文章目錄
- 摘要
- 一、介紹
- 二、相關工作
- 2.1. 鉸接對象建模
- 2.2. 部件感知3D生成
- 三、方法
- 3.1. 概述
- 3.2. 通過VLM助手進行可移動部件分割
- 3.3. 通過幾何感知視覺提示的發音估計
- 3.4. 通過隨機關節狀態進行細化
- 四、實驗
- 4.1. 定量實驗
- 發音估計
- 設置:
- 4.2. 應用程序
- 五、結論
- 六、思考
摘要
3D鉸接對象建模長期以來一直是一個具有挑戰性的問題,因為它需要捕獲精確的表面幾何形狀以及語義上有意義和空間上精確的結構、零件和關節。現有方法嚴重依賴于一組有限的手工制作的鉸接對象類別(例如,櫥柜和抽屜)的訓練數據,這限制了它們在開放詞匯上下文中對大范圍鉸接對象建模的能力。為了解決這些限制,我們提出了articable ANYMESH,這是一個自動化框架,能夠以開放詞匯的方式將任何剛性3D網格轉換為其鉸接的對應對象。給定一個3D網格,我們的框架利用先進的視覺語言模型和視覺提示技術來提取語義信息,允許對象部分的分割和功能關節的構建。我們的實驗表明,articable ANYMESH可以生成大規模、高質量的3D鉸接對象,包括工具、玩具、機械設備和車輛,顯著擴大了現有3D鉸接對象數據集的覆蓋范圍。此外,我們表明,這些生成的資產可以促進在模擬中獲得新的鉸接對象操作技能,然后可以將其轉移到真實的機器人系統中。我們的Github網站是https://articulateanymesh.Github.io/。
一、介紹
大規模的數據收集是嵌入式AI和機器人技術的一個新興研究趨勢。為機器人和嵌入式AI構建的大型基礎模型非常需要數據,這加劇了對大規模數據收集的需求。與在現實世界中收集數據相比,在模擬中收集數據明顯更快、更方便,更容易捕獲各種類型的地面真實信息,如物理狀態、分段掩模、深度圖等。現有的工作已經探索了
如何在模擬中進行大規模數據收集的許多不同方面,包括資產生成、場景生成、任務設計、演示收集、獎勵設計等。盡管做出了這些努力,但一個關鍵的挑戰仍然存在:收集日常生活中必不可少的多樣化和現實的鉸接對象,這對于產生可推廣到現實世界應用的多樣化數據至關重要。實現這一目標的一種直觀方法是使用生成模型。雖然在3D資產生成方面已經取得了實質性進展,但很少有可用的方法能夠滿足對鉸接對象集合的需求。大多數3D生成方法,利用訓練網絡的前向傳遞,或SDS損耗優化,只產生物體的表面。這些物體只能作為一個整體來操作。例如,通過這些3D生成方法制作的衣柜不能打開,也不能用來存放衣服。部件感知3D生成方法生成3D物體及其部件特定細節。盡管這些方法對結構更敏感,但由于缺乏運動參數,生成的對象仍然局限于整個對象的操作。鉸接對象創建方法能夠生產具有多個交互部分的鉸接對象,展示功能。然而,這種方法需要在多個關節狀態下對待重構關節物體進行密集觀察,或者僅限于用于訓練其網絡的有限規模數據和對象類別。因此,目前的方法很難自動生成各種各樣的鉸接對象,特別是那些來自現有數據集中未被代表或缺失類別的對象。

圖1。articable ANYMESH將3D網格轉換為鉸接對象。我們的管道能夠處理各種各樣的物體,包括日用品、家具、車輛,甚至是虛構的物體。
因此,與非鉸接3D資產相比,不同鉸接對象的收集提出了額外的挑戰:(1)精確的語義結構必須伴隨著幾何和外觀,(2)關節方向和位置等關節參數是必需的,(3)與3D對象數據集相比,相對小規模的鉸接對象數據集不足以支持可泛化模型的訓練。為了克服這些挑戰,我們引入了articable ANYMESH,這是一種自動管道,可以將任何3D網格轉換為相應的鉸接資產。為了超越現有的鉸接對象數據集,我們的管道利用了視覺和語言基礎模型的先驗知識和可推廣的幾何線索,而不是依賴于現有的標記鉸接對象數據。我們的管道從生成或手工制作的3D網格開始,然后是可移動部件分割,關節估計和細化階段。
在可移動部件分割中,目標是識別所有可移動部件并確定其語義,用于后續的關節估計。最近的開放詞匯3D零件分割方法利用開放詞匯分割模型(即SAM)和多模態基礎模型對渲染的二維圖像進行分割,整合二維信息實現三維零件分割。在這項工作中,我們采用了PartSlip++提出的管道進行三維零件分割。
在獲得非固定零件的三維分割及其語義之后,我們提出的流水線的下一階段重點是關節估計。與之前的方法不同,它們依賴于訓練數據集來預測鉸接參數。為了克服現有數據集的局限性并擴展到開放詞匯表方式,我們提取了鉸接對象中固有的幾何線索,而不是依賴于學習模型。具體來說,連接兩個分段部分的關節與連接區域的幾何形狀內在相關。例如,在連接遵循一條直線的情況下,例如筆記本電腦的鉸鏈或打開的門,這條線有效地代表了關節,因為鉸鏈結構與它對齊。我們通過視覺提示為gpt - 4o提供此類信息,使其能夠利用常識性知識幾何推理來推斷關節參數。這種方法允許對未見過的物體進行泛化,并進行精確的分割,隨著視覺語言模型變得更加先進,性能將繼續提高。
在這個階段,已經創建了一個功能性的鉸接對象。但是,如果輸入網格是僅包含表面幾何和紋理的生成或掃描表面網格,則分割的3D部件經常會出現遮擋,并且可能在其他部件上留下孔洞。例如,在封閉狀態下,只會對抽屜的外表面進行分割,其內部結構根本不存在。
為了解決這些問題并完成我們提出的管道,我們加入了最后一個階段:細化。在這個階段,我們利用二維擴散模型,以關閉井眼,增強幾何形狀,并改善紋理質量。這樣的模型是在數百萬張圖像上訓練的,建立了關于3D物體的堅實先驗。這種3D先驗可以使用SDS損失有效地提取出來。盡管該優化過程不考慮三維零件分割,導致零件相互生長,但我們通過一種簡單而有效的優化策略解決了這一問題,該策略在SDS損耗優化階段根據可移動零件的連接參數進行隨機變換。
我們進行了實驗,比較了不同基線下的關節參數預估精度和無條件生成能力。實驗結果表明,雖然我們的方法與PartNet-Mobility數據集中訓練的選定類別的最先進的鉸接對象建模方法相匹配,但它也顯示出對這些類別之外更廣泛的鉸接對象進行建模的能力。我們將我們的貢獻總結如下:
?我們引入articable ANYMESH,這是一個能夠以開放詞匯的方式創建多樣化,逼真和復雜的鉸接對象的管道。
?我們提出了一種新穎的銜接參數估計方法,該方法利用幾何線索和定制的視覺提示方法以開放詞匯表的方式估計關節參數。
?我們提出了一種新的優化策略,該策略可以在細化鉸接對象之前使用擴散,同時保持部件的語義不被改變或丟失。
二、相關工作
2.1. 鉸接對象建模
其中一行工作集中在感知端,包括從觀測中重建鉸接對象,聯合參數估計網絡從輸入多幀點云重建鉸接對象。其他一些作品從主動交互中學習聯合參數。從被鉸接物體不同狀態下獲得的多視圖圖像中重建鉸接物體的幾何形狀和關節參數。通過在大規模合成數據上訓練的網絡,從單一真實世界的RGB圖像中重建鉸接物體。在給定關節對象的poincloud或圖像的情況下估計關節參數和部分段。然而,這些方法要么需要對同一物體進行廣泛的觀察,要么依賴于現有的鉸接物體數據來訓練神經網絡,在很小的類別范圍內進行泛化的能力有限。
除了感知作品,生成作品包括,將鉸接對象表示為圖形,并采用擴散模型來擬合分布。零件的形狀、位置和語義信息編碼在頂點中,而關節參數存儲在邊緣中。與感知方法類似,這些生成方法也依賴于現有的鉸接對象數據集來訓練它們的擴散模型,無法泛化到訓練數據之外。此外,最近有一項關于鉸接對象建模的調查。總的來說,現有的方法都不能以開放詞匯表的方式自動創建鉸接對象。
2.2. 部件感知3D生成
部件感知3D生成方法不是生成一個整體的3D對象,而是生成帶有部件級信息的對象。學習兩個獨立的VAEs來建模全局結構信息和詳細的零件幾何形狀。將3D對象編碼為分解結構和幾何形狀的表示。利用圖VAE將形狀編碼為分層圖表示。應用Seq2Seq生成網絡進行零件裝配和生成。獨立建模零件幾何形狀和整體零件變換,并以兩者為條件,擴散模型綜合最終形狀。另一方面,用一個擴散模型生成局部幾何勢,并用這些勢為條件的另一個擴散模型合成全局幾何。提供的生成的多視圖圖像和相應的2D分割圖中學習news模型,并使用聚類算法提取3D分割蒙版。
雖然這些方法可以產生具有合理結構和零件幾何形狀的形狀,但它們經常依賴于具有零件級注釋的對象數據集,并且無法泛化用于訓練的數據集之外的數據集。此外,它們不為單個零件生成關節參數,導致生成的零件在仿真中單獨不可操作,這限制了它們在機器人學習的下游任務中的適用性。
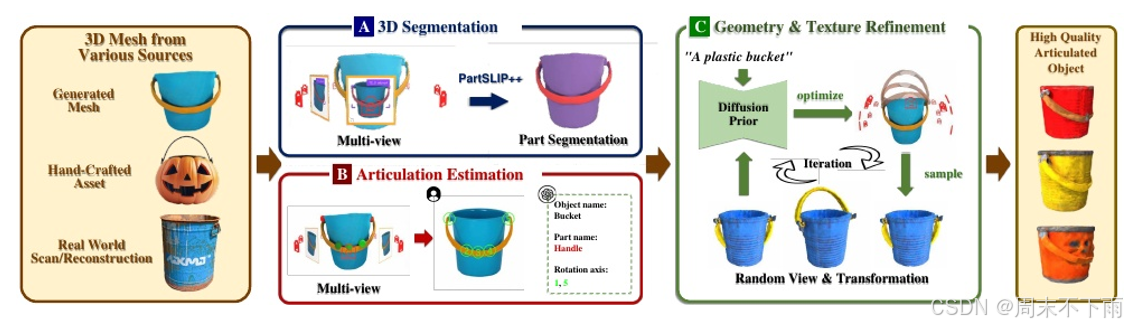
圖2。articelanymesh通過三個主要部分將來自各種來源的3D網格轉換為高質量的鉸接對象:A.可移動部件分割,B.關節估計,C.細化
三、方法
3.1. 概述
我們的管道將任何網格轉換為其鉸接的對等體,包括具有部分幾何形狀的手工制作網格,通過文本到3d或圖像到3d方法生成的表面網格以及從現實世界對象重建的網格。該過程包括三個主要步驟,包括可移動部件分割、關節估計和細化,如圖2所示。具體而言,可移動部件分割步驟采用PartSlip++提出的方法從輸入網格中分割可移動部件。關節估計利用視覺和語言基礎模型中的幾何線索和先驗知識提取每個可移動部件的關節參數。在細化階段,通過幾何感知的2D擴散模型Rich-dreamer增強鉸接對象的幾何和紋理,并在SDS損失的指導下提取擴散模型的3D先驗。在此階段,可移動部件進行隨機變換以提高優化性能。
3.2. 通過VLM助手進行可移動部件分割
如圖2A所示,此步驟旨在從3D網格中分割所有可移動部件,并以開放詞匯表的方式識別其語義。我們主要使用PartSlip++ 作為我們的分割方法。在Part-Slip++中,首先將輸入網格的圖像饋送到VLM中以識別所有可移動部件。接下來,將開放詞匯表接地模型和SAM應用于輸入網格的2D渲染圖像,以提取相關部件語義標簽的邊界框和分割掩碼。然后將這些多視圖2D檢測和分割結果融合以產生3D零件分割。
3.3. 通過幾何感知視覺提示的發音估計
實現膠接估計的開放詞匯范圍需要超越發音對象的有限尺度數據集。為了解決這個問題,我們提出了一種幾何感知視覺提示方法,該方法通過利用幾何、機械結構和功能方面的共享特征,概括了各種鉸接對象。具體來說,我們觀察到連接兩個部件的關節與部件非常接近的區域的幾何形狀密切相關,我們將其稱為連接區域。
**將兩個相鄰部分a和b的點云分別表示為Pa和Pb。為了定義連接區域,我們選擇Pa中與Pb中最近點的距離低于預定義閾值的點,反之亦然對于Pb中的點。從Pa和Pb中選擇的點一起構成了零件之間的連接區域。如果沒有點被選中,則閾值加倍,并重復該過程,直到確定連接區域。**我們主要關注兩種占主導地位的關節類型:移動關節和旋轉關節。這些都是使用適合其各自機械結構的不同方法進行估計的。
旋轉關節通過物理鉸鏈或其他類似鉸鏈的機構(如紙板箱的蓋子)連接鉸接物體的兩個部分。旋轉關節的旋轉軸與其鉸鏈的長度對齊,這意味著在3D空間中識別鉸鏈可以直接估計旋轉軸。由于鉸鏈在物理上連接兩個部件,因此它通常位于部件連接的區域內。在這一觀察結果的驅動下,我們提出了以下視覺提示流程。首先,我們將連接區域劃分為多個集群,集群中心作為候選點。然后將這些候選點投影到輸入網格的2D渲染圖像上,并用數字標記
如圖2B所示。該圖像用于提示gpt-4o選擇兩個或多個定義鉸鏈的點,從而建立旋轉軸。選擇渲染視點以最大化所考慮的部件的像素數。K-means以不同的聚類計數運行多次,并選擇最終計數以最大化候選點的數量,同時避免在渲染圖像上重疊標簽。
在某些情況下,鉸鏈可能沒有定位在對象的表面上,導致在對象表面上只能識別旋轉軸的一端,例如帶有旋鈕。在這些情況下,我們假設旋轉軸垂直于貼合到連接區域的平面。然后,軸由該平面的法向量和單個選定點確定。當鉸鏈機構隱藏在表面之下時,不能假定連接結構完全在連接區域內。因此,除了來自連接區域的候選點外,我們還從零件表面采樣額外的點。具體來說,我們使用l0-cutpursuit 算法從零件的點云中生成超級點,使用點法線和顏色作為特征,并從這些超級點中導出候選日期點。這確保了新的候選點分布在零件的不同幾何和紋理區域。
棱鏡關節通過滑動機構連接鉸接對象的兩個部分,實現沿單軸的線性運動。如果輸入網格包含物理上精確的內部幾何,則對無碰撞滑動方向進行采樣可能會產生精確的棱柱關節軸。然而,大多數網格,特別是表面網格,缺乏這種基于碰撞的方法所需的理想幾何形狀。此外,滑動機構通常隱藏在物體表面之下,與旋轉關節的鉸鏈結構相比,使其難以識別,并且使用于旋轉關節的策略不適用于移動關節。
根據其功能,移動關節可分為兩種類型:
- 向內和向外滑動接頭:這些接頭允許子組件在其連接的對象中滑動進出,如抽屜和按鈕等部件。雖然平移方向可能不同,但將部件拉出的運動主要是從對象向外移動。因此,滑動方向的特征是擬合到連接區域的平面的法向量。
- 表面滑動接頭:這些接頭使子組件能夠沿著對象的表面滑動,就像在滑動窗口和烤面包機杠桿等部件中看到的那樣。對于這樣的關節,潛在的平移方向被限制在沿表面的二維范圍內。這允許我們用箭頭標注2D渲染圖像,并提示GPT-4o選擇最合適的方向。
給定一個鉸接對象及其分割部分,我們提示GPT-4o將所有移動關節分為這兩類。基于分類,然后對棱柱關節的平移方向進行相應的估計。
3.4. 通過隨機關節狀態進行細化
在完成3D分割和關節估計階段后,我們得到了一個具有正確結構的鉸接對象。然而,當輸入網格是曲面網格時,結果往往仍然存在缺陷。從表面網格分割出來的物體部分——缺乏內部結構——不可避免地會受到遮擋,導致有孔的部分網格不完整。
為了解決這個問題,我們將一個細化步驟集成到我們的管道中。該步驟完成遮擋的幾何形狀,填充孔洞,并通過使用SDS損失將3D物體幾何形狀和紋理先驗從幾何感知的2D擴散模型提取到關節物體中來增強紋理質量。細化過程建立在richdream 的基礎上,它依次應用法向深度擴散模型和反照率擴散模型,分別優化3D物體的幾何和紋理。
然而,將現有的SDS優化方法直接應用于固定姿態的鉸接物體上,往往會導致零件的生長和重疊,從而在物體零件運動時產生偽影。為了解決這一問題,我們提出了一種針對鉸接對象的新穎優化技術:在優化過程中隨機化鉸接配置。在每個優化步驟中,除了隨機采樣攝像機位置和擴散時間步外,我們還對每個非固定部分的運動參數(例如,旋轉角度和平移長度)進行采樣,并應用這些變換。這種方法確保了大多數部分在某些姿勢下暴露,而一個姿勢中的重疊幾何形狀在其他姿勢中作為偽像變得明顯,從而允許逐步優化。由于零件在初始化時已經可以識別,因此擴散模型有效地保留了它們的語義,確保了零件的含義和身份在整個細化過程中保持不變。
實現細節請參考附錄A。
四、實驗
在可移動部件分割階段,我們使用Partslip++進行分割,并用DINO-X重新放置接地模型,以獲得更好的性能。此外,還提示gpt-4o提取輸入網格的部分標簽及其部分聯結點圖形,如關節類型,父鏈接等。在關節估計階段,我們直觀地提示gpt40其余的關節配置。在細化階段,我們實現了用于鉸接對象表示的多部分DMTet (Shen等人,2021)。物體的每個部分被分配一個獨立的DMTet網絡來描述其幾何和紋理特征。我們利用Richdreamer 提出的法向深度擴散模型和反照率擴散模型進行幾何和紋理先驗。
基線據我們所知,這是第一個以開放詞匯表的方式解決將網格轉換為鉸接對象的挑戰的工作。因此,沒有現有的基線直接處理與articalanymesh相同的輸入和輸出。相反,我們單獨評估各個組件,并與相應的基線進行比較。我們流水線中的關節估計步驟將對象部件作為輸入,并輸出它們的關節配置。NAP (Lei et al., 2023)和CAGE 學習擴散模型生成鉸接對象,也可以生成以對象部件為條件的關節配置,使其成為該步驟最接近的基線。此外,ANCSH、OPD 和OPDmulti 等方法可以直接估計關節參數。這些方法采用單個觀測值(例如,RGB、深度或兩者)作為輸入,同時預測零件分割和關節參數,作為額外的基線。我們將這些方法與articalanymesh中的三維分割和關節估計相結合的步驟進行了比較。對于細化步驟,由于我們的方法是基于Richdreamer ,因此它可以作為該階段的自然基線。
對于關節參數估計,我們使用角誤差來評估關節方向精度,使用線之間的距離來評估關節位置精度。
對于細化步驟,由于沒有理想的度量可以在沒有參考集的情況下直接評估3D對象的視覺質量和結構正確性,因此我們轉而渲染不同狀態下鉸接對象的2D圖像,并使用測量圖像標題相似性的度量來評估這些圖像。潛在的假設是,結構準確且視覺上合理的鉸接對象將產生更好地對應其類別的渲染圖像,從而獲得更高的圖像-文本對應分數。具體來說,我們使用CLIPscore (Hessel et al., 2021)和VQAscore (Lin et al., 2024)作為該評估的指標。
4.1. 定量實驗
發音估計
如基線部分所述,我們在兩種情況下評估發音參數估計的性能
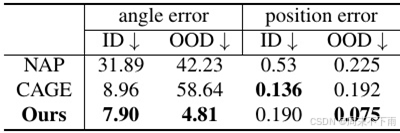
表1。在兩組測試對象類別上評估目標部件網格連接估計的結果:域內(ID),由CAGE訓練集中的類別組成;域外(OOD),由來自PartNet-Mobility的一些不屬于CAGE訓練集的類別組成。
設置:
?對象部分網格作為輸入。對于使用物體部分網格的關節參數估計,我們將AR-TICULATE ANYMESH與兩種生成擴散模型(NAP和CAGE)進行比較,這兩種模型將關節物體表示為圖。在這個實驗中,我們提供了所有部件的ground-truth形狀,任務是估算它們的鉸接參數。NAP生成的聯合參數(邊)以真地頂點為條件,如零件邊界框、空間位置和形狀潛點。對于CAGE,為每個節點提供邊界框、關節類型和語義標簽等屬性,同時生成關節軸和范圍。我們使用來自伙伴移動的鉸接對象進行評估,遵循CAGE中使用的訓練-測試分割,并在相同的分割上對NAP進行再訓練。我們使用測試集中的對象和排除在訓練之外的類別的泛化性能來評估域內性能。如表4.1所示,雖然articable ANYMESH在域內實現了與NAP和CAGE相當的性能,但在未見過的類別中,它的性能明顯優于它們。
?單觀測作為輸入。我們還將articulate ANYMESH與三種方法(ancsh, OPD和opdmulti)進行了比較,以從單次觀測中估計關節參數。ANCSH使用單視圖點云作為輸入,而OPD和OPD-multi采用RGB圖像(可選的深度信息)作為輸入。這些方法輸出部分分割和關節參數。為了適應這種設置,我們修改了管道,使只有一個圖像(輸入觀察)被分割。得到的分割結果被投影到帶有標簽的點云中,然后在銜接估計步驟中進行處理。表4.1所示的結果表明,盡管articable ANYMESH被設計為一種免費的、開放詞匯表的訓練方法,但它在各自的訓練領域內的表現優于ANCSH、OPD和OPDmulti。

圖3。細化步驟輸出的鉸接對象的可視化。(a) articable ANYMESH生成的各種鉸接對象(輸入網格由InstantMesh生成(Xu等人,2024));(b)對于相同的輸入,由細化步驟創建的不同紋理,保留幾何和鉸接參數(用方框突出顯示);? articable ANYMESH生成的虛擬對象

圖4。articable ANYMESH適用于從Objaverse中檢索的手工制作的網格

表2。單觀測聯合估計結果。用于訓練和測試的數據集是單門數據集(OPDsynth的子集),用于訓練PyTorch版本Github存儲庫中提供的ANCSH。
細化
對于細化步驟,我們使用章節metrics中描述的度量來評估精細鉸接對象的視覺質量和結構正確性。我們在發音估計步驟的中間輸出上測試了三種配置:(1)沒有應用細化步驟,(2)沒有隨機變換的情況下應用細化步驟(與Richdreamer)和(3)應用隨機變換的細化步驟。本實驗中使用的表面網格是使用文本到3d模型InstantMesh 生成的,以伙伴移動中對應類別的文本提示為條件。表4.1所示的結果表明,通過結合隨機變換的細化獲得了最高分,突出了我們提出的細化步驟的有效性。

表3。細化步驟的評價。Re代表細化,RT是隨機變換的縮寫。
4.2. 應用程序
通過集成現有的3D生成模型來生成表面網格,作為articable ANYMESH的輸入,我們的管道利用了3D生成模型的開放詞匯3D生成能力,并繼承了其生成范式。如圖3所示,我們的擴展管道生成了各種類別的高質量鉸接對象,從日常對象到專業工具。

圖5.。我們使用我們的方法在模擬中構建了真實世界物體的數字雙胞胎。然后我們在模擬中對完成任務的軌跡進行采樣,并在現實世界中復制這些軌跡。
注釋3D對象數據集Other than generated from Scratch,我們的工作也可以從現有的藝術家設計的網格開始。例如,我們在Objaverse對象上標注部分分割和關節結構。這樣的對象通常具有高質量的網格和紋理,也具有內部結構。因此,我們只執行管道的3D分割部分和關節估計部分來注釋這些對象。結果如圖4所示。預告片(圖1)中的對象也是用這種方式產生的。
在本實驗中,我們首先使用2DGS重建現實世界物體的3D表面網格。然后應用articable ANYMESH將重建的網格轉換為URDF格式表示的仿真對象,使其與仿真環境兼容。接下來,我們對動作目標進行采樣,并使用運動規劃(Sucan et al., 2012)來避免碰撞,生成軌跡以成功完成仿真中的任務。最后,我們在現實世界中復制軌跡,觀察到機械臂可以有效地執行任務。
我們重點研究了涉及不同鉸接物體的三個任務:推鉆扳機、打開微波門和旋轉方向盤,如圖5所示。
我們的結果表明,生成的軌跡可以成功地轉移到現實世界中,在零件分割和關節預測方面顯示出極小的誤差。
模擬中的策略學習我們遵循DexArt 進行鉸接對象操作策略學習,并評估兩個任務:打開筆記本電腦蓋子和提起水桶。為了增強“桶”和“筆記本”實驗的訓練集,我們包括了由articable ANYMESH生成的相同類別的附加鉸接對象。此外,我們通過合并一些生成的鉸接對象來使測試集多樣化。我們對專門在原始數據集上訓練的檢查點進行微調,并評估它們在增強測試集上的性能。結果如表4.2所示

表4。操作策略學習實驗的成功率,將在原始訓練集上微調的策略與在增強訓練集上微調的策略進行比較。報告結果,用于在增強測試集上進行評估。
articable ANYMESH生成的數據有效地增強了機器人的學習能力。articable anymes生成的鉸接對象來源于Objaverse。
五、結論
在本文中,我們介紹了articable ANYMESH,這是一個新的框架,用于將開放詞匯3D網格轉換為鉸接網格的關鍵任務。我們的管道首先基于零件級語義對3D對象進行分段,估計對象零件之間的銜接結構,然后對幾何和紋理進行細化,以修復缺陷并增強視覺質量。通過利用視覺語言模型和視覺提示技術的進步,我們有效地分割了零件,并使用常見的幾何線索估計了關節結構。我們的流水線從生成的3D網格、手工制作的3D資產和重建的網格中創建高質量的紋理鉸接對象。生成的資產可以支持仿真中鉸接對象操作技能的學習,然后可以轉移到現實世界的機器人中。
局限性和未來的工作盡管我們的方法創建了具有語義正確部件的鉸接對象,但鉸接參數并不總是準確或物理接地。這種限制源于三個關鍵挑戰:(1)現有和生成的3D網格通常缺乏正確的物理結構,(2)當前的3D分割方法偶爾會產生不正確的結果,以及(3)gpt40展品
在某些情況下的偏見。此外,一些不常見的情況并沒有被我們的方法所涵蓋——例如,當一個抽屜被設計成可以正面拉開的時候。
如果未來的進步導致具有增強的3D推理能力的大型vlm的開發,我們的管道可以利用這些改進變得更加穩健和可靠。解決這些挑戰以創建完全準確和物理接地的發音參數代表了未來研究的一個令人興奮的方向。
六、思考
1、本文所提的算法解決了什么問題?算法的網絡模型及主要Idea(自己畫圖來闡述)?
2、算法所采用關鍵技術(用自己的話來解釋,不需要翻譯論文)?
3、仿真的參數以及性能評價的標準,并學習文章作者的對數據的分析部分。
4、通過仔細的閱讀說明該算法的優缺點,最好擬提出如何解決缺點?
5、對該問題的展望是什么,包括可以開展的工作等。
針對問題一:
- 提出一了一種小規模泛化的開放詞匯集的鉸接物體生成任務;主要的解決問題,就是提供了一種鉸接物體的生成任務;主要流程就是分割-評估-在生成;主要idea,一個是提出這個想法并成功實現,第二個就是阻止了擴散模型的任意生成所提出對SDS的改進。
針對問題二:
就是采用分割模型,對圖像進行分割,然后就是對擴散模型的應用。
針對問題三:
由于本篇文章在鉸接領域無人做過相同的輸入輸出,作者采用的逐步分解的比較方法,每一步的產生結果都會與其他模型進行比較;在細化方面,引入了角誤差的評價指標,以顯示其精度
針對問題四:
其實在算法上并沒有特別大的改進,但在分割時候會有分割的不準確,可以加入幾何先驗進行進一步的提升。
針對問題五:
針對這篇資產生成的論文,在各個領域都有應用,如果繼續做下去,還有兩個方向可以繼續做,第一個就是對于分割精準度的優化,通過添加一些結構性物理先驗的正則項,可能會進一步提高分割情況;第二個就是對幾何結構上的優化,用生成擴散模型生成出來的資產可能會有幾何上的缺陷,需要進一步的提高幾何質量。








![[工具]B站緩存工具箱 (By 郭逍遙)](http://pic.xiahunao.cn/[工具]B站緩存工具箱 (By 郭逍遙))










