Redis分片(Sharding)是解決單機性能瓶頸的核心技術,其本質是將數據分散存儲到多個Redis節點(實例)中,每個實例將只是所有鍵的一個子集,通過水平擴展提升系統容量和性能。
分片的核心價值
-
性能提升:
存儲擴展:突破單機內存限制,支持TB級數據存儲。
計算并行化:多節點同時處理請求,提高吞吐量(如電商大促場景下,分片集群可承載百萬級QPS)。 -
高可用性:
故障隔離:單節點故障僅影響其管理的槽,其他節點正常服務。
主從復制:每個主節點可配置從節點,主節點宕機時從節點自動接管槽。 -
資源優化:
冷熱數據分離:高頻訪問數據可分配至SSD節點,低頻數據存機械硬盤,降低成本。
負載均衡:哈希槽機制確保數據均勻分布,避免“熱點”問題。
分片的實現方式
按照分片的計算邏輯由誰來執行,可以分為以下幾種實現方式:
-
客戶端分片:由客戶端直接計算鍵的槽編號,并連接對應節點。例如,使用一致性哈希算法或直接取模分配節點。
- 優點:實現簡單,無需中間代理。
- 缺點:節點變更時需手動調整客戶端邏輯,運維復雜度高。
-
代理分片:通過中間代理(如Twemproxy)轉發請求,客戶端不感知節點信息。代理根據分片規則將請求路由到目標節點。
- 優點:客戶端無需關心分片細節。
- 缺點:代理層可能成為性能瓶頸。
-
服務端分片(Redis Cluster):Redis官方集群模式,節點間通過Gossip協議同步槽分配信息。客戶端可連接任意節點,若請求的鍵不屬于當前節點,服務端會返回重定向指令。
- 特點:支持自動故障轉移、數據遷移,是生產環境首選方案。
查詢路由:可發送你的查詢到一個隨機實例,該實例會保證轉發你的查詢到正確節點。
Redis集群在客戶端的幫助下,實現了查詢路由的一種混合形式,請求不是直接從Redis實例轉發到另一個,而是客戶端收到重定向到正確的節點。
分片的算法
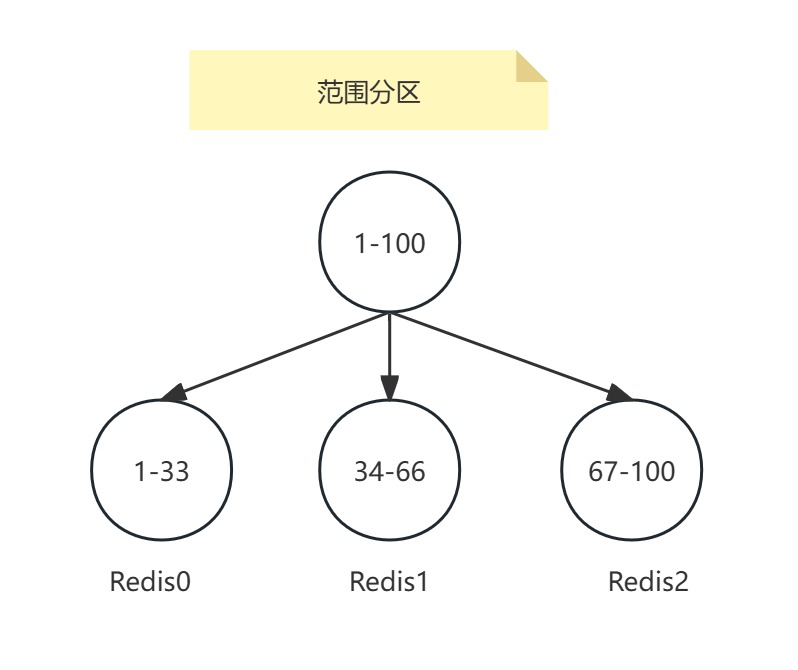
范圍分區
范圍分區也叫順序分區,最簡單的分區方式。通過映射對象的范圍到指定的Redis實例來完成分片。
假設用戶ID的范圍為1100,從133進入實例Redis1,3466進入Redis2,67100進入Redis3。
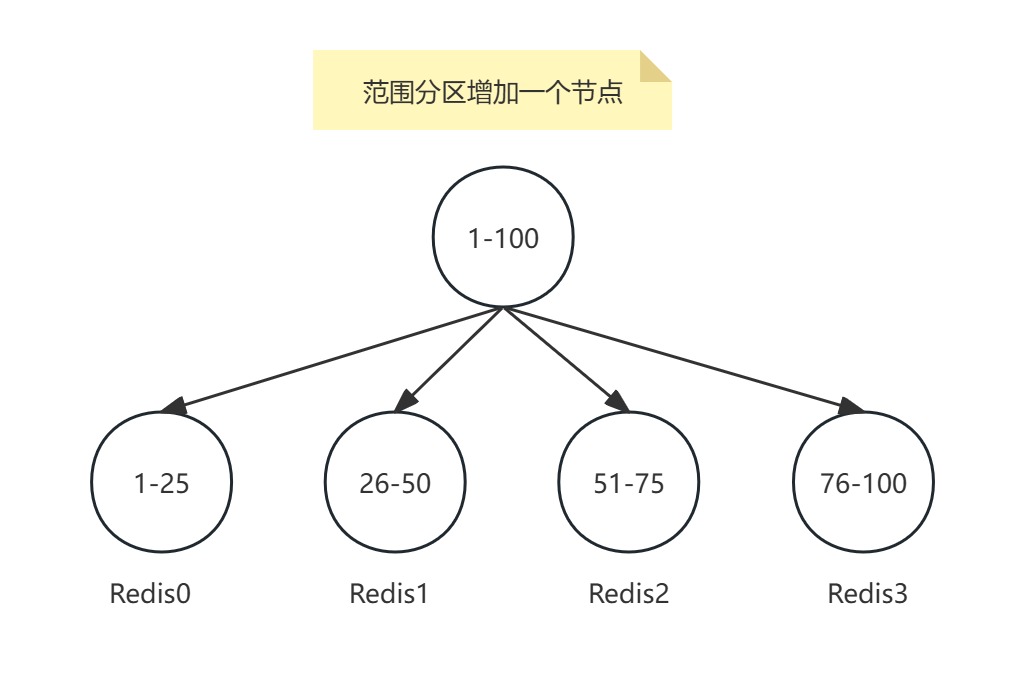
范圍分區增加一個節點需要遷移大部分數據:
優點:
- 支持高效的范圍查詢:同一范圍分區內的范圍查詢不需要跨節點,提升查詢速度。
- 支持批量操作:支持同一范圍分區內的批量操作如事務、pipeline、lua腳本等
- 實現簡單直觀:分區規則邏輯清晰,開發人員易于理解和維護。
缺點:
- 數據分散度易傾斜:若分區鍵范圍設計不合理,可能導致部分分區數據量過大
- 分區鍵選擇受限:范圍分區要求分區鍵為數值型或可排序字段(如時間、ID)
- 維護范圍映射表:需額外存儲和管理分區范圍與節點的映射關系,增加系統復雜性
- 數據遷移成本:調整分區范圍時,需遷移大部分數據
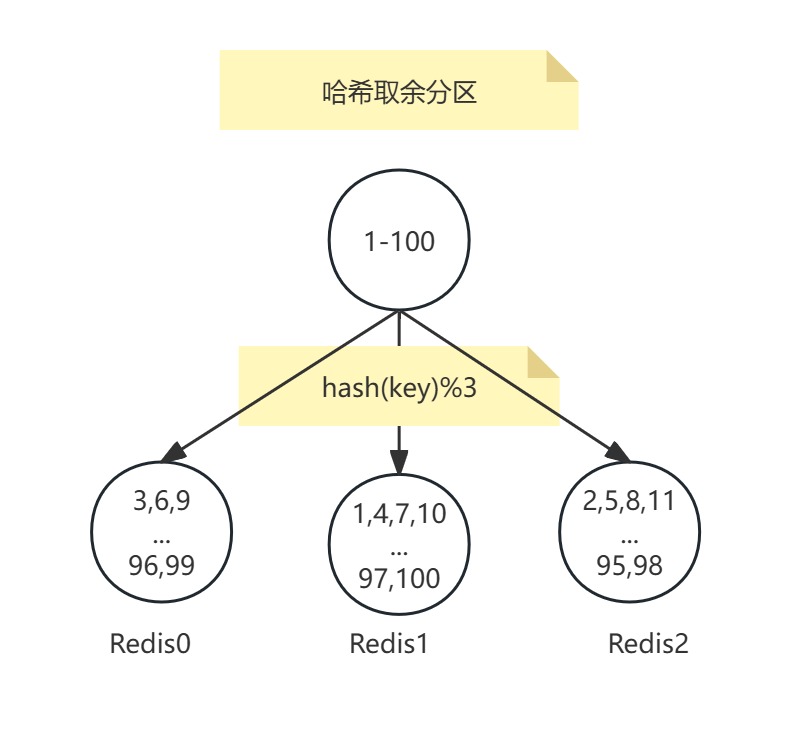
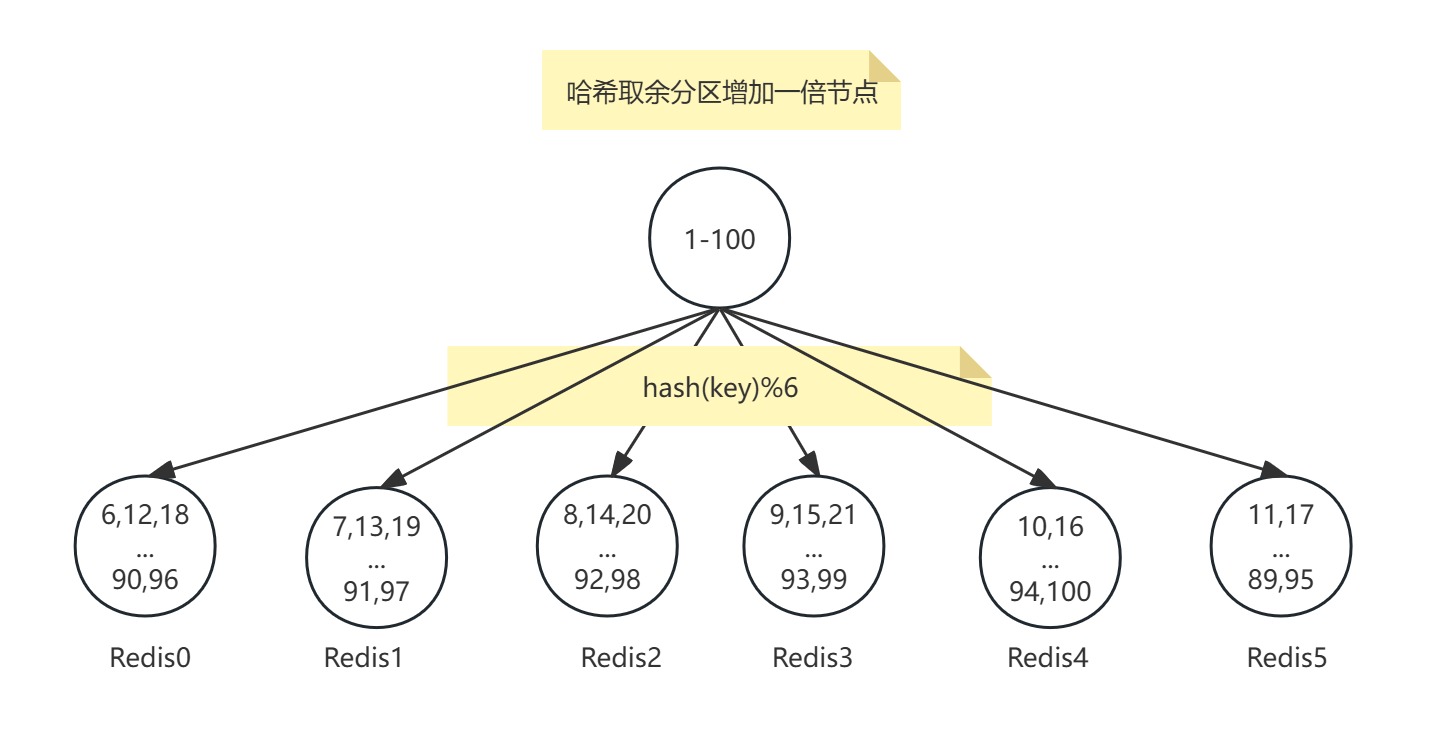
哈希取余分區
哈希取余分區是分布式緩存中常用的數據分片策略,其核心原理是通過哈希函數和取模運算將數據均勻分布到多個節點。
對每個鍵(Key)使用哈希函數(如CRC16、MD5)計算哈希值,再對Redis節點總數取余,公式為:
目標節點 = hash(key) % 節點數量
例如,3個節點的集群中,鍵user:100的哈希值為93024922,則93024922 % 3 = 1,該鍵會被分配到第2個節點(編號從 0開始)。
添加一個節點:
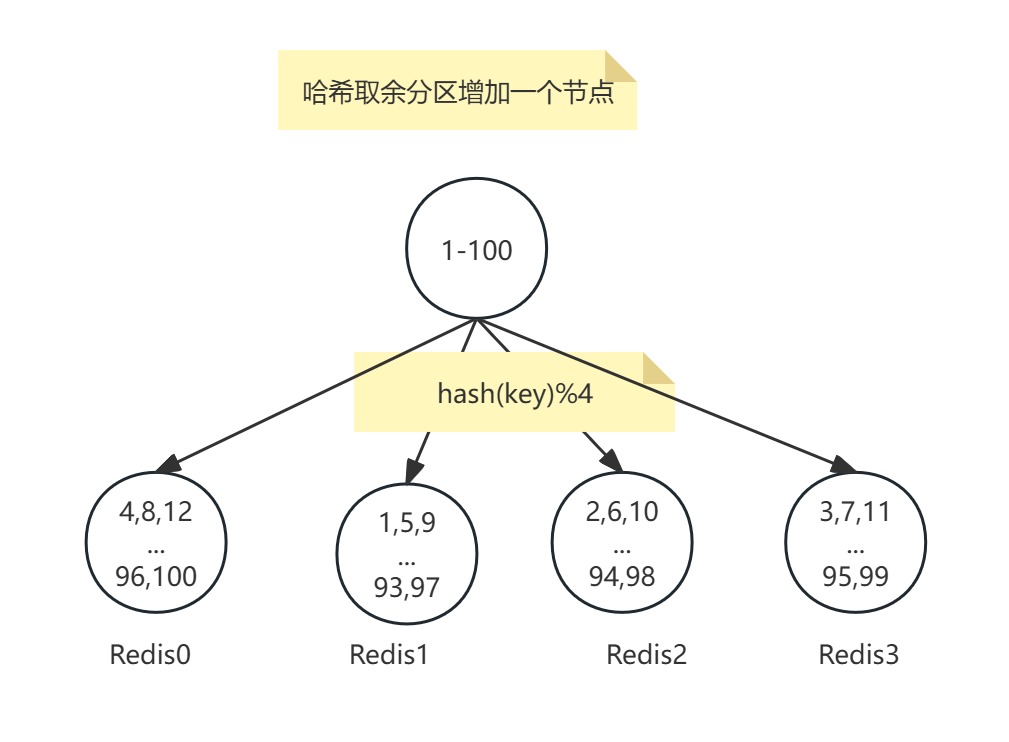
翻倍擴容
優點:
- 實現簡單高效:僅需哈希函數和取模運算即可完成數據分布,適合快速搭建小型分布式系統。
- 負載均衡:數據均勻分布到所有節點,每個節點處理固定比例的請求,避免單點過載。
缺點:擴容/縮容成本高,節點數量變化時,取模分母改變,導致所有數據需重新計算映射關系并遷移,引發全量數據洗牌。從 3節點擴容至4節點時,hash(key) % 3變為hash(key) % 4,75%的數據需遷移。雖然翻倍擴容可以相對減少遷移量,但是翻倍所需的成本太大。
一致性哈希分區
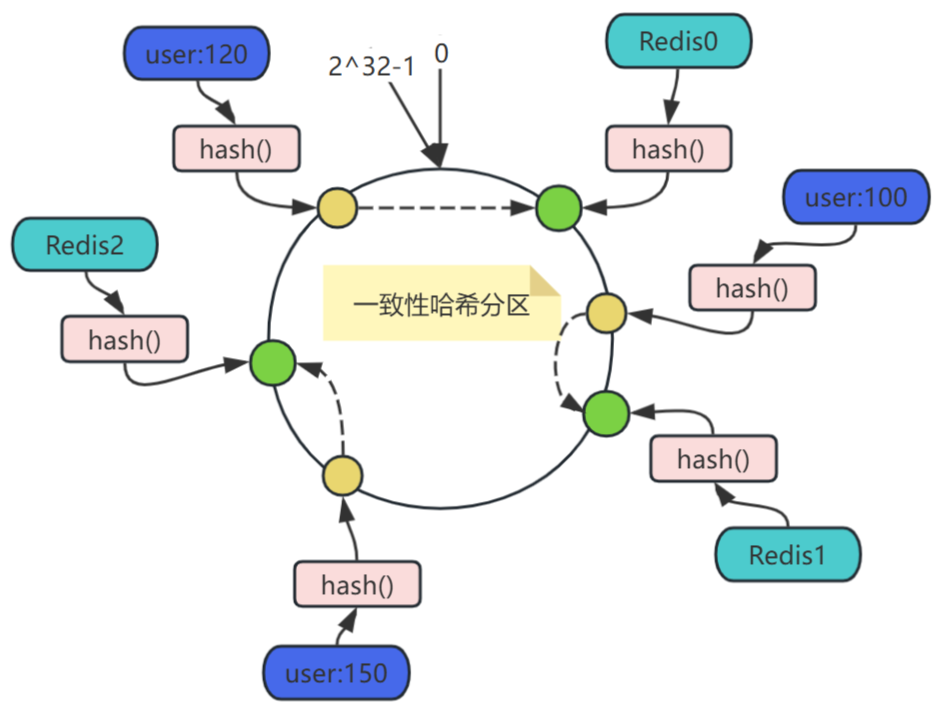
一致性哈希分區是一種用于分布式系統的數據分片技術,旨在解決節點動態變化時數據遷移開銷大的問題。
設計如下:
-
設計哈希函數Hash(key),要求取值范圍為
[0, 2^32-1],將這個取值范圍的數字頭尾相連,想象成一個閉合環形,各哈希值在Hash環上的分布:時鐘12點位置為0,按順時針方向遞增,臨近12點的左側位置為2^32-1。 -
將Redis節點映射至哈希環,如圖哈希環上的綠球所示,三個節點Redis0、Redis1、Redis2,可以通過其IP地址或機器名,經過同一個Hash函數計算的結果,映射到哈希環上。
-
將key映射于哈希環,如圖哈希環上的黃球所示,三個key
user:100、user:120、user:150經過同一個Hash()計算的結果,映射到哈希環上。 -
將key映射至Redis節點,在對象和節點都映射至同一個哈希環之后,要確定某個對象映射至哪個節點,只需從該對象開始,沿著哈希環順時針方向查找,找到的第一個節點,即是。
增加節點:服務器擴容時增加節點,比如要在Redis1和Redis2之間增加節點Redis3,只會影響欲新增節點Redis3與上一個(順時針為前進方向)節點Redis1之間的對象,也就是user:300,這些對象的映射關系,按照上面的規則,調整映射至新增的節點Redis3,其他對象的映射關系,都無需調整。
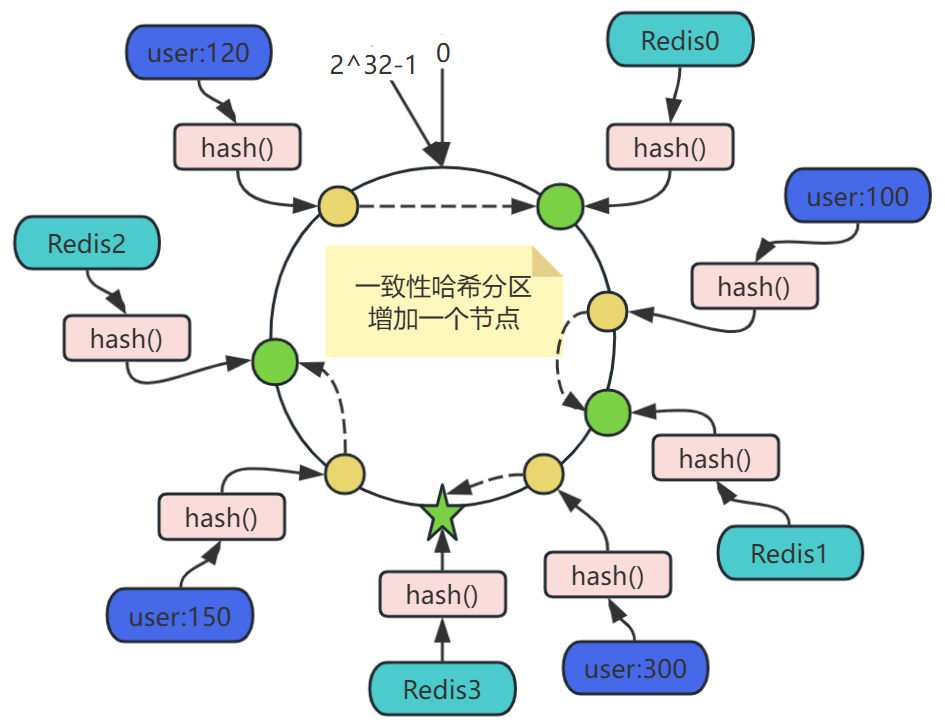
優點:
- 動態擴展友好:增減節點僅影響相鄰節點,遷移量減少至約1/N(N為節點數)。
缺點:
- 數據傾斜風險:節點較少時分布不均。
- 數據丟失風險:欲新增節點與上一個節點之間的數據不可命中,丟失
虛擬一致性哈希分區
對于前面的方案,節點數越少,越容易出現節點在哈希環上的分布不均勻,導致各節點映射的對象數量嚴重不均衡(數據傾斜);相反,節點數越多越密集,數據在哈希環上的分布就越均勻。
但實際部署的物理節點有限,我們可以用有限的物理節點,虛擬出足夠多的虛擬節點(Virtual Node),最終達到數據在哈希環上均勻分布的效果,如下圖,實際只部署了3個節點Redis0、Redis1、Redis2,把每個節點都復制成2倍,結果看上去是部署了6個節點。
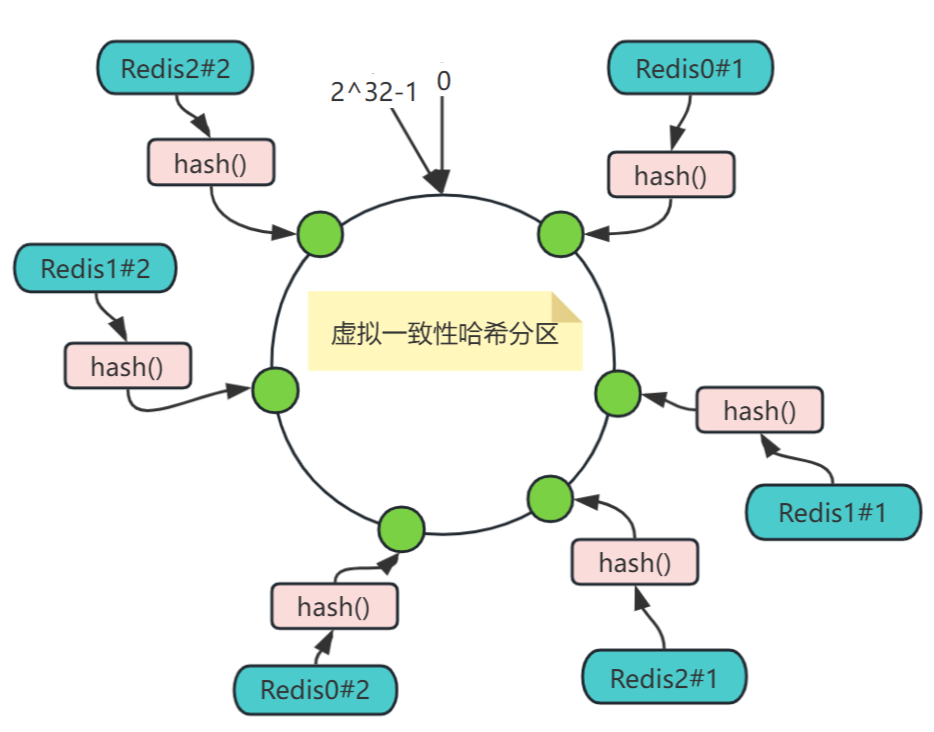
虛擬一致性哈希分區增加一個節點:
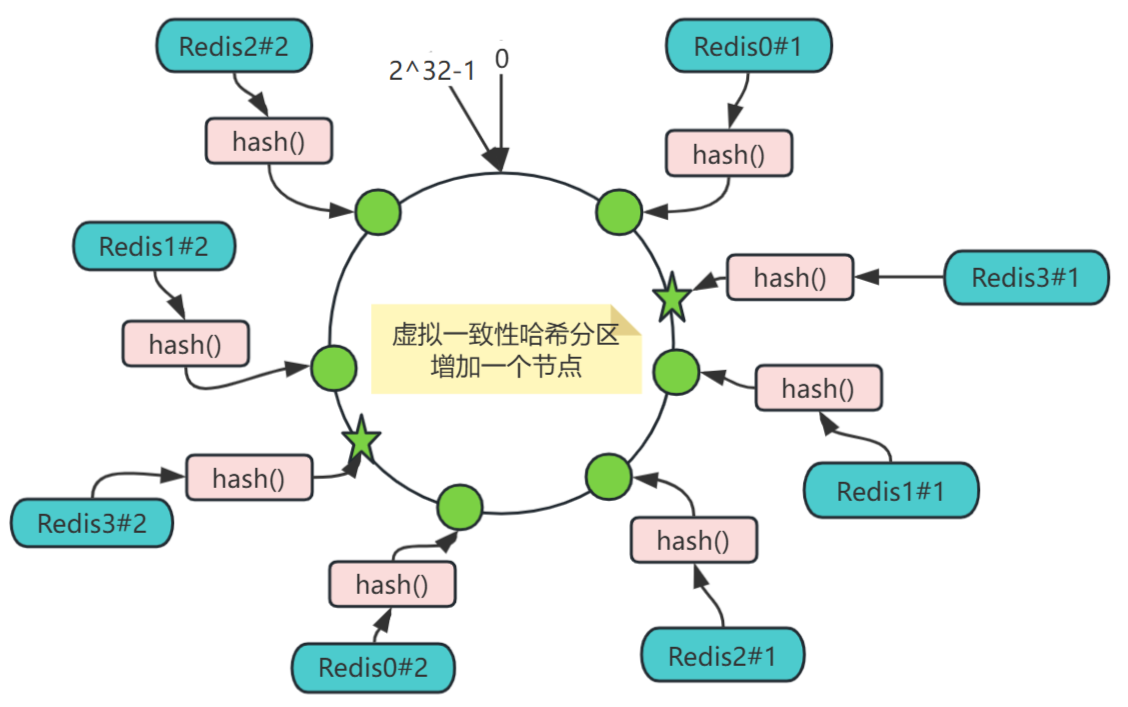
可以想象,當虛擬節點個數達到2^32時,就達到絕對的均勻,通常可取復制倍數為32或更高。
優點:
- 負載均衡優化:虛擬節點分散物理節點壓力,減少數據傾斜。
- 異構節點適配:根據節點性能差異分配不同數量的虛擬節點。
缺點:
- 管理復雜度高:需維護虛擬節點與物理節點的映射關系。
- 遷移成本上升:節點變動需調整多個虛擬節點,操作復雜。
虛擬槽分區(Redis Cluster方案)
虛擬槽分區(Virtual Slot Partitioning)是Redis Cluster設計的核心分片機制,旨在解決分布式系統中數據分片、負載均衡和高可用性問題。其核心思想是將整個數據空間劃分為固定數量的邏輯槽(Slot),通過動態分配槽到物理節點的方式實現數據分布。
虛擬槽分區是對一致性哈希分區進行的改造,虛擬槽中的槽就是大量的虛擬節點的抽象化,將原來的虛擬節點變成一個槽,槽的范圍是0~16383,redis內置是有16384個槽也就是有16384個虛擬節點。
虛擬槽分區巧妙地使用了哈希空間,使用分散度良好的哈希函數把所有數據映射到一個固定范圍的整數集合中,這個整數定義為槽(slot),這個范圍一般遠遠大于節點數。
假設當前集群有3個節點,每個節點平均大約負責5461個槽,所有的鍵根據哈希函數映射到0~16383整數槽內,計算公式:slot = CRC16(key)& 16383。每一個節點負責維護一部分槽以及槽所映射的鍵值數據,如下圖所示:
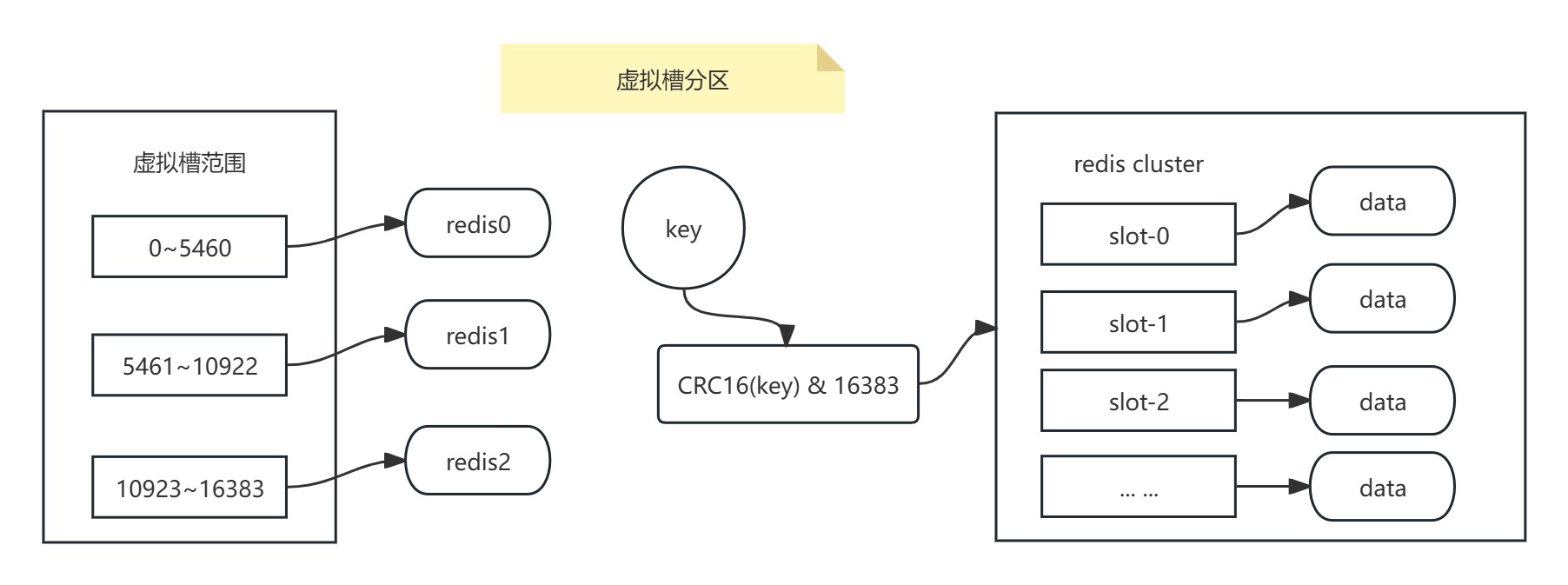
slot = CRC16(key)& 16383其實就是slot = CRC16(key)% 16384,一個數跟2^N取模的結果等于它與2^N-1按位與的結果。
在虛擬槽分區中擴展一個節點(擴容)時,需通過槽遷移將部分槽從現有節點轉移到新節點,實現數據重新分布和負載均衡。
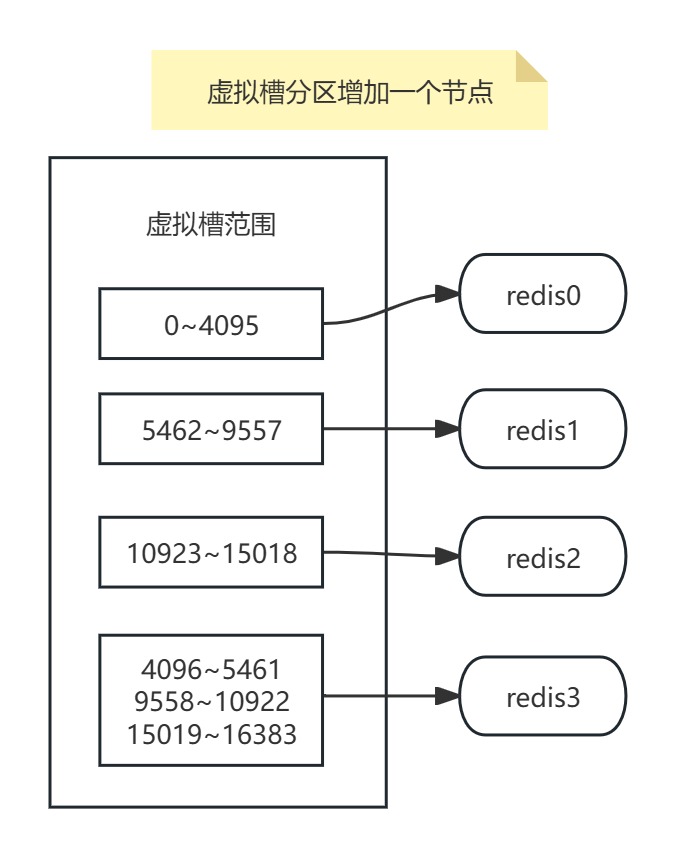
優點:
- 動態擴縮容平滑:僅遷移受影響槽的數據,遷移量可控(如刪除節點時僅重分配其槽)。當需要增加節點時,只需要把其他節點的某些哈希槽挪到新節點就可以了,當需要移除節點時,只需要把移除節點上的哈希槽挪到其他節點就行了。
- 解耦數據與節點之間的直接關系:槽作為中間層,支持靈活調整節點與槽的映射關系。一致性hash分片需要映射key和節點的關系, 但是使用hash槽計算方式是
CRC16(key) % 槽的個數, 所以就解耦了數據和節點的關系 - 節點自身維護槽的映射關系, 不需要客戶端和代理服務器進行維護處理
缺點:
- 實現復雜:需集群協議維護槽與節點狀態,客戶端需支持重定向邏輯。
- 功能限制:跨槽事務、多鍵操作受限。

![[250509] x-cmd 發布 v0.5.11 beta:x ping 優化、AI 模型新增支持和語言變量調整](http://pic.xiahunao.cn/[250509] x-cmd 發布 v0.5.11 beta:x ping 優化、AI 模型新增支持和語言變量調整)

)






)




)

】)
——qt的背景及安裝)
