目錄
- 奇異值分解(SVD)的輸入和輸出
- 奇異值的應用
- 實際案例
- 1. 問題分析
- 2. 解決方案:對測試集應用相同的變換
- 3. 為什么不能對測試集單獨做 SVD?
- 4. 代碼示例:訓練集和測試集的 SVD 降維
- 6. 實際操作中的注意事項
奇異值分解(SVD)的輸入和輸出
- 輸入:一個任意的矩陣 A A A,尺寸為 m × n m \times n m×n(其中 m m m 是行數, n n n 是列數,可以是矩形矩陣,不必是方陣)。
奇異值分解(SVD)得到的三個矩陣 U U U、 Σ \Sigma Σ 和 V T V^T VT 各有其特定的意義和用途,下面我簡要說明它們的作用:
-
U U U(左奇異向量矩陣):
- 是一個 m × m m \times m m×m 的正交矩陣,列向量是矩陣 A A T A A^T AAT 的特征向量。
- 作用:表示原始矩陣 A A A 在行空間(樣本空間)中的主方向或基向量。簡單來說, U U U 的列向量描述了數據在行維度上的“模式”或“結構”。
- 應用:在降維中, U U U 的前幾列可以用來投影數據到低維空間,保留主要信息(如在圖像處理中提取主要特征)。
-
Σ \Sigma Σ(奇異值矩陣):
- 是一個 m × n m \times n m×n 的對角矩陣,對角線上的值是奇異值(singular values),按降序排列,非負。
- 作用:奇異值表示原始矩陣 A A A 在每個主方向上的“重要性”或“能量”。較大的奇異值對應更重要的特征,較小的奇異值對應噪聲或次要信息。
- 應用:通過選擇前 k k k 個較大的奇異值,可以實現降維,丟棄不重要的信息(如數據壓縮、去噪)。
-
V T V^T VT(右奇異向量矩陣的轉置):
- 是 V V V 的轉置, V V V 是一個 n × n n \times n n×n 的正交矩陣,列向量是矩陣 A T A A^T A ATA 的特征向量。
- 作用:表示原始矩陣 A A A 在列空間(特征空間)中的主方向或基向量。簡單來說, V V V 的列向量描述了數據在列維度上的“模式”或“結構”。
- 應用:類似 U U U, V V V 的前幾列可以用來投影數據到低維空間,提取主要特征。
整體作用:
- 結合起來, A = U Σ V T A = U \Sigma V^T A=UΣVT 意味著原始矩陣 A A A 可以被分解為一系列主方向( U U U 和 V V V)和對應的權重( Σ \Sigma Σ)的組合。這種分解揭示了數據的內在結構。
- 主要應用:
- 降維:通過保留前 k k k 個奇異值及其對應的 U U U 和 V V V 的列向量,可以近似重建 A A A,減少數據維度(如 PCA 的基礎)。
- 數據壓縮:如圖像壓縮,丟棄小的奇異值以減少存儲空間。
- 去噪:小的奇異值往往對應噪聲,丟棄它們可以提高數據質量。
- 推薦系統:如矩陣分解,用于預測用戶評分矩陣中的缺失值。
簡單來說, U U U、 Σ \Sigma Σ 和 V T V^T VT 提供了數據的核心結構信息,幫助我們在保留主要信息的同時簡化數據處理。
- 輸出:SVD 將矩陣 A A A 分解為三個矩陣的乘積形式,即 A = U Σ V T A = U \Sigma V^T A=UΣVT,其中:
- U U U:一個 m × m m \times m m×m 的正交矩陣,列向量是 A A T A A^T AAT 的特征向量,稱為左奇異向量矩陣。
- Σ \Sigma Σ:一個 m × n m \times n m×n 的對角矩陣,對角線上的元素是非負的奇異值(singular values),通常按降序排列,表示 A A A 的“重要性”或“能量”。
- V T V^T VT:一個 n × n n \times n n×n 的正交矩陣的轉置, V V V 的列向量是 A T A A^T A ATA 的特征向量,稱為右奇異向量矩陣。
奇異值的應用
奇異值分解(SVD)后,原始矩陣 A A A 被分解為 A = U Σ V T A = U \Sigma V^T A=UΣVT,這種分解是等價的,意味著通過 U U U、 Σ \Sigma Σ 和 V T V^T VT 的乘積可以完全重構原始矩陣 A A A,沒有任何信息損失。
但在實際應用中,我們通常不需要保留所有的奇異值和對應的向量,而是可以通過篩選規則選擇排序靠前的奇異值及其對應的向量來實現降維或數據壓縮。以下是這個過程的核心思想:
-
奇異值的排序:
- 在 Σ \Sigma Σ 矩陣中,奇異值(對角線上的值)是按降序排列的。靠前的奇異值通常較大,代表了數據中最重要的信息或主要變化方向;靠后的奇異值較小,代表次要信息或噪聲。
- 奇異值的大小反映了對應向量對原始矩陣 A A A 的貢獻程度。
-
篩選規則:
- 我們可以根據需求選擇保留前 k k k 個奇異值( k k k 是一個小于原始矩陣秩的數),并丟棄剩余的較小奇異值。
- 常見的篩選規則包括:
- 固定數量:直接選擇前 k k k 個奇異值(例如,前 10 個)。
- 累計方差貢獻率:計算奇異值的平方(代表方差),選擇累計方差貢獻率達到某個閾值(如 95%)的前 k k k 個奇異值。
- 奇異值下降幅度:觀察奇異值下降的“拐點”,在下降明顯變緩的地方截斷。
-
降維與近似:
- 保留前 k k k 個奇異值后,我們只取 U U U 矩陣的前 k k k 列(記為 U k U_k Uk?,尺寸為 m × k m \times k m×k)、 Σ \Sigma Σ 矩陣的前 k k k 個奇異值(記為 Σ k \Sigma_k Σk?,尺寸為 k × k k \times k k×k)、以及 V T V^T VT 矩陣的前 k k k 行(記為 V k T V_k^T VkT?,尺寸為 k × n k \times n k×n)。
- 近似矩陣為 A k = U k Σ k V k T A_k = U_k \Sigma_k V_k^T Ak?=Uk?Σk?VkT?,這個矩陣是原始矩陣 A A A 的低秩近似,保留了主要信息,丟棄了次要信息或噪聲。
- 這種方法在降維(如主成分分析 PCA)、圖像壓縮、推薦系統等領域非常常用。
-
對應的向量:
- U U U 的列向量和 V V V 的列向量分別對應左右奇異向量。保留前 k k k 個奇異值時, U k U_k Uk? 的列向量代表數據在行空間中的主要方向, V k V_k Vk? 的列向量代表數據在列空間中的主要方向。
- 這些向量與奇異值一起,構成了數據的主要“模式”或“結構”。
總結:SVD 分解后原始矩陣是等價的,但通過篩選排序靠前的奇異值和對應的向量,我們可以實現降維,保留數據的主要信息,同時減少計算量和噪聲影響。這種方法是許多降維算法(如 PCA)和數據處理技術的基礎。
實際案例
在機器學習中,如果對訓練集進行 SVD 降維后訓練模型,而測試集的特征數量與降維后的訓練集不一致(測試集仍保持原始特征數量),該如何處理?
1. 問題分析
- 訓練集降維:假設訓練集有 1000 個樣本,50 個特征,通過 SVD 降維后保留 k = 10 k=10 k=10 個特征,得到形狀為
(1000, 10)的新數據。模型基于這 10 個特征進行訓練。 - 測試集問題:測試集假設有 200 個樣本,仍然是 50 個特征。如果直接輸入測試集到模型中,特征數量不匹配(模型期望 10 個特征,測試集有 50 個),會導致錯誤。
- 核心問題:如何確保測試集也能被正確地降維到與訓練集相同的 k k k 個特征空間?
2. 解決方案:對測試集應用相同的變換
在機器學習中,降維(如 SVD、PCA 等)是一種數據預處理步驟。訓練集和測試集必須經過相同的變換,以確保數據分布一致。具體到 SVD,步驟如下:
- 訓練階段:對訓練集 X t r a i n X_{train} Xtrain? 進行 SVD 分解,得到 U U U, Σ \Sigma Σ, 和 V T V^T VT,并保存 V T V^T VT 矩陣(或其前 k k k 行)用于降維變換。
- 測試階段:使用從訓練集得到的 V T V^T VT 矩陣,將測試集 X t e s t X_{test} Xtest? 投影到相同的低維空間,得到降維后的測試數據。
- 原因: V T V^T VT 矩陣定義了從原始特征空間到低維特征空間的映射關系,測試集必須使用相同的映射以保持一致性。
數學上,假設訓練集 SVD 分解為 X t r a i n = U Σ V T X_{train} = U \Sigma V^T Xtrain?=UΣVT,我們保留前 k k k 個奇異值對應的 V k T V_k^T VkT?(形狀為 k × 50 k \times 50 k×50)。測試集降維公式為:
X t e s t _ r e d u c e d = X t e s t ? V k T . T X_{test\_reduced} = X_{test} \cdot V_k^T.T Xtest_reduced?=Xtest??VkT?.T
其中 V k T . T V_k^T.T VkT?.T 是 V k T V_k^T VkT? 的轉置(形狀為 50 × k 50 \times k 50×k), X t e s t X_{test} Xtest? 是形狀為 (n_test, 50) 的測試集矩陣,降維后 X t e s t _ r e d u c e d X_{test\_reduced} Xtest_reduced? 的形狀為 (n_test, k)。
3. 為什么不能對測試集單獨做 SVD?
- 如果對測試集單獨進行 SVD,會得到不同的 V T V^T VT 矩陣,導致測試集和訓練集的低維空間不一致,模型無法正確處理測試數據。
- 訓練集的 V T V^T VT 矩陣代表了訓練數據的特征映射規則,測試集必須遵循相同的規則,否則會引入數據泄漏或不一致性問題。
4. 代碼示例:訓練集和測試集的 SVD 降維
以下是一個完整的代碼示例,展示如何對訓練集進行 SVD 降維,訓練模型,并對測試集應用相同的降維變換。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 設置隨機種子以便結果可重復
np.random.seed(42)# 模擬數據:1000 個樣本,50 個特征
n_samples = 1000
n_features = 50
X = np.random.randn(n_samples, n_features) * 10 # 隨機生成特征數據
y = (X[:, 0] + X[:, 1] > 0).astype(int) # 模擬二分類標簽# 劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
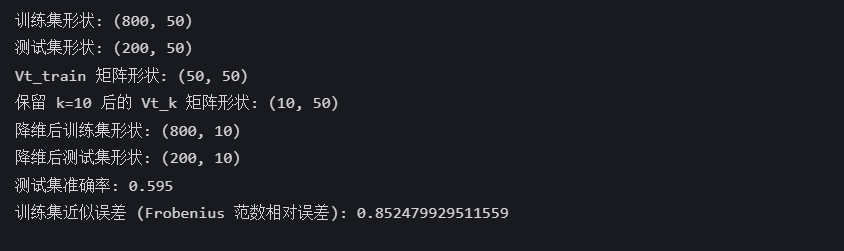
print(f"訓練集形狀: {X_train.shape}")
print(f"測試集形狀: {X_test.shape}")# 對訓練集進行 SVD 分解
U_train, sigma_train, Vt_train = np.linalg.svd(X_train, full_matrices=False)
print(f"Vt_train 矩陣形狀: {Vt_train.shape}")# 選擇保留的奇異值數量 k
k = 10
Vt_k = Vt_train[:k, :] # 保留前 k 行,形狀為 (k, 50)
print(f"保留 k={k} 后的 Vt_k 矩陣形狀: {Vt_k.shape}")# 降維訓練集:X_train_reduced = X_train @ Vt_k.T
X_train_reduced = X_train @ Vt_k.T
print(f"降維后訓練集形狀: {X_train_reduced.shape}")# 使用相同的 Vt_k 對測試集進行降維:X_test_reduced = X_test @ Vt_k.T
X_test_reduced = X_test @ Vt_k.T
print(f"降維后測試集形狀: {X_test_reduced.shape}")# 訓練模型(以邏輯回歸為例)
model = LogisticRegression(random_state=42)
model.fit(X_train_reduced, y_train)# 預測并評估
y_pred = model.predict(X_test_reduced)
accuracy = accuracy_score(y_test, y_pred)
print(f"測試集準確率: {accuracy}")# 計算訓練集的近似誤差(可選,僅用于評估降維效果)
X_train_approx = U_train[:, :k] @ np.diag(sigma_train[:k]) @ Vt_k
error = np.linalg.norm(X_train - X_train_approx, 'fro') / np.linalg.norm(X_train, 'fro')
print(f"訓練集近似誤差 (Frobenius 范數相對誤差): {error}")
6. 實際操作中的注意事項
-
標準化數據:在進行 SVD 之前,通常需要對數據進行標準化(均值為 0,方差為 1),以避免某些特征的量綱差異對降維結果的影響。可以使用
sklearn.preprocessing.StandardScaler。from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)注意:
scaler必須在訓練集上fit,然后對測試集只用transform,以避免數據泄漏。 -
選擇合適的 k k k:可以通過累計方差貢獻率(explained variance ratio)選擇 k k k,通常選擇解釋 90%-95% 方差的 k k k 值。代碼中可以計算:
explained_variance_ratio = np.cumsum(sigma_train**2) / np.sum(sigma_train**2) print(f"前 {k} 個奇異值的累計方差貢獻率: {explained_variance_ratio[k-1]}") -
使用 sklearn 的 TruncatedSVD:
sklearn提供了TruncatedSVD類,專門用于高效降維,尤其適合大規模數據。它直接計算前 k k k 個奇異值和向量,避免完整 SVD 的計算開銷。from sklearn.decomposition import TruncatedSVD svd = TruncatedSVD(n_components=k, random_state=42) X_train_reduced = svd.fit_transform(X_train) X_test_reduced = svd.transform(X_test) print(f"累計方差貢獻率: {sum(svd.explained_variance_ratio_)}")
@浙大疏錦行

![[vue]error:0308010C:digital envelope routines::unsupported](http://pic.xiahunao.cn/[vue]error:0308010C:digital envelope routines::unsupported)


![[python] 函數3-python內置函數](http://pic.xiahunao.cn/[python] 函數3-python內置函數)






![[250509] x-cmd 發布 v0.5.11 beta:x ping 優化、AI 模型新增支持和語言變量調整](http://pic.xiahunao.cn/[250509] x-cmd 發布 v0.5.11 beta:x ping 優化、AI 模型新增支持和語言變量調整)

)





