論文鏈接:SAM 2: Segment Anything in Images and Videos
代碼鏈接:https://github.com/facebookresearch/sam2?tab=readme-ov-file
作者:Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R?dle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer
發表單位:Meta AI Research, FAIR
會議/期刊:Arxiv 2024年10月
相關系列:
【視覺基礎模型-SAM系列-1】Segment Anything-CSDN博客文章瀏覽閱讀335次,點贊6次,收藏13次。自然語言處理(NLP)領域的基礎模型(如GPT、BERT)通過海量文本訓練和prompt方式,展現出強大的零樣本、少樣本泛化能力。相比之下,計算機視覺領域中的基礎模型發展相對滯后,尤其在圖像分割任務中,尚缺乏類似“預訓練+提示”的通用方法。https://blog.csdn.net/cjy_colorful0806/article/details/147764385?fromshare=blogdetail&sharetype=blogdetail&sharerId=147764385&sharerefer=PC&sharesource=cjy_colorful0806&sharefrom=from_link
【視覺基礎模型-SAM系列-3】Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks-CSDN博客文章瀏覽閱讀4次。ICCV 2023【視覺基礎模型-SAM系列-1】Segment Anything-CSDN博客自然語言處理(NLP)領域的基礎模型(如GPT、BERT)通過海量文本訓練和prompt方式,展現出強大的零樣本、少樣本泛化能力。相比之下,計算機視覺領域中的基礎模型發展相對滯后,尤其在圖像分割任務中,尚缺乏類似“預訓練+提示”的通用方法。【視覺基礎模型-SAM系列-2】SAM2: Segment Anything in Images and Videos-CSDN博客。 https://blog.csdn.net/cjy_colorful0806/article/details/147774458?fromshare=blogdetail&sharetype=blogdetail&sharerId=147774458&sharerefer=PC&sharesource=cjy_colorful0806&sharefrom=from_link
https://blog.csdn.net/cjy_colorful0806/article/details/147774458?fromshare=blogdetail&sharetype=blogdetail&sharerId=147774458&sharerefer=PC&sharesource=cjy_colorful0806&sharefrom=from_link
一、研究背景
盡管前作SAM在圖像分割任務上有了很好的效果,但是仍然無法處理現實世界中大量存在的視頻數據。視頻分割面臨比圖像更復雜的問題,比如目標可能因運動、遮擋、形變、光照等不斷變化;視頻分辨率低、幀數多,處理成本高;需要跨時間建模,單幀分割能力不足。
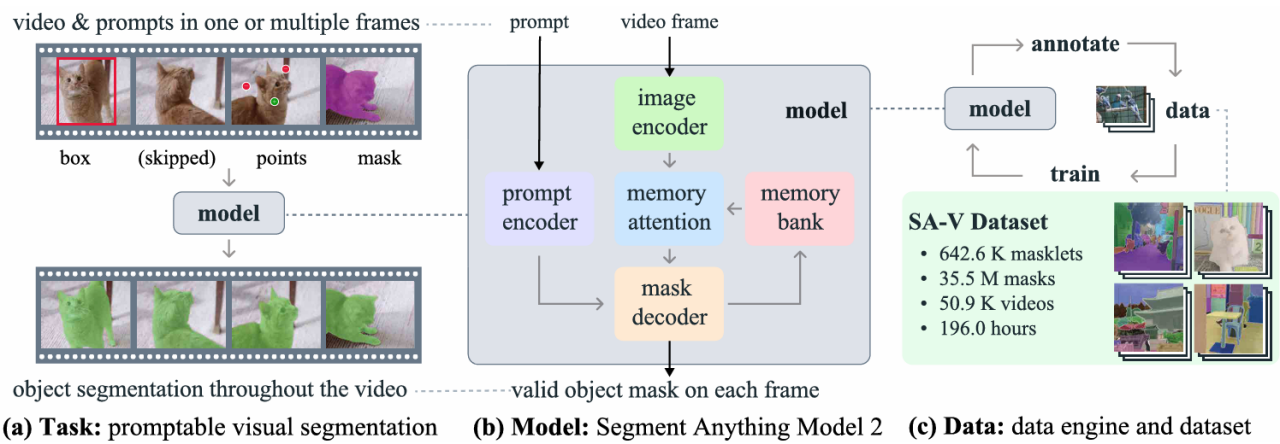
任務定義:Promptable Visual Segmentation,即在任意幀通過點、框、mask等提示進行目標分割,并可跨幀傳播(形成“masklet”);
模型設計:引入流式記憶機制的 transformer 架構,支持跨幀記憶與交互;
數據引擎:構建全球最大的開放視頻分割數據集 SA-V,包括 50.9K 視頻與 35.5M mask。
因此,作者提出新的目標:構建一個支持圖像與視頻統一提示分割任務的視覺基礎模型,即 SAM2。
和SAM一樣的定義風格
二、整體框架
SAM2 的核心由三部分構成:
-
任務定義:Promptable Visual Segmentation(PVS),即在任意幀通過點、框、mask等提示進行目標分割,并可跨幀傳播(形成“masklet”);
-
模型設計:引入流式記憶機制的 transformer 架構,支持跨幀記憶與交互;
-
數據支撐:構建全球最大的開放視頻分割數據集 SA-V,包括 50.9K 視頻與 35.5M mask。
三、核心方法
3.1 模型結構
Promptable Visual Segmentation:擴展 SAM 在圖像上的點擊/框提示分割到視頻中,模型可以在任意幀接收提示(點/框/mask);接著自動生成該目標在全視頻中的掩碼序列(稱為 masklet);用戶可隨時補充提示以修正掩碼,實現“多輪交互式視頻分割”。
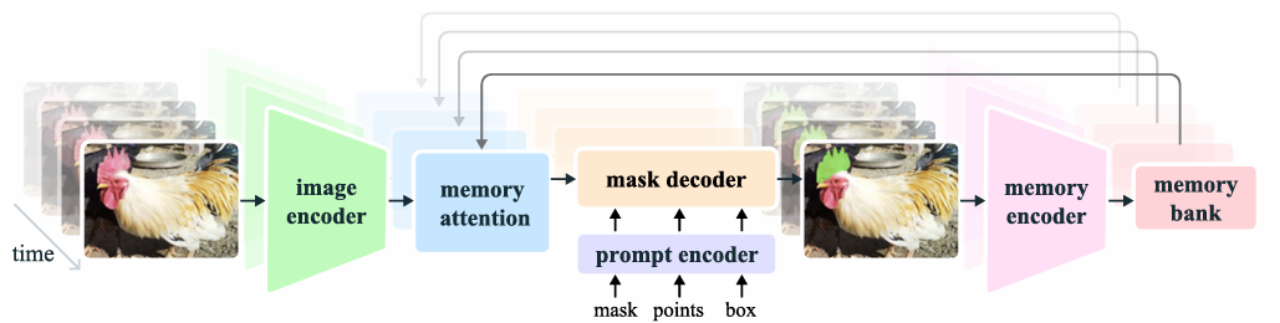
SAM2模型框架
圖像編碼器:采用MAE預訓練的Hiera模型(Meta同期工作,SAM用的是普通的ViT),采用FPN多尺度提取高分辨率特征(stride 4、8、16、32);流式處理視頻幀,每幀僅需前向一次。
Mask Decoder:雙向 Transformer 解碼器堆疊組成,對于每一幀,解碼器輸入當前幀特征 + 歷史記憶 + 當前提示;輸出多個掩碼與其 IoU 分數(支持提示歧義);引入可見性預測頭,支持“當前幀是否包含目標”的輸出。
記憶機制:記憶編碼器融合當前幀圖像特征與掩碼預測,構造記憶;Memory Bank,保存 N 幀最近記憶 + M 幀提示記憶(FIFO 隊列);存儲空間特征與目標語義向量(object pointer);采用位置嵌入,建模短期時間運動信息。Memory Attention,當前幀自注意力 + 與記憶幀做交叉注意力,采用FlashAttention 2。
提示編碼器:完全繼承SAM的工作。支持點、框、掩碼;稀疏提示通過位置編碼+類型嵌入;掩碼提示通過卷積編碼后加到圖像特征上。
3.2 數據集構造
SAM2 使用 “Model-in-the-loop” 數據引擎創建了新的 SA-V 數據集,流程分三階段:
階段1:SAM逐幀輔助
使用原始 SAM 對每幀單獨分割;幀率 6FPS,使用畫筆/橡皮(PS)精修;每幀需 37.8s,收集 16K masklets。
階段2:SAM + SAM2 Mask
SAM2(僅接受 mask)進行掩碼傳播;可反復修改并重新傳播;速度提升至 7.4s/frame,5.1×提速。
階段3:SAM2 完整交互
使用具有記憶與點交互能力的 SAM2;僅需偶爾點擊修正;提速至 4.5s/frame,8.4×提速;共采集 197K masklets。
最終構建 SA-V 數據集:共計 50.9K 視頻,642.6K masklets(含自動掩碼)比已有最大 VOS 數據集多 53× mask 數量;覆蓋完整目標與細粒度部件;覆蓋不同場景、目標大小、遮擋變化等挑戰。
四、總結
SAM2不輸出全圖所有 instance(如 Mask R-CNN 那樣),但可以通過點擊/框選擇“某個目標”,只分割這個實例,并跨幀追蹤。
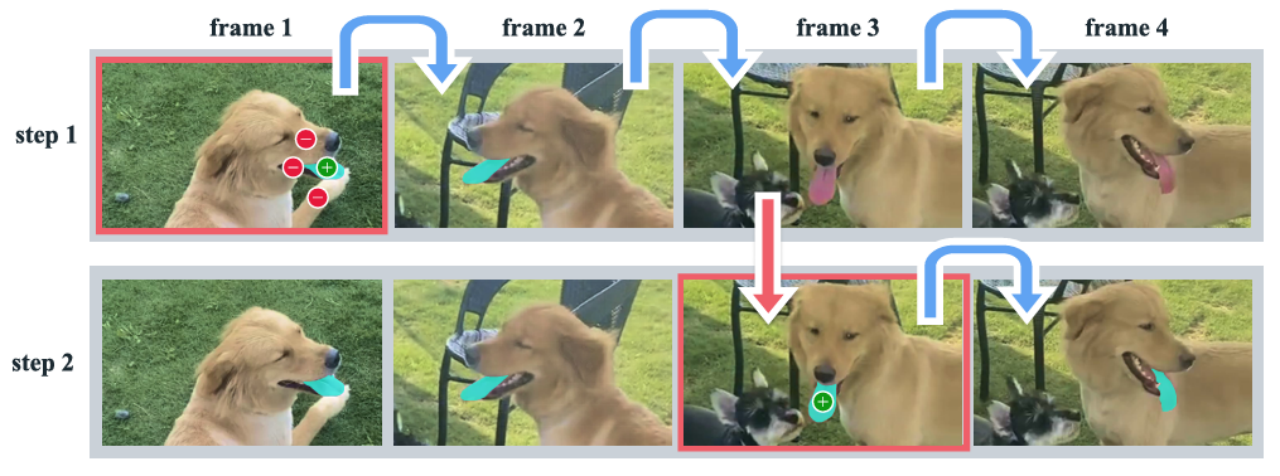
給出舌頭的掩碼,其中綠點是正面,紅點是負面提示;自動傳播到后續幀(即只跟蹤這一實例);支持點擊糾正(如錯過了某一幀的舌頭)。
SAM2 用的是一種transformer + memory bank 的記憶機制:
每幀提取 image feature;用戶點擊提示指明要追蹤哪個目標;模型構建一個“object token”(即目標語義表示);后續幀通過注意力在記憶幀與當前幀之間交互 → 輸出掩碼;若目標不在,模型能預測其“可見性為0”;

)








詳解)




![[D1,2] 貪心刷題](http://pic.xiahunao.cn/[D1,2] 貪心刷題)



