鋒哥原創的Pandas2?Python數據處理與分析 視頻教程:??
2025版 Pandas2 Python數據處理與分析 視頻教程(無廢話版) 玩命更新中~_嗶哩嗶哩_bilibili

前面我們學了.loc[]等幾個簡單的數據篩選操作,但實際業務需求往 往需要按照一定的條件甚至復雜的組合條件來查詢數據。
邏輯運算操作
類似于Python的邏輯運算,我們以DataFrame其中一列進行邏輯計算,會產生一個對應的由布爾值組成的Series,真假值由此位上的數據是否滿足邏輯表達式決定。
我們看一個最簡單示例,查看語文是否及格:
df.set_index('姓名').語文分數 >= 60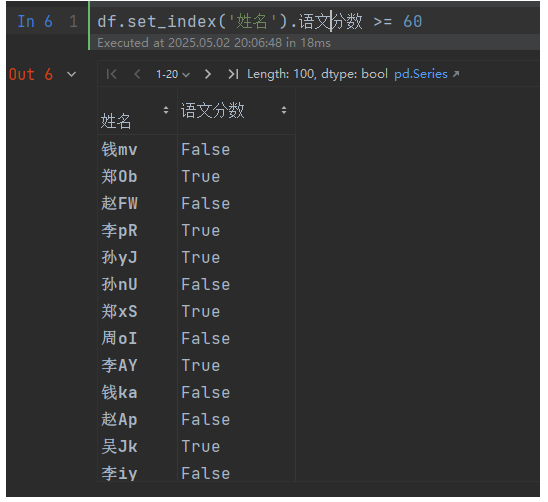
同樣支持多列判斷,查看語文,數據,英語是否及格:
df.set_index('姓名').loc[:, ['語文分數', '數學分數', '英語分數']] >= 60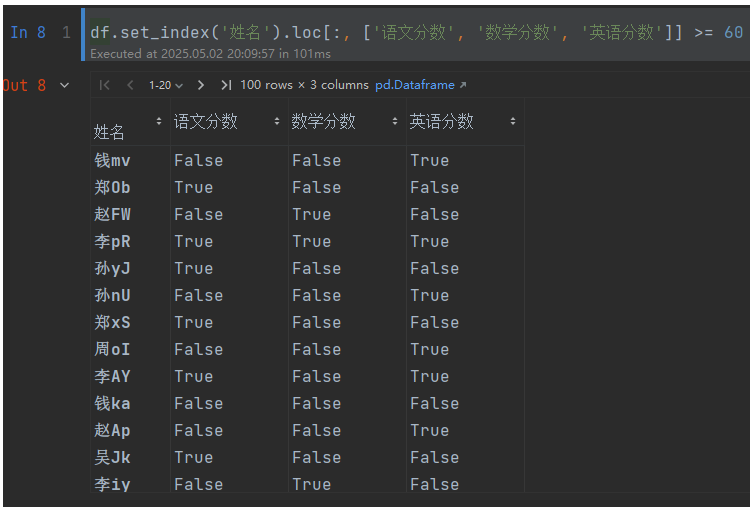
同時還支持組合條件的邏輯運算,我們來查下數學及格的男生。
~(df.數學分數 < 60) & (df['性別'] == '男')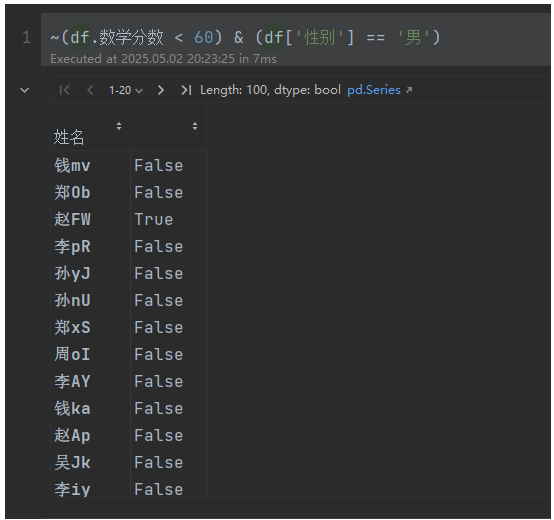
邏輯篩選數據操作
前面我們邏輯運算返回的是布爾類型的Series結果集,我們現在可以通過切片[],.loc()方法來返回邏輯篩選結果。
我們看幾個切片[]實例:
df[df['語文分數'] >= 60] # 查詢語文及格的人
df[~(df['語文分數'] >= 60)] #查詢語文不及格的人
df[df.語文分數 > df.數學分數] # 查詢語文分數高于數學分數的人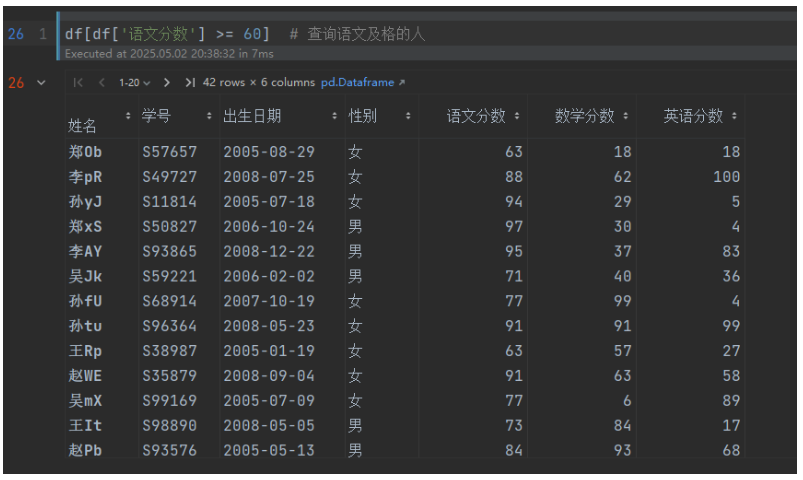
我們在幾個.loc[]實例:
df.loc[df['語文分數'] >= 60, '語文分數'] # 查詢語文及格的人,只顯示索引名稱和語文分數列
df.loc[(df.語文分數 >= 60) & (df.數學分數 >= 60) & (df.英語分數 >= 60)] # 語數英都及格的人
df.loc[(df.語文分數 >= 90) | (df.數學分數 >= 90) | (df.英語分數 >= 90)] # 語數英至少有一個90分的人
df.loc[df.語文分數 == 100] # 語文滿分的人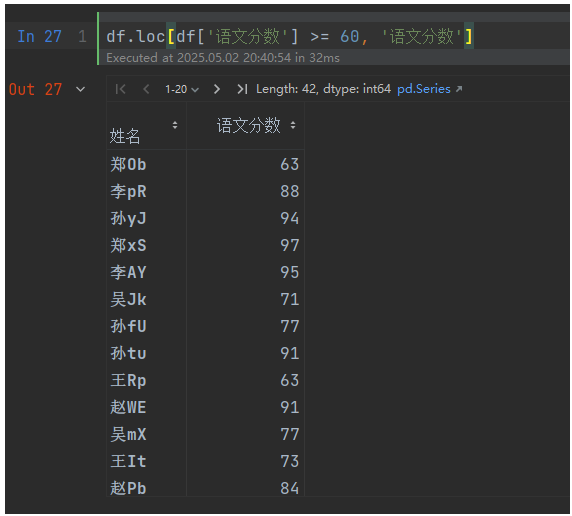
需要注意的是在進行或(|)、與(&)、非(~)運算時,各個獨 立邏輯表達式需要用括號括起來。
pandas提供了一些比較函數來支持邏輯運算:
df.ne() # 不等于 !=
df.le() # 小于等于 <=
df.lt() # 小于 <
df.ge() # 大于等于 >=
df.gt() # 大于 >參考示例:
df.loc[df.語文分數.eq(100)] # 語文滿分的人
df.loc[(df.語文分數.ge(60)) & (df.數學分數.ge(60)) & (df.英語分數.ge(60))] # 語數英都及格的人查詢函數query()操作
pandas 的 query() 方法是一種高效且簡潔的 DataFrame 數據過濾工具,允許通過字符串表達式篩選滿足條件的行。它的語法類似于 SQL 的 WHERE 子句,特別適合復雜查詢和動態條件處理。
基本語法
DataFrame.query(expr, inplace=False, **kwargs)-
expr:字符串形式的查詢條件表達式(支持列名、運算符、邏輯條件等)。
-
inplace:是否直接修改原 DataFrame(默認為
False,返回新 DataFrame)。 -
**kwargs:其他參數(如
engine='python'或parser='pandas')。
核心特性
-
簡潔性:無需重復寫 DataFrame 名稱,直接使用列名操作。
-
動態表達式:支持字符串插值(如
@variable引用外部變量)。 -
性能優化:底層依賴
numexpr庫,對大數據集查詢效率更高。 -
復雜條件支持:靈活組合多條件(
and/or/not)。
我們來看下示例:
df.query('數學分數>90') # 數學分數大于90的人
df.query('數學分數+語文分數+英語分數>250') # 總分大于250的人
df.query('(語文分數>90)&(性別=="男")') # 語文分數90分以上的男生
df.query('(語文分數>90)and(性別=="男")') # 語文分數90分以上的男生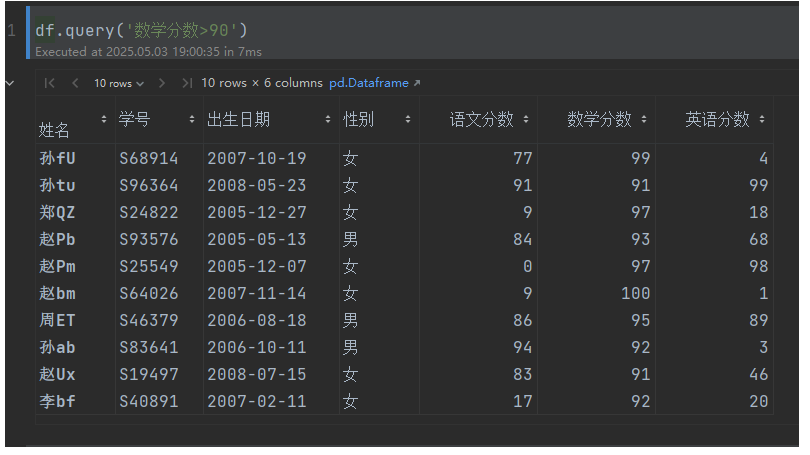
還支持使用@符號引入變量,看下下面示例:
avg = df.語文分數.mean() # 求平均分
df.query('語文分數>@avg') # 語文分數超過平均分的人
df.query('語文分數>@avg+30') # 語文分數超過平均分30分的人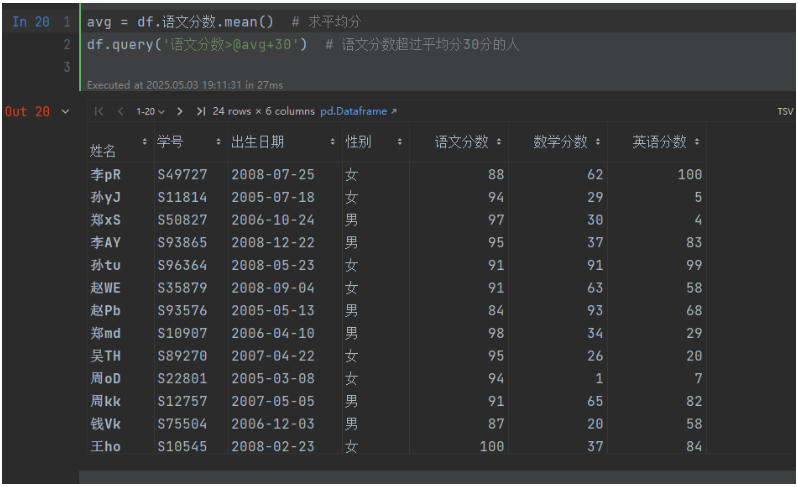
篩選函數filter()操作
pandas 的 filter() 方法用于根據行或列的標簽名稱篩選數據,支持按列名或行名匹配規則快速過濾。它不依賴數據內容,而是基于標簽的規則匹配,適合處理列名或索引有特定規律的場景。
基本語法
DataFrame.filter(items=None, # 直接指定列名/行名列表like=None, # 模糊匹配包含指定字符串的標簽regex=None, # 正則表達式匹配標簽axis=None # 篩選方向:0(行)或 1(列,默認)
)核心參數詳解:
-
items:精確匹配列名或行名
-
like:模糊匹配包含字符串的標簽
-
regex:正則表達式匹配標簽
-
axis:指定篩選方向
具體示例:
df.filter(items=['語文分數', '數學分數']) # 選擇列
df.filter(like='分數') # 列名包含分數的列
df.filter(regex='孫', axis=0) # 所有孫姓數據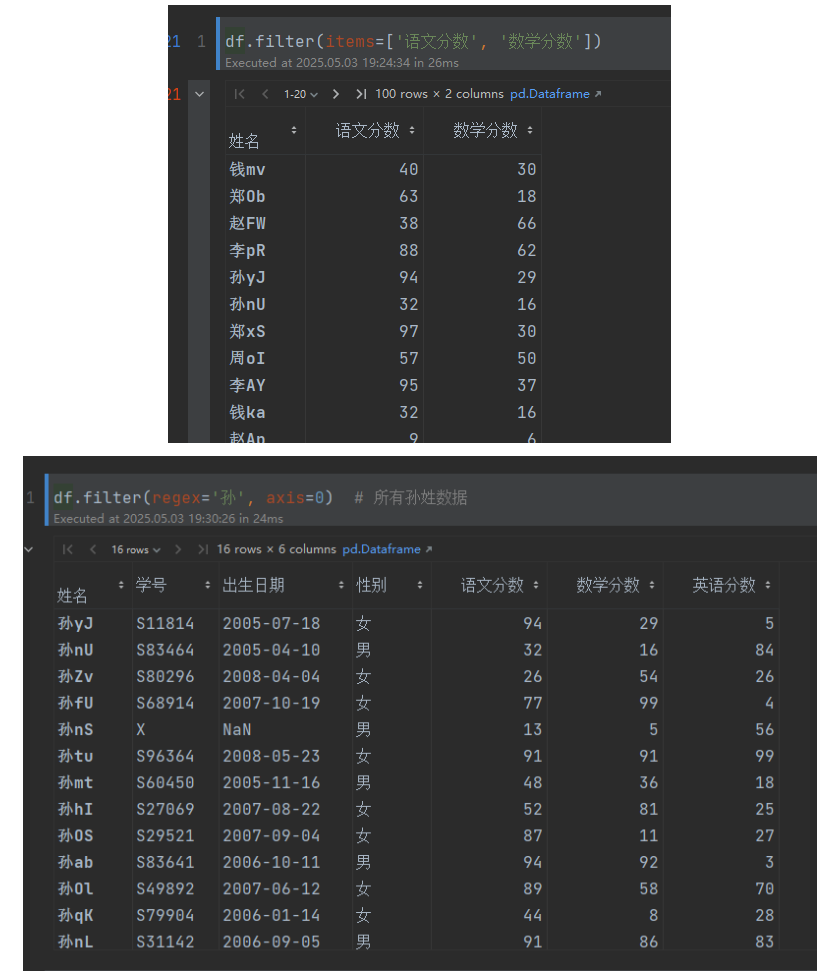
失效)



)
知識點總結歸納)












)
---java版)