1、氣泡圖
使用氣泡圖分析某一年中國同歐洲各國之間的貿易情況。
氣泡圖分析的三個維度:
? 進口額:橫軸
? 出口額:縱軸
? 進出口總額:氣泡大小
數據來源:鏈接: 國家統計局數據
數據概覽(進出口總額,進口總額和出口總額數據格式與總額類似)
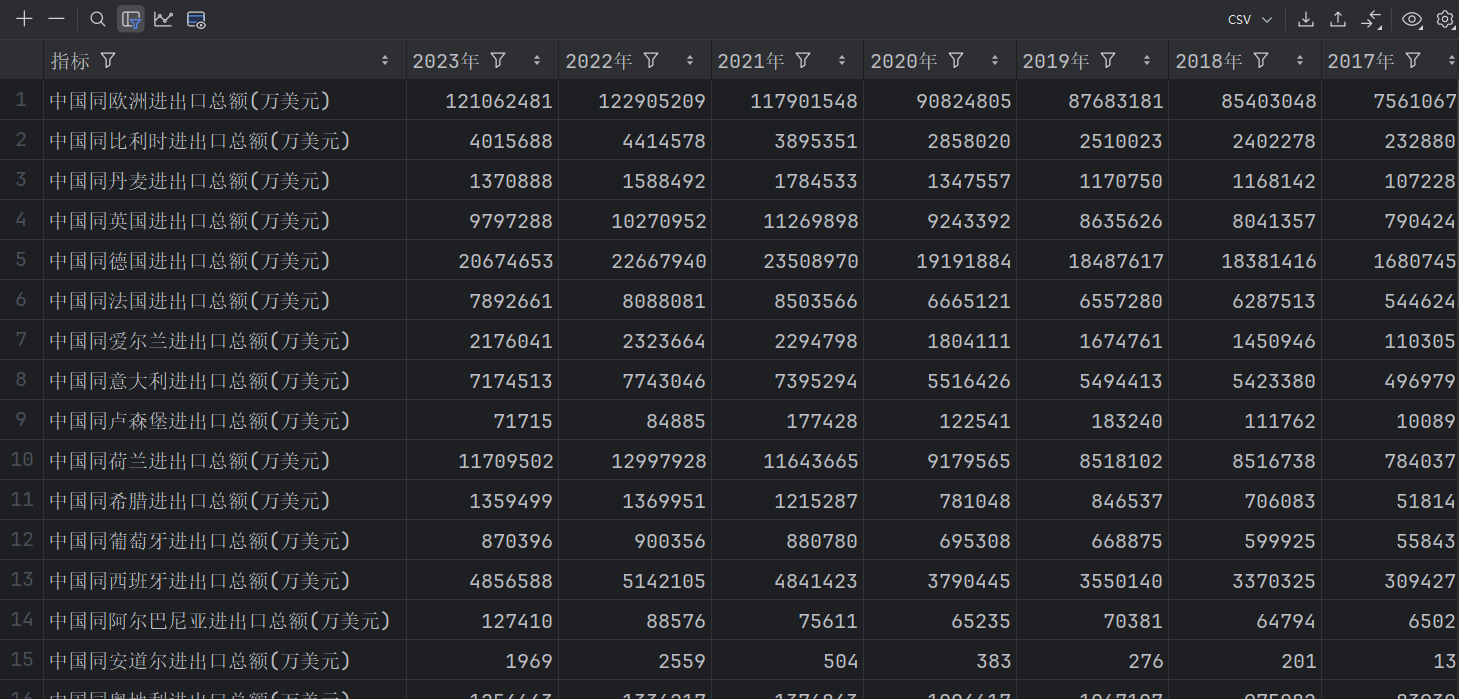
(1)數據預處理
1. 知識點:
- 通過 .str 來調用字符串處理方法
- extract 方法的作用是根據指定的正則表達式模式,從字符串中提取出符合模式的部分。它會返回一個新的 DataFrame 或者 Series
- 正則表達式 r’同(.*?)進出口總額’:整體意思是捕獲 “同” 后面直到遇到 “進出口總額” 之前的任意字符內容。
2. 代碼:
#數據預處理:填充缺失值、提取國家名稱
# 提取國家名稱替換 country 列
df['country'] = df['country'].str.extract(r'同(.*?)進出口總額')
# 將 input 列中的缺失值用 0 填充
df['input'] = df['input'].fillna(0)
# 將結果保存為 Excel 文件
df.to_excel('/初始數據_2023_預處理.xlsx', index=False)
3. 結果:
備注:刪除 “歐洲” 這樣一行數據,避免造成數據量級差別較大造成的不美觀
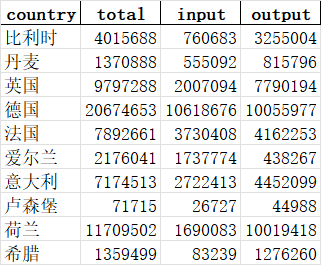
(2)可視化
1. 知識點:
- plt.cm.tab20:cm 是 matplotlib 中顏色映射(colormap)模塊。tab20 是 matplotlib 內置的一種顏色映射表,它包含 20 種不同的顏色 ,這些顏色在視覺上有較好的區分度,適用于區分多個類別。
- linspace 函數用于在指定的區間內生成均勻間隔的數值序列。
- 使用plotly.express繪制氣泡圖并添加懸停提示
2. 代碼:
import pandas as pd
import plotly.express as px
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import numpy as np# 讀取Excel文件數據
df = pd.read_excel('初始數據_2023_預處理.xlsx', engine='openpyxl')# 使用seaborn設置風格
sns.set_style("whitegrid")# 自定義顏色映射
colors = plt.cm.tab20(np.linspace(0, 5, len(df)))
cmap = ListedColormap(colors)# 使用plotly.express繪制氣泡圖并添加懸停提示
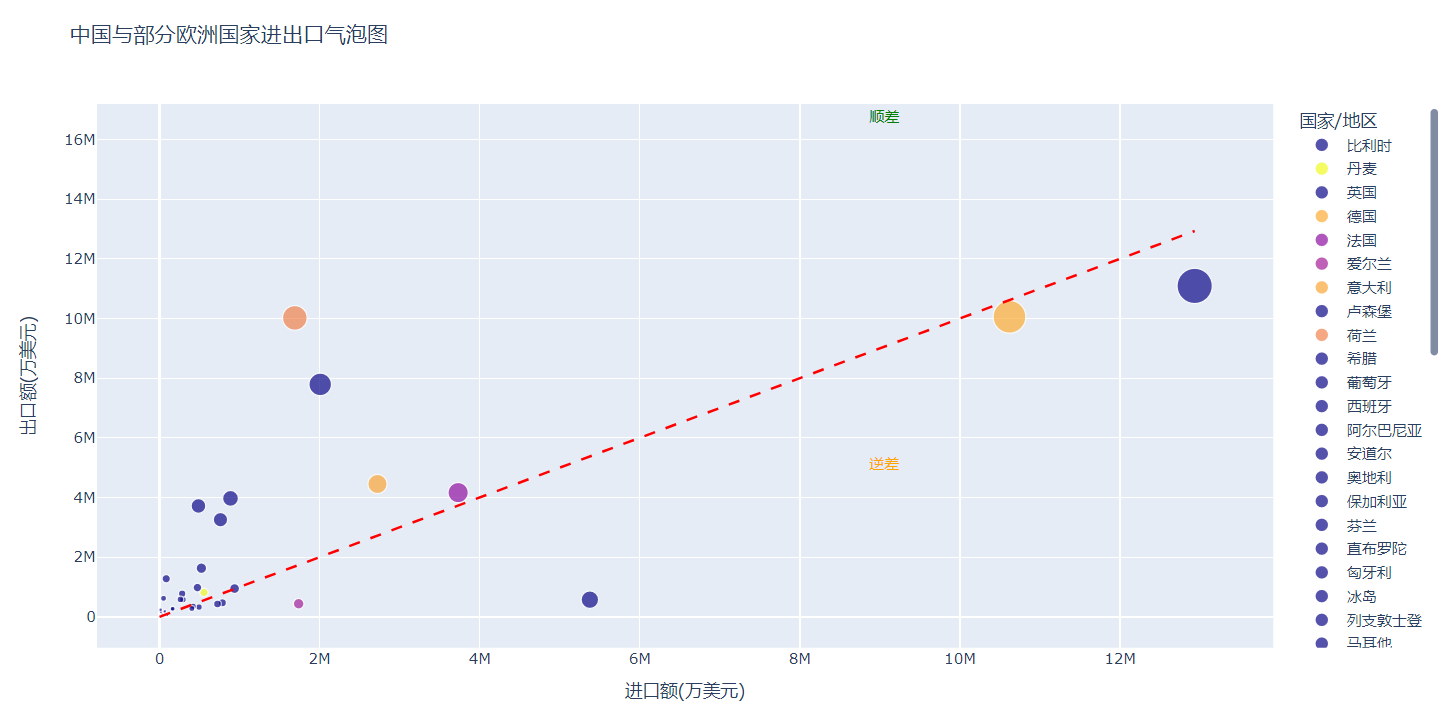
fig = px.scatter(df, x='input', y='output', size='total',color='country',color_discrete_sequence=cmap.colors,labels={'input': '進口額(萬美元)', 'output': '出口額(萬美元)', 'total': '進出口總額(萬美元)','country': '國家/地區'},title='中國與部分歐洲國家進出口氣泡圖')
# 更新標記點為圓形
fig.update_traces(marker=dict(symbol='circle'))# 添加進出口平衡輔助線
fig.add_shape(type="line",x0=df['input'].min(), # 輔助線起點x坐標為進口額最小值y0=df['input'].min(), # 輔助線起點y坐標(與進口額相等,保證在平衡線上 )x1=df['input'].max(), # 輔助線終點x坐標為進口額最大值y1=df['input'].max(), # 輔助線終點y坐標(與進口額相等,保證在平衡線上 )line=dict(color="red", # 輔助線顏色設為紅色width=2,dash="dash" # 輔助線樣式設為虛線)
)# 為順差區域添加注釋
fig.add_annotation(xref="x",yref="y",x=df['input'].max() * 0.7, # 注釋x坐標位置y=df['input'].max() * 1.3, # 注釋y坐標位置text="順差", # 注釋文本font=dict(size=12,color="green" # 注釋文字顏色),showarrow=False # 不顯示箭頭
)# 為逆差區域添加注釋
fig.add_annotation(xref="x",yref="y",x=df['input'].max() * 0.7,y=df['input'].max() * 0.4,text="逆差",font=dict(size=12,color="orange"),showarrow=False
)# 顯示圖形
fig.show()
3. 結果:
2、動態氣泡圖:
(1)數據預處理
1. 知識點:
- melt 函數用于將數據從寬格式轉換為長格式
- id_vars=[‘指標’] :指定在重塑過程中保持不變的列,這里 ‘指標’ 列的內容會被保留。
- var_name=‘年份’ :將原來寬格式數據中的列名(除 id_vars 列外)轉換為長格式中的一列,并將該列命名為 ‘年份’ 。
- value_name=‘進出口總額’ :將原來寬格式數據中對應的值轉換為長格式中的一列,并將該列命名為 ‘進出口總額’ 。通過這一步,數據的結構變得更便于后續分析。
- 提取年份中的數字并轉換類型
- df_total[‘年份’].str.extract(‘(\d+)’) :使用 str.extract 方法,結合正則表達式 (\d+) 從 ‘年份’ 列的字符串中提取連續的數字部分。(\d+) 表示捕獲一個或多個數字。
- .astype(int) :將提取出的數字字符串轉換為整數類型,這樣 ‘年份’ 列的數據類型就變為整數,方便后續進行數值相關的操作或分析。
- dropna 函數用于刪除包含缺失值的行。subset=[‘國家’] 表示只檢查 ‘國家’ 這一列,如果這一列存在缺失值(NaN ),則刪除對應的行。這樣可以保證數據集中的 ‘國家’ 列沒有缺失值,使后續基于該列的分析更加可靠。
2. 代碼:
import pandas as pdpd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
# 讀取數據
def read_data():# 讀取出口數據df_export = pd.read_csv('年度數據(1).csv', encoding='utf-8')df_export = df_export.melt(id_vars=['指標'], var_name='年份', value_name='出口額')df_export['年份'] = df_export['年份'].str.extract('(\d+)').astype(int)df_export['國家'] = df_export['指標'].str.extract('中國向(.*?)出口總額')df_export = df_export.dropna(subset=['國家'])# 讀取進口數據df_import = pd.read_csv('年度數據(2).csv', encoding='utf-8')df_import = df_import.melt(id_vars=['指標'], var_name='年份', value_name='進口額')df_import['年份'] = df_import['年份'].str.extract('(\d+)').astype(int)df_import['國家'] = df_import['指標'].str.extract('中國從(.*?)進口總額')df_import = df_import.dropna(subset=['國家'])# 讀取進出口總額數據df_total = pd.read_csv('年度數據.csv', encoding='utf-8')df_total = df_total.melt(id_vars=['指標'], var_name='年份', value_name='進出口總額')df_total['年份'] = df_total['年份'].str.extract('(\d+)').astype(int)df_total['國家'] = df_total['指標'].str.extract('中國同(.*?)進出口總額')df_total = df_total.dropna(subset=['國家'])# 合并數據df = pd.merge(df_export, df_import, on=['國家', '年份'])df = pd.merge(df, df_total, on=['國家', '年份'])# 計算貿易差額df['貿易差額'] = df['出口額'] - df['進口額']df['順差/逆差'] = df['貿易差額'].apply(lambda x: '順差' if x > 0 else '逆差')return df# 讀取數據
df = read_data()# 將 DataFrame 存儲為 CSV 文件
df.to_csv('中國進出口貿易數據.csv', index=False, encoding='utf-8-sig') # utf-8-sig 支持 Excel 中文顯示
print("\n數據已保存到 '中國進出口貿易數據.csv'")
3. 結果:
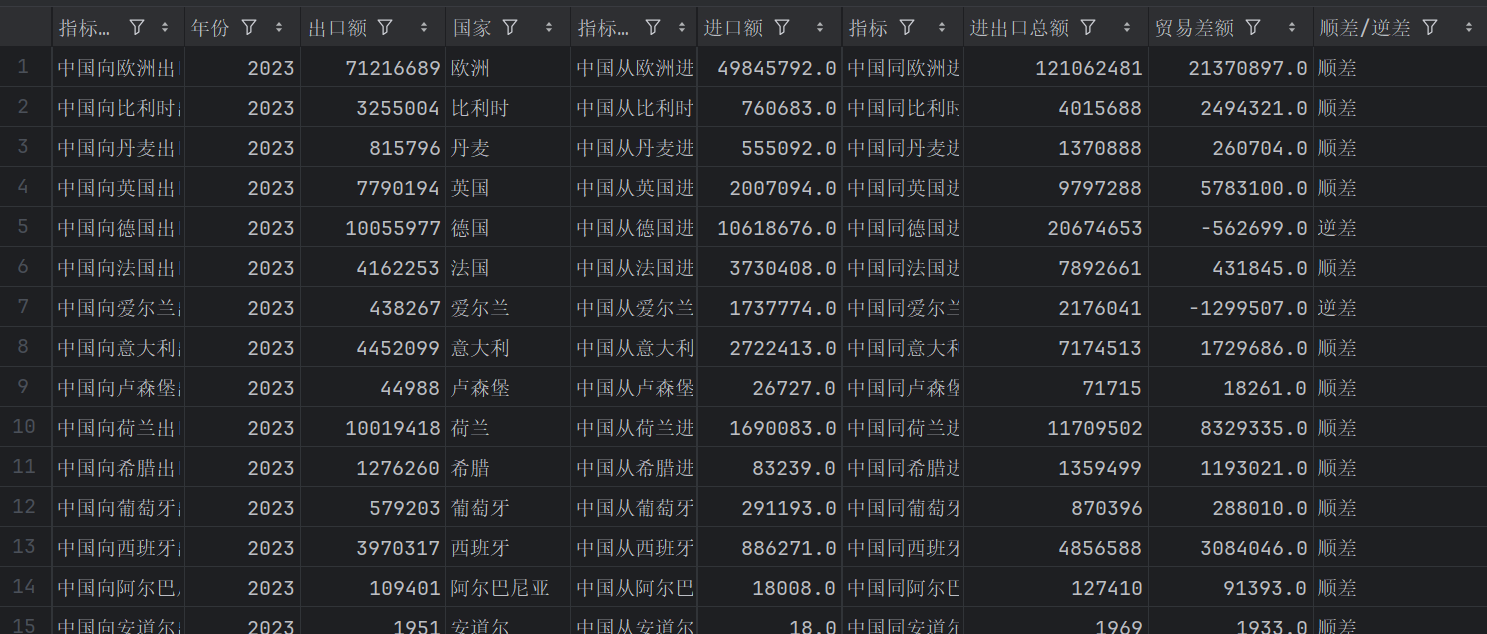
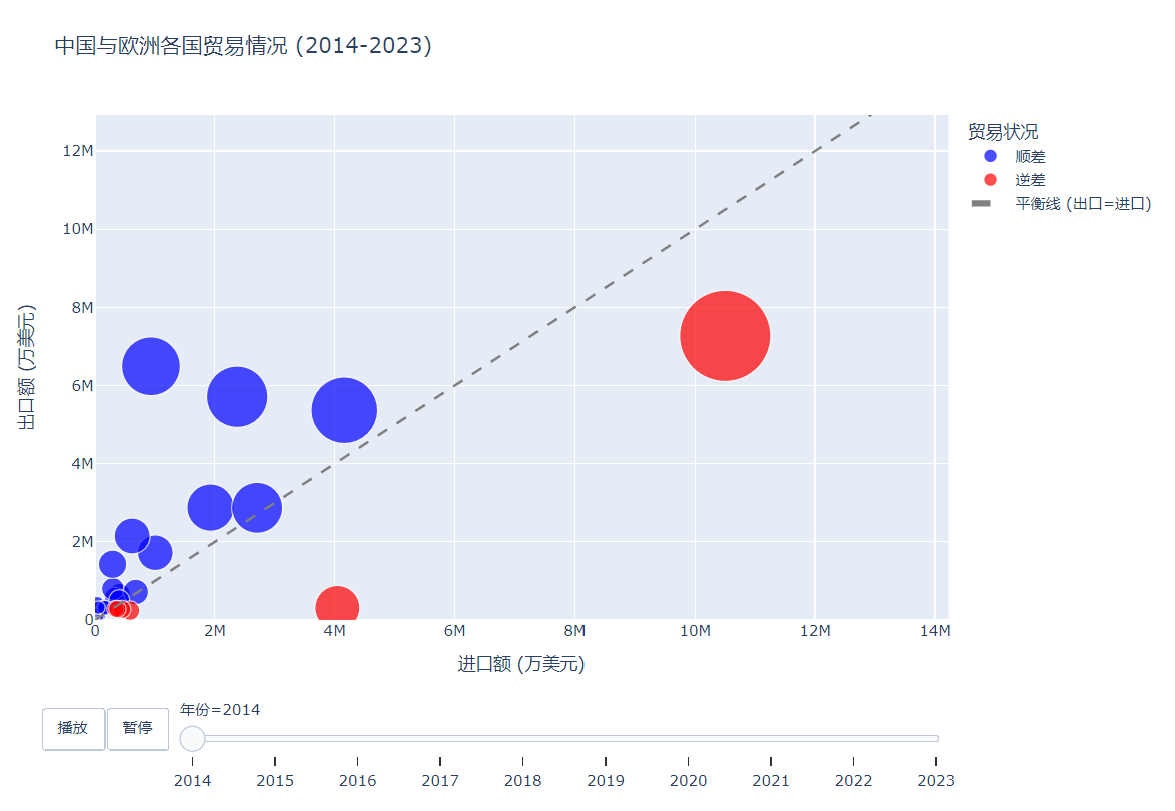
(2)可視化V1 —— 展示貿易順差/逆差隨著年份的變化
1. 實現步驟
a. 數據分組:
函數 create_bubble_chart 接受一個 DataFrame 對象 df 作為輸入。
使用 groupby 方法按 ‘年份’ 和 ‘國家’ 對數據進行分組,然后使用 agg 方法對分組后的數據進行聚合操作:
‘出口額’、‘進口額’、‘進出口總額’ 和 ‘貿易差額’ 列使用 ‘sum’ 方法進行求和。
‘順差/逆差’ 列使用 ‘first’ 方法,即取每組中的第一個值(假設每組中該值是相同的)。
最后使用 reset_index 方法重置索引,使分組的 ‘年份’ 和 ‘國家’ 變為普通列。
df_grouped = df.groupby(['年份', '國家']).agg({'出口額': 'sum','進口額': 'sum','進出口總額': 'sum','貿易差額': 'sum','順差/逆差': 'first'}).reset_index()
b. 創建氣泡圖
使用 plotly.express 庫的 scatter 函數創建一個散點圖(氣泡圖):
x 和 y 分別指定為 ‘進口額’ 和 ‘出口額’ 列。
size 指定為 ‘進出口總額’ 列,用于表示氣泡的大小。
color 指定為 ‘順差/逆差’ 列,用于根據貿易狀況給氣泡上色。
hover_name 指定為 ‘國家’ 列,當鼠標懸停在氣泡上時顯示國家名稱。
animation_frame 指定為 ‘年份’ 列,使圖表按年份進行動態變化。
animation_group 指定為 ‘國家’ 列,確保每個國家的數據在動畫中保持一致。
size_max 設置氣泡的最大大小為 60。
range_x 和 range_y 設置 x 軸和 y 軸的范圍,分別為進口額和出口額最大值的 1.1 倍。
labels 字典用于自定義圖表中各軸和圖例的標簽。
title 設置圖表的標題。
color_discrete_map 字典指定了 ‘順差’ 和 ‘逆差’ 對應的顏色。
fig = px.scatter(df_grouped,x="進口額",y="出口額",size="進出口總額",color="順差/逆差",hover_name="國家",animation_frame="年份",animation_group="國家",size_max=60,range_x=[0, df_grouped['進口額'].max() * 1.1],range_y=[0, df_grouped['出口額'].max() * 1.1],labels={"進口額": "進口額 (萬美元)","出口額": "出口額 (萬美元)","進出口總額": "進出口總額","順差/逆差": "貿易狀況"},title="中國與歐洲各國貿易情況 (2014-2023)",color_discrete_map={"順差": "blue","逆差": "red"})
c. 添加輔助線
for frame in fig.frames::這是一個循環,遍歷 fig(即創建的氣泡圖對象)中的每一個 frame(幀)。因為這個氣泡圖是動態的,按年份作為動畫幀展示數據變化,所以這里要對每一個幀都添加輔助線,以保證在動畫的每一幀中都能顯示平衡線。
frame.data += (…):frame.data 表示每一幀中的數據集合,這里使用 += 操作符向每一幀的數據集合中添加一個新的 go.Scatter 對象。
go.Scatter 對象用于創建一個散點圖(在這里用于創建一條線):
x=[0, max_value] 和 y=[0, max_value]:指定了這條線的起點 (0, 0) 和終點 (max_value, max_value),這樣就形成了 y = x 的直線。
mode=‘lines’:表示這個 go.Scatter 對象的模式是繪制線。
line=dict(color=‘gray’, dash=‘dash’):設置線的屬性,顏色為灰色,樣式為虛線。
name=‘平衡線 (出口=進口)’:給這條線命名為 ‘平衡線 (出口=進口)’,用于標識這條線的含義。
showlegend=False:設置這條線不顯示在圖例中,因為這條輔助線主要是為了視覺上的參考,不需要在圖例中占據空間。
# 獲取最大值的110%用于輔助線 這樣可以確保所有的數據點都在輔助線所界定的區域內顯示,使圖表更加完整和美觀
max_value = max(df_grouped['進口額'].max(), df_grouped['出口額'].max()) * 1.1# 添加輔助線 (y = x)
for frame in fig.frames:frame.data += (go.Scatter(x=[0, max_value],y=[0, max_value],mode='lines',line=dict(color='gray', dash='dash'),name='平衡線 (出口=進口)',showlegend=False
d. 更新布局
- hovermode 用于設置當鼠標懸停在圖形上時的交互模式。這里設置為 “closest”,表示當鼠標懸停在圖表上時,會顯示離鼠標位置最近的數據點的詳細信息(例如國家名稱、進口額、出口額等,這些信息是在創建氣泡圖時通過 hover_name 等參數設置的)。
- updatemenus 用于在圖形中添加一些交互按鈕或菜單。這里創建了一個類型為 “buttons” 的 updatemenus,即添加按鈕。
buttons 是一個列表,用于定義按鈕的具體屬性。這里列表中只有一個按鈕,通過 dict 來設置按鈕的屬性。
label=“播放” 設置按鈕的顯示文本為 “播放”。
method=“animate” 表示當點擊這個按鈕時,執行的操作是啟動動畫。
args 是傳遞給 animate 方法的參數。[None, {“frame”: {“duration”: 1000, “redraw”: True}, “fromcurrent”: True}] 中,None 表示不指定特定的幀序列來播放動畫;{“frame”: {“duration”: 1000, “redraw”: True}, “fromcurrent”: True} 表示設置動畫幀的持續時間為 1000 毫秒,并且在播放動畫時重新繪制圖形(redraw": True),同時從當前幀開始播放動畫(“fromcurrent”: True)。
fig.update_layout(xaxis_title="進口額 (萬美元)",yaxis_title="出口額 (萬美元)",legend_title="貿易狀況",hovermode="closest",transition={'duration': 1000},updatemenus=[dict(type="buttons",buttons=[dict(label="播放",method="animate",args=[None, {"frame": {"duration": 1000, "redraw": True}, "fromcurrent": True}]),dict(label="暫停",method="animate",args=[[None], {"frame": {"duration": 0, "redraw": False}, "mode": "immediate","transition": {"duration": 0}}])])])
e. 添加初始輔助線
fig.add_trace(…):
fig 是 plotly 里的圖形對象,代表了整個圖表。add_trace 方法的作用是往圖表里添加一個新的繪圖軌跡(trace)。繪圖軌跡可以理解成圖表中的一個獨立繪圖元素,例如散點圖、折線圖等。這里添加的是一條直線。
fig.add_trace(go.Scatter(x=[0, max_value],y=[0, max_value],mode='lines',line=dict(color='gray', dash='dash'),name='平衡線 (出口=進口)'))
3. 結果
圖片:
視頻:
動態氣泡圖_順逆差
(3)可視化V1
1. 改進
體現具體國家而不僅僅是順逆差
2. 結果
動態氣泡圖_彩色
3、桑基圖 Sankey diagram:分析與可視化不同因素之間的關系,借助繪制桑基圖來呈現這些因素之間的關聯和流動情況
(1)桑基圖簡介
- 組成要素
- 節點:代表不同的類別或狀態,通常用矩形或其他形狀表示。例如,在能源流動的桑基圖中,節點可以是不同的能源來源(如煤炭、石油、天然氣)和能源使用部門(如工業、交通、居民生活)。
- 邊或流線:連接節點的線條,用于表示數據的流動方向和數量。邊的寬度與所代表的數據量成正比,因此可以直觀地看出不同路徑上數據的相對大小。
- 特點
- 可視化數據流動:能夠清晰地展示數據從一個狀態或類別到另一個狀態或類別的流動過程,使復雜的流程和關系變得直觀易懂。
- 定量展示:通過邊的寬度準確地展示數據的數量,讓觀眾可以直觀地比較不同部分的數據大小,了解各部分在整體中所占的比例。
- 整體守恒:桑基圖中所有流入節點的流量總和等于所有流出節點的流量總和,體現了數據在整個系統中的守恒關系,有助于分析數據在各個環節的分配和轉化情況。
(2)數據集
- credit_record.csv
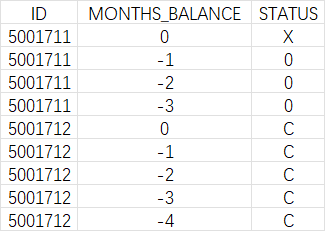
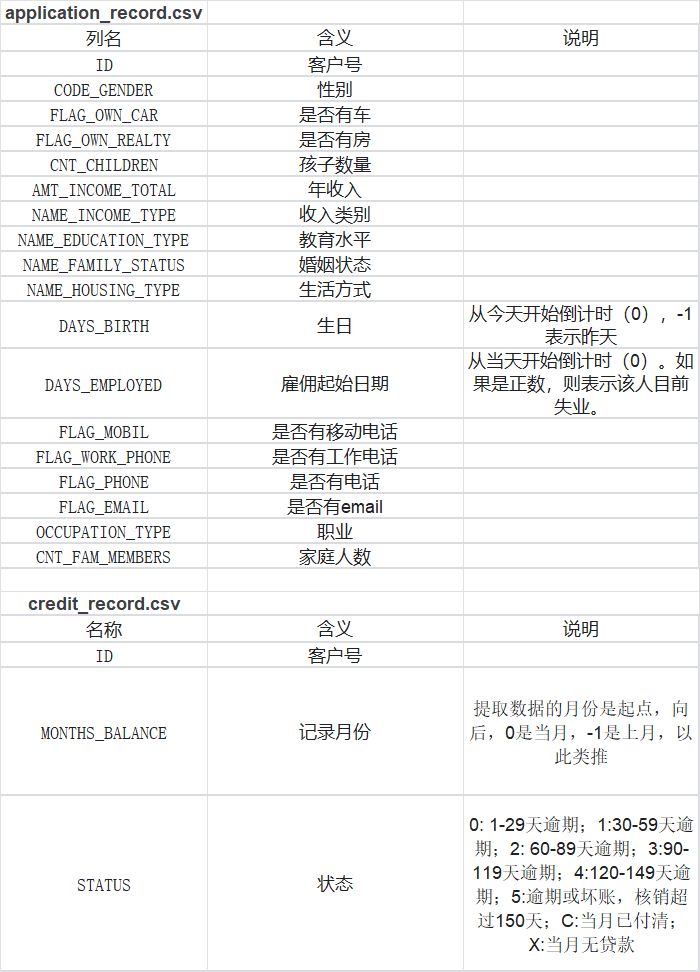
- application_record.csv:

- 數據說明:
(3)實現步驟
1.導入包、讀取數據
import pandas as pd
import plotly.graph_objects as go# 讀取數據
app = pd.read_csv("application_record.csv")
credit = pd.read_csv("credit_record.csv")
2.定義函數用于信用狀態分類——優先考慮逾期情況最嚴重的狀態
- 如果列表中有多種狀態,首先使用 any(s in [‘1’, ‘2’, ‘3’, ‘4’, ‘5’] for s in status_list) 判斷列表中是否存在逾期狀態(‘1’ 到 ‘5’)。any() 函數用于判斷可迭代對象中是否有任何一個元素滿足條件。
- 如果存在逾期狀態,優先考慮逾期最嚴重的情況,按照逾期天數從多到少的順序進行判斷,返回對應的信用狀態分類描述
- 如果列表中不存在逾期狀態,使用 all(s in [‘C’, ‘0’] for s in status_list) 判斷列表中的所有狀態是否都為 ‘C’(本月已還清)或 ‘0’(逾期 1 - 29 天)。
- all() 函數用于判斷可迭代對象中的所有元素是否都滿足條件。 如果是,則返回 ‘Paid off’ 表示已還清。
- credit.groupby(‘ID’) 按照用戶 ID 對信用記錄數據 credit 進行分組。
.apply(classify_credit_status) 對每個分組應用 classify_credit_status 函數,得到每個用戶的信用狀態分類結果。
.reset_index() 重置索引,將結果轉換為一個數據框。
credit_status.columns = [‘ID’, ‘CREDIT_STATUS’] 為數據框的列設置名稱,分別為 ‘ID’ 和 ‘CREDIT_STATUS’。
f classify_credit_status(group):status_list = group['STATUS'].tolist()# 如果列表中只有一種狀態,直接返回該狀態對應的分類if len(set(status_list)) == 1:status = status_list[0]if status == '0':return '1-29 days due'elif status == '1':return '30-59 days due'elif status == '2':return '60-89 days due'elif status == '3':return '90-119 days due'elif status == '4':return '120-149 days due'elif status == '5':return 'Over 150 days due or bad debt'elif status == 'C':return 'Paid off this month'elif status == 'X':return 'No loan this month'# 如果列表中有多種狀態,需要根據規則判斷else:if any(s in ['1', '2', '3', '4', '5'] for s in status_list):# 優先考慮逾期嚴重的情況if '5' in status_list:return 'Over 150 days due or bad debt'elif '4' in status_list:return '120-149 days due'elif '3' in status_list:return '90-119 days due'elif '2' in status_list:return '60-89 days due'elif '1' in status_list:return '30-59 days due'elif all(s in ['C', '0'] for s in status_list):return 'Paid off'elif 'X' in status_list:return 'No loan this month'else:return 'Complex status'credit_status = credit.groupby('ID').apply(classify_credit_status).reset_index()
credit_status.columns = ['ID', 'CREDIT_STATUS']3.合并數據
merged = pd.merge(app, credit_status, on='ID')
4.創建字段
依據 FLAG_OWN_REALTY 列創建新列 OWN_REALTY,將 Y 映射為 Yes Property,N 映射為 No Property。
merged['OWN_REALTY'] = merged['FLAG_OWN_REALTY'].map({'Y': 'Yes Property', 'N': 'No Property'})
5.選取需要的字段
df = merged[['NAME_HOUSING_TYPE', 'NAME_INCOME_TYPE', 'OWN_REALTY', 'CREDIT_STATUS']]
6.匯總數據
按照 NAME_HOUSING_TYPE、NAME_INCOME_TYPE、OWN_REALTY 和 CREDIT_STATUS 進行分組,統計每組的數量,將結果保存到 count 列。
df_grouped = df.groupby(['NAME_HOUSING_TYPE', 'NAME_INCOME_TYPE', 'OWN_REALTY', 'CREDIT_STATUS']).size().reset_index(name='count')
7.設置標簽和映射
labels:將所有可能的標簽(房屋類型、收入類型、是否擁有房產、信用狀態)合并,去除重復項后轉換為列表。
label_index:創建一個字典,將每個標簽映射到一個唯一的索引。
labels = pd.concat([df_grouped['NAME_HOUSING_TYPE'], df_grouped['NAME_INCOME_TYPE'],df_grouped['OWN_REALTY'], df_grouped['CREDIT_STATUS']]).unique().tolist()
label_index = {label: i for i, label in enumerate(labels)}
8.構建鏈接
source、target 和 value:分別代表桑基圖中鏈接的起始節點索引、結束節點索引和鏈接的值(即每組的數量)。
通過三次循環構建三組鏈接:房屋類型到收入類型、收入類型到是否擁有房產、是否擁有房產到信用狀態。
source = []
target = []
value = []# Housing ? Income Type
for _, row in df_grouped.iterrows():source.append(label_index[row['NAME_HOUSING_TYPE']])target.append(label_index[row['NAME_INCOME_TYPE']])value.append(row['count'])# Income Type ? Own Realty
for _, row in df_grouped.iterrows():source.append(label_index[row['NAME_INCOME_TYPE']])target.append(label_index[row['OWN_REALTY']])value.append(row['count'])# Own Realty ? Credit Status
for _, row in df_grouped.iterrows():source.append(label_index[row['OWN_REALTY']])target.append(label_index[row['CREDIT_STATUS']])value.append(row['count'])
9.繪制桑基圖
go.Sankey:創建一個桑基圖對象。
node:設置節點的屬性,如節點間距、厚度、線條顏色和寬度、標簽等。
link:設置鏈接的屬性,如起始節點索引、結束節點索引和鏈接的值。
fig.update_layout:更新圖表的布局,設置標題和字體大小。
fig.show():顯示桑基圖。
fig = go.Figure(data=[go.Sankey(node=dict(pad=15,thickness=20,line=dict(color="black", width=0.5),label=labels),link=dict(source=source,target=target,value=value))])fig.update_layout(title_text="House Type ? Income Type ? Owns Property ? Credit Status", font_size=12)
fig.show()
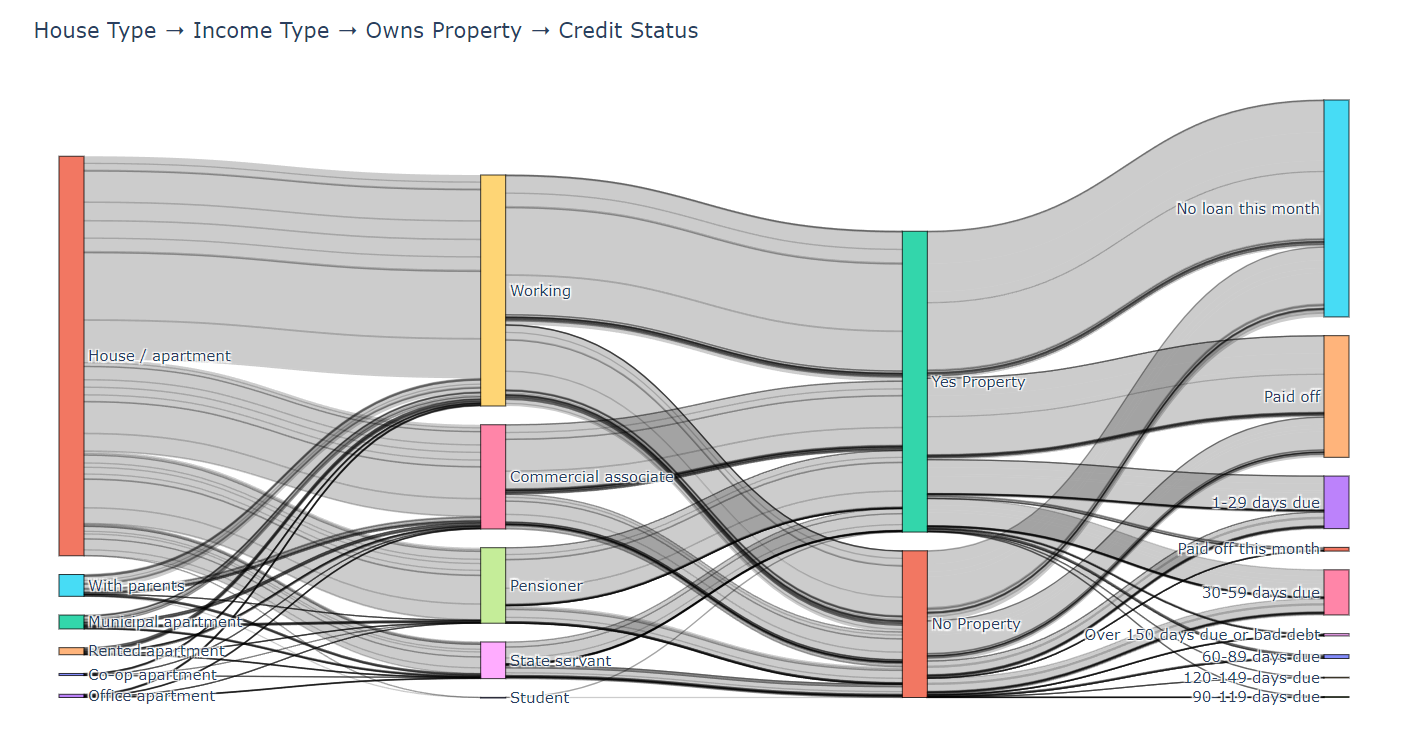
(4)結果
- House Type → Income Type → Owns Property → Credit Status
4、桑基圖2
同理根據以下代碼繪制結果如圖
import pandas as pd
import plotly.graph_objects as go# 讀取數據
app = pd.read_csv("application_record.csv")
credit = pd.read_csv("credit_record.csv")# 一、處理收入分組
def map_income_level(income):if income < 50000:return "Very Low income"elif income < 100000:return "Low income"elif income < 150000:return "Lower - middle income"elif income < 200000:return "Middle income"elif income < 300000:return "Upper - middle income"elif income < 400000:return "Moderate - high income"elif income < 600000:return "High income"else:return "Very High income"app["INCOME_LEVEL"] = app["AMT_INCOME_TOTAL"].apply(map_income_level)# 二、處理信用記錄中的月收支平衡時間段
def map_month_balance(group):earliest = group['MONTHS_BALANCE'].min()if earliest >= -6:return "Within 6 months"elif earliest >= -12:return "6 - 12 months ago"elif earliest >= -24:return "1 - 2 years ago"elif earliest >= -36:return "2 - 3 years ago"elif earliest >= -48:return "3 - 4 years ago"elif earliest >= -60:return "4 - 5 years ago"else:return "Over 5 years ago"credit_time = credit.groupby('ID').apply(map_month_balance).reset_index()
credit_time.columns = ['ID', 'MONTH_BALANCE_GROUP']# 三、合并數據
merged = pd.merge(app, credit_time, on='ID')# 四、選取需要的字段
df = merged[['CODE_GENDER', 'INCOME_LEVEL', 'NAME_EDUCATION_TYPE', 'NAME_FAMILY_STATUS', 'MONTH_BALANCE_GROUP']]# 五、分組統計
df_grouped = df.groupby(['CODE_GENDER', 'INCOME_LEVEL', 'NAME_EDUCATION_TYPE', 'NAME_FAMILY_STATUS', 'MONTH_BALANCE_GROUP']).size().reset_index(name='count')# 六、構建節點標簽及索引映射
labels = pd.concat([df_grouped['CODE_GENDER'],df_grouped['INCOME_LEVEL'],df_grouped['NAME_EDUCATION_TYPE'],df_grouped['NAME_FAMILY_STATUS'],df_grouped['MONTH_BALANCE_GROUP']
]).unique().tolist()label_index = {label: i for i, label in enumerate(labels)}# 七、構建桑基圖的 source、target、value
source, target, value = [], [], []# Gender ? Income Level
for _, row in df_grouped.iterrows():source.append(label_index[row['CODE_GENDER']])target.append(label_index[row['INCOME_LEVEL']])value.append(row['count'])# Income Level ? Education Level
for _, row in df_grouped.iterrows():source.append(label_index[row['INCOME_LEVEL']])target.append(label_index[row['NAME_EDUCATION_TYPE']])value.append(row['count'])# Education Level ? Marital Status
for _, row in df_grouped.iterrows():source.append(label_index[row['NAME_EDUCATION_TYPE']])target.append(label_index[row['NAME_FAMILY_STATUS']])value.append(row['count'])# Marital Status ? Month Balance
for _, row in df_grouped.iterrows():source.append(label_index[row['NAME_FAMILY_STATUS']])target.append(label_index[row['MONTH_BALANCE_GROUP']])value.append(row['count'])# 八、繪制桑基圖
fig = go.Figure(data=[go.Sankey(node=dict(pad=15,thickness=20,line=dict(color="black", width=0.5),label=labels),link=dict(source=source,target=target,value=value))])fig.update_layout(title_text="Gender / Income Level / Education Level / Marital Status / Month Balance",font_size=12,height=700
)
fig.show()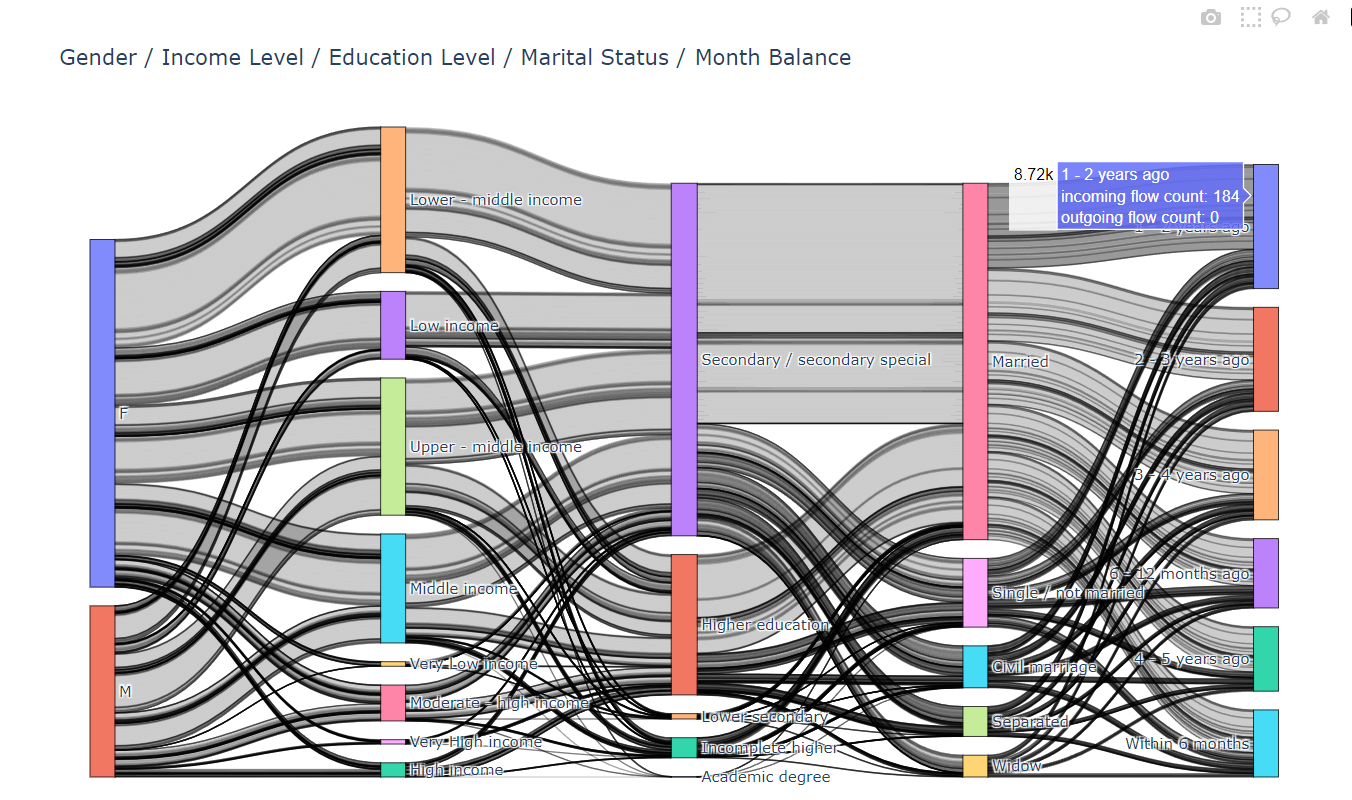
5、存在的問題——信用狀態的判斷
-
最近一個月的信用狀態?
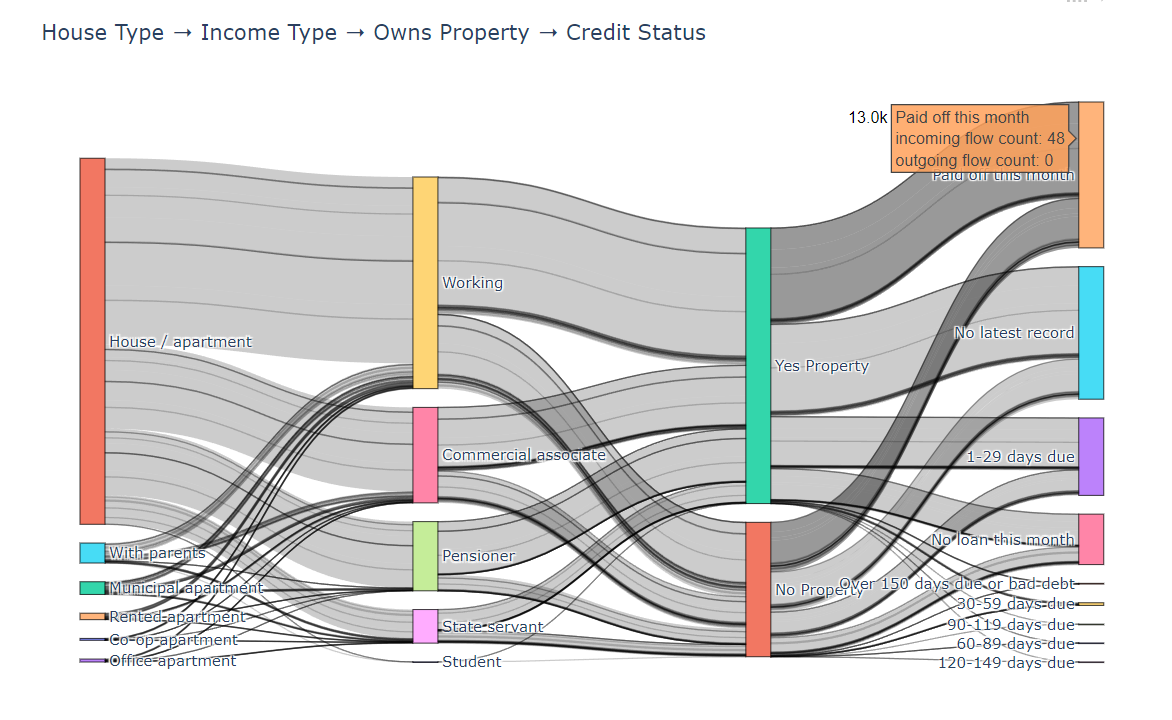
-
逾期最嚴重的信用狀態?
# 圖2 House Type → Income Type → Owns Property → Credit Statusimport pandas as pd
import plotly.graph_objects as go# 讀取數據
app = pd.read_csv("application_record.csv")
credit = pd.read_csv("credit_record.csv")# 信用狀態分類
def classify_credit_status(group):status_list = group['STATUS'].tolist()# 如果列表中只有一種狀態,直接返回該狀態對應的分類if len(set(status_list)) == 1:status = status_list[0]if status == '0':return '1-29 days due'elif status == '1':return '30-59 days due'elif status == '2':return '60-89 days due'elif status == '3':return '90-119 days due'elif status == '4':return '120-149 days due'elif status == '5':return 'Over 150 days due or bad debt'elif status == 'C':return 'Paid off this month'elif status == 'X':return 'No loan this month'# 如果列表中有多種狀態,需要根據規則判斷else:if any(s in ['1', '2', '3', '4', '5'] for s in status_list):# 優先考慮逾期嚴重的情況if '5' in status_list:return 'Over 150 days due or bad debt'elif '4' in status_list:return '120-149 days due'elif '3' in status_list:return '90-119 days due'elif '2' in status_list:return '60-89 days due'elif '1' in status_list:return '30-59 days due'elif all(s in ['C', '0'] for s in status_list):return 'Paid off'elif 'X' in status_list:return 'No loan this month'else:return 'Complex status'credit_status = credit.groupby('ID').apply(classify_credit_status).reset_index()
credit_status.columns = ['ID', 'CREDIT_STATUS']# 合并
merged = pd.merge(app, credit_status, on='ID')# 創建字段
merged['OWN_REALTY'] = merged['FLAG_OWN_REALTY'].map({'Y': 'Yes Property', 'N': 'No Property'})df = merged[['NAME_HOUSING_TYPE', 'NAME_INCOME_TYPE', 'OWN_REALTY', 'CREDIT_STATUS']]# 匯總
df_grouped = df.groupby(['NAME_HOUSING_TYPE', 'NAME_INCOME_TYPE', 'OWN_REALTY', 'CREDIT_STATUS']).size().reset_index(name='count')# 標簽和映射
labels = pd.concat([df_grouped['NAME_HOUSING_TYPE'], df_grouped['NAME_INCOME_TYPE'],df_grouped['OWN_REALTY'], df_grouped['CREDIT_STATUS']]).unique().tolist()
label_index = {label: i for i, label in enumerate(labels)}# 構建鏈接
source = []
target = []
value = []# Housing ? Income Type
for _, row in df_grouped.iterrows():source.append(label_index[row['NAME_HOUSING_TYPE']])target.append(label_index[row['NAME_INCOME_TYPE']])value.append(row['count'])# Income Type ? Own Realty
for _, row in df_grouped.iterrows():source.append(label_index[row['NAME_INCOME_TYPE']])target.append(label_index[row['OWN_REALTY']])value.append(row['count'])# Own Realty ? Credit Status
for _, row in df_grouped.iterrows():source.append(label_index[row['OWN_REALTY']])target.append(label_index[row['CREDIT_STATUS']])value.append(row['count'])# 繪制桑基圖
fig = go.Figure(data=[go.Sankey(node=dict(pad=15,thickness=20,line=dict(color="black", width=0.5),label=labels),link=dict(source=source,target=target,value=value))])fig.update_layout(title_text="House Type ? Income Type ? Owns Property ? Credit Status", font_size=12)
fig.show()- 所有的信用狀態全部考慮的數據流向和流量是否準確(因為會把重復的用戶計入)
import pandas as pd
import plotly.graph_objects as go# 讀取數據
app = pd.read_csv("application_record.csv")
credit = pd.read_csv("credit_record.csv")# 按 ID 合并數據集
merged = pd.merge(app, credit, on='ID')# 創建新字段 OWN_REALTY
merged['OWN_REALTY'] = merged['FLAG_OWN_REALTY'].map({'Y': 'Yes Property', 'N': 'No Property'})# 定義狀態映射字典
status_mapping = {'0': '1-29 days due','1': '30-59 days due','2': '60-89 days due','3': '90-119 days due','4': '120-149 days due','5': 'Over 150 days due or bad debt','C': 'Paid off this month','X': 'No loan this month'
}# 將 STATUS 列映射為描述性狀態
merged['CREDIT_STATUS'] = merged['STATUS'].map(status_mapping)# 選擇用于繪制桑基圖的列
columns = ['NAME_HOUSING_TYPE', 'NAME_INCOME_TYPE', 'OWN_REALTY', 'CREDIT_STATUS']# 分組統計每個組合的數量
df_grouped = merged.groupby(columns).size().reset_index(name='count')# 生成所有唯一的標簽
labels = pd.concat([df_grouped[col] for col in columns]).unique().tolist()
# 為每個標簽分配一個索引
label_index = {label: i for i, label in enumerate(labels)}# 初始化存儲鏈接信息的列表
source = []
target = []
value = []# 構建所有可能的鏈接
for i in range(len(columns) - 1):for _, row in df_grouped.iterrows():source.append(label_index[row[columns[i]]])target.append(label_index[row[columns[i + 1]]])value.append(row['count'])# 創建桑基圖對象
fig = go.Figure(data=[go.Sankey(node=dict(pad=15,thickness=20,line=dict(color="black", width=0.5),label=labels),link=dict(source=source,target=target,value=value))])# 更新圖表布局,設置標題和字體大小
fig.update_layout(title_text="House Type ? Income Type ? Owns Property ? Credit Status", font_size=12)
# 顯示桑基圖
fig.show()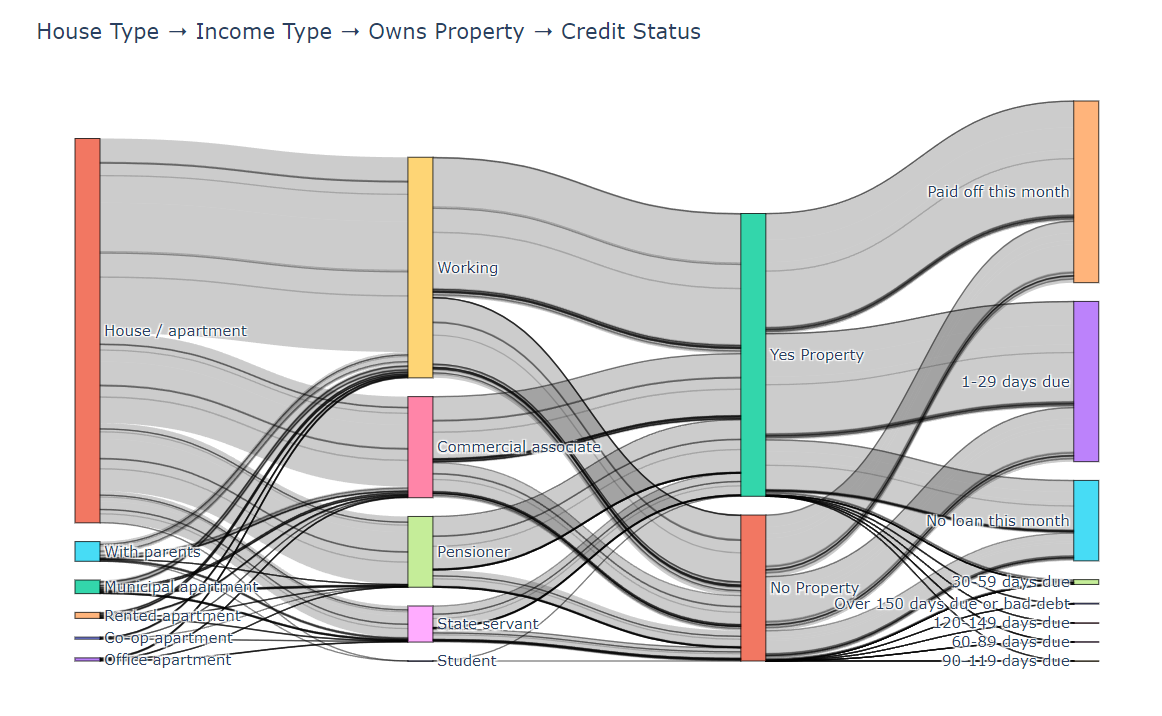
6、相關資料:
鏈接1: 桑基圖
鏈接2: plotly 基本操作手冊
--vue Router(二)導航守衛、路由元信息、路由懶加載、動態路由)

)

![[硬件電路-11]:模擬電路常見元器件 - 什么是阻抗、什么是輸入阻抗、什么是輸出阻抗?阻抗、輸入阻抗與輸出阻抗的全面解析](http://pic.xiahunao.cn/[硬件電路-11]:模擬電路常見元器件 - 什么是阻抗、什么是輸入阻抗、什么是輸出阻抗?阻抗、輸入阻抗與輸出阻抗的全面解析)




)




![[Spring] Sentinel詳解](http://pic.xiahunao.cn/[Spring] Sentinel詳解)




