什么是向量數據庫?
向量數據庫是一種專門設計用來存儲、索引和查詢向量數據的數據庫系統。在當今的人工智能和機器學習領域中,向量數據庫變得越來越重要,尤其是在處理高維數據如圖像、音頻和文本等非結構化數據時。

主要用途
- 相似度搜索:通過計算向量之間的距離(如歐氏距離、余弦相似度)來查找與給定向量最接近的數據點。
- 推薦系統:利用用戶和物品的向量表示進行個性化推薦。
- 自然語言處理:用于文本分類、情感分析等任務中,通過將文本轉換成向量來進行處理。
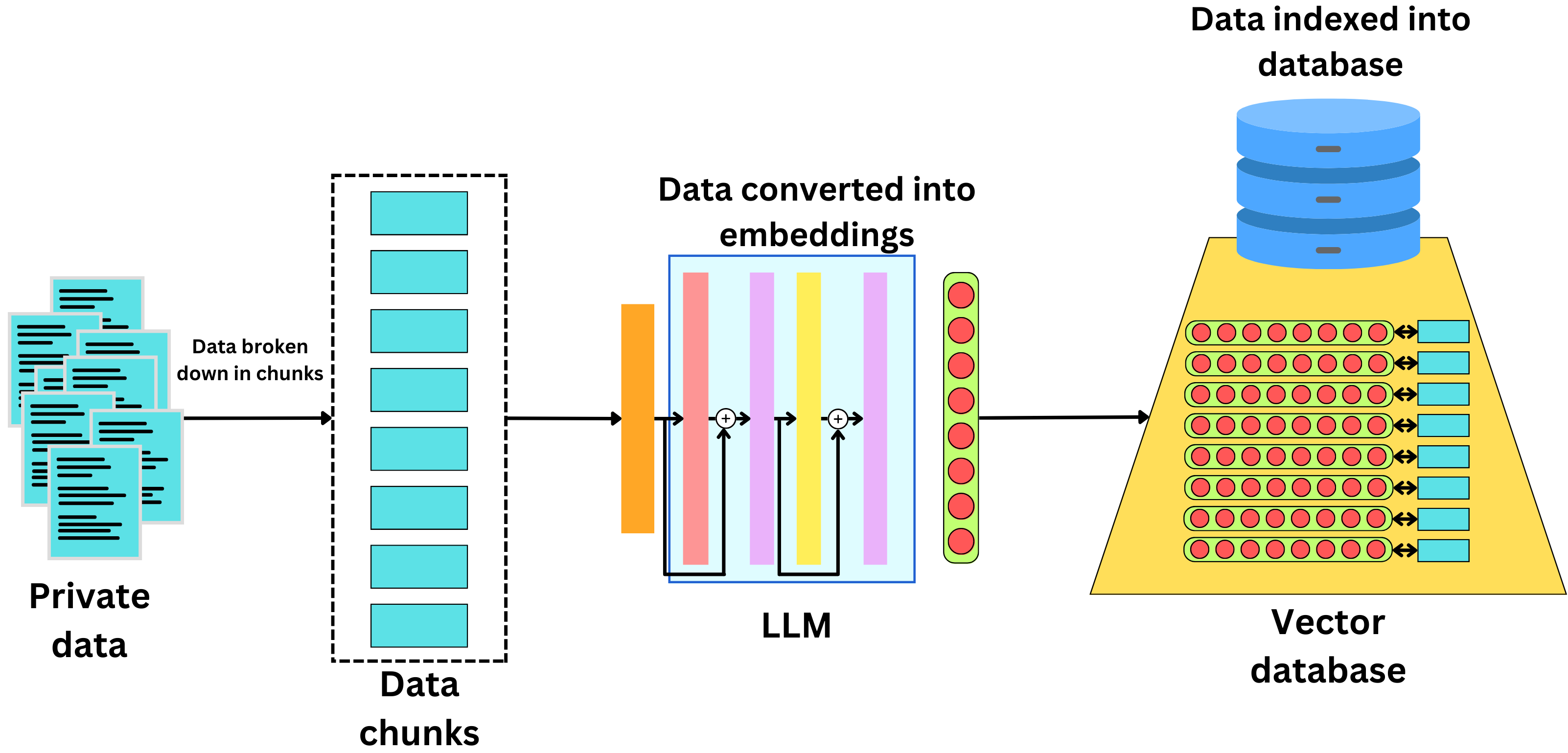
特性
- 高效查詢:針對大規模向量數據集優化了查詢性能,使得即使在海量數據中也能快速找到最近鄰。
- 可擴展性:支持水平擴展以應對不斷增長的數據量。
- 兼容性:可以與多種數據源和AI模型集成,方便數據處理和分析流程的構建。
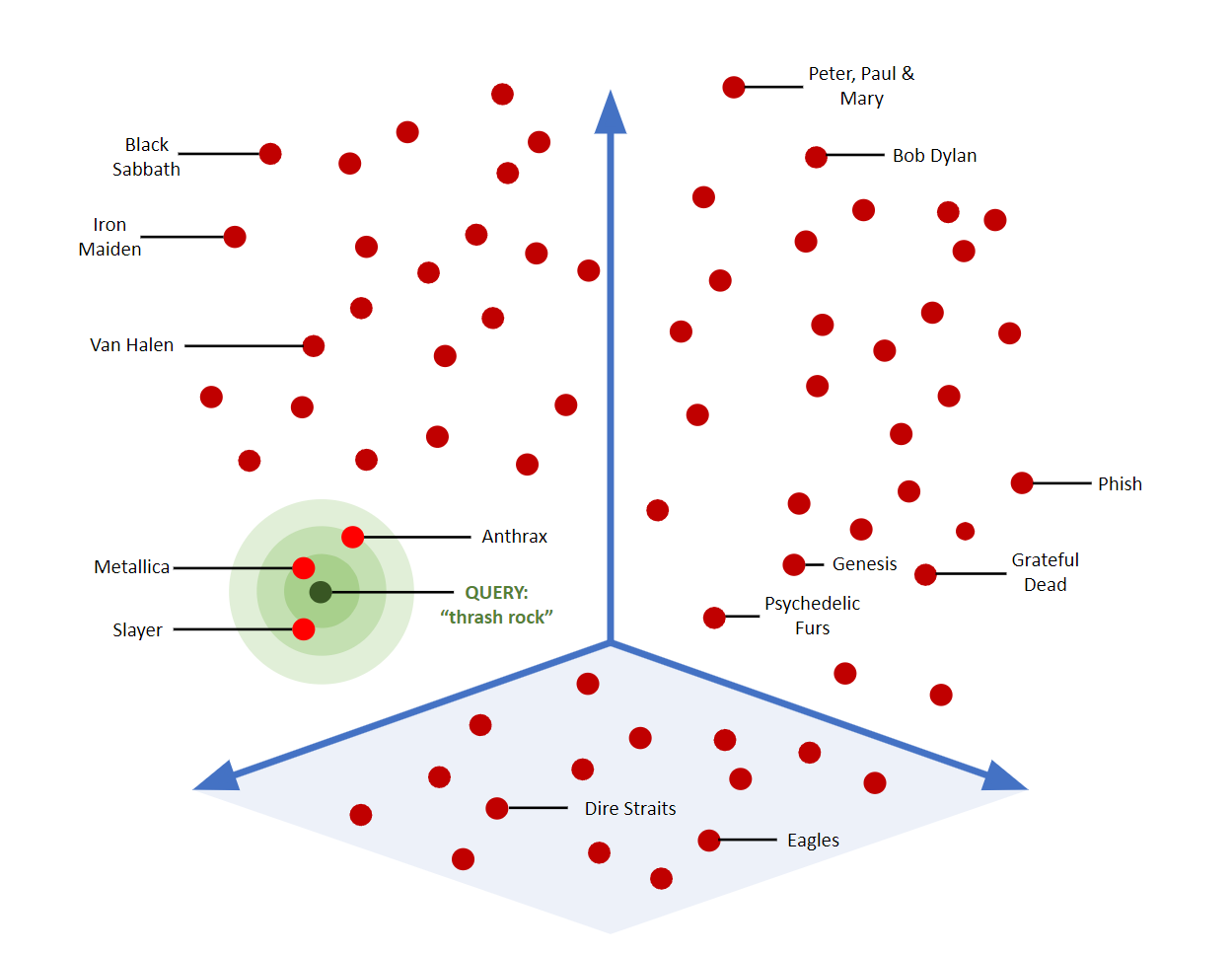
流行的向量數據庫
- Milvus:一個開源的向量數據庫,旨在使相似度搜索變得更加簡單易用。
- Faiss:由Facebook AI Research開發,專注于高效的相似度搜索和聚類。
- Pinecone:一種云服務形式的向量數據庫,強調實時性和可擴展性。
隨著深度學習技術的發展,向量數據庫的應用場景將會更加廣泛,為解決復雜的搜索和匹配問題提供強大的工具。
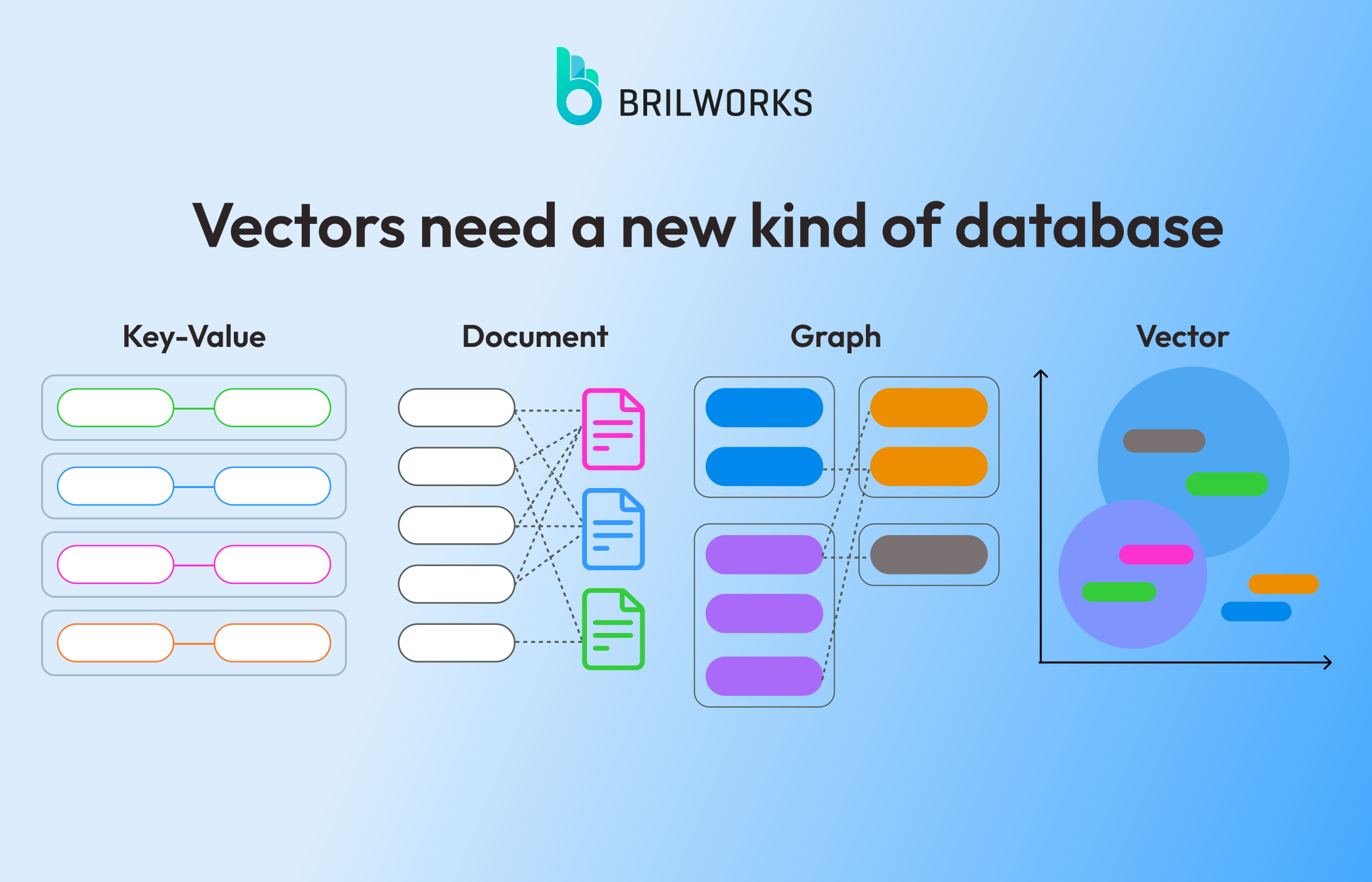
向量數據庫和關系數據庫有什么區別?
向量數據庫和關系數據庫在設計目標、數據模型、查詢方式等方面存在顯著差異,它們各自適用于不同類型的應用場景。以下是兩者的主要區別:
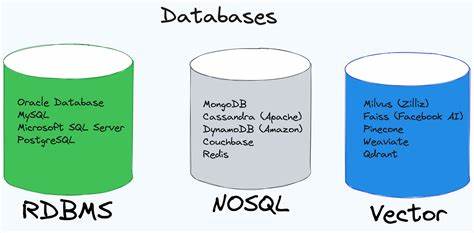
數據模型
- 關系數據庫:基于表格的數據模型,數據以行和列的形式組織,每個表有固定的結構(模式),包括字段名和數據類型。關系數據庫通過定義主鍵、外鍵等來維護數據之間的關系。
- 向量數據庫:主要用于存儲高維向量數據,這些向量通常代表了某種特征空間中的點。例如,在機器學習應用中,文本、圖像等非結構化數據可以通過各種嵌入技術轉化為向量形式。

查詢方式
- 關系數據庫:使用SQL(Structured Query Language)進行數據的查詢、更新、刪除等操作。查詢通常基于特定的條件或關系(如等于、大于、小于等比較運算符)。
- 向量數據庫:專注于相似度搜索,即查找與給定向量最“接近”的其他向量。這通常涉及到計算向量間的距離(如歐氏距離、余弦相似度等)。雖然也可以支持一些傳統的過濾和檢索功能,但其核心能力在于處理復雜的相似度匹配任務。

應用場景
- 關系數據庫:廣泛應用于需要精確匹配和復雜事務處理的應用中,如金融系統、在線交易處理(OLTP)等。
- 向量數據庫:更適合用于處理大規模非結構化數據的相似性搜索任務,如推薦系統、圖像識別、自然語言處理等領域。
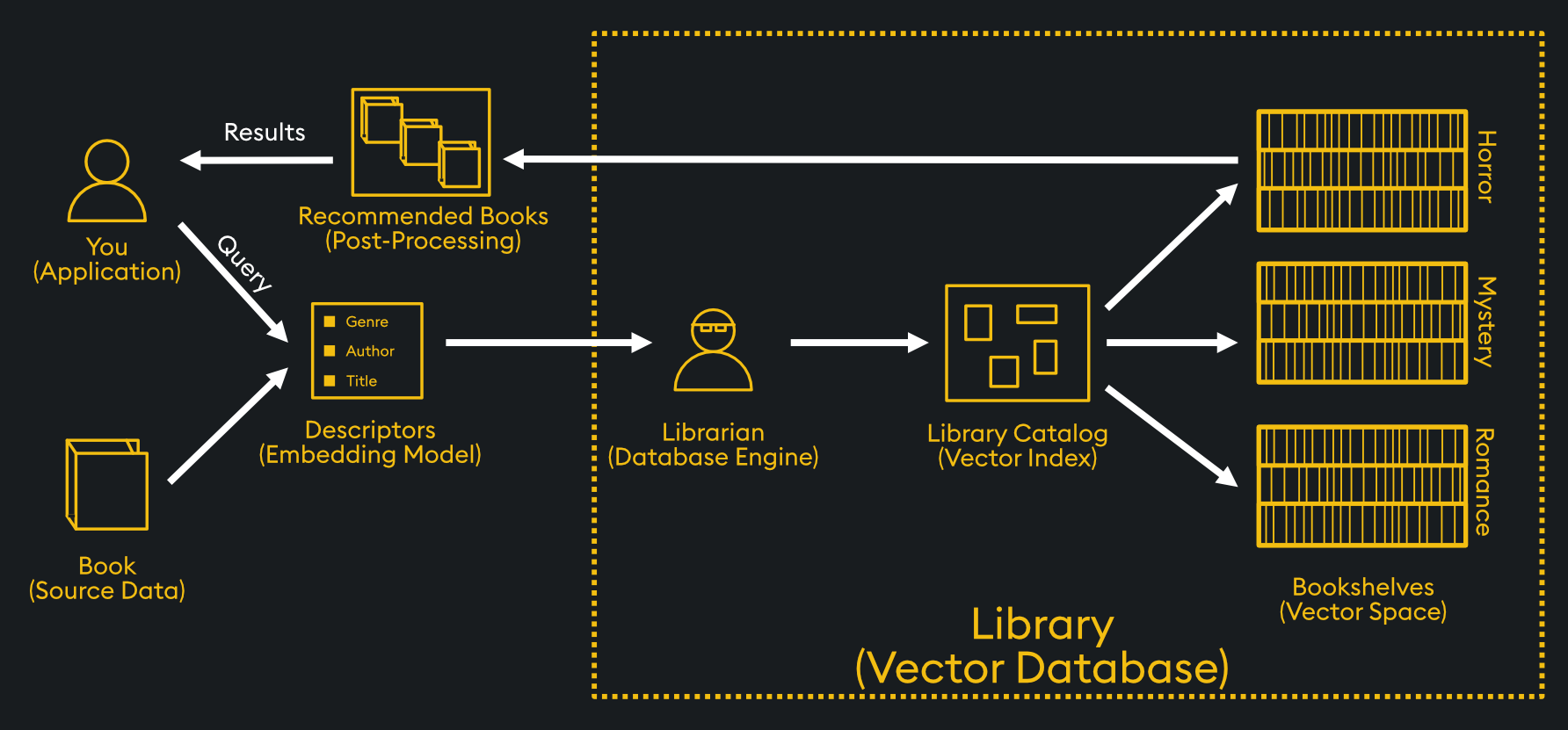
性能和擴展性
- 關系數據庫:對于結構化數據的快速讀寫和事務處理進行了優化,但在處理非常大規模的數據集時可能會遇到性能瓶頸。
- 向量數據庫:特別為高效處理高維向量數據集而設計,能夠很好地支持水平擴展,并且在處理大規模數據時仍能保持較高的查詢效率。
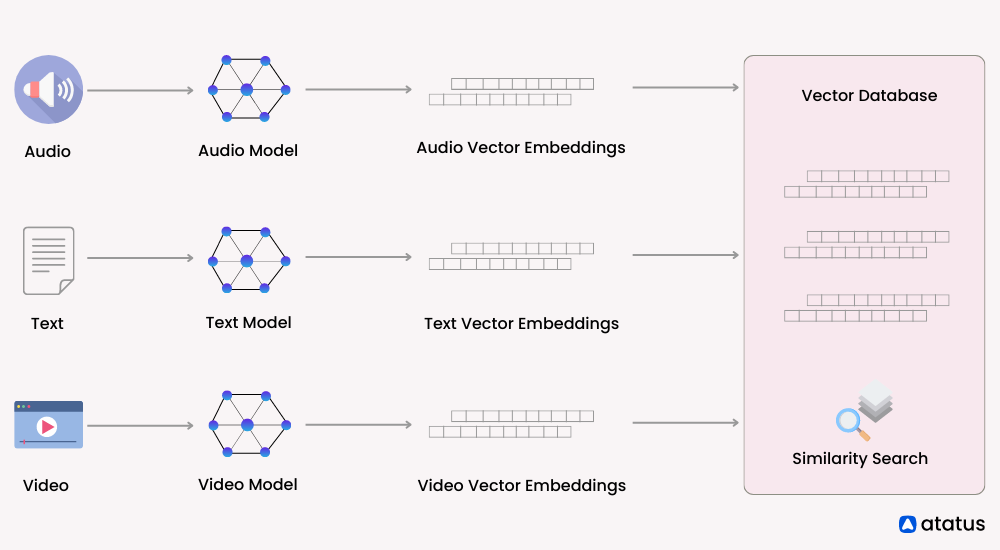
總之,選擇使用哪種類型的數據庫取決于具體的應用需求。如果您的應用場景涉及大量的非結構化數據并且需要執行高效的相似度搜索,那么向量數據庫可能是更好的選擇;反之,對于結構化數據和需要嚴格事務支持的應用,則可能更適合采用關系數據庫。
丟失MFA的解決方案)

)


)




 如何配置? Spring Boot 是如何自動配置常見視圖解析器的?)








