目錄
一、前言:原生 HBase 查詢的痛點
(一)連接管理混亂,容易造成資源泄露
(二)查詢邏輯重復,缺乏統一的模板
(三)多線程/高并發下的線程安全性隱患
(四)?? 總結一下
二、系統架構總覽
(一)邏輯視圖架構
1. BizService(業務服務層)
2. HBaseTemplate(查詢執行模板)
3. HBaseConnectionFactory(連接管理器)
(二)? 架構設計亮點要求
三、核心實現一:基于 AtomicReference 的連接懶加載機制
(一)為什么選用 AtomicReference 持有連接?
(二)雙重檢查鎖實現懶加載(DCL)
(三)自動重試機制,提高連接穩定性
(四)生命周期管理:@PreDestroy 優雅關閉連接
(五)HBase 配置參數統一集中管理
? 小結:這一層解決了什么問題?
四、核心實現二:函數式接口封裝查詢執行邏輯
(一)目標:讓查詢邏輯像“寫 Lambda 一樣”簡單
(二)函數式接口設計:對標 Spring JdbcTemplate
(三)execute() 模板方法封裝
(四)查詢調用示例:像 Lambda 一樣優雅
(五)支持更細粒度的擴展能力(如 Put/Delete)
五、完整案例演示:從查詢封裝到業務落地
(一)場景說明:根據手機號前綴模糊查找用戶信息
(二)原始寫法:重復 + 冗余 + 難維護
(三)優化后寫法:基于模板封裝
(四)支撐代碼匯總(用于上下文完整性)
1. 用戶實體類 UserInfo
2. HBaseTemplate 示例定義
六、異常處理與重試機制的策略設計
(一)異常類型與分類
(二)重試機制設計
(三)異常類型處理
可重試異常
不可重試異常
(四)結合重試與模板使用
七、性能優化與高可用設計:如何讓查詢模板更高效
(一)查詢性能優化的基本原則
1. 減少不必要的 I/O 操作
2. 使用連接池減少連接創建和銷毀開銷
3. 異步操作與批量操作
(二)高可用性設計
1. 集群容錯與負載均衡
2. 彈性擴展
3. 故障恢復與災難恢復
(三)查詢模板的優化
示例:使用緩存優化查詢
(四)小結:如何提高查詢模板的性能和可用性
八、總結與未來展望:從技術實現到業務落地
(一)設計總結:一個高效且健壯的 HBase 查詢模板
(二)對業務的實際影響
(三)未來展望:進一步優化與發展方向
1. 高級查詢優化
2. 更靈活的查詢策略
3. 異常監控與自動化運維
4. 支持更多數據源和兼容性
(四)小結
干貨分享,感謝您的閱讀!
隨著大數據時代的到來,企業在存儲和處理數據時面臨著越來越多的挑戰。在這其中,HBase 作為一個高性能、可擴展的分布式列式數據庫,在海量數據的存儲和查詢中發揮著重要作用。然而,盡管 HBase 具有極高的查詢性能和可伸縮性,它的使用過程中依然存在一些痛點,特別是在高并發環境下,如何管理連接、優化查詢、確保系統的高可用性,往往需要開發者進行額外的封裝和優化。
傳統的 HBase 查詢方式存在諸多問題,例如連接管理復雜、查詢邏輯重復、性能瓶頸等。這些問題不僅影響開發效率,還可能在業務高峰期間導致系統性能下降,甚至造成不可用的情況。因此,如何在 HBase 的基礎上封裝出一個既高效又易于擴展的查詢模板,成為了許多企業工程師面臨的實際問題。
本文將從一個高效、線程安全且可復用的 HBase 查詢模板的設計與實現入手,深入探討如何解決 HBase 查詢中的常見問題,提升查詢性能,并簡化開發流程。通過基于 AtomicReference 的連接懶加載機制、函數式接口封裝查詢邏輯,以及完整的案例演示,本文將為開發者提供一個可復用的解決方案,幫助他們在復雜業務場景中高效地使用 HBase。
一、前言:原生 HBase 查詢的痛點
在實際業務開發中,使用 HBase 進行數據查詢時,我們往往會遇到一系列令人頭疼的問題:
(一)連接管理混亂,容易造成資源泄露
HBase 的連接是重量級資源,底層維護著 socket、線程池、region cache 等,如果沒有統一管理,每次查詢都創建新連接,很容易導致資源耗盡或者頻繁報錯:
Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("ns:my_table"));
Result result = table.get(new Get(Bytes.toBytes("rowKey")));
table.close();
connection.close(); // 寫不寫?寫早了會影響別的調用?
我們常常會糾結:連接該不該關閉?在哪關閉?有沒有被復用? 這些細節一旦管理不好,就可能引發連接泄露、線程堆積等問題。
(二)查詢邏輯重復,缺乏統一的模板
HBase 查詢語法雖然不復雜,但每次都要寫重復的獲取連接、構建表對象、異常處理、關閉資源,實際業務邏輯反而被掩蓋在大量模板代碼中。例如:
try (Connection conn = getConn(); Table table = conn.getTable(...)) {Result result = table.get(new Get(Bytes.toBytes("row")));// 業務處理
} catch (IOException e) {// 錯誤處理
}
-
這段代碼每個地方幾乎都要復制粘貼
-
錯誤處理方式不統一,日志風格不一致
-
不利于抽象和單元測試
(三)多線程/高并發下的線程安全性隱患
如果 HBase 連接是通過某個 Bean 單例持有的,如何確保線程安全?
原生 Connection 是線程安全的,但一旦你在懶加載或共享使用上沒處理好(比如用普通的 null 判斷),就可能出現競態條件:
if (connection == null) {connection = ConnectionFactory.createConnection(config); // 多線程可能重復初始化
}
高并發場景下,這樣的代碼就可能出現重復連接、甚至初始化失敗,導致業務抖動。
(四)?? 總結一下
| 問題場景 | 描述 |
|---|---|
| 連接創建 | 重復、混亂、易泄露 |
| 查詢代碼 | 冗余、不利維護和測試 |
| 多線程 | 缺乏安全防護,存在競態風險 |
為了解決這些問題,我們有必要設計并封裝了一個具備以下特性的 HBase 查詢模塊:
-
? 使用
AtomicReference實現線程安全的連接懶加載 -
? 封裝模板方法,屏蔽底層連接細節
-
? 自動管理資源關閉,支持 Spring 生命周期
-
? 對異常處理和日志輸出做了統一規范
接下來,我們將一步步拆解這個封裝模塊的核心設計思路和具體實現方式。
二、系統架構總覽
為了實現一個線程安全、可復用、具備連接池特性的 HBase 查詢模板,我們將查詢模塊劃分為三個核心組件,每個組件職責清晰、解耦良好:
(一)邏輯視圖架構
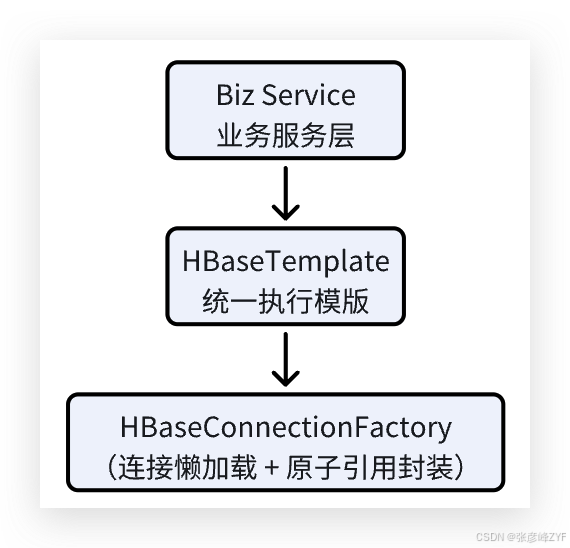
1. BizService(業務服務層)
業務層的具體服務類,只關注業務邏輯,通過模板調用來讀取數據。例如:
-
按 rowKey 查詢用戶得分
-
封裝 rowKey 邏輯、解析數據格式
-
完全不關心連接獲取和關閉等底層細節
這一層體現了高內聚、低耦合的原則,查詢邏輯清晰、可測試。
2. HBaseTemplate(查詢執行模板)
這是我們封裝的核心查詢執行模板,引入了函數式接口 Function<Table, T>,極大簡化調用方式,并集中管理:
-
表的打開與關閉(使用 try-with-resources)
-
異常捕獲與日志統一輸出
-
函數式執行傳入的操作邏輯,靈活又強大
開發者只需關注“我要查什么表、查什么字段”,無需重復編寫資源管理和異常處理代碼。
3. HBaseConnectionFactory(連接管理器)
這是最底層的連接持有者,具備以下關鍵特性:
-
使用
AtomicReference<Connection>實現線程安全懶加載 -
支持配置最大重試次數與重試間隔
-
支持 Spring 生命周期注解
@PreDestroy,實現優雅關閉 -
統一封裝 HBase 配置參數,解耦業務層對配置細節的感知
這部分我們采取?雙重檢查鎖(DCL)+ 原子引用,保證連接初始化只發生一次,同時具備并發安全性。
(二)? 架構設計亮點要求
| 特性 | 說明 |
|---|---|
| 線程安全 | 基于 AtomicReference 和 synchronized 實現安全的懶加載 |
| 復用性 | Connection 和 Template 單例注入,避免重復創建資源 |
| 清晰分層 | 業務邏輯、模板執行、連接管理各自獨立,職責單一 |
| 可測試性 | 各層通過依賴注入隔離,方便 Mock 和單元測試 |
| 可配置性 | 連接參數、重試邏輯均可通過 Spring 配置靈活注入 |
三、核心實現一:基于 AtomicReference 的連接懶加載機制
在高并發、IO 敏感的微服務系統中,連接的創建與管理往往決定了系統的穩定性與性能瓶頸。為此,我們可以通過 AtomicReference<Connection> 結合雙重檢查加鎖,構建了一個線程安全、可懶加載的 HBase 連接池。
(一)為什么選用 AtomicReference 持有連接?
Java 的 AtomicReference<T> 是一種非阻塞式的對象引用容器,具有以下優勢:
-
保證原子性操作(如
get、set) -
可與
synchronized聯合使用,減少鎖粒度 -
避免
volatile配合雙重檢查鎖時的指令重排問題
相比直接用 volatile Connection,AtomicReference 更適合需要頻繁讀取、偶爾寫入的單例資源(如連接、緩存等)。
? 目的:提高并發訪問的安全性,避免重復創建 HBase Connection 對象。
(二)雙重檢查鎖實現懶加載(DCL)
連接的創建使用了標準的“雙重檢查鎖”寫法:
if (connectionRef.get() == null || connectionRef.get().isClosed()) {synchronized (this) {if (connectionRef.get() == null || connectionRef.get().isClosed()) {// 創建連接邏輯...connectionRef.set(connection);}}
}
這段邏輯的重點在于:
| 步驟 | 含義 |
|---|---|
| 外層判斷 | 避免無意義的加鎖,提升并發效率 |
| 內層判斷 | 保證連接真正尚未創建,防止重復初始化 |
| 加鎖粒度 | 只在需要初始化時加鎖,保證效率 |
(三)自動重試機制,提高連接穩定性
連接過程中可能出現網絡抖動、配置錯誤等異常,為此我們需要引入了重試機制:
for (int attempt = 1; attempt <= maxRetry; attempt++) {try {// 嘗試建立連接} catch (IOException e) {// 達到最大重試次數則拋出// 否則 sleep + retry}
}
通過配置參數 apiHbaseConnectionMaxRetry 和 apiHbaseConnectionMaxRetryDelayMillis,開發者可靈活控制重試策略,避免因一時網絡抖動導致系統雪崩。
(四)生命周期管理:@PreDestroy 優雅關閉連接
為了避免應用關閉時 HBase 連接未及時釋放造成資源泄露,我們使用了 Spring 的生命周期注解 @PreDestroy:
@PreDestroy
public void close() {if (connection != null && !connection.isClosed()) {connection.close();}
}
確保在容器銷毀時自動關閉連接,釋放資源,提升系統健壯性。
(五)HBase 配置參數統一集中管理
創建連接時,所有 HBase 所需的配置都統一注入:
config.set(HBASE_ZOOKEEPER_QUORUM_KEY, zyfHbaseConfig.getHbaseZookeeperQuorum());
...
config.set(HBASE_CLIENT_CONNECTION_IMPL, AliHBaseUEClusterConnection.class.getName());
配置信息集中于 ZyfHbaseConfig?類中,做到了參數解耦、配置集中化管理,更易于調試和維護。
? 小結:這一層解決了什么問題?
| 問題 | 原始狀態 | 優化后效果 |
|---|---|---|
| 多線程連接創建 | 可能重復創建多個連接、存在線程安全隱患 | 原子引用 + DCL,線程安全且只創建一次連接 |
| 連接異常不可恢復 | 一次失敗即掛 | 增加重試邏輯,提升系統容錯性 |
| Bean 銷毀連接未關閉 | 容易造成資源泄漏 | 使用 @PreDestroy 優雅關閉 |
| 配置分散、不透明 | 各個類硬編碼配置項 | 通過 ZyfHbaseConfig 解耦配置邏輯 |
四、核心實現二:函數式接口封裝查詢執行邏輯
完成連接池后,我們真正的目標并不是「能連上 HBase」,而是「優雅、穩定、高復用地執行查詢邏輯」。這一節重點圍繞我們自定義的 HBaseTemplate 展開,它解決的是 HBase 原生查詢語義復雜、樣板代碼冗余、異常處理分散 等痛點。
(一)目標:讓查詢邏輯像“寫 Lambda 一樣”簡單
對業務開發來說,其希望的是:
List<Result> results = hbaseTemplate.execute("user_table", table -> {Scan scan = new Scan();return table.getScanner(scan);
});
而不是關注:
-
連接有沒有初始化?
-
是否線程安全?
-
出了異常怎么辦?
-
Table 用完是否關閉?
-
HBase 接口是否阻塞?
(二)函數式接口設計:對標 Spring JdbcTemplate
我們定義了一個非常簡單的函數式接口:
@FunctionalInterface
public interface TableCallback<T> {T doInTable(Table table) throws Throwable;
}
這個接口的作用類似于 JDBC 中的 ConnectionCallback<T>,只不過這里操作的是 org.apache.hadoop.hbase.client.Table,它允許業務方只關心如何從 Table 中執行邏輯,而不必管理資源生命周期。
(三)execute() 模板方法封裝
我們封裝了如下通用模板:
public class HBaseTemplate {private final HBaseConnectionFactory connectionFactory;public HBaseTemplate(HBaseConnectionFactory connectionFactory) {this.connectionFactory = connectionFactory;}public <T> T execute(String tableName, TableCallback<T> action) {try (Table table = connectionFactory.getConnection().getTable(TableName.valueOf(tableName))) {return action.doInTable(table);} catch (Throwable e) {throw new HBaseTemplateException("Failed to execute HBase action on table: " + tableName, e);}}
}
關鍵點:
| 設計點 | 作用 |
|---|---|
try-with-resources | 自動釋放 HBase Table,避免資源泄漏 |
泛型返回值 <T> | 查詢可返回任意類型(Result、List、Map 等) |
| 封裝異常 | 統一異常處理,避免業務層 try-catch |
| 解耦連接獲取 | 所有連接交由 connectionFactory 管理 |
(四)查詢調用示例:像 Lambda 一樣優雅
List<String> rowKeys = hbaseTemplate.execute("user_table", table -> {Scan scan = new Scan();try (ResultScanner scanner = table.getScanner(scan)) {List<String> keys = new ArrayList<>();for (Result result : scanner) {keys.add(Bytes.toString(result.getRow()));}return keys;}
});
這一段代碼有以下特性:
-
無樣板代碼:不需要手動獲取連接、關閉資源、處理異常
-
業務聚焦:只關注核心邏輯(從 result 中提取 row key)
-
異常統一拋出:由模板封裝異常處理邏輯
(五)支持更細粒度的擴展能力(如 Put/Delete)
由于封裝為函數式接口,這套機制同樣適用于插入、刪除、批量處理等場景:
hbaseTemplate.execute("user_table", table -> {Put put = new Put(Bytes.toBytes("row1"));put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("name"), Bytes.toBytes("Alice"));table.put(put);return null;
});
開發者無需關注連接池的底層實現,無需擔心 Table.close() 是否漏寫,整個 API 盡可能地“隱身”,但又具備靈活性。
五、完整案例演示:從查詢封裝到業務落地
在這一節,我們將用一個完整的實際案例來演示如何通過 ApiHBaseConnectionFactory + ApiHBaseTemplate 兩個組件,完成一次 線程安全、資源友好、邏輯聚焦的 HBase 查詢。
(一)場景說明:根據手機號前綴模糊查找用戶信息
假設業務希望從 HBase 中的 user_info 表里,掃描所有手機號前綴為 "138" 的用戶,并提取部分字段。
(二)原始寫法:重復 + 冗余 + 難維護
org.apache.hadoop.conf.Configuration config = HBaseConfiguration.create();
// ... 設置一堆 config 參數(略)try (Connection conn = ConnectionFactory.createConnection(config);Table table = conn.getTable(TableName.valueOf("user_info"))) {Scan scan = new Scan();scan.setRowPrefixFilter(Bytes.toBytes("138"));try (ResultScanner scanner = table.getScanner(scan)) {for (Result result : scanner) {String userId = Bytes.toString(result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("user_id")));String phone = Bytes.toString(result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("phone")));// ...}}
} catch (IOException e) {// 異常處理
}
? 不利之處:
大量樣板代碼(連接、關閉、異常處理)
Scan、ResultScanner的釋放順序容易寫錯每次寫查詢都重復邏輯,極易出錯
(三)優化后寫法:基于模板封裝
List<UserInfo> matchedUsers = hbaseTemplate.execute("user_info", table -> {Scan scan = new Scan();scan.setRowPrefixFilter(Bytes.toBytes("138"));List<UserInfo> result = new ArrayList<>();try (ResultScanner scanner = table.getScanner(scan)) {for (Result row : scanner) {String userId = Bytes.toString(row.getValue(Bytes.toBytes("cf"), Bytes.toBytes("user_id")));String phone = Bytes.toString(row.getValue(Bytes.toBytes("cf"), Bytes.toBytes("phone")));result.add(new UserInfo(userId, phone));}}return result;
});
業務層代碼只需要關心三件事:
-
查哪個表(
user_info) -
掃描什么前綴(
138) -
組裝什么字段(
userId,phone)
其余連接復用、異常封裝、資源釋放,全交由模板內部處理。
(四)支撐代碼匯總(用于上下文完整性)
1. 用戶實體類 UserInfo
public class UserInfo {private String userId;private String phone;public UserInfo(String userId, String phone) {this.userId = userId;this.phone = phone;}// getter/setter/toString 可略
}
2. HBaseTemplate 示例定義
@Component
public class HBaseTemplate {private final HBaseConnectionFactory connectionFactory;@Autowiredpublic HBaseTemplate(ApiHBaseConnectionFactory connectionFactory) {this.connectionFactory = connectionFactory;}public <T> T execute(String tableName, TableCallback<T> action) {try (Table table = connectionFactory.getConnection().getTable(TableName.valueOf(tableName))) {return action.doInTable(table);} catch (Throwable e) {throw new HBaseTemplateException("Failed to execute action on table: " + tableName, e);}}
}
六、異常處理與重試機制的策略設計
在分布式系統中,HBase 作為一個非關系型數據庫,涉及到大量的網絡通信、數據存儲和資源管理,因此在查詢過程中難免會遇到各種異常情況,例如連接超時、網絡故障、節點不可用等。為了確保業務系統在遇到這些異常時能夠優雅地退化,并盡量保證查詢的成功率,設計一個合理的異常處理和重試機制顯得尤為重要。
(一)異常類型與分類
在 HBase 查詢中,我們可能會遇到以下幾種常見的異常類型:
-
連接異常:由于網絡故障或 HBase 集群問題,無法建立連接。
-
超時異常:HBase 查詢請求未能在規定時間內返回結果。
-
IO 異常:由于網絡不穩定或 HBase 服務器異常,導致查詢失敗。
-
不可恢復異常:如配置錯誤、表不存在等,屬于邏輯錯誤,一般不適合重試。
我們需要對這些異常進行分類,分別采取不同的處理策略。
(二)重試機制設計
為了保證高可用性,通常需要對可以恢復的異常進行重試處理。重試機制的設計應考慮以下幾個因素:
-
重試次數限制:重試次數過多會導致延遲過長,因此需要在系統中設置最大重試次數。
-
重試間隔:每次重試之間應有適當的間隔,避免短時間內頻繁請求導致系統負載過高。
-
指數回退策略:對于網絡不穩定等場景,可以采用指數回退策略,使重試間隔逐步增加,避免過多的并發請求同時到達 HBase。
示例代碼:重試邏輯的實現
public class HBaseRetryTemplate {private final int maxRetryAttempts;private final long retryDelayMillis;private final long maxRetryDelayMillis;public HBaseRetryTemplate(int maxRetryAttempts, long retryDelayMillis, long maxRetryDelayMillis) {this.maxRetryAttempts = maxRetryAttempts;this.retryDelayMillis = retryDelayMillis;this.maxRetryDelayMillis = maxRetryDelayMillis;}public <T> T executeWithRetry(HBaseOperation<T> operation) throws IOException {int attempt = 0;long currentRetryDelay = retryDelayMillis;while (attempt < maxRetryAttempts) {attempt++;try {return operation.execute();} catch (IOException e) {// 檢查是否需要重試if (shouldRetry(e)) {log.warn("HBase operation failed on attempt {}: {}. Retrying in {} ms...", attempt, e.getMessage(), currentRetryDelay);try {Thread.sleep(currentRetryDelay);} catch (InterruptedException ie) {Thread.currentThread().interrupt();throw new IOException("Thread was interrupted during retry sleep.", ie);}// 指數回退currentRetryDelay = Math.min(currentRetryDelay * 2, maxRetryDelayMillis);} else {throw e; // 無法恢復的異常,不再重試}}}throw new IOException("Exceeded maximum retry attempts.");}private boolean shouldRetry(IOException e) {// 判斷異常是否為可重試異常,如連接超時、網絡錯誤等return e instanceof SocketTimeoutException || e instanceof ConnectException;}// 操作接口,供業務層傳入具體的操作public interface HBaseOperation<T> {T execute() throws IOException;}
}
在上面的代碼中,HBaseRetryTemplate 類負責執行重試邏輯。executeWithRetry 方法接受一個 HBaseOperation,這是一個函數式接口,允許業務層傳入實際的操作(如 HBase 查詢)。如果操作失敗,系統將檢查異常類型,決定是否重試,并在必要時采用指數回退策略。
(三)異常類型處理
在實現重試邏輯時,我們需要區分哪些異常是可以重試的,哪些是不可恢復的。一般來說,網絡相關的異常、連接超時等可以重試,而配置錯誤、數據不一致等不可恢復的錯誤則應該立即拋出。
可重試異常
-
SocketTimeoutException:連接超時或數據傳輸超時
-
ConnectException:網絡連接錯誤
不可重試異常
-
TableNotFoundException:表不存在
-
IllegalArgumentException:查詢參數錯誤
-
HBaseIOException:由于系統配置問題導致的異常
private boolean shouldRetry(IOException e) {if (e instanceof SocketTimeoutException || e instanceof ConnectException) {return true; // 網絡相關錯誤可重試}if (e instanceof TableNotFoundException) {log.error("Table not found: " + e.getMessage());return false; // 表不存在,不可重試}if (e instanceof IllegalArgumentException) {log.error("Invalid query parameters: " + e.getMessage());return false; // 查詢參數無效,不可重試}return false;
}
(四)結合重試與模板使用
結合前面提到的 HBaseTemplate 和 HBaseRetryTemplate,我們可以在執行查詢時引入重試機制。以下是一個使用重試機制的查詢示例:
List<UserInfo> matchedUsers = hbaseRetryTemplate.executeWithRetry(() -> {return hbaseTemplate.execute("user_info", table -> {Scan scan = new Scan();scan.setRowPrefixFilter(Bytes.toBytes("138"));List<UserInfo> result = new ArrayList<>();try (ResultScanner scanner = table.getScanner(scan)) {for (Result row : scanner) {String userId = Bytes.toString(row.getValue(Bytes.toBytes("cf"), Bytes.toBytes("user_id")));String phone = Bytes.toString(row.getValue(Bytes.toBytes("cf"), Bytes.toBytes("phone")));result.add(new UserInfo(userId, phone));}}return result;});
});
在這里,我們通過 HBaseRetryTemplate 的 executeWithRetry 方法,確保在執行查詢操作時,如果遇到臨時的連接問題(如網絡超時),系統會自動重試,最大重試次數和重試間隔由配置項控制。
七、性能優化與高可用設計:如何讓查詢模板更高效
在高并發和大規模數據環境中,HBase 查詢的性能往往會成為系統瓶頸。因此,在實現查詢模板時,我們不僅要關注代碼的正確性,還要考慮如何優化查詢性能、減少響應時間和提高系統的可用性。
(一)查詢性能優化的基本原則
1. 減少不必要的 I/O 操作
HBase 查詢的效率往往取決于 I/O 操作的數量。為了提高性能,我們需要確保查詢只涉及必要的數據,并避免全表掃描。常見的優化方式有:
-
使用列族過濾器:通過設置列族(ColumnFamily)過濾器,只返回必要的列,減少網絡傳輸量。
-
使用行鍵過濾:通過行鍵(Row Key)進行精確匹配或前綴匹配,避免掃描整個表。
-
限制返回的行數:通過設置
Scan.setMaxResultSize限制返回的數據量,防止查詢過多數據。
2. 使用連接池減少連接創建和銷毀開銷
每次連接的創建和銷毀都可能帶來較大的性能損耗。為了優化性能,可以使用 連接池 來復用已有連接,減少頻繁創建連接的開銷。
// 示例:配置連接池
HBaseConnectionPool pool = new HBaseConnectionPool(config);
Connection connection = pool.getConnection();
通過連接池,可以讓多個線程共享連接,避免了每次操作都需要重新建立連接的問題。對于高并發系統而言,連接池是提升性能的關鍵組件。
3. 異步操作與批量操作
對于大量數據的查詢和寫入,可以考慮 異步操作 和 批量操作,避免單個請求的延遲導致整體性能下降。
-
異步查詢:通過使用
AsyncTable來執行異步查詢,可以避免同步阻塞,提高查詢吞吐量。 -
批量操作:對于多個插入、更新或刪除操作,使用批量 API(如
Put、Delete)來減少多次網絡交互的開銷。
// 示例:異步查詢
AsyncTable<Scan> asyncTable = connection.getAsyncTable(TableName.valueOf("my_table"));
asyncTable.scan(scan).thenAccept(results -> {// 處理結果
});
(二)高可用性設計
1. 集群容錯與負載均衡
為了確保系統的高可用性,HBase 集群的配置至關重要。為了避免單點故障,HBase 集群應該部署在多個節點上,并采用以下策略:
-
RegionServer 的冗余:HBase 會將數據切分成 Region,并在多個 RegionServer 上分布。RegionServer 的故障可以通過自動轉移 Region 來保證服務的高可用性。
-
負載均衡:通過合理的負載均衡策略,可以避免某些 RegionServer 過載,確保各個 RegionServer 承載均衡的負載。
HBase 會自動處理 Region 的分配和調度,但在查詢時,我們也可以通過合適的請求路由策略,減少單個 RegionServer 的壓力,提高集群的整體吞吐量。
2. 彈性擴展
高可用性系統需要具備彈性擴展的能力。當集群負載增加時,可以通過動態添加 RegionServer 節點來擴展 HBase 集群的處理能力。系統設計應當支持在流量增長時,平滑地增加機器資源,并確保不會因為資源不足導致服務不可用。
-
自動化擴展:通過監控集群的負載、存儲容量等,自動化地增加或減少 RegionServer 節點。
-
動態調整配置:根據業務需求動態調整 HBase 的配置參數(如 MemStore 大小、Region 分配策略等),確保集群能夠靈活應對不同的負載情況。
3. 故障恢復與災難恢復
為了確保高可用性,HBase 集群應具備故障恢復能力。HBase 支持以下幾種故障恢復機制:
-
數據備份與恢復:定期進行 HBase 數據的備份,并在發生故障時能夠快速恢復。
-
RegionServer 的自動切換:如果某個 RegionServer 節點宕機,HBase 會自動將該節點上的 Region 轉移到其他正常的 RegionServer 上,確保數據不丟失且服務繼續可用。
-
Zookeeper 故障轉移:HBase 依賴 Zookeeper 來協調集群中的服務,確保集群的狀態一致性。在 Zookeeper 出現故障時,可以通過手動或自動恢復機制快速切換到備用 Zookeeper 節點。
(三)查詢模板的優化
在實現查詢模板時,為了保證查詢的高效性和系統的高可用性,我們需要結合前述的優化策略,設計出高效的查詢模板。具體做法包括:
-
緩存優化:使用緩存技術(如 Redis)緩存頻繁查詢的數據,減少對 HBase 的查詢壓力。特別是對于熱點數據,緩存能顯著減少查詢響應時間。
-
查詢預熱與異步查詢:針對一些復雜的查詢操作,可以在后臺異步執行查詢,并提前加載數據,減少用戶請求時的延遲。
-
合理的參數配置:在查詢時,合理設置 Scan 參數(如
setBatch、setCaching等),避免全表掃描或不必要的網絡傳輸。
示例:使用緩存優化查詢
public class HBaseCacheTemplate {private Cache<String, List<UserInfo>> cache; // 使用緩存來存儲查詢結果public List<UserInfo> queryUserInfo(String prefix) throws IOException {// 先檢查緩存List<UserInfo> cachedData = cache.get(prefix);if (cachedData != null) {return cachedData;}// 如果緩存沒有,執行 HBase 查詢List<UserInfo> result = hbaseTemplate.execute("user_info", table -> {Scan scan = new Scan();scan.setRowPrefixFilter(Bytes.toBytes(prefix));return executeScan(table, scan);});// 將查詢結果放入緩存cache.put(prefix, result);return result;}private List<UserInfo> executeScan(Table table, Scan scan) throws IOException {List<UserInfo> result = new ArrayList<>();try (ResultScanner scanner = table.getScanner(scan)) {for (Result row : scanner) {String userId = Bytes.toString(row.getValue(Bytes.toBytes("cf"), Bytes.toBytes("user_id")));String phone = Bytes.toString(row.getValue(Bytes.toBytes("cf"), Bytes.toBytes("phone")));result.add(new UserInfo(userId, phone));}}return result;}
}
(四)小結:如何提高查詢模板的性能和可用性
| 優化點 | 效果 |
|---|---|
| 限制查詢數據范圍 | 減少 I/O 操作,降低網絡傳輸量 |
| 連接池復用 | 減少連接創建銷毀開銷,提高響應速度 |
| 異步與批量操作 | 提升查詢吞吐量,減少單個請求的延遲 |
| 高可用設計 | 保證系統在故障時能夠快速恢復,減少停機時間 |
| 緩存優化 | 通過緩存熱點數據,減少對 HBase 的重復查詢 |
| 故障恢復 | 保證在服務不可用時能夠快速恢復,提升系統的可靠性 |
通過這些優化,我們能夠提升查詢模板的性能,確保系統在高并發、大規模數據訪問的場景下仍能高效運行。
八、總結與未來展望:從技術實現到業務落地
在前面的章節中,我們詳細介紹了如何設計和實現一個線程安全、可復用的 HBase 查詢模板。從連接池的懶加載、查詢執行邏輯的封裝,到性能優化和高可用性設計,我們全面探討了構建一個高效、可擴展、可靠的 HBase 查詢模板的關鍵要點。
(一)設計總結:一個高效且健壯的 HBase 查詢模板
我們從實際需求出發,設計了一個能夠在多線程環境下安全地復用連接的查詢模板。整個模板的設計考慮了以下幾點核心需求:
-
線程安全性:通過使用
AtomicReference和雙重檢查鎖實現了懶加載的連接管理,確保在多線程環境中只有一個連接被創建和復用。 -
性能優化:通過連接池復用、批量操作、異步查詢等手段,我們有效提升了查詢性能,減少了不必要的 I/O 操作和延遲。
-
高可用性設計:在設計上引入了容錯機制和自動重試機制,保證系統在高負載和故障恢復場景下能繼續高效運行。
-
查詢邏輯封裝:使用函數式接口封裝查詢邏輯,使得查詢操作更加靈活,業務代碼與查詢實現解耦,提高了代碼的可維護性。
通過這些設計,我們不僅滿足了對性能的要求,也保障了系統的高可用性,使得 HBase 查詢能夠平穩地支持大規模業務的高并發訪問。
(二)對業務的實際影響
在實際業務中,這種 HBase 查詢模板的引入,使得系統能夠在面對不斷增長的數據量和請求量時,保持較低的延遲和較高的查詢效率。尤其是在需要高并發處理和快速響應的場景下,查詢模板的性能優化和高可用性設計提供了重要的保障。
-
減少開發復雜度:通過封裝查詢邏輯和連接池的管理,開發人員不再需要關心 HBase 連接的管理和細節,可以更加專注于業務邏輯的開發。
-
提升服務可用性:自動重試機制和連接池的使用大大提升了系統的容錯能力,減少了因連接失敗或高負載導致的服務中斷。
-
加速業務迭代:優化后的查詢模板不僅提升了性能,還為業務的擴展和優化提供了便利。業務團隊可以更快速地推出新功能,支持更多的查詢需求。
(三)未來展望:進一步優化與發展方向
盡管我們已經實現了一個性能較好且可靠的查詢模板,但隨著技術的不斷發展和業務需求的變化,仍然有許多潛力可以挖掘,以下是未來的一些發展方向:
1. 高級查詢優化
隨著數據量的不斷增加,單純的連接池復用和緩存優化可能無法滿足更高的查詢需求。未來可以考慮更多的 查詢優化策略,如:
-
預計算和物化視圖:對于頻繁查詢的復雜數據,可以采用預計算的方式,將結果存儲在獨立的表或緩存中,減少查詢時的計算壓力。
-
基于機器學習的查詢優化:利用機器學習算法預測和優化查詢模式,根據歷史查詢數據自動調整查詢策略和索引。
2. 更靈活的查詢策略
隨著業務需求的變化,可能會出現更多種類的查詢模式,未來的查詢模板可以支持 更多靈活的查詢策略,例如:
-
多維度查詢支持:對于具有復雜查詢需求的業務,模板可以支持更加靈活的查詢方式,如基于時間、地理位置、用戶行為等多維度的查詢。
-
分布式查詢:隨著大數據量的增長,HBase 集群可能會變得更加復雜,支持跨 RegionServer 或跨集群的分布式查詢可能成為未來的需求。
3. 異常監控與自動化運維
在高可用系統中,異常監控和自動化運維的能力至關重要。未來的查詢模板可以與 分布式監控系統(如 Prometheus、Grafana)集成,實時監控查詢性能和連接池的狀態。系統出現異常時,可以自動觸發警報或恢復操作。
-
查詢性能監控:監控每次查詢的延遲和吞吐量,自動識別性能瓶頸。
-
自動擴展和調整:根據系統負載,自動擴展連接池或調整查詢參數,保證查詢性能。
4. 支持更多數據源和兼容性
未來,隨著系統需求的多樣化,可能會接入不同的數據源。查詢模板可以進一步擴展,支持對 多種數據源的兼容性,例如:
-
支持多個 NoSQL 數據庫:除了 HBase,還可以支持 Cassandra、MongoDB 等其他 NoSQL 數據庫,統一管理多個數據源的查詢操作。
-
對不同版本 HBase 的兼容:隨著 HBase 版本的更新,可能會有新的 API 和功能,查詢模板應能兼容不同版本的 HBase,以便平滑過渡。
(四)小結
通過本章節的總結,我們可以看到一個完善的 HBase 查詢模板不僅要關注基本的性能和高可用性,還應考慮靈活性、擴展性和長期運維的需求。從當前的實現到未來的展望,查詢模板的優化和演進將是一個持續的過程,隨著業務發展和技術進步,我們可以不斷改進和優化查詢模板,以應對越來越復雜的應用場景。
希望通過本書的介紹,讀者能夠掌握高效的 HBase 查詢模板設計和實現技巧,并將其應用到實際的業務中,解決查詢性能、連接管理和高可用性等方面的問題,最終提高整個系統的業務效率和穩定性。



)

)





在施工階段的實踐與應用方案(90頁PPT)(文末有下載方式))


和畫像(Figure))




