無監督學習:讓機器從“混沌”中自我覺醒 ????

?? 摘要:無監督學習(Unsupervised Learning)是機器學習的重要分支,它不依賴于人工標簽,通過自身“感知”數據結構來發現潛在模式。本文系統梳理了其核心概念、典型算法、實際應用與代碼實戰,既適合入門學習,也適用于工程實踐與技術面試準備。
1?? 無監督學習是什么?沒有“答案”的學習也能開悟!
設想你剛進一家圖書館,看到一大堆沒有標簽的書籍——沒有作者分類、沒有題材標識。你會怎么辦?大多數人會根據封面、厚度、插圖和目錄,自行把這些書大致分為“小說”“工具書”“傳記”等類型。
這正是無監督學習的核心思想:不需要標簽,僅根據樣本間的結構關系,讓模型自我發現數據分布中的規律。
?? 無監督學習適用于無法獲取標注或人工標注成本過高的場景,是AI領域“自動發現知識”的關鍵支撐。
2?? 無監督 VS 監督學習:核心差異一圖看懂 ??
| 特征對比 | 監督學習(Supervised) | 無監督學習(Unsupervised) |
|---|---|---|
| 是否需標簽 | ? 需要 | ? 不需要 |
| 學習目標 | 學習 X ? Y 的映射關系 | 挖掘 X 內部的分布和結構 |
| 代表任務 | 分類(Classification)、回歸(Regression) | 聚類(Clustering)、降維(Dimensionality Reduction) |
| 示例應用 | 識別貓狗圖像、預測房價 | 客戶分群、異常檢測、推薦系統 |
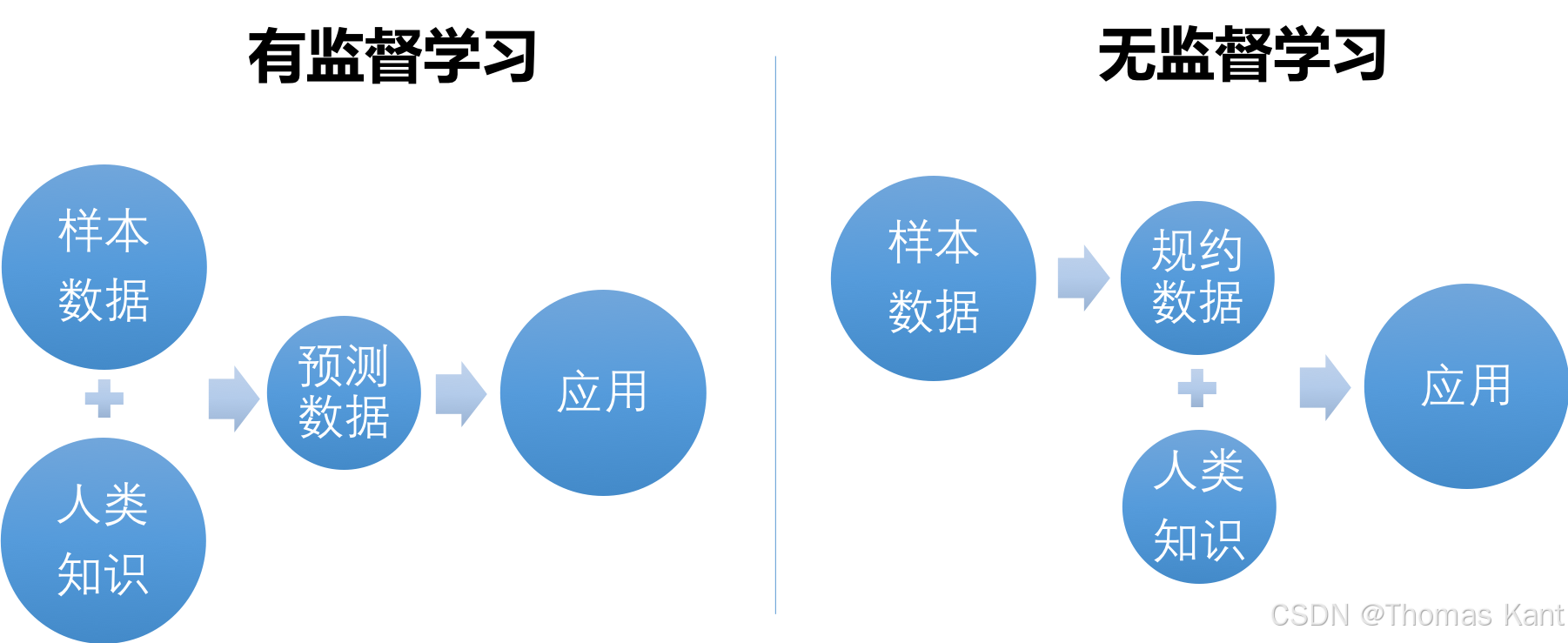
?? 簡而言之:監督學習是“有老師教你考試”,而無監督學習是“自己琢磨出題規律”。
3?? 無監督學習四大核心任務 ?
3.1 聚類(Clustering):物以類聚,人以群分 ??
?? 目標:將相似樣本自動劃分到同一類中。
? 代表算法:
- K-Means:基于中心點的迭代聚類,速度快,適用于結構清晰的數據集。
- DBSCAN:基于密度聚類,能識別任意形狀簇,抗




開發 python3基礎11: java 調用python waitfor卡死,導致深入理解操作系統進程模型和IPC機制)
學習筆記(九)--搭建多租戶系統)




)
Detail-Preserving Latent Diffusion for Stable Shadow Removal論文閱讀)


)




