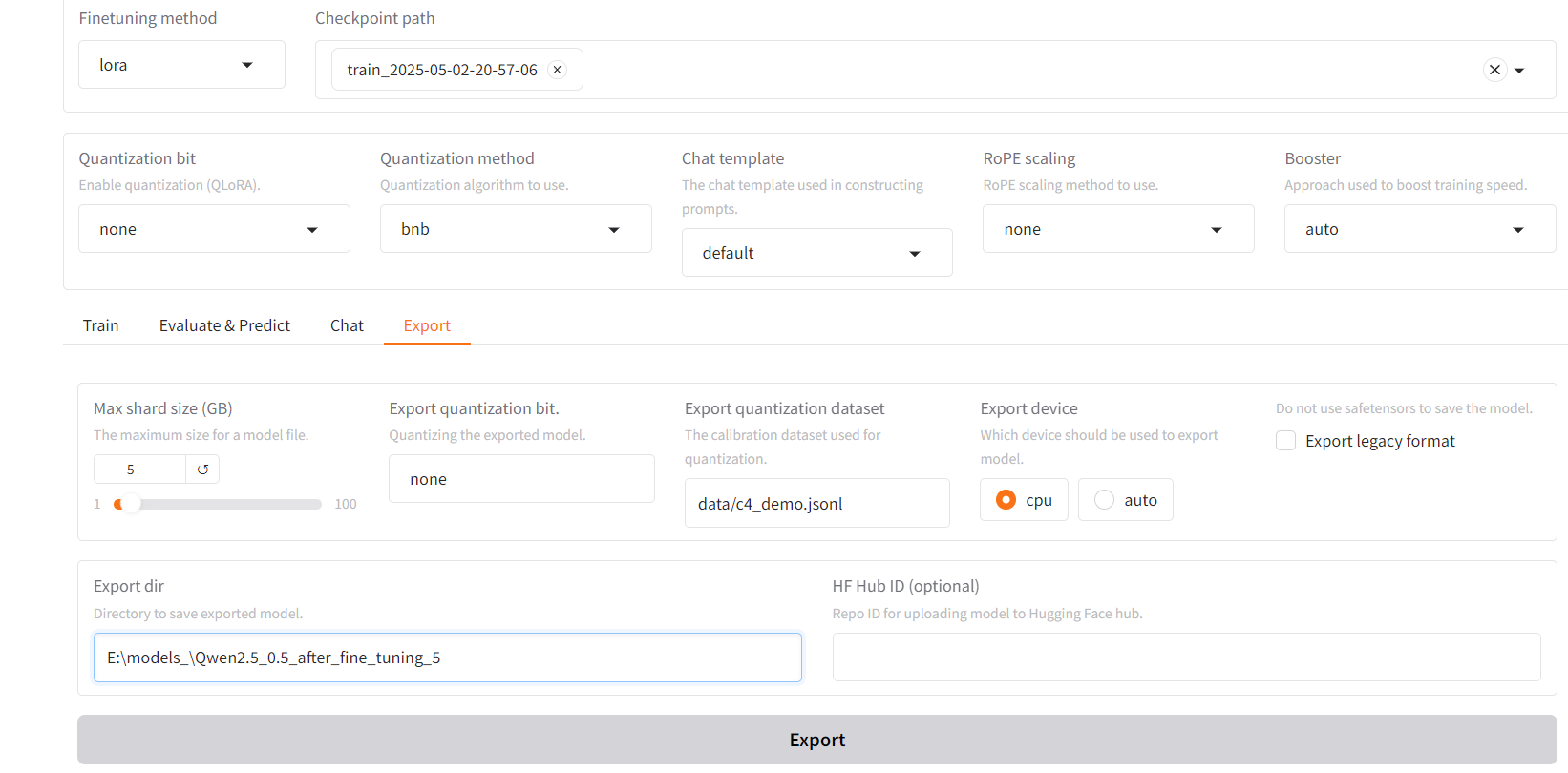
4.4、采用llama-factory將微調后的模型導出
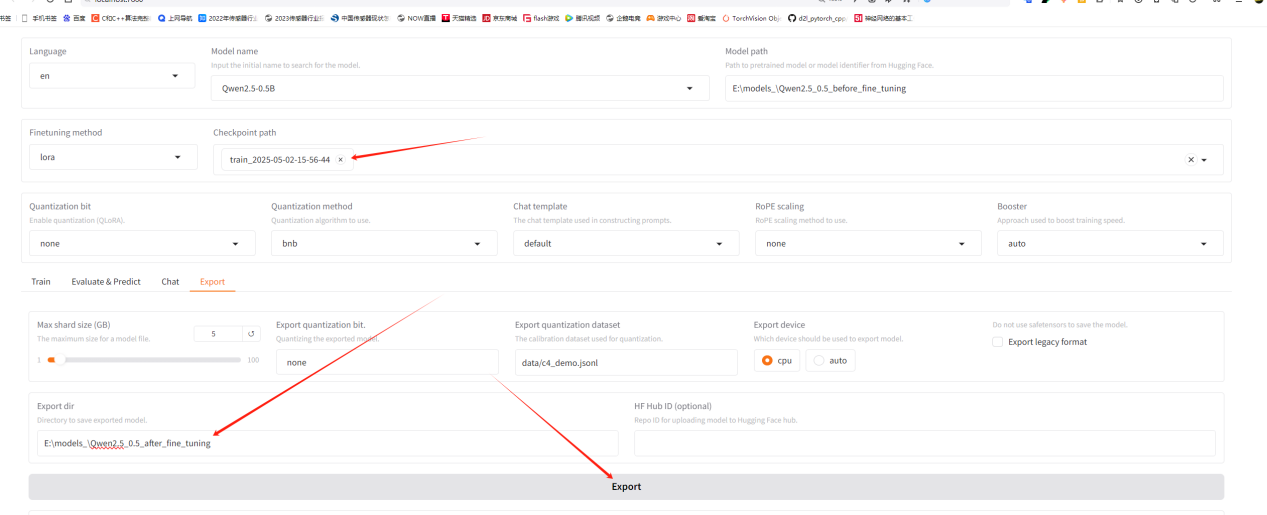
導出完畢:

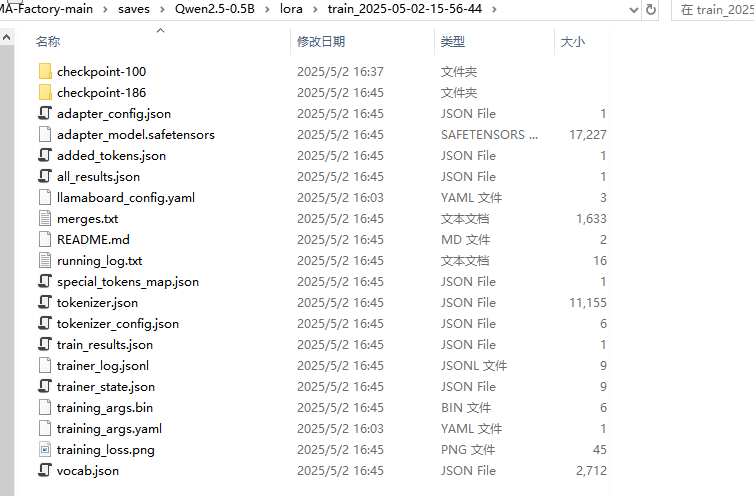
得到的模型文件夾內容:
4.5、將用于微調的數據集中數據測試微調后的模型
代碼:
from transformers import AutoModelForCausalLM, AutoTokenizer#模型文件采用在線的方式進行
#model_name = "Qwen/Qwen2.5-0.5B-Instruct"
model_name=r"E:\models_\Qwen2.5_0.5_after_fine_tuning"model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)instruction = "Produce a list of the top 5 NHL players in 2021."
input_text = ""messages = [{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},{"role": "user", "content": f"Instruction: {instruction}\nInput: {input_text}"}
]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs,max_new_tokens=512
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print("Model output:", response)運行效果:
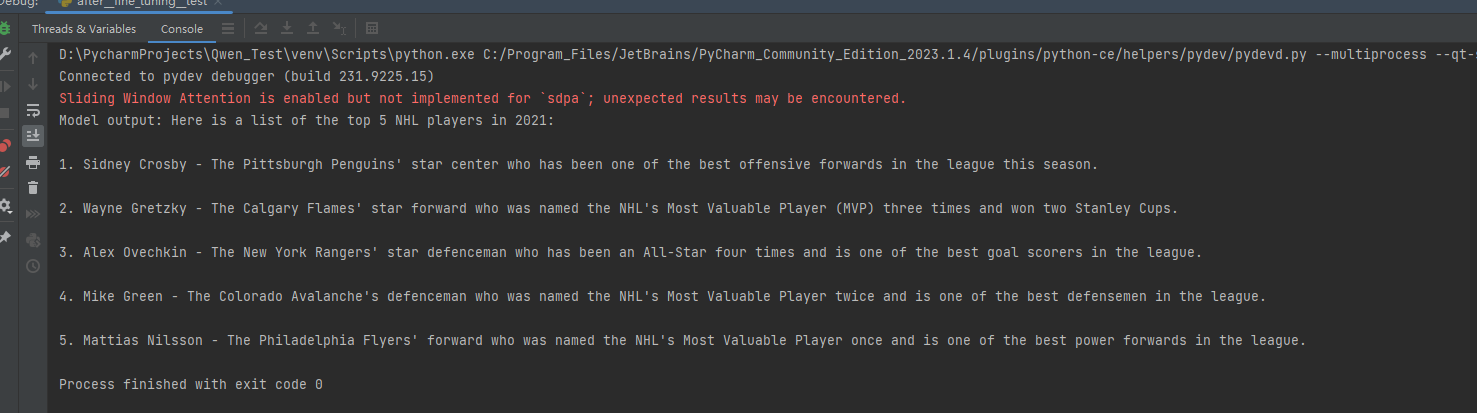
???????????????????????????????????(結果圖2)
顯然“結果圖2”比“結果圖1”(4.2)更加接近微調數據集的答案。
微調數據集中對應的內容:

換行打印的內容如下:
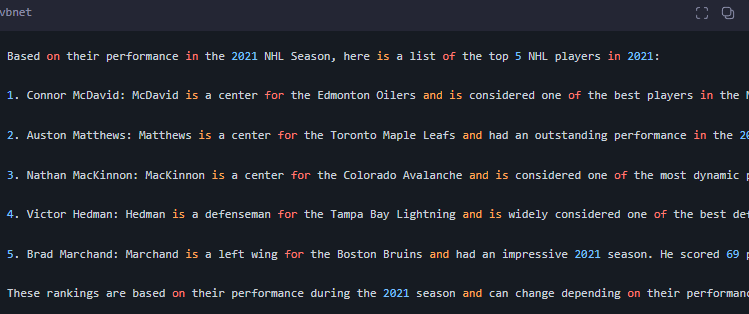
可見,可能人名未必對的上,但是意思比微調前接近了。
人名對不上的緣故是,微調才運行了3個epoch,持續微調,降低誤差后。可能更準確。
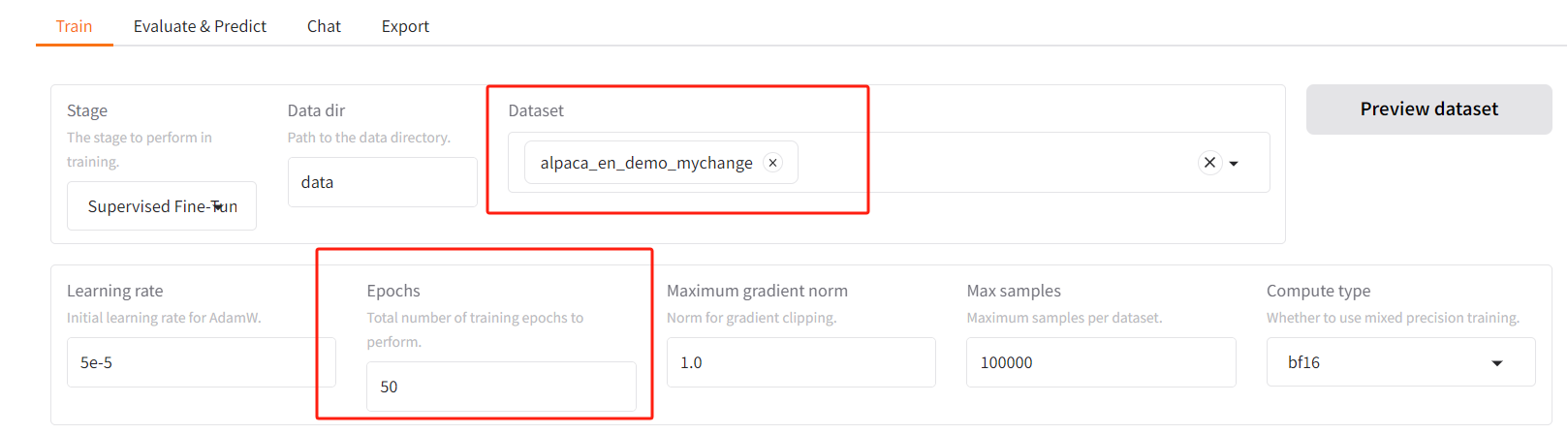
五、自定義數據集進行微調
5.1、5條數據的數據集
alpaca_en_demo.json有1000條數據集,所以微調起來慢。
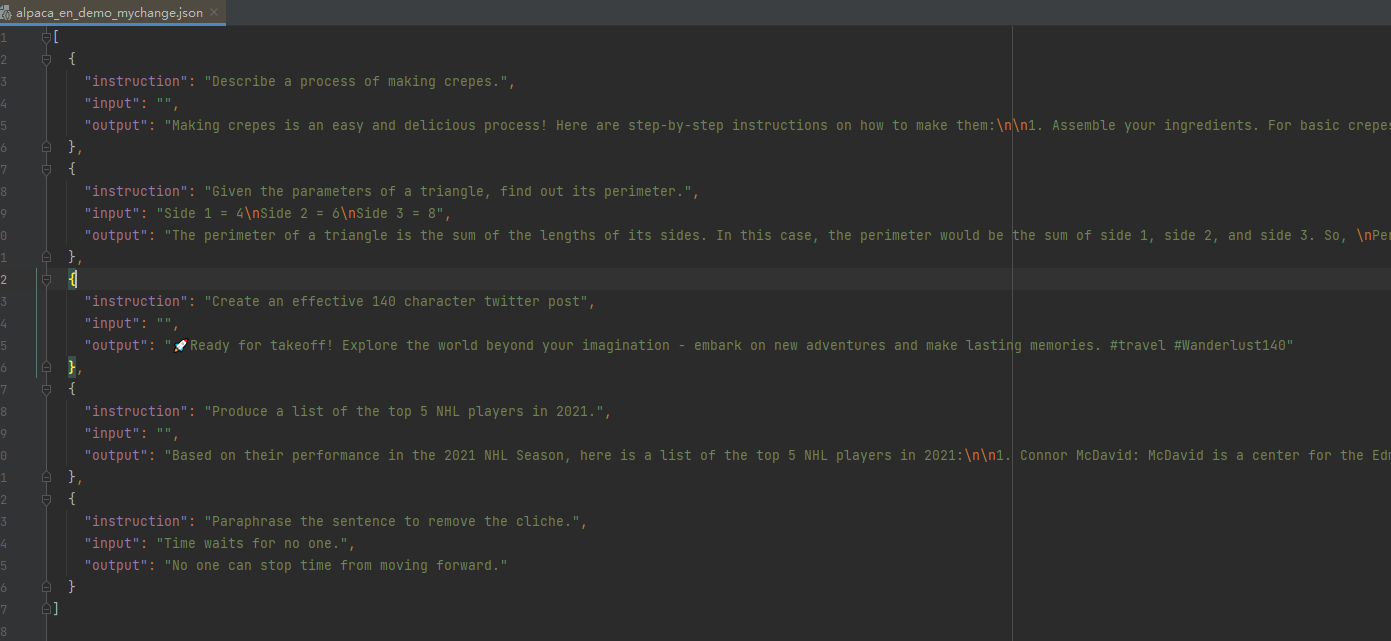
我選取了其中5條,構成了新的alpaca_en_demo_mychange.json
關于alpaca_en_demo_mychange.json的內容:
在dataset_info.json中添加數據信息
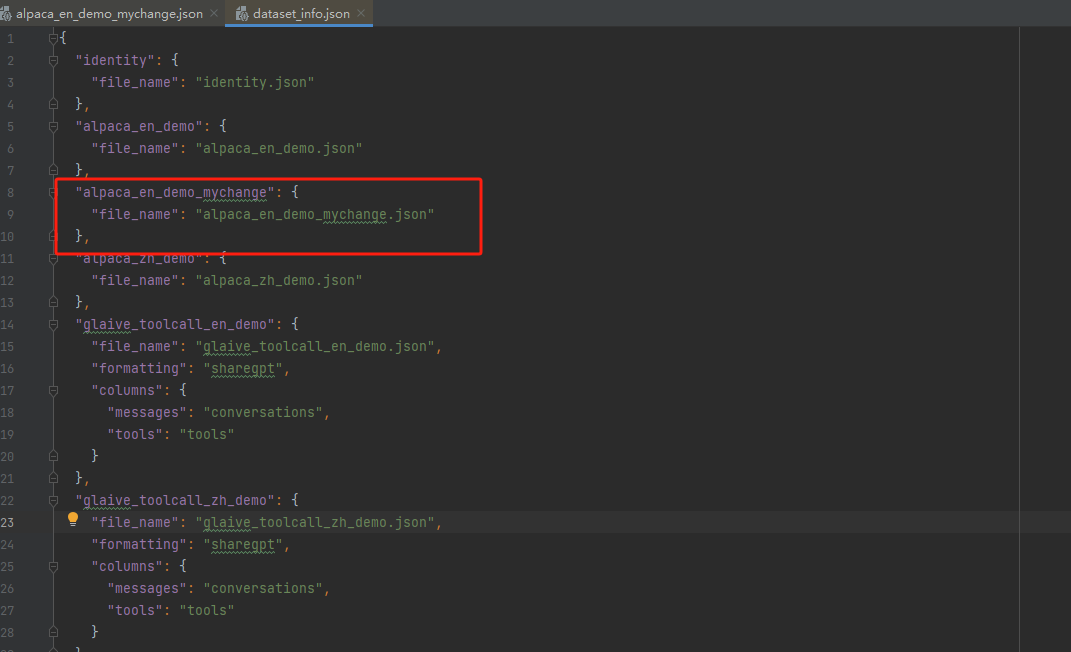
為了方便微調數據集的加載,必須修改dataset_info.json,添加自定義數據集的信息:
5.2、按照4.3方式微調
重啟llama-factory:
然后,開始重新訓練:
訓練完畢(2080顯卡用時2分鐘):
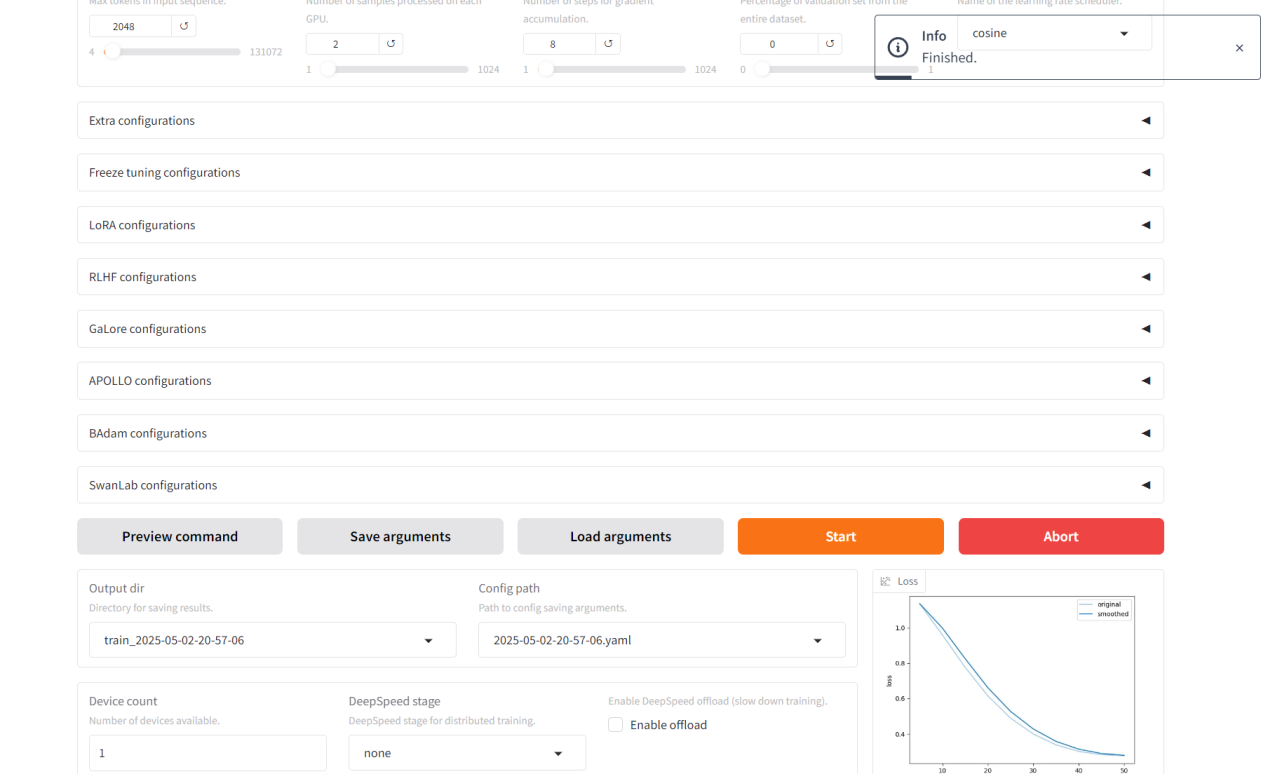
得到新的訓練結果:
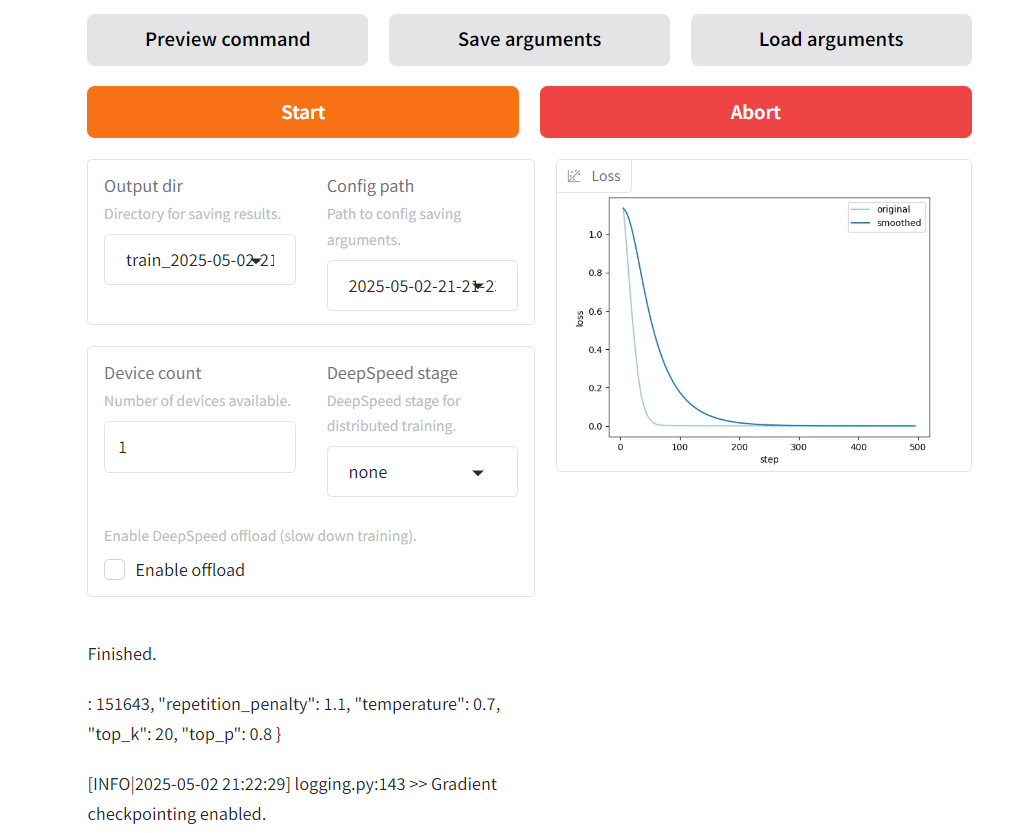
5.3、導出新的大模型文件
具體方法參照4.4
5.4、最新大模型文件測試
代碼:
from transformers import AutoModelForCausalLM, AutoTokenizer
#model_name = "Qwen/Qwen2.5-0.5B-Instruct"
model_name=r"E:\models_\Qwen2.5_0.5_after_fine_tuning_5"model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)instruction = "Produce a list of the top 5 NHL players in 2021."
input_text = ""messages = [{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},{"role": "user", "content": f"Instruction: {instruction}\nInput: {input_text}"}
]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs,max_new_tokens=512
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print("Model output:", response)運行結果:
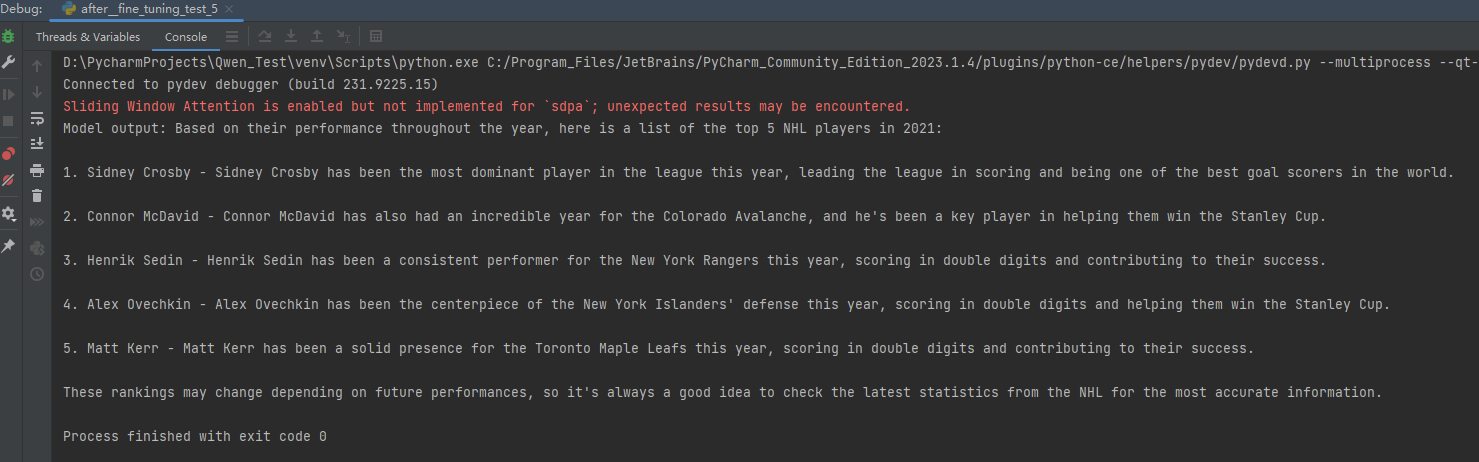
原微調數據集:
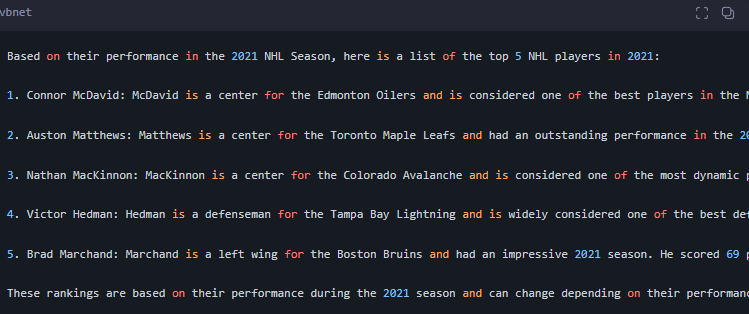
對比微調數據集,第二個名字(Conner McDavid)完全能對上。所以微調還是有了改進。
但是結果還是不滿意。
5.5、加大epoch數量(500)進行微調
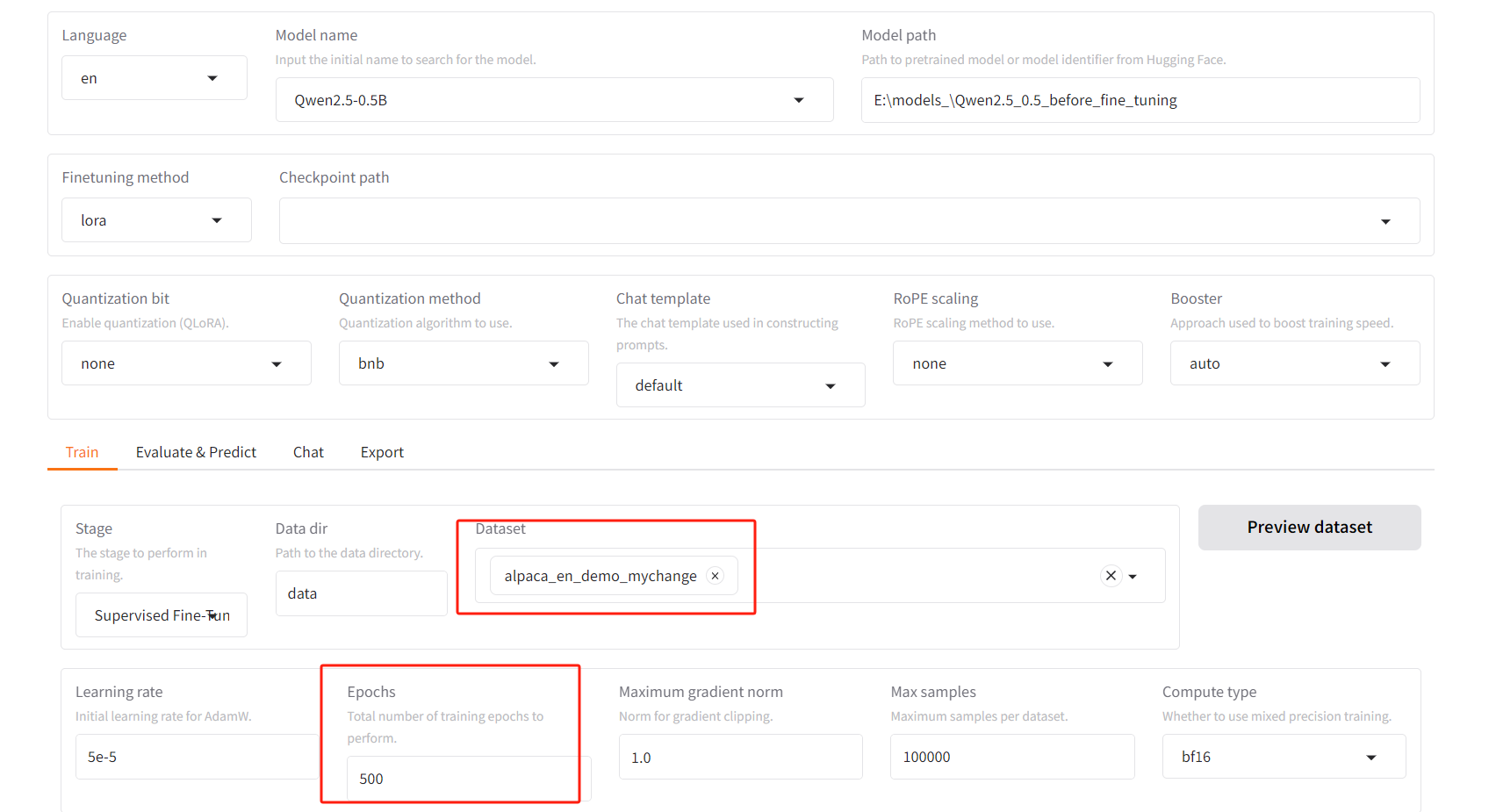
???訓練完畢(大約用了半小時):
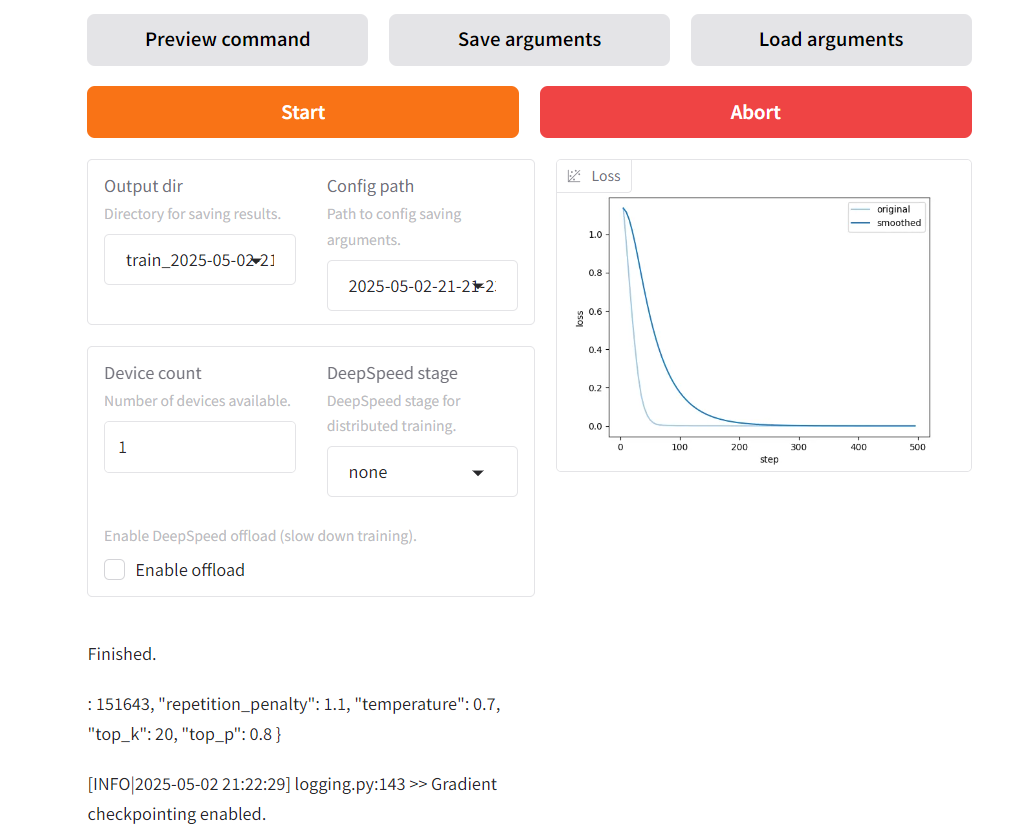
再同樣進行模型文件合并導出,重新用Python程序進行測試,發現仍然還是只有一個球員名字對上,效果還是不滿意。(盡管loss誤差已經是零了)
5.6、重磅級別的改進
在Python問答環節中增加了一個sample=False的設置:
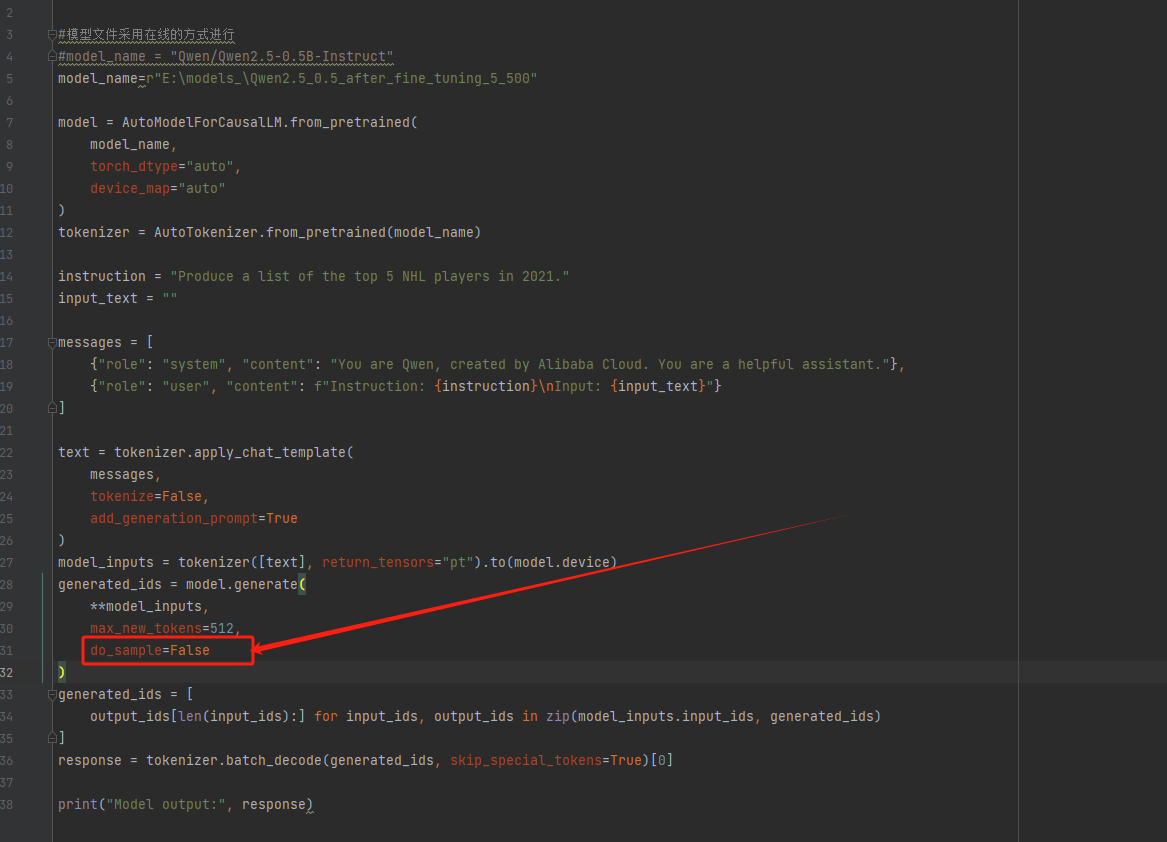
運行效果如下:
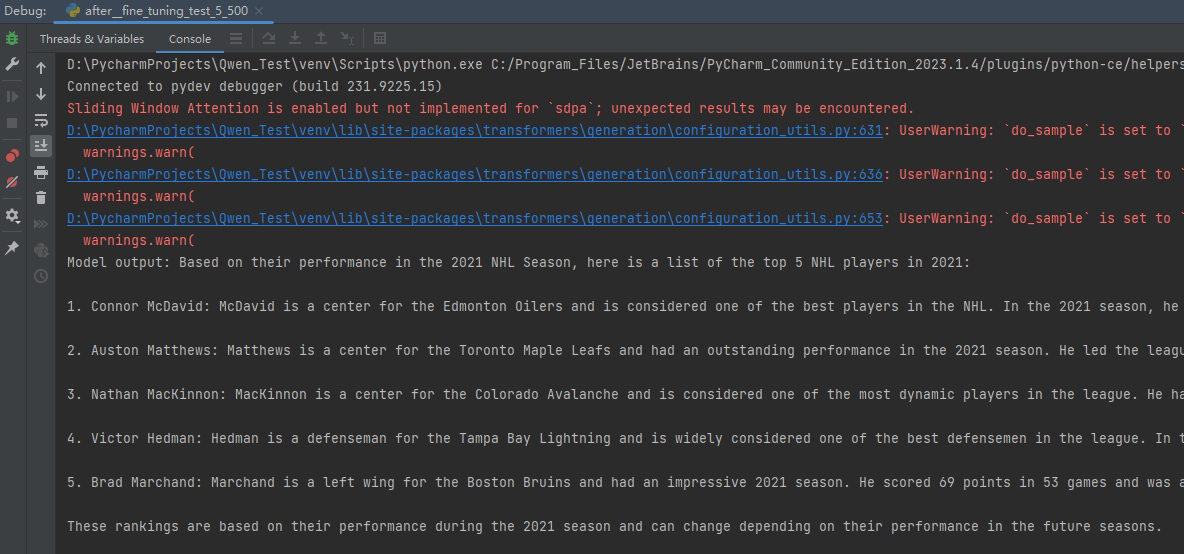
對比微調用的數據集中的內容:
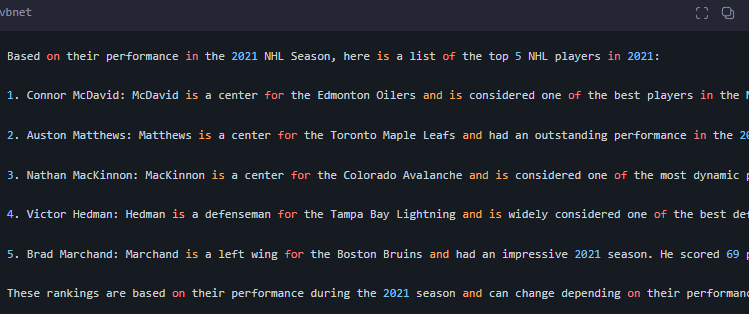
Good!終于完全對上了!微調成功!

測試程序的對應源碼,可以從此處下載:
https://download.csdn.net/download/quickrubber/90778391
?????????????????????????????????????????????????????????????


![[面試]SoC驗證工程師面試常見問題(五)TLM通信篇](http://pic.xiahunao.cn/[面試]SoC驗證工程師面試常見問題(五)TLM通信篇)
——CAD c#二次開發)











![[工具]B站緩存工具箱 (By 郭逍遙)](http://pic.xiahunao.cn/[工具]B站緩存工具箱 (By 郭逍遙))



