目錄
一、智算中心發展概覽
二、計算力核心技術解析

一、智算中心發展概覽
智算中心是人工智能發展的關鍵基礎設施,基于人工智能計算架構,提供人工智能應用所需算力服務、數據服務和算法服務的算力基礎設施,融合高性能計算設備、高速網絡以及先進的軟件系統,為人工智能訓練和推理提供高效、穩定的計算環境。智算中心的主要功能包括:
-
提供強大的計算能力:智算中心采用專門的AI算力硬件,如GPU、NPU、TPU等,以支持高校的AI計算任務。
-
高效的數據處理:智算中心融合了高性能計算設備和高速網絡,能夠處理大規模的數據集和復雜的計算任務。
-
支持多種AI應用:智算中心適用于計算機視覺、自然語言處理、機器學習等領域,處理圖像識別、語音識別、文本分析、模型訓練推理等任務。
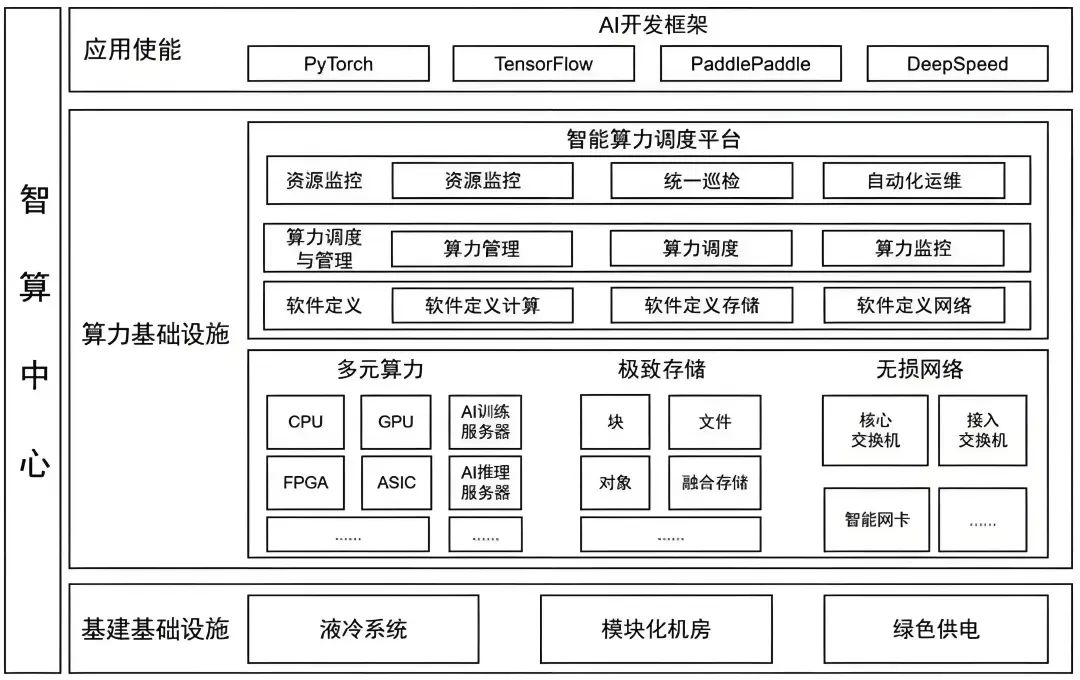
智算中心AIDC內涵
狹義上講,智算中心是通用算力中心的升級,在傳統數據中心的基礎上融合GPU、TPU、FPGA等專用芯片支撐大量數據處理和復雜模型訓練。AIDC把不同的計算任務實時智能調度分配給不同的服務器集群以提升計算效率。簡單講智算中心就是“機房+網絡+GPU 服務器+算力調度平臺”的融合基礎設施,是傳統數據中心的增值性延伸。
廣義地說,智算中心是提供人工智能應用所需算力服務、數據服務和算法服務的新型算力基礎設施,包含基礎層、平臺層和應用層。其中,基礎部分是支撐智算中心建設與應用的先進人工智能理論和計算架構,平臺部分圍繞智算中心算力生產、聚合、調度、釋放的作業邏輯展開;應用層提供算力生產供應、數據開放共享、智能生態建設和產業創新聚集。是融合算力+數據+算法的新型基礎設施,是AI技術一體化的載體,是傳統云的智能化升級。
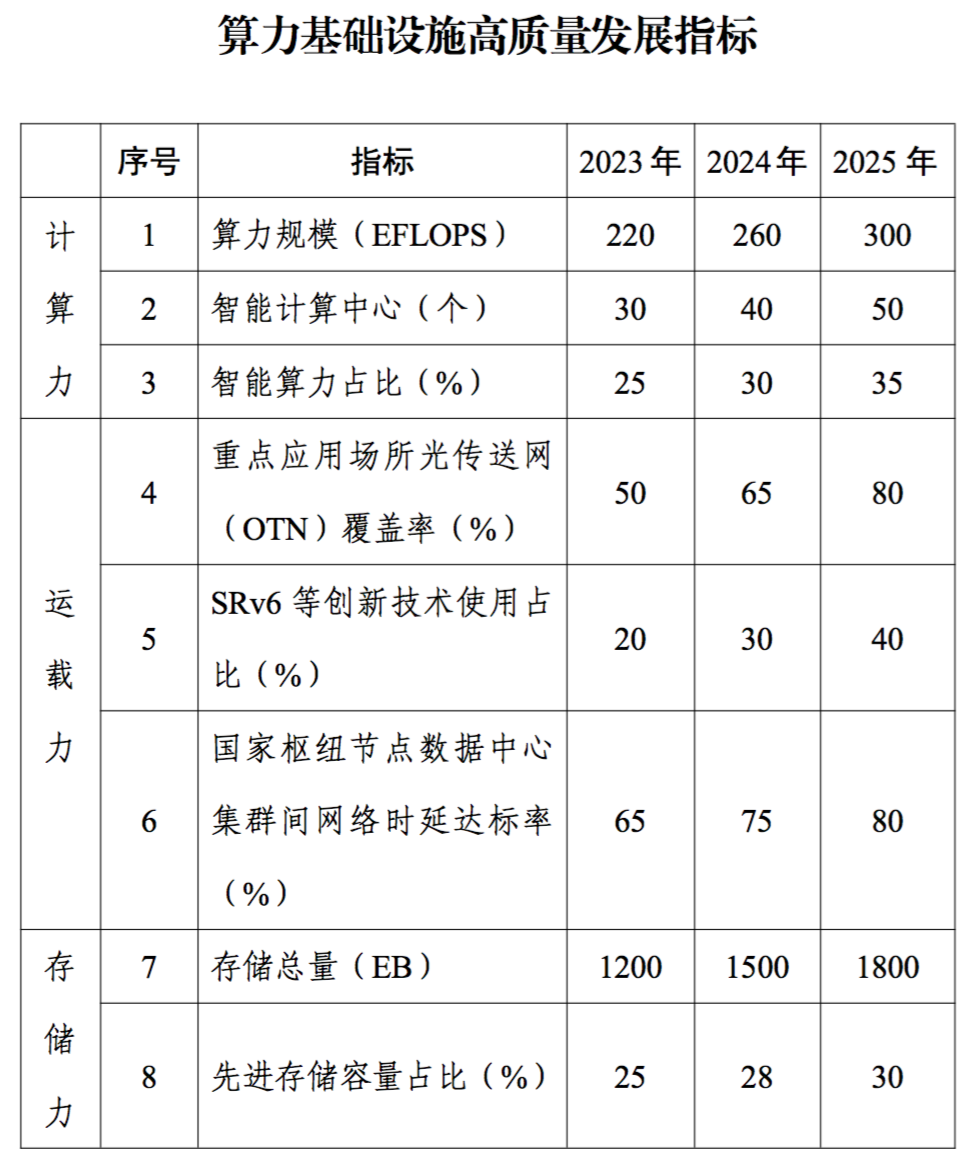
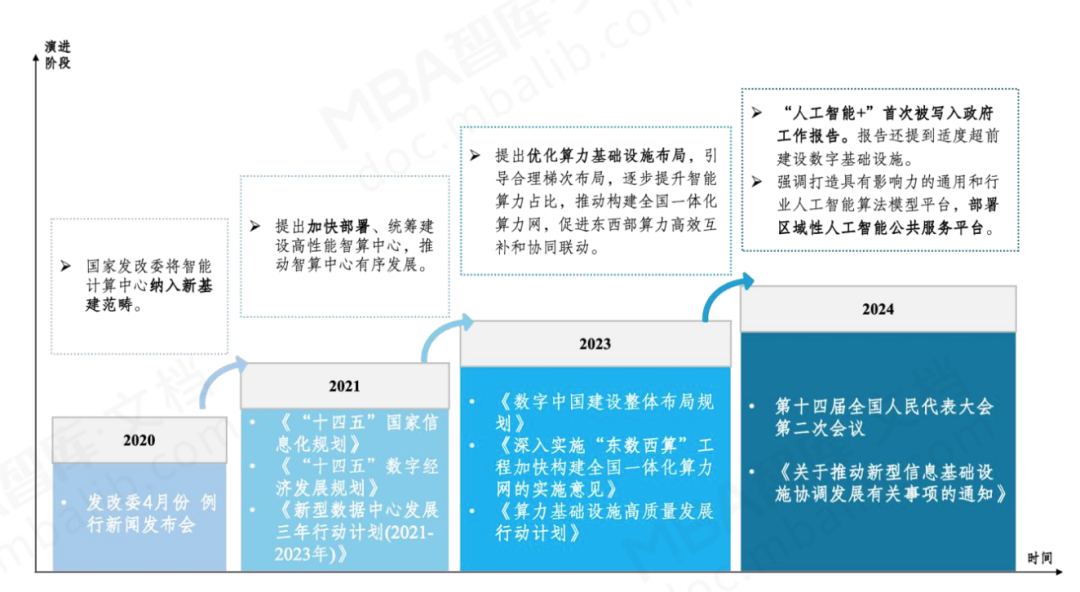
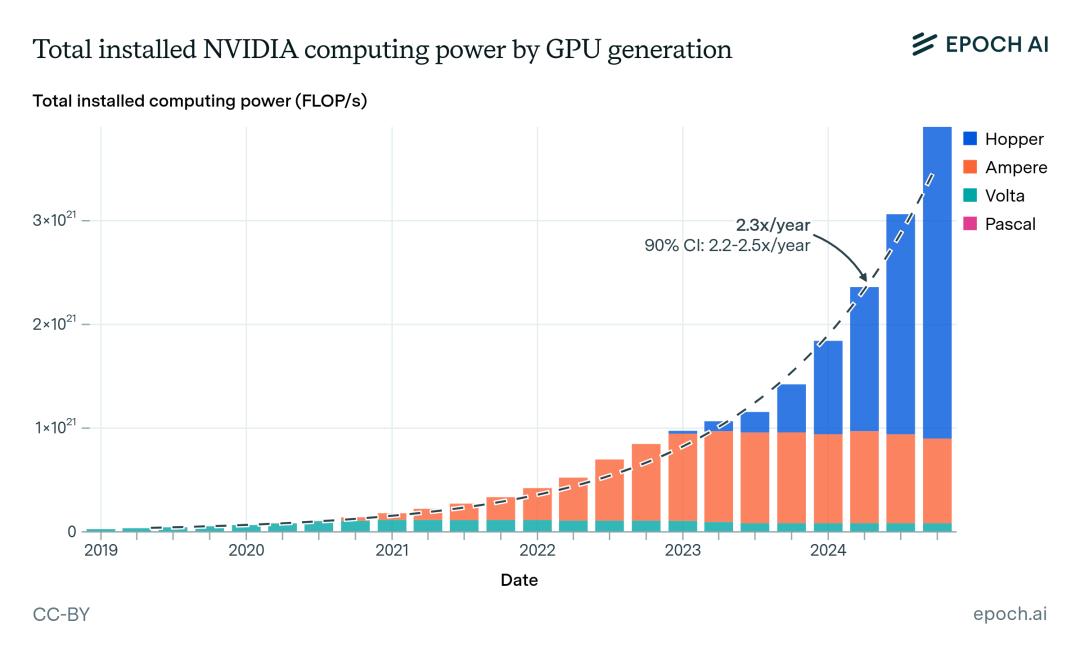
人工智能作為引領未來的戰略性技術,逐步成為衡量國家國際競爭力的重要領域,高性能算力是人工智能發展的重要組成部分。從全球范圍看,各國紛紛制定人工智能相關的戰略和政策,推動高性能算力發展。如美國成立智算中心基礎設施特別工作組、歐盟出臺《歐盟高性能計算共同計劃》、日本發布《人工智能戰略2022》等。我國也于2023年出臺《算力基礎設施高質量發展行動計劃》,進一步凝聚產業共識、強化政策引導,全面推動我國算力基礎設施高質量發展。報告要求,到2025年要實現如下主要目標:

算力常用計量單位是每秒執行的浮點運算次數(FLOPS,Floating-point operations per second),數值越大計算能力越強。
KFLOPS(kiloFLOPS)=10^3 FLOPS
MFLOPS(megaFLOPS)=10^6 FLOPS
GFLOPS(gigaFLOPS)=10^9 FLOPS
TFLOPS(teraFLOPS)=10^12 FLOPS
PFLOPS(petaFLOPS)=10^15 FLOPS
EFLOPS(exaFLOPS)=10^18 FLOPS
存儲容量常用計量單位是艾字節(EB,1EB=2^60bytes)
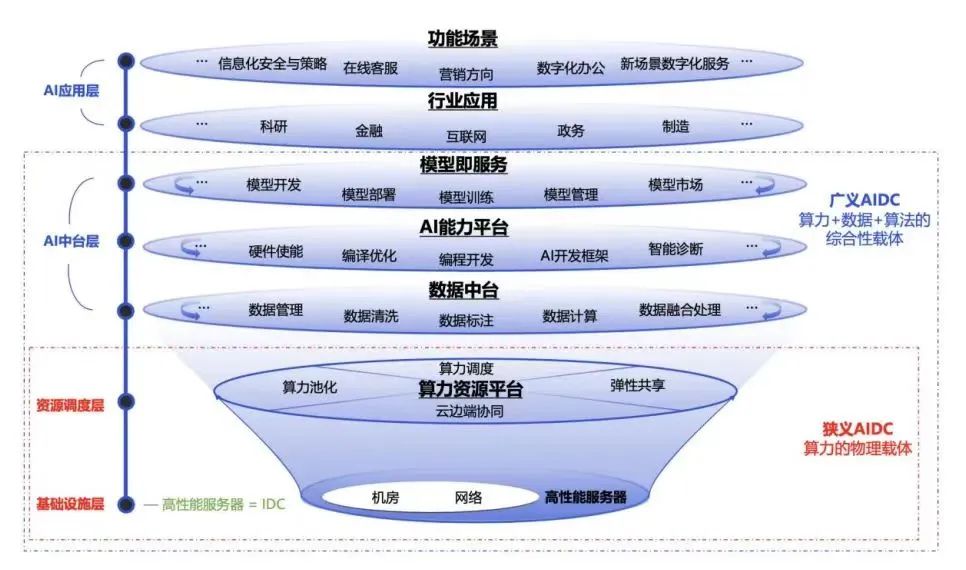
智算中心產業及市場規模
智算中心產業鏈涵蓋從AI芯片/服務器等設計制造、基礎設施建設,到智算服務提供,以及生成式大模型研發及基于大模型的行業應用。
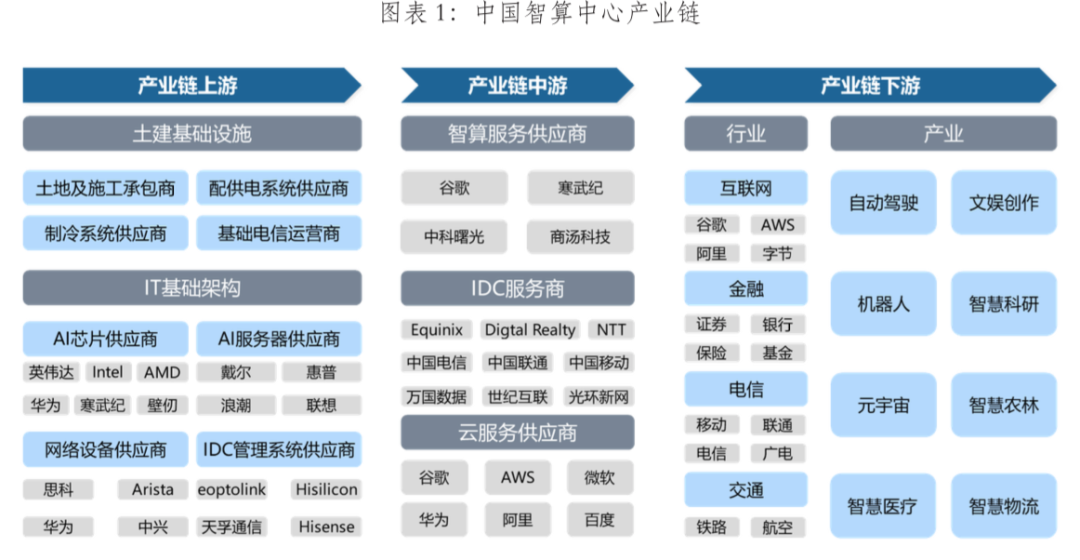
在需求的推動下我國智算中心市場投資規模高速增長。2022年生成式人工智能大模型推向市場,在過國內引起AIGC發展熱潮,大模型訓練對智能算力的需求迅速攀升。2023年起國內頭部互聯網企業及科技公司加速AIGC布局,政府也牽頭建設公共智能算力中心,賦能社會數字化轉型需求,全國智算中心投資火熱,智算中心市場規模大幅增長,尤其是今年1月份DeekSeep的火爆出圈,更是進一步加速了這一進程。
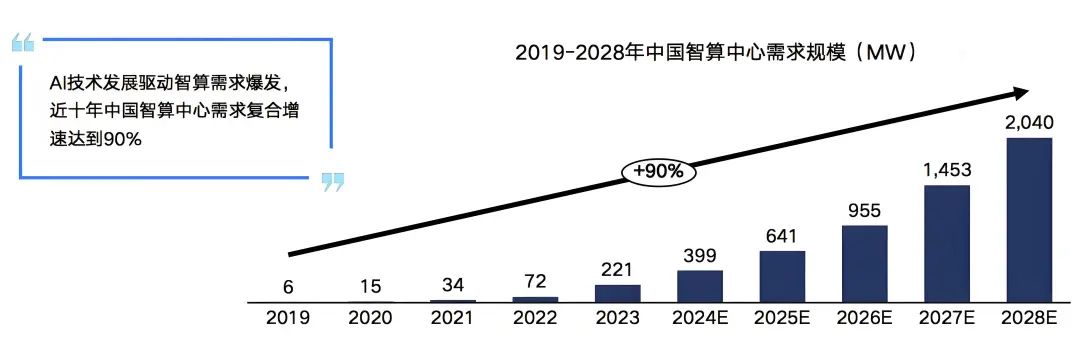
雖然近期有消息稱,智算中心建設暫時按下了減速鍵,但是未來,AI大模型應用場景,不斷豐富,商用進程逐步加快,智算中心市場增長動力逐漸由訓練切換至推理,市場進入平穩增長期,預計2028年我國智算中心市場投資規模有望達到2886億元。
二、計算力核心技術解析
AI芯片
智算中心常見應用場景為訓練和推理,根據其對算力精度的需求的差異分為FP32、TF32、FP16、BF16、INT8、FP8、FP6、FP4等。智能算力的核心是CPU、GPU、FPGA、ASIC等各類計算芯片。AI芯片內核數量多,擅長并行計算,滿足AI算法所需要的大量并行處理能力,并顯著提升計算效率和靈活性。智算服務器是智算中心的主要算力硬件一般采用CPU+GPU、CPU+FPGA、CPU+ASIC等異構形式,以充分發揮不同算力芯片在性能、成本和能耗上的優勢。
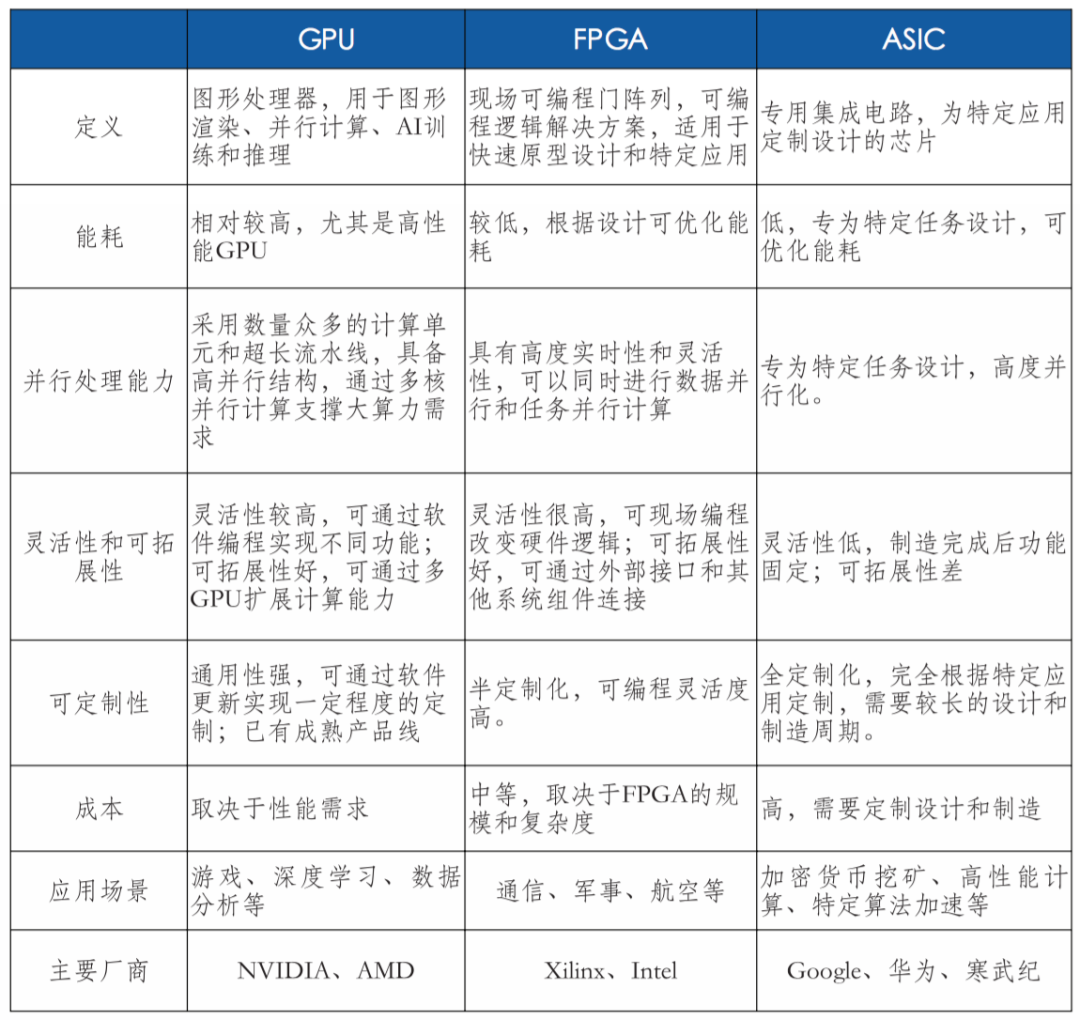
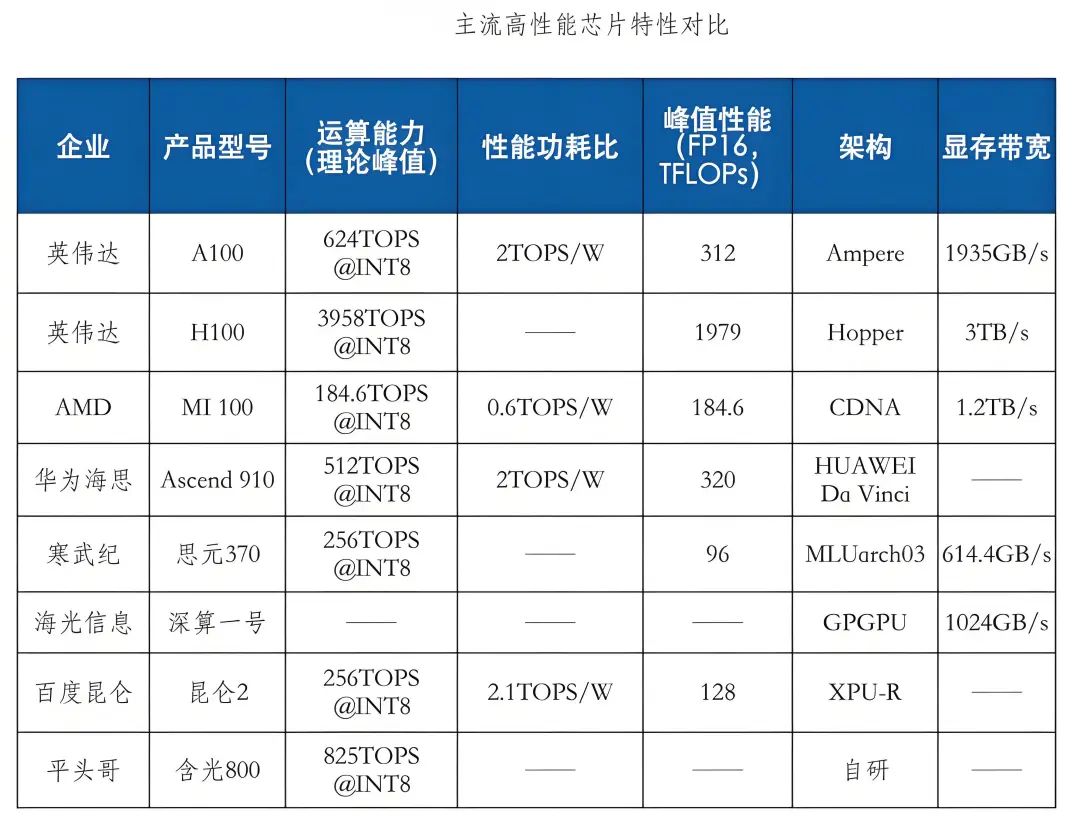
高性能芯片技術快速迭代創新,為人工智能發展提供保障,進而帶動智算中心發展,Nvidia作為全球GPU算力芯片市場領導者,代表性產品H100、A100、V100技術指標處于領先水平,最新的Blackwell架構B200 GPU采用先進的4納米工藝,實現了基于FP4高達40PFLOPS的運算能力,相較前代提升5倍。其他科技巨頭如AMD、英特爾、微軟、亞馬遜和谷歌也在AI芯片領域展開競爭。同時,我國AI芯片國產化進程正在加速發展,華為、寒武紀、海光信息、景嘉微以及阿里、百度等企業不僅在自研AI芯片技術上取得重要進展,還通過產品集成、行業解決方案及生態伙伴合作等方式推進國產AI芯片商業化應用,為智能算力發展提供堅實基礎。
Nvidia H100 GPU
本節基于Nvidia的公開資料GPU H100報告為例,解析GPU的相關技術實現。
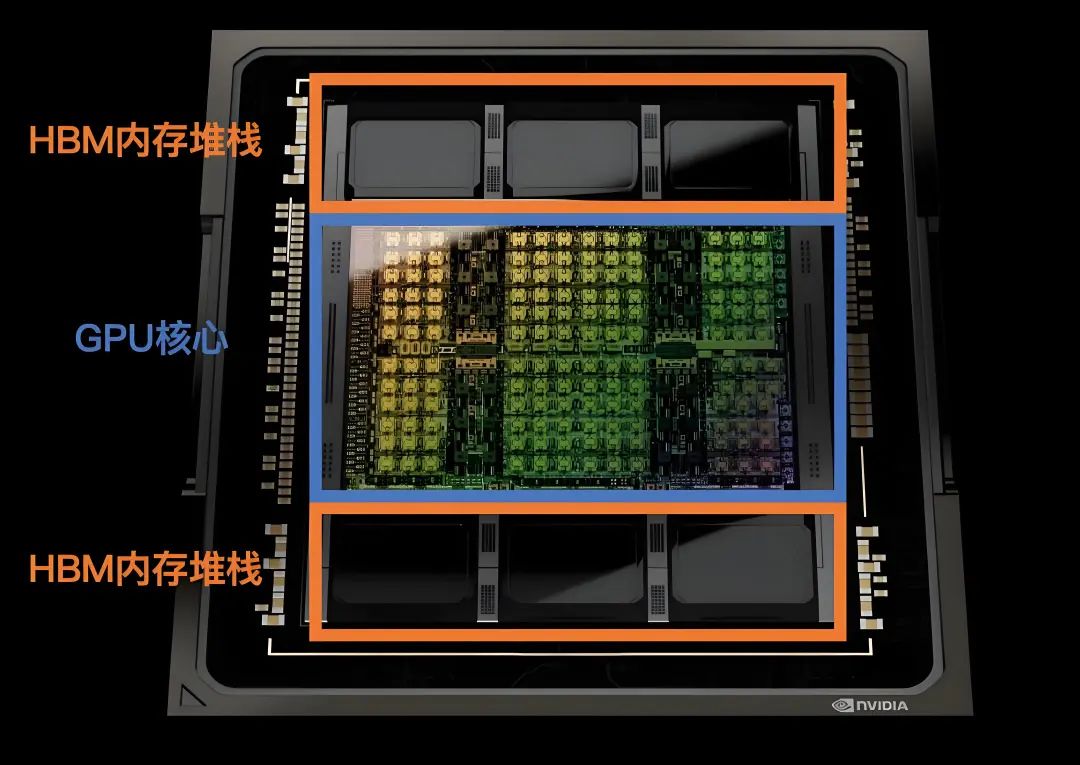
GPU在本質上是一個PCI-E插卡/扣卡,由PCB(Printed Circult Board,印刷電路板)、GPU芯片、GPU內存(即“顯存”)及其他附屬電路構成。
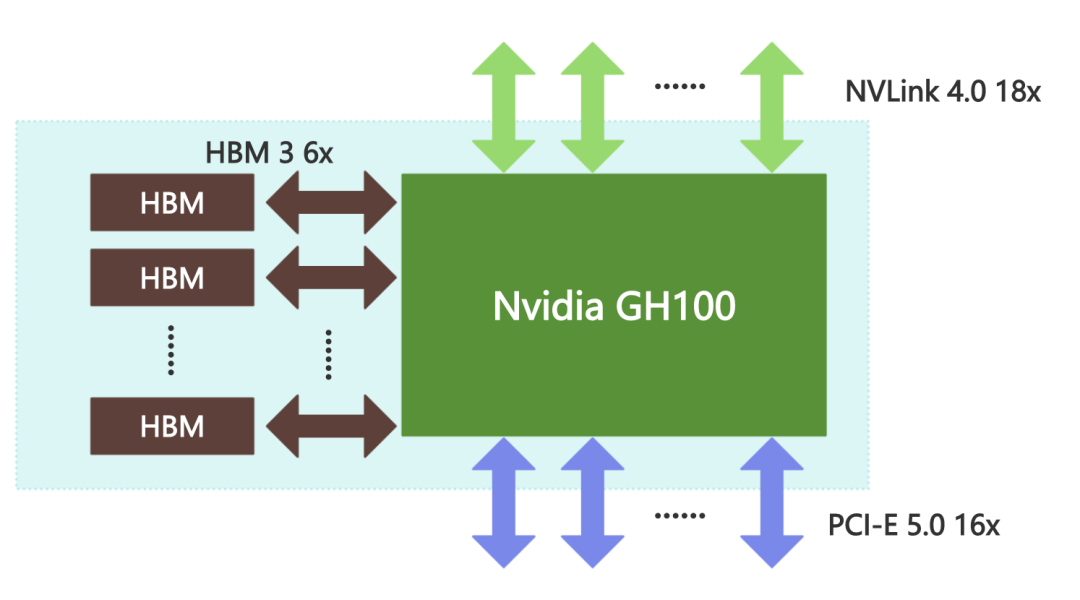
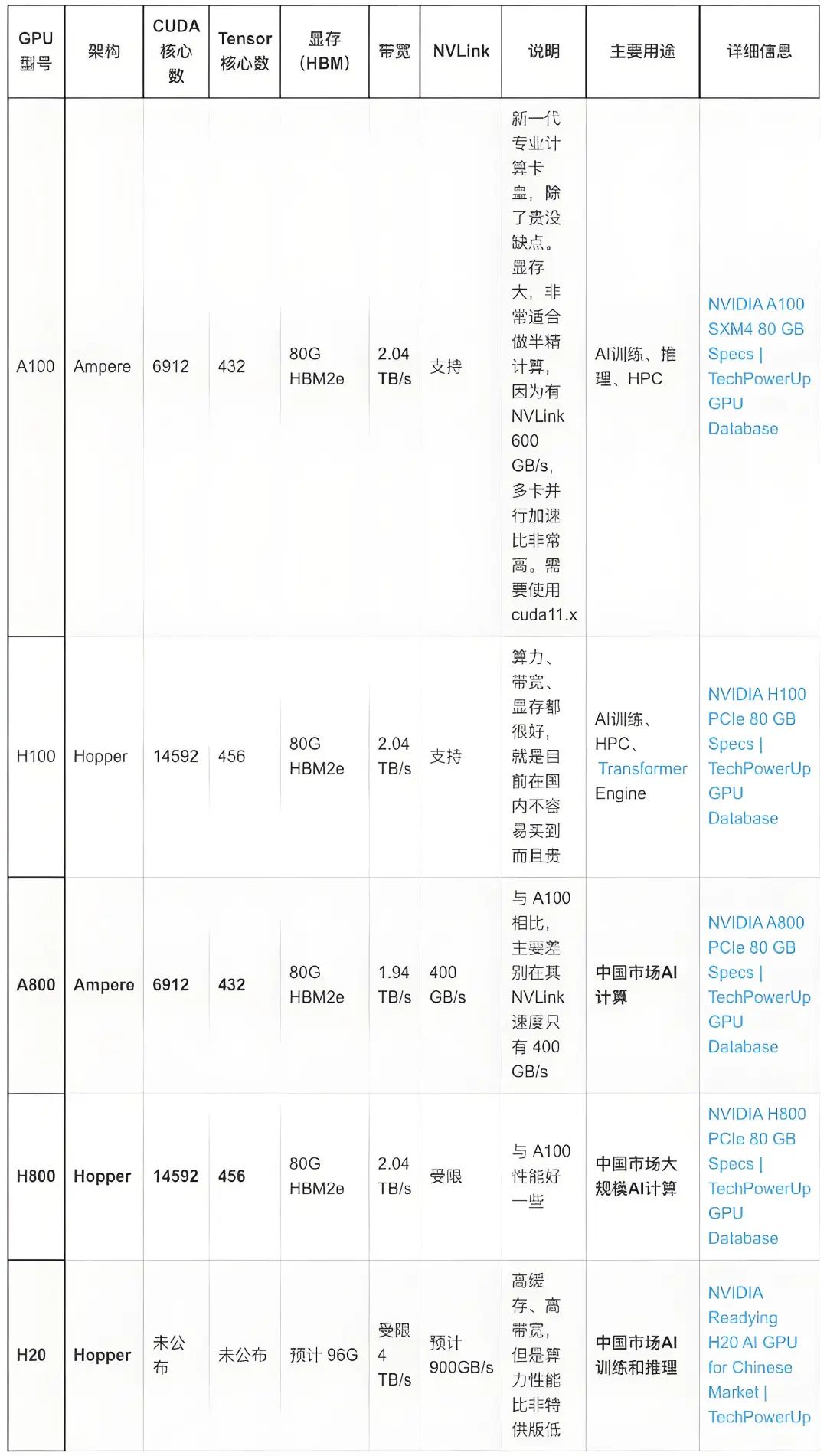
Nvidia H100 GPU的核心芯片是Nvidia GH100,對外的接口有16個PCI-E 5.0通道、18個NVLink 4.0通道和6個HBM 3/HBM 2e通道。
-
在Nvidia H100 GPU卡上,Nvidia GH100 的16個PCI-E 5.0通道用于連接到CPU,實現CPU將程序指令發送到GPU,并為GPU提供訪問計算機主存儲器的通道,總共可以提供約63GBps的理論傳輸帶寬。
-
與Nvidia GH100 配套的顯存是HBM(High Bandwidth Memory,高帶寬內存)。HBM是由三星、AMD和SK Hynix等芯片廠商在2013年提出的一種在DDR內存的基礎上進一步提升內存性能的內存接口標準,仍然采用DDR內存的時序標準。與DDR內存不同,HBM充分利用了內存芯片封裝內部的立體空間,在內存芯片中將多層存儲電路堆疊起來,以實現在較小的平面面積上獲得極高的內存容量和帶寬。Nvidia GH100 芯片支持6個HBM Stack,每個HBM Stack都可以提供800GBps的傳輸帶寬,總內存帶寬可達到4.8TBps。
-
Nvidia GH100 還提供了18個NVLink 4.0通道,共提供900GBps的理論傳輸帶寬,可以直接連接到其他GPU,或通過NVLink Switch連接多個GPU,實現GPU之間的互訪,讓一個GPU可以在CPU無感知的情況下訪問另一個GPU的內存,而無需繞行PCI-E總線。
在Nvidia H100 GPU卡上,PCI-E 5.0通道和NVLink通道是連接到GPU卡外部的,而HBM通道在PCB內部連接到PCB上的HBM芯片,不延伸到卡外部。另外,Nvidia提供了不帶NVLink的精簡版本Nvidia H100 GPU卡,這樣Nvidia GH100芯片上的NVLink接口也就閑置了,在其他規格上也有一定的精簡。同時,Nvidia考慮到其他因素,為特定的國家和地區提供了進一步精簡規格的GPU,比如Nvidia H800等。
SM 流式多處理器
下圖是Nvidia GH100芯片的內部架構圖,在Nvidia GH100芯片中,除了NVLink接口、PCI-E接口和HBM接口,真正的核心部件就是SM(Streaming Multiprocessor,流式多處理器)。
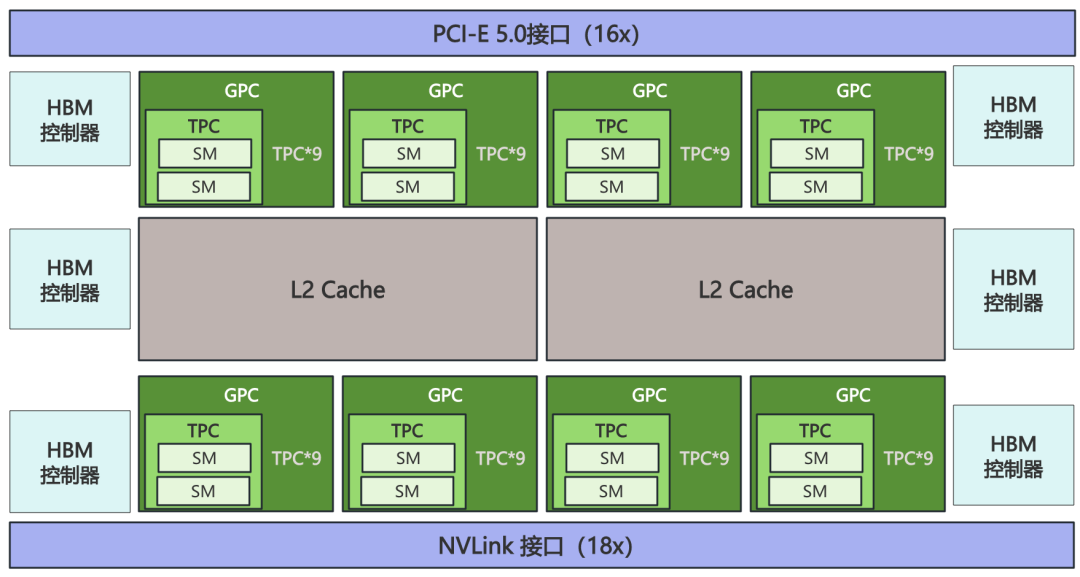
整個Nvidia GH100 芯片有8個GPC(CPU Processing Cluster,GPU處理集群),每4個GPC都共有30MB的L2 Cache(二級緩存),每個GPC都有9個TPC(Texture Processing Cluster,紋理處理集群),在每個TPC內都有2個SM。也就是說,整顆Nvidia GH100 芯片集成了144個SM。
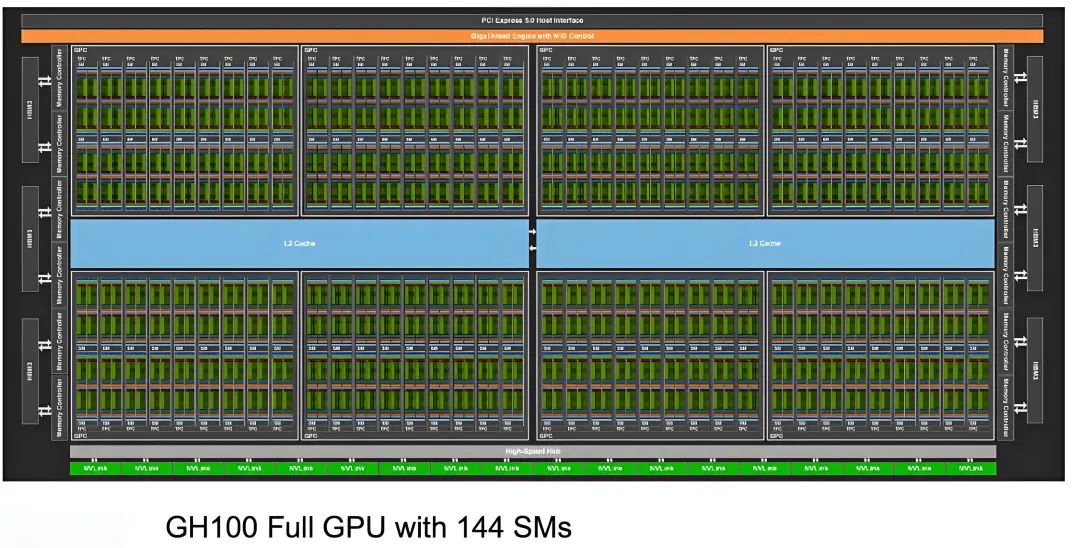
SM內部結構如下圖所示。在每個SM內部都有256KB的L1 Data Cache(一級數據緩存),被所有計算單元共享,同時,在SM內部還有4個紋處理單元Tex。SM的計算核心部件是Tensor Core和CUDA Core(下圖中一個INT32單元、2個FP32單元和1個FP64計算單元組成)。除此之外,還有L0 Instruction Cache(一級指令緩存)等部件。
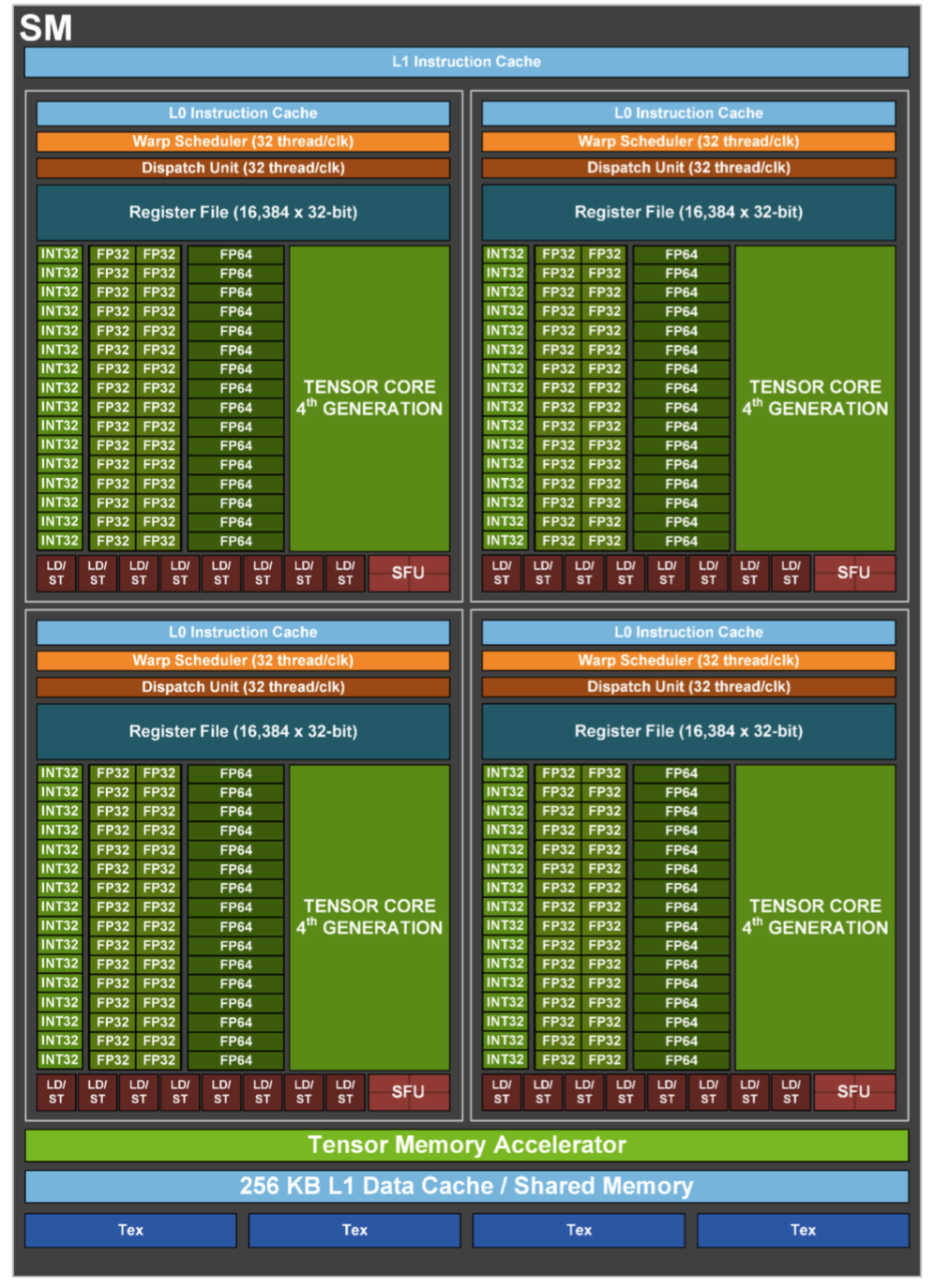
在Hopper架構中,每個SM都有4個象限,每個象限都包含1個Tensor Core和32個CUDA Core,總計4個Tensor Core和128個CUDA Core。整顆芯片可用的CUDA Core數量為144 X 128 = 18432個,可用的Tensor Core 數量為144 X 4 = 576個。
內存加速器
為了提升Tensor Core的內存存取速度,Nvidia在Hopper架構中引入了TMA(Tensor Memory Accelerator,張量存儲加速器),以提高Tensor Core讀寫內存的交換效率。TMA可以讓Tensor Core使用張量維度和塊坐標指定數據傳輸,而不是簡單地按數據地址直接尋址,這在矩陣分割等場景中能進一步提升尋址效率。例如,在Nvidia A100上,線程本身需要生成矩陣的子矩陣中各行數據所在的地址,并執行所有數據復制操作。但在基于Hopper架構的Nvidia H100中,TMA可以自動生成矩陣中各行的地址序列,接管數據復制任務,將線程解放出來做真正有價值的計算任務。TMA加速的工作原理如下圖。
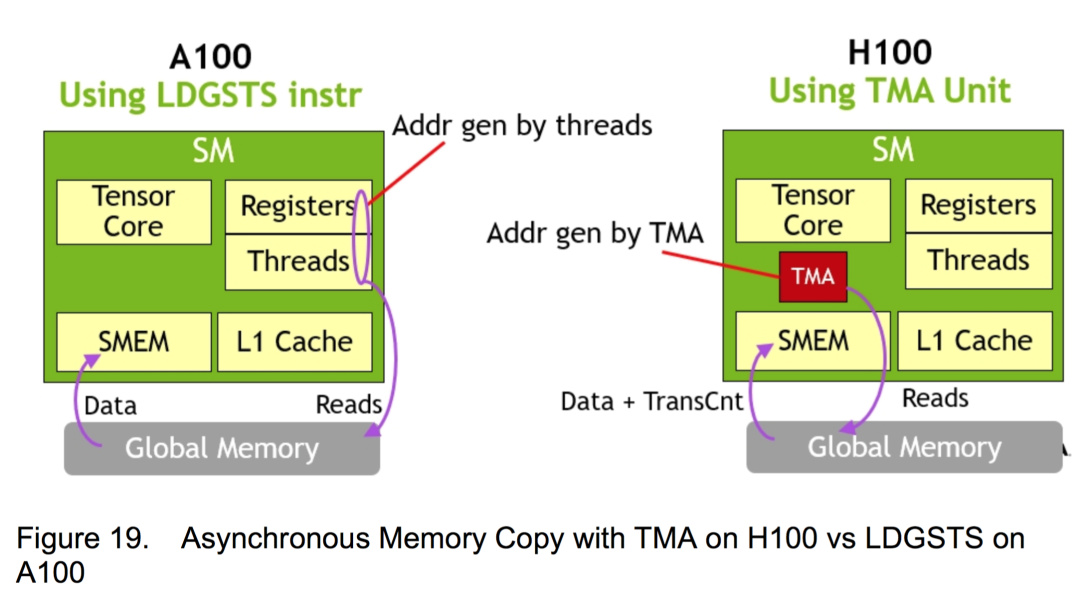
數據局部性考量
在GPU這種超大規模的并行計算機中,對數據局部性的考量變得尤為重要,對于GPU而言,就是要將數據盡量放在靠近計算單元的位置,這樣能夠讓計算單元盡可能發揮緩存的低延遲和高帶寬優勢。如果想充分利用時間局部性和空間局部性提升計算機的性能,就首先要充分理解計算單元和緩存。
-
在Hopper架構下,訪問速度最快的是SM中每個象限的1KB Register File。
-
訪問速度次之的是每個象限的1塊L0指令緩存,被32個CUDA Core和1個Tensor Core共用。
-
訪問速度更慢一些的,是每個SM中的256KB L1 Data Cache,由所有CUDA Core和Tensor Core共用。
-
比L1 Data Cache更慢的是在整顆芯片中集成的60MB的L2 Cache,由2個BANK 組成,最慢的是Nvidia GH100 芯片外部的HBM3顯存。
在劃分工作負載時,也需要充分考慮這幾個閾值,在避免發生緩存沖突的同時,將系統性能發揮到最大。
異步計算
除了基于緩存的優化外,并行計算在異步計算方面也進行了優化。異步計算就是盡量杜絕任務的互鎖或序列化操作,充分利用所有計算單元,避免計算單元等待和阻塞。Hopper架構提供了SM之間共享內存的交換網絡,每個線程塊都可以將自身的內存共享出來,是的其他線程塊的CUDA Core和Tensor Core能夠直接通過load/store/atomic等操作訪問。
Hopper架構還繼承和改進了Amper架構的一個重要特性:MIG(Multi-Intance CPU),支持GPU的硬件虛擬化。在MIG的加持下,可以將GPU劃分為多個彼此隔離的GPU實例給不同的用戶使用,每個GPU實例都擁有自己獨立的SM和顯存,如下圖所示。
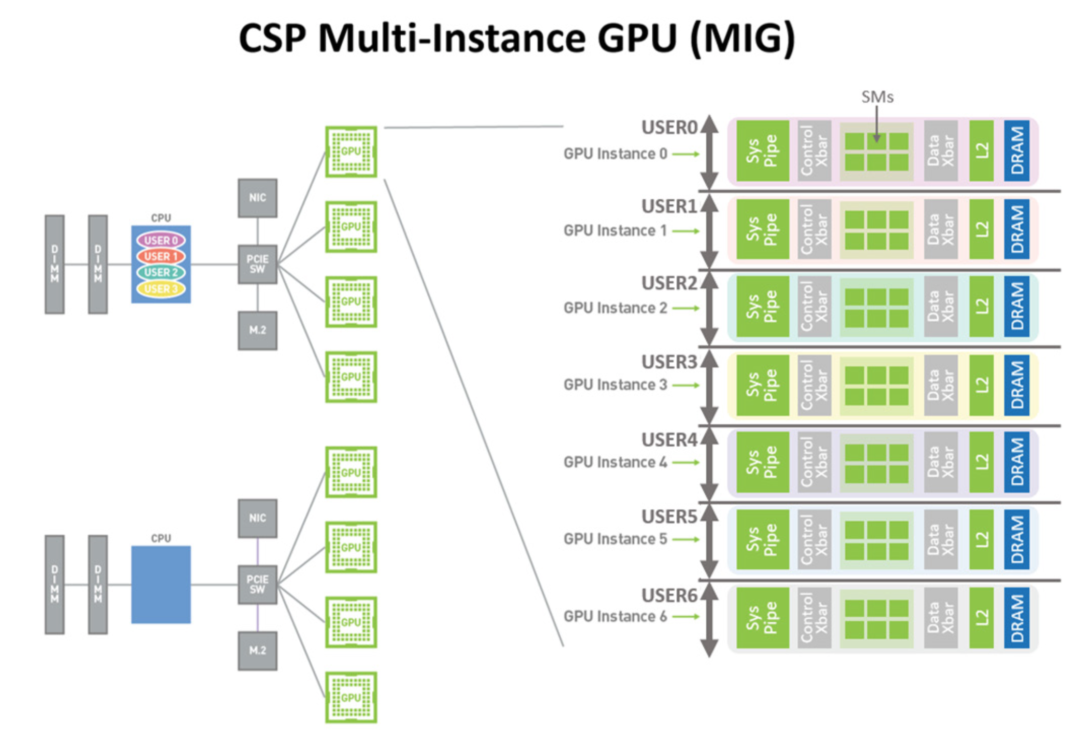
在Hopper架構中對MIG進行了安全方面的增強,能夠支持可信計算,還增加了對MIG虛擬化實例監控能力,從而更適應多租戶的云服務場景。
IO框架
分布式計算機系統,I/O設計往往也是影響系統性能的重要因素。典型的分布式I/O設計有虛擬化系統中常用的VirtIO,高性能計算中常用的HPFS,以及大數據平臺依托的HDFS。在常規的分布式訓練模式中,會涉及以下問題:
-
CPU對其他節點上的GPU下發GPU指令
-
GPU和GPU之間的交互,比如交換彼此計算出的權重、取值等。
-
GPU與本地存儲設備的交互,比如讀取模型和樣本。
-
GPU與遠端存儲設備的交互,比如讀取其他節點上的模型和樣本。
對于這些問題,Nvidia給出的解決方案是讓GPU使用盡量短的路徑實現直通,也就是GPU Direct。對此Nvidia提供了對應的I/O設計框架:Magnum IO,如下所示。
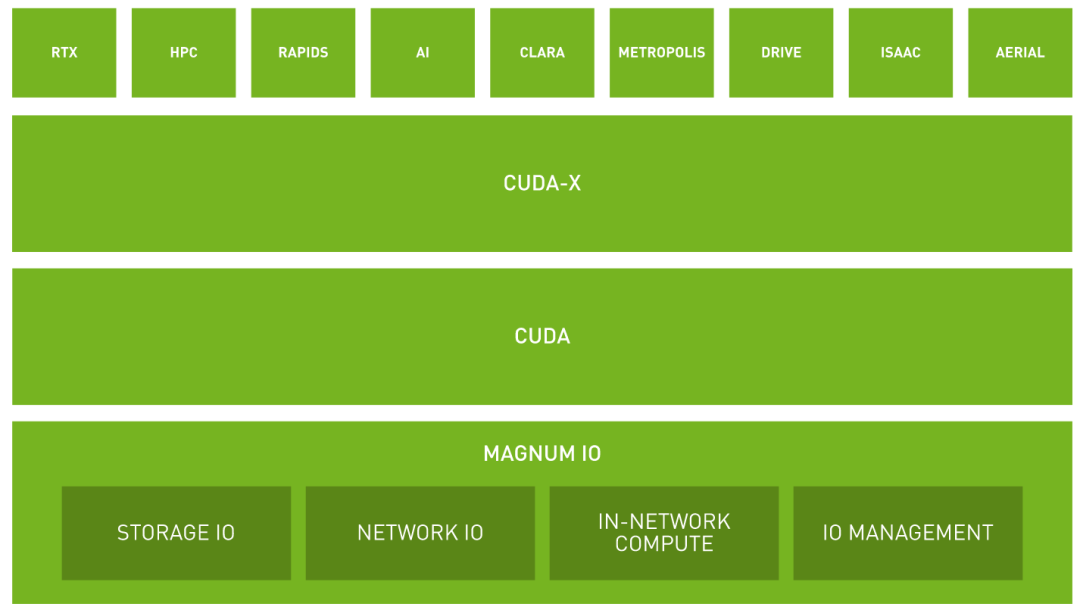
Magnum IO四大核心組件:Storage IO、Network IO、In-Network Compute和IO Management。這幾大組件都是GPU Direct的一部分,或者是支撐GPU Direct運行的保障體系。GPU Direct是Nvidia開發的一種技術,可實現GPU與其他設備(例如主機內存、其他GPU、網絡接口卡NIC或存儲設備)之間的直接通信和數據傳輸,而不涉及CPU。
往期推薦
一文解讀DeepSeek在保險業的應用-CSDN博客
一文解讀DeepSeek在銀行業的應用_deepseek在銀行的應用-CSDN博客
一文解讀DeepSeek大模型在政府工作中具體的場景應用_大模型會議紀要場景-CSDN博客
一文解讀DeepSeek大模型在政務服務領域的應用-CSDN博客
一文解讀DeepSeek在工業制造領域的應用-CSDN博客
一文解讀DeepSeek的安全風險、挑戰與應對策略_deepseek的發展帶來的風險與挑戰-CSDN博客




)
---java版)


:操作系統)










