
【作者主頁】Francek Chen
【專欄介紹】 ? ? ?PyTorch深度學習 ? ? ? 深度學習 (DL, Deep Learning) 特指基于深層神經網絡模型和方法的機器學習。它是在統計機器學習、人工神經網絡等算法模型基礎上,結合當代大數據和大算力的發展而發展出來的。深度學習最重要的技術特征是具有自動提取特征的能力。神經網絡算法、算力和數據是開展深度學習的三要素。深度學習在計算機視覺、自然語言處理、多模態數據分析、科學探索等領域都取得了很多成果。本專欄介紹基于PyTorch的深度學習算法實現。
【GitCode】專欄資源保存在我的GitCode倉庫:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目錄
- 一、模型
- 二、定義注意力解碼器
- 三、訓練
- 小結
??序列到序列學習(seq2seq)中探討了機器翻譯問題:通過設計一個基于兩個循環神經網絡的編碼器-解碼器架構,用于序列到序列學習。具體來說,循環神經網絡編碼器將長度可變的序列轉換為固定形狀的上下文變量,然后循環神經網絡解碼器根據生成的詞元和上下文變量按詞元生成輸出(目標)序列詞元。然而,即使并非所有輸入(源)詞元都對解碼某個詞元都有用,在每個解碼步驟中仍使用編碼相同的上下文變量。有什么方法能改變上下文變量呢?
??我們試著找到靈感:在為給定文本序列生成手寫的挑戰中,Graves設計了一種可微注意力模型,將文本字符與更長的筆跡對齊,其中對齊方式僅向一個方向移動。受學習對齊想法的啟發,Bahdanau等人提出了一個沒有嚴格單向對齊限制的可微注意力模型。在預測詞元時,如果不是所有輸入詞元都相關,模型將僅對齊(或參與)輸入序列中與當前預測相關的部分。這是通過將上下文變量視為注意力集中的輸出來實現的。
一、模型
??下面描述的Bahdanau注意力模型將遵循序列到序列學習(seq2seq)中的相同符號表達。這個新的基于注意力的模型與序列到序列學習(seq2seq)中的模型相同,只不過其中式(3)中的上下文變量 c \mathbf{c} c在任何解碼時間步 t ′ t' t′都會被 c t ′ \mathbf{c}_{t'} ct′?替換。假設輸入序列中有 T T T個詞元,解碼時間步 t ′ t' t′的上下文變量是注意力集中的輸出:
c t ′ = ∑ t = 1 T α ( s t ′ ? 1 , h t ) h t (1) \mathbf{c}_{t'} = \sum_{t=1}^T \alpha(\mathbf{s}_{t' - 1}, \mathbf{h}_t) \mathbf{h}_t \tag{1} ct′?=t=1∑T?α(st′?1?,ht?)ht?(1) 其中,時間步 t ′ ? 1 t' - 1 t′?1時的解碼器隱狀態 s t ′ ? 1 \mathbf{s}_{t' - 1} st′?1?是查詢,編碼器隱狀態 h t \mathbf{h}_t ht?既是鍵,也是值,注意力權重 α \alpha α是使用加性注意力打分函數計算的。
??與循環神經網絡編碼器-解碼器架構略有不同,圖1描述了Bahdanau注意力的架構。

import torch
from torch import nn
from d2l import torch as d2l
二、定義注意力解碼器
??下面看看如何定義Bahdanau注意力,實現循環神經網絡編碼器-解碼器。其實,我們只需重新定義解碼器即可。為了更方便地顯示學習的注意力權重,以下AttentionDecoder類定義了帶有注意力機制解碼器的基本接口。
#@save
class AttentionDecoder(d2l.Decoder):"""帶有注意力機制解碼器的基本接口"""def __init__(self, **kwargs):super(AttentionDecoder, self).__init__(**kwargs)@propertydef attention_weights(self):raise NotImplementedError
??接下來,讓我們在接下來的Seq2SeqAttentionDecoder類中實現帶有Bahdanau注意力的循環神經網絡解碼器。首先,初始化解碼器的狀態,需要下面的輸入:
- 編碼器在所有時間步的最終層隱狀態,將作為注意力的鍵和值;
- 上一時間步的編碼器全層隱狀態,將作為初始化解碼器的隱狀態;
- 編碼器有效長度(排除在注意力池中填充詞元)。
??在每個解碼時間步驟中,解碼器上一個時間步的最終層隱狀態將用作查詢。因此,注意力輸出和輸入嵌入都連結為循環神經網絡解碼器的輸入。
class Seq2SeqAttentionDecoder(AttentionDecoder):def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)self.attention = d2l.AdditiveAttention(num_hiddens, num_hiddens, num_hiddens, dropout)self.embedding = nn.Embedding(vocab_size, embed_size)self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs, enc_valid_lens, *args):# outputs的形狀為(batch_size,num_steps,num_hiddens).# hidden_state的形狀為(num_layers,batch_size,num_hiddens)outputs, hidden_state = enc_outputsreturn (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)def forward(self, X, state):# enc_outputs的形狀為(batch_size,num_steps,num_hiddens).# hidden_state的形狀為(num_layers,batch_size,# num_hiddens)enc_outputs, hidden_state, enc_valid_lens = state# 輸出X的形狀為(num_steps,batch_size,embed_size)X = self.embedding(X).permute(1, 0, 2)outputs, self._attention_weights = [], []for x in X:# query的形狀為(batch_size,1,num_hiddens)query = torch.unsqueeze(hidden_state[-1], dim=1)# context的形狀為(batch_size,1,num_hiddens)context = self.attention(query, enc_outputs, enc_outputs, enc_valid_lens)# 在特征維度上連結x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)# 將x變形為(1,batch_size,embed_size+num_hiddens)out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)outputs.append(out)self._attention_weights.append(self.attention.attention_weights)# 全連接層變換后,outputs的形狀為# (num_steps,batch_size,vocab_size)outputs = self.dense(torch.cat(outputs, dim=0))return outputs.permute(1, 0, 2), [enc_outputs, hidden_state, enc_valid_lens]@propertydef attention_weights(self):return self._attention_weights
??接下來,使用包含7個時間步的4個序列輸入的小批量測試Bahdanau注意力解碼器。
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size,num_steps)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape
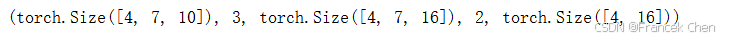
三、訓練
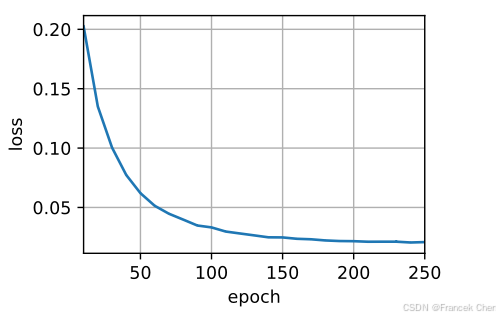
??與序列到序列學習(seq2seq)類似,我們在這里指定超參數,實例化一個帶有Bahdanau注意力的編碼器和解碼器,并對這個模型進行機器翻譯訓練。由于新增的注意力機制,訓練要序列到序列學習(seq2seq)比沒有注意力機制的慢得多。
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
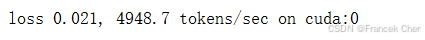
??模型訓練后,我們用它將幾個英語句子翻譯成法語并計算它們的BLEU分數。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq = d2l.predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device, True)print(f'{eng} => {translation}, ', f'bleu {d2l.bleu(translation, fra, k=2):.3f}')

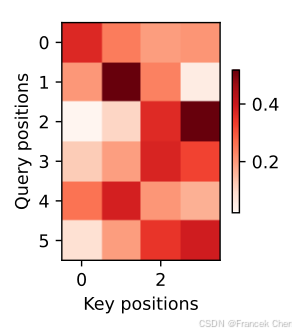
attention_weights = torch.cat([step[0][0][0] for step in dec_attention_weight_seq], 0).reshape((1, 1, -1, num_steps))
??訓練結束后,下面通過可視化注意力權重會發現,每個查詢都會在鍵值對上分配不同的權重,這說明在每個解碼步中,輸入序列的不同部分被選擇性地聚集在注意力池中。
# 加上一個包含序列結束詞元
d2l.show_heatmaps(attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(),xlabel='Key positions', ylabel='Query positions')
小結
- 在預測詞元時,如果不是所有輸入詞元都是相關的,那么具有Bahdanau注意力的循環神經網絡編碼器-解碼器會有選擇地統計輸入序列的不同部分。這是通過將上下文變量視為加性注意力池化的輸出來實現的。
- 在循環神經網絡編碼器-解碼器中,Bahdanau注意力將上一時間步的解碼器隱狀態視為查詢,在所有時間步的編碼器隱狀態同時視為鍵和值。









)


)





 尋路)
