一些小知識:
- ?關于事務:時序數據庫是沒有事務的,它和關系數據庫的應用場景不同,通常情況下不需要多點同時操作同一條數據,而且要保證極高的吐出量,事務太消耗資源,并且時序數據庫提供了覆寫的功能,能讓用戶后期修改數據。
- ?關于iotdb的寫入速度:(后面引用官方的內容)時序數據庫 IoTDB 可通過底層文件 Apache TsFile 支持列式數據寫入,達到毫秒級數據接入,并首創亂序分離存儲引擎,大幅提升弱網環境產生的亂序數據處理效率,穩定實現千萬級/秒數據寫入。
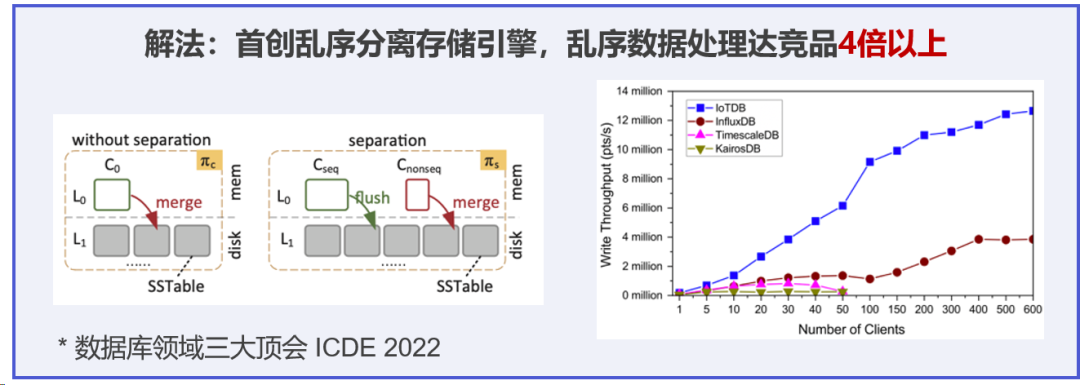
(目前即使用開源版本,從我個人角度來看,系統用的1.3.x的版本運行了一年左右的時間,沒有出現任何問題,可想IoTDB的穩定性,不虧為國貨之光!而且還有官方的交流群,里面的問答還都非常的積極,真的是很難得!)
?V2.0.2正式版
? ? ? ? 前兩天IoTDB正式發布了V2.0.2正式版,作為樹表雙模型正式版本,主要新增表模型權限管理、用戶管理以及相關操作鑒權,并新增了表模型 UDF、系統表和嵌套查詢等功能。補齊了之前beta版本中權限相關的內容。
? ? ? ? 在這個版本中算是正式的帶來了表模型,雖然表模型對我我個人在我的應用場景下感覺不大,對我來說就是展示層“列轉行”了一下。(因為從開始從網上搜索對比時序數據庫,團隊就選定了國產IoTDB,不涉及一些遷移),其實內部上也是“列轉行”,只是對同一種數據文件的不同展示,官方也有對應的說明,使用的是同一個底層數據文件TsFile。
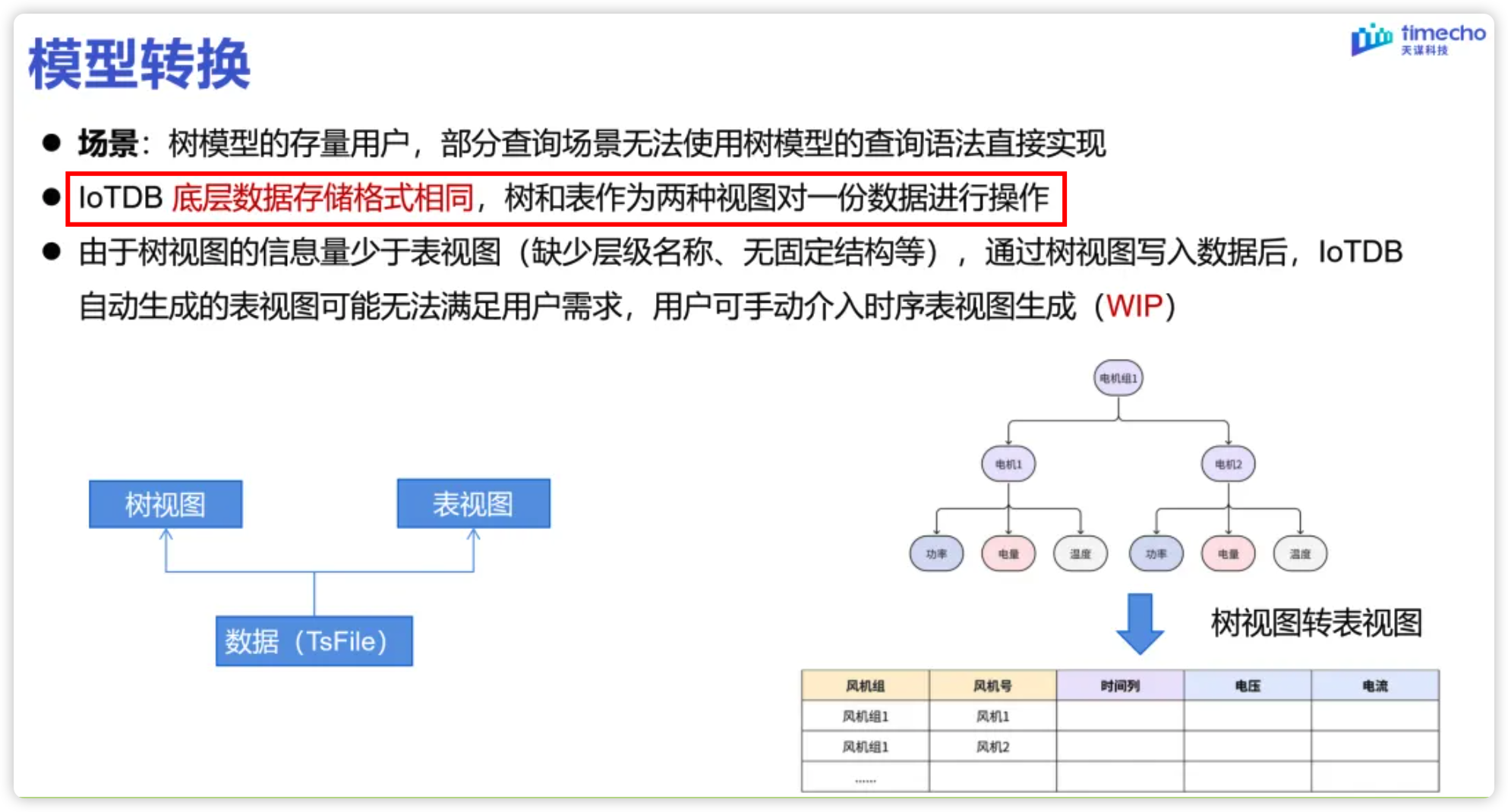
所謂的表模型和樹模型其實就是兩種視圖view。其實在之前的workbench中也有所提現。在workbench中的數據模型里面,就是樹模式的展現,根就是root。
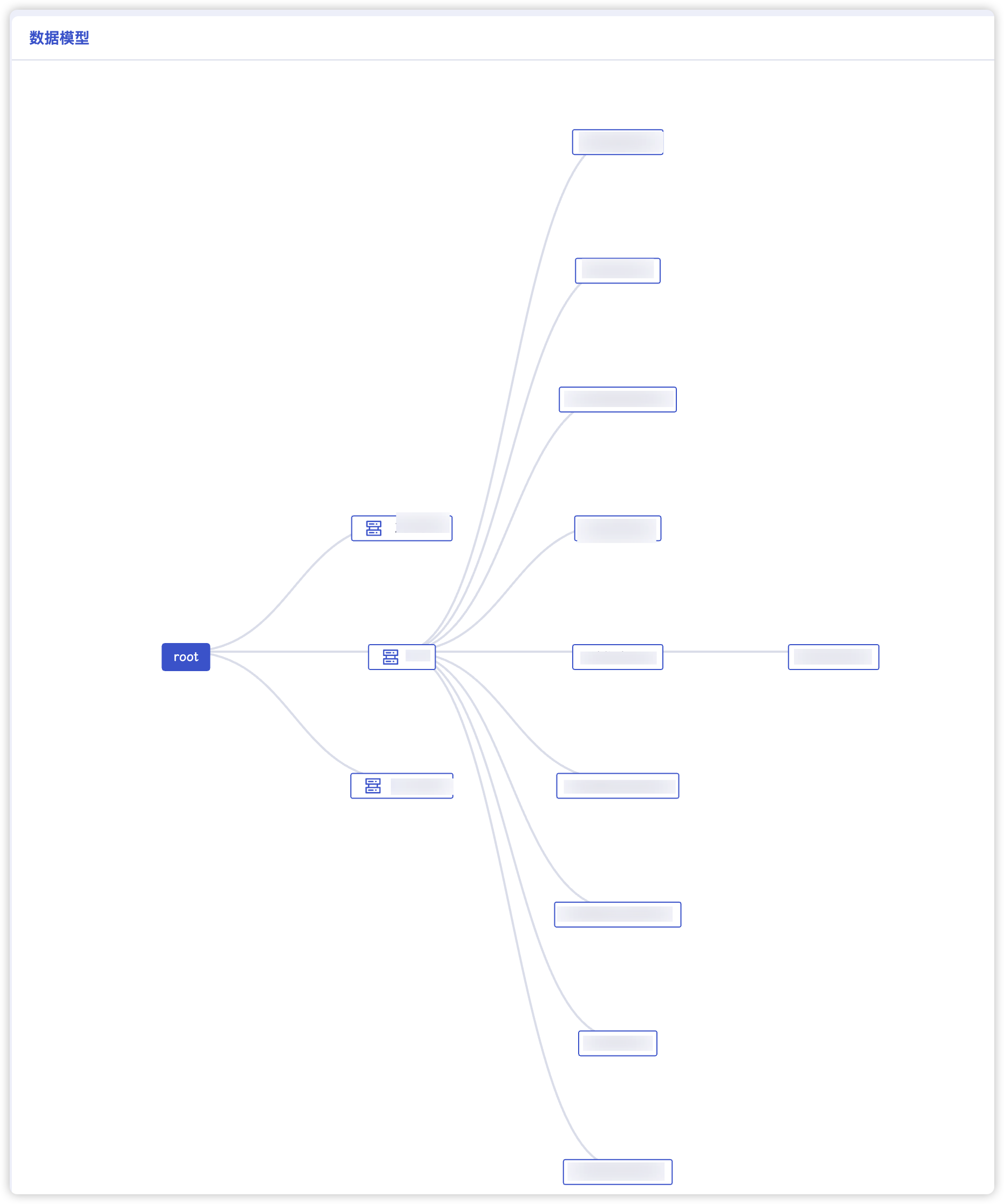
在數據查詢頁面,所有的點位的路徑都在column上
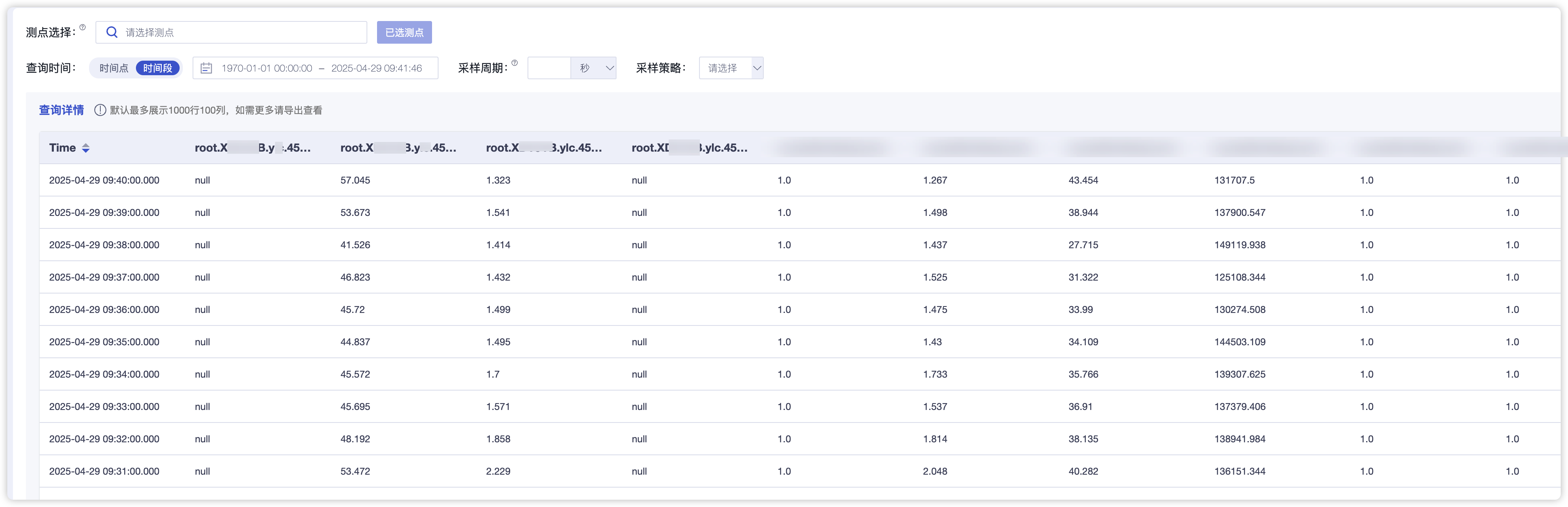
而表模式從另一種角度理解的話,就是把time后面的column名稱中的相同部分進行拆分放到了前面,拆分幾項就多增加幾列,方便看具體的點位內容。
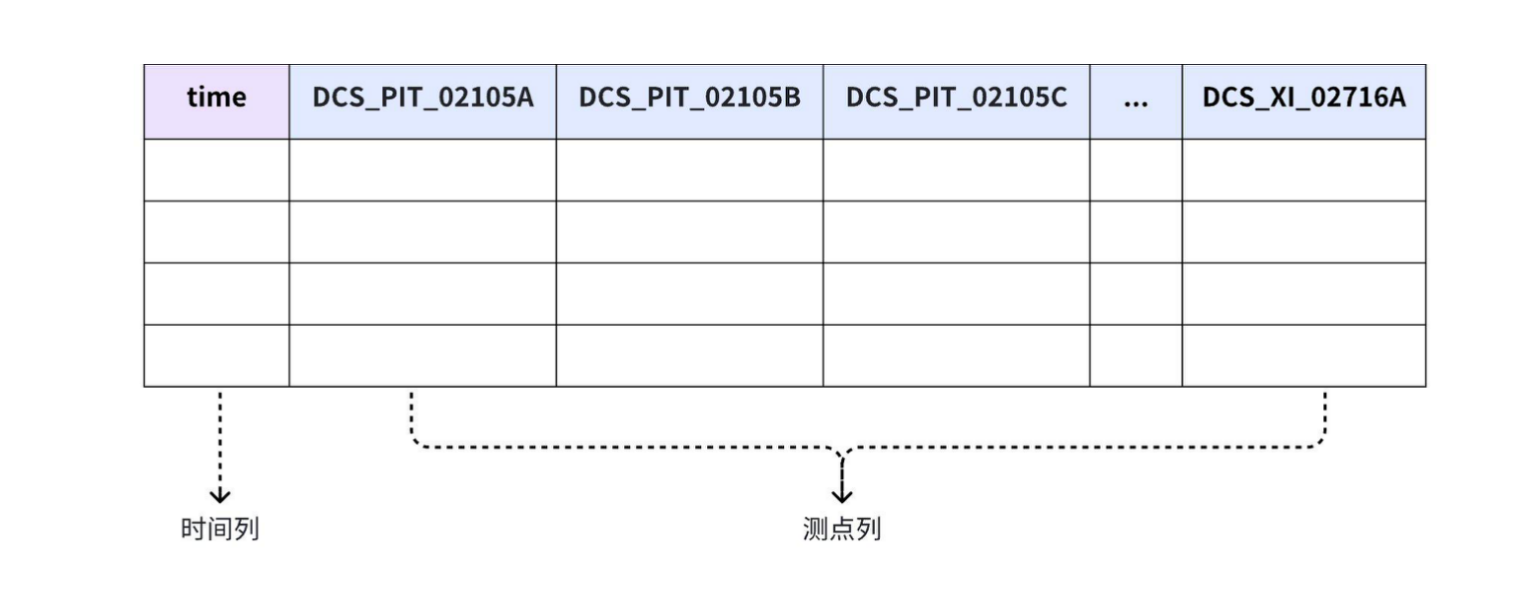
注:表模式的column不能用root開頭!
應用場景
? ? ? ? 至于兩種模式的應用場景,我個人覺得團隊的經驗還是很重要的,整體還是需要根據實際情況來,下面貼出官方的建議(但也只是建議,大多數對的并不一定適合你自身的場景)
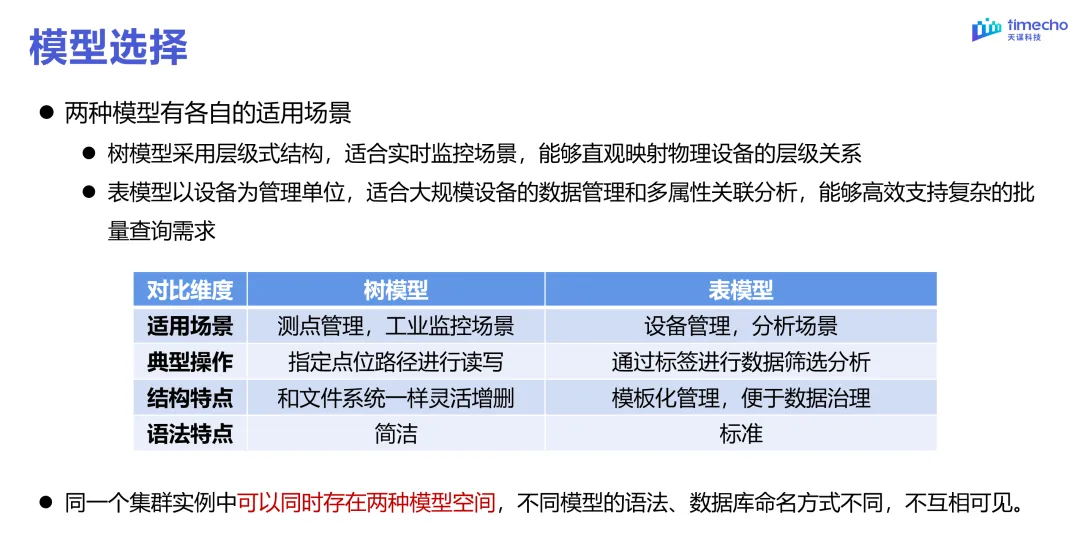
雖然IoTDB支持兩種模式的切換,我個人更建議如果有資源的話,而且你的業務場景也需要兩種場景的話,不如弄兩份“單機”數據庫,這樣可以一個專門負責實時采集,一個負責分析。
表模型的鏈接方式
先附上官方的圖(這個在說明文檔里面可能沒有,在教學視頻里面。)

我個人用的是java,也就是把之前用的SessionPool前面都加上Table。至于其它方式注意圖片上面的紅字內容!
IoTDB與其他時序數據庫的綜合對比
? ? ?下面的內容來自deepseek(現在有Ai了,要用好Ai,從deepseek給我的反饋,我更慶幸我們的團隊從最開始就選擇了IoTDB,尤其是他們的群聊里面回復疑問真的很及時!)
1.?架構設計與分布式能力
-
IoTDB
-
原生分布式優化:IoTDB專為物聯網場景設計,支持靈活的分布式架構,提供共識協議統一框架(如IoTConsensus、RatisConsensus),用戶可根據需求選擇不同算法,兼顧性能與一致性110。其數據分區和負載均衡策略適應億級設備與跨十年時間范圍的數據管理,最大支持PB級存儲14。
-
輕量級部署:支持單機部署,無需依賴Hadoop或Zookeeper等組件,資源占用低,適合邊緣設備110。
-
-
對比其他數據庫
-
HBase/OpenTSDB:依賴HDFS和Zookeeper,架構復雜,擴展性受限;HBase采用鏈式復制(Chain Replication),寫入延遲較高,故障恢復復雜1410。
-
TimescaleDB:基于PostgreSQL擴展,支持SQL兼容,但時序優化不如IoTDB深入,分布式能力依賴外部分片策略7。
-
2.?邊云同步與邊緣計算支持
-
IoTDB
-
內置流處理引擎:支持端邊云實時同步,自適應選擇流式或文件(TsFile)傳輸,斷點續傳和低帶寬優化,適合邊緣環境1310。
-
近存儲計算:通過TsFile高壓縮傳輸,減少網絡流量,支持邊緣側數據預處理19。
-
-
其他數據庫
-
HBase:需借助Kafka或Flink實現同步,開發運維成本高10。
-
InfluxDB:單機版開源,缺乏分布式支持,長期數據查詢性能下降3。
-
3.?性能表現與存儲優化
-
IoTDB
-
寫入與查詢性能:在TPCx-IoT基準測試中,IoTDB的吞吐量是HBase的6.6倍,性價比提升11.8倍58。支持千萬點/秒寫入,10年跨度的歷史數據查詢秒級響應9。
-
高壓縮比:采用復合壓縮算法(如Gorilla、SDT),存儲成本降低10倍,適用于振動波形等高頻數據69。
-
-
對比其他數據庫
-
OpenTSDB:依賴HBase存儲,查詢受限于讀放大,壓縮效率較低4。
-
TimescaleDB:支持自動分片和壓縮,但時序壓縮率不及IoTDB,且寫入性能在工業級場景中表現較弱7。
-
4.?部署易用性與運維成本
-
IoTDB
-
一鍵部署:支持單機與集群模式,無需復雜依賴,運維工具豐富(如監控指標上千種)110。
-
動態擴展:節點增減無需停機,適應業務彈性需求410。
-
-
其他數據庫
-
HBase/OpenTSDB:需部署HDFS、Zookeeper等組件,運維復雜度高,擴展需人工干預分區策略14。
-
TimescaleDB:依賴PostgreSQL生態,輕量級場景資源占用較高7。
-
5.?功能特性與擴展性
-
IoTDB
-
分析與計算:內置30+函數(如標準差、頻域分析),支持時序聚合、異常檢測及機器學習框架(AINode)47。
-
動態模式:支持樹形數據模型,靈活適應設備層級結構,動態更新元數據27。
-
-
對比其他數據庫
-
OpenTSDB:僅支持基礎聚合(如sum/avg),復雜計算需依賴Spark等外部系統4。
-
TimescaleDB:完整SQL支持,適合傳統數據分析,但缺乏原生時序語義優化7。
-
6.?應用場景與行業實踐
-
IoTDB
-
工業物聯網:支持端-邊-云協同,應用于能源電力(如寶武鋼鐵)、車聯網(千萬級數據點/秒)等場景,實現長周期數據存儲與實時分析39。
-
案例:寶武集團通過IoTDB替換OpenTSDB,寫入性能提升10倍,存儲成本降低90%,支持振動波形數據納秒級處理9。
-
-
其他數據庫
-
InfluxDB:適合短期監控數據,長期存儲性能不足3。
-
HBase:適用于數據中心大規模存儲,但邊緣場景適配性差10。
-
7.?產品迭代與生態建設
-
IoTDB:代碼提交活躍(周均100-300次),持續優化壓縮算法與邊緣計算支持,社區生態與Hadoop/Spark深度集成47。
-
OpenTSDB:發展停滯,依賴老舊HBase生態,功能迭代緩慢4。
總結
IoTDB在工業物聯網場景中展現出顯著優勢,尤其在分布式架構靈活性、邊云協同、高壓縮存儲及長期數據管理方面領先。相比HBase、OpenTSDB等依賴傳統大數據組件的數據庫,IoTDB更適合資源受限的邊緣環境與海量時序數據處理;而對比TimescaleDB等關系型時序庫,其原生時序優化更貼合工業需求。未來,隨著端邊云協同需求的增長,IoTDB有望進一步鞏固其作為時序數據庫領航者的地位。
至于代碼環境的相關升級和注意點,請點擊👇🏻這篇!
IoTDB時序數據庫V2.0.2代碼環境升級-CSDN博客



)
---java版)


:操作系統)











