一、前言
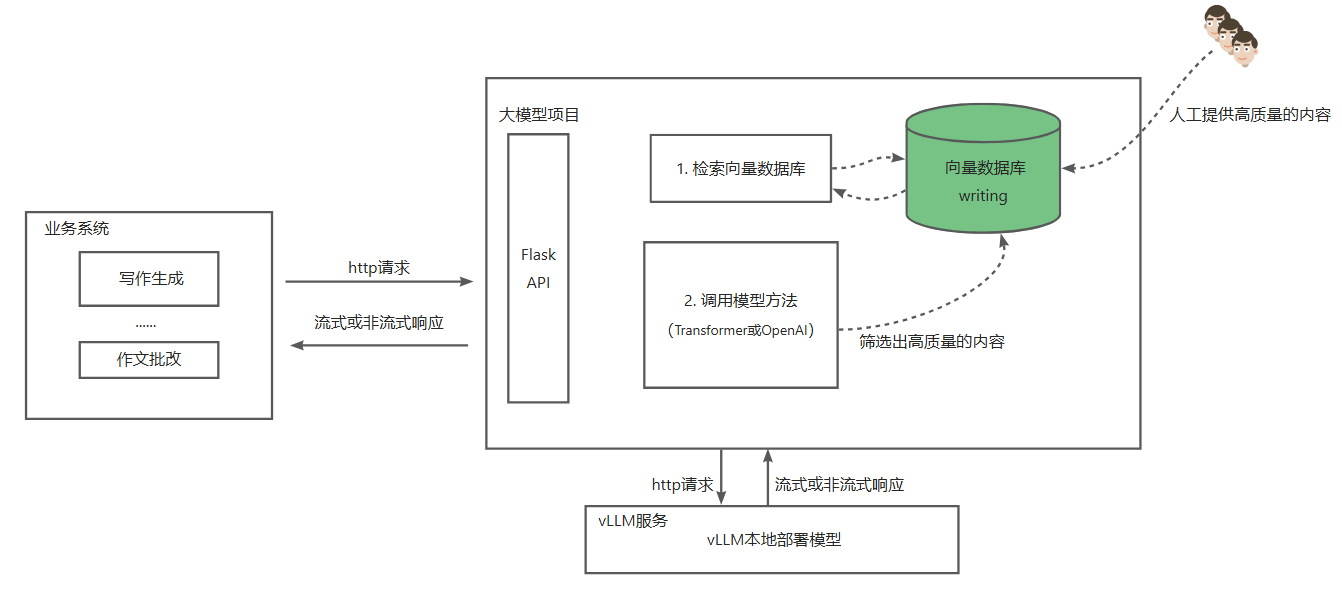
結合前面掌握的vLLM部署Qwen7B模型、通過Embedding模型(bdg-large-zh模型)提取高質量作文內容并預先存儲到Milvus向量數據庫中,我們很容易實現RAG方案進一步提高寫作內容的生成質量。
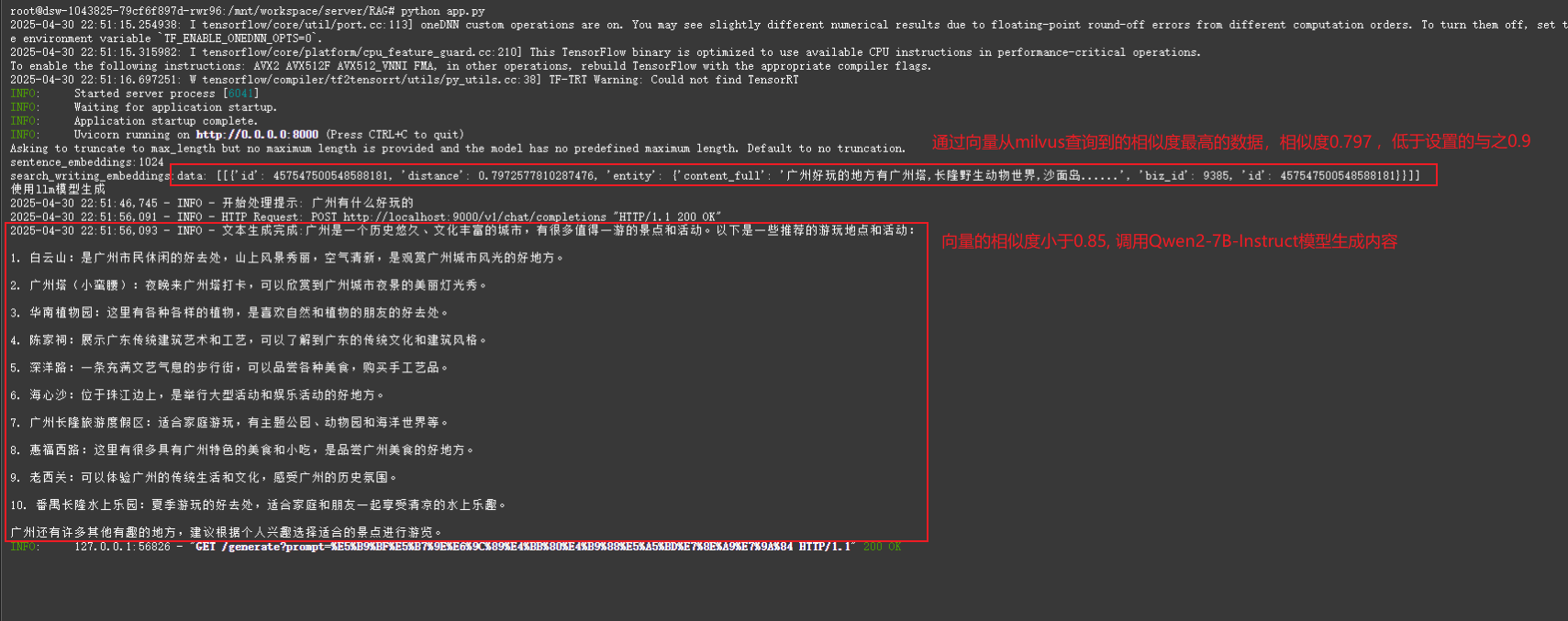
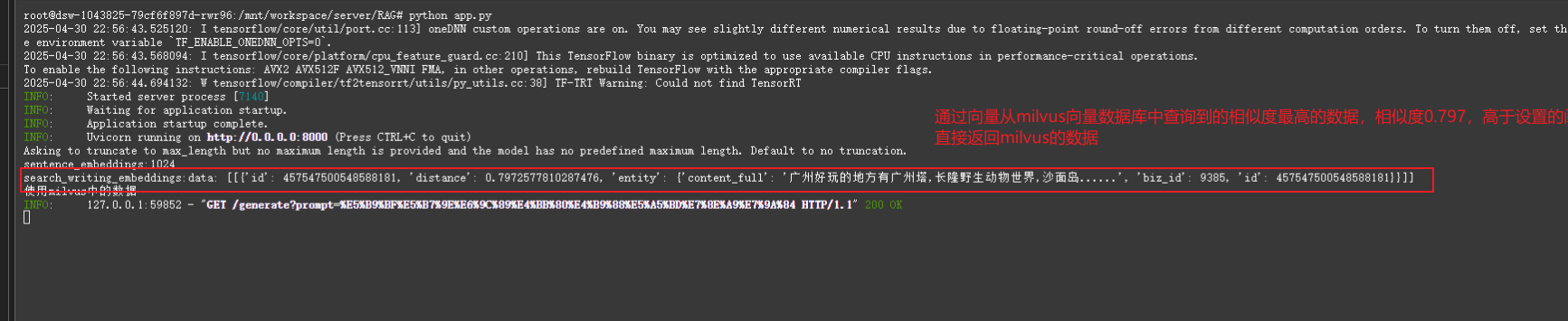
本篇要實現的目標是:通過FlaskAPI對上游業務系統提供一個開放接口,調用該接口將返回寫作內容(非流式)。 該接口優先通過dbg-large-zh模型生成ebedding向量,然后從Milvus向量數據庫中查詢和向量相似度最高的1條數據,若查到數據且相似度達到指定閾值(如0.75或0.9,具體數值由業務決定),則直接返回Milvus中存儲的內容,否則調用Qwen2-7B-Instruct模型生成寫作內容。
要實現的架構為:
往期文章:
快速掌握大語言模型-Qwen2-7B-Instruct落地1-CSDN博客
快速掌握大語言模型-Qwen2-7B-Instruct落地2-CSDN博客
快速掌握向量數據庫-Milvus探索1-CSDN博客
快速掌握向量數據庫-Milvus探索2_集成Embedding模型-CSDN博客
二、術語
2.1 vLLM
vLLM采用連續批處理,吞吐量相比傳統框架(如Hugging Face Transformers)可提升5-10倍;
分布式推理支持允許在多GPU環境下并行處理;
通過PagedAttention技術,vLLM將注意力計算的鍵值(KV Cache)分頁存儲在顯存中,動態分配空間以減少碎片;
內置了對 OpenAI API 的兼容支持,可直接啟動符合 OpenAI 標準的 API 服務;
2.2 FastApi
基于Python的Web框架,主要用于構建高性能、易維護的API和Web應用程序,通過FastApi可以對上游業務系統暴露API,上游業務系統通過http請求即調用相關接口。
2.3 Milvus
Milvus是一個專為處理高維向量數據設計的開源向量數據庫,支持數百億級數據規模,在多數開源向量數據庫中綜合表現突出(一般是其他的2~5倍)。
提供三種部署方式:本地調試Milvus Lite、企業級小規模數據的Milvus Standalone(一億以內向量)、企業級大規模數據的Milvus Distributed (數百億向量)。
2.4 bge-large-zh
bge-large-zh模型是專為中文文本設計的,同尺寸模型中性能優異的開源Embedding模型,憑借其中文優化、高效檢索、長文本支持和低資源消耗等特性,成為中文Embedding領域的標桿模型。
2.5 Qwen2-7B-Instruct
Qwen2-7B-Instruct 是阿里云推出的開源指令微調大語言模型,屬于 Qwen2 系列中的 70 億參數版本。該模型基于 Transformer 架構,通過大規模預訓練和指令優化,展現出強大的語言理解、生成及多任務處理能力
三、代碼
3.1 代碼目錄
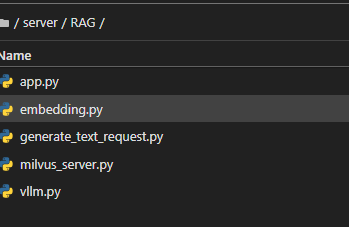
- vllm.py :提供調用Qwen7B模型的方法;
- app.py :提供通過FastAPI暴露給上游業務系統調用的API;
- embedding.py :提供調用bge-large-zh模型生成內容的embedding向量的方法 ;
- milvus_server.py :提供查詢Milvus向量數據庫的方法;
- generate_text_request.py : 模擬上游業務系統通過http調用app.py提供的生成寫作內容的API
3.2 完整代碼
3.2.1 安裝依賴
# vllm需要的依賴
pip install vllm# milvus需要的依賴
python -m pip install -U pymilvus?3.2.2?app.py
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
import logging
from vllm import Model
from embedding import search_writing_embeddings# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
app = FastAPI()
model = Model()# 流式響應
@app.get("/chat")
async def chat(prompt: str):return StreamingResponse(model.generate_stream(prompt), media_type="text/plain")# 非流式響應(RAG增強檢索)
@app.get("/generate")
async def generate(prompt: str):# 優先通過embedding向量從milvus中搜索相似度最高的1條數據,如果相似度達到90%以上,則直接返回該數據的content_full字段作為結果,否則調用llm模型生成# 這里的90%是一個閾值,可以根據實際情況調整res = search_writing_embeddings(prompt)print(f"search_writing_embeddings:{res}")threshold = 0.75if res and res[0] and res[0][0]['distance'] >= threshold:print("使用milvus中的數據")result = res[0][0]['entity']['content_full']else:print("使用llm模型生成")result = await model.generate_text(prompt)return resultif __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=8000)3.2.3?vllm.py
# 大語言模型LLM文件import logging
from openai import OpenAI
from pydantic_core import Url# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
model_path = "/mnt/workspace/models/Qwen2-7B-Instruct"
base_url = "http://localhost:9000/v1"class Model:def __init__(self):# 創建 OpenAI 客戶端實例,這里的密鑰可以隨意填寫,vLLM 不需要驗證self.client = OpenAI(api_key="EMPTY", base_url= base_url) # 流式處理async def generate_stream(self, prompt: str):try:logging.info(f"開始處理提示: {prompt}")# 使用新客戶端調用 API# 確保使用類的實例屬性 self.clientchat_response = self.client.chat.completions.create(model= model_path,messages=[{"role": "user", "content": prompt}],stream=True,max_tokens=512,temperature=0.7,top_p=0.9)for chunk in chat_response:msg = chunk.choices[0].delta.contentif msg is not None:logging.info(f"生成文本塊: {msg}")yield msglogging.info("流式輸出結束")except Exception as e:logging.error(f"處理提示時出錯: {e}", exc_info=True)# 非流式處理async def generate_text(self, prompt: str):try:logging.info(f"開始處理提示: {prompt}")# 使用新客戶端調用 APIresponse = self.client.chat.completions.create(model= model_path,messages=[{"role": "user", "content": prompt}],stream=False,max_tokens=512,temperature=0.7,top_p=0.9)# 獲取完整響應content = response.choices[0].message.contentlogging.info(f"文本生成完成:{content}")return contentexcept Exception as e:logging.error(f"處理提示時出錯: {e}", exc_info=True)return ""
3.2.4?embedding.py
from transformers import AutoTokenizer, AutoModel
import torch
import random
from milvus_server import WritingDTO, insert_data_to_milvus,search_data_from_milvus# 加載模型和分詞器
model_path = "/mnt/workspace/models/bge-large-zh" # 根據實際情況修改
model = AutoModel.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 推理模式
model.eval() # 寫作生成合集名稱
writing_collection_name = "writing"def get_embedding_list(text_list):"""輸入文本列表,返回文本的embedding向量:param text_list: 待獲取embedding的文本集合:return: ebedding向量集合"""# 編碼輸入(自動截斷和填充)encoded_input = tokenizer(text_list, padding=True, truncation=True, return_tensors='pt')# 調用大模型得到文本的embeddingwith torch.no_grad():model_output = model(**encoded_input)sentence_embeddings = model_output[0][:, 0] # bdge-large-zh 模型的輸出是一個元組,第一個元素是句子的嵌入向量,1024維print(f"sentence_embeddings:{ len(sentence_embeddings[0])}")# 歸一化處理:可以提高模型的穩定性和收斂速度,尤其在處理向量相似度計算時非常有用sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)# 轉換嵌入向量為列表embeddings_list = sentence_embeddings.tolist()return embeddings_listdef insert_writing_embeddings(text_list):"""獲取寫作生成內容的文本的embedding向量,并寫入到milvus中:param text_list: 待獲取embedding的寫作生成內容集合:return: 寫入到到milvus結果,ebedding向量集合"""# 獲取embedding embeddings_list = get_embedding_list(text_list)print(f"embeddings_list:{len(embeddings_list)}")# 寫作記錄合集writing_list = []for i, embedding in enumerate(embeddings_list):writingDTO = WritingDTO(embedding, text_list[i], random.randint(500,9999)) #組裝對象數據,其中biz_id是業務ID,這里這里方便說明暫設為隨機數字writing_list.append(writingDTO.to_dict()) # 將對象轉換為字典,并添加到集合中# 插入數據到 Milvusres = insert_data_to_milvus(writing_collection_name,writing_list)return res,embeddings_listdef search_writing_embeddings(text):"""獲取寫作內容的embedding向量,并從milvus中搜索"""# 獲取embeddingembeddings_list = get_embedding_list([text])# 搜索數據res = search_data_from_milvus(writing_collection_name,embeddings_list,["id","content_full","biz_id"],1)return resif __name__ == "__main__":# 輸入文本content = "推薦廣州有哪些好玩的地方"# 將文本轉eembedding向量并寫入到milvus中res = search_writing_embeddings(content)print("Search result:", res)3.2.5?milvus_server.py
from pymilvus import MilvusClient, db
import numpy as np
from pymilvus.orm import collection
from typing import Iterable# 定義 Milvus 服務的主機地址
host = "阿里云公網IP"# 創建一個 Milvus 客戶端實例,連接到指定的 Milvus 服務
client = MilvusClient(uri=f"http://{host}:19530",db_name="db001") # 連接到 Milvus 服務并選擇數據庫 "db001"
# collection_name = "writing" # 指定要連接的集合名稱 "writing"# 寫作生成對象
class WritingDTO:def __init__(self, content_vector, content_full, biz_id):self.content_vector = content_vectorself.content_full = content_fullself.biz_id = biz_iddef to_dict(self):"""將 WritingDTO 對象轉換為字典。:return: 包含 WritingDTO 對象屬性的字典"""return {"content_vector": self.content_vector,"content_full": self.content_full,"biz_id": self.biz_id}def insert_data_to_milvus(collection_name,data):"""將對象集合中的數據插入到 Milvus 集合中。:param data: 字典對象集合:return: 插入操作的結果"""print(f"insert_data_to_milvus:{collection_name}")print(f"insert_data_to_milvus:{len(data)}")res = client.insert(collection_name=collection_name,data=data)return resdef search_data_from_milvus(collection_name,query_vector,output_fields, top_k=10):"""從 Milvus 集合中搜索與查詢向量最相似的向量。:param query_vector: 查詢向量:param top_k: 返回的最相似向量的數量:return: 搜索結果"""res = client.search(collection_name= collection_name, # 合集名稱data=query_vector, # 查詢向量search_params={"metric_type": "COSINE", # 向量相似性度量方式,COSINE 表示余弦相似度(適用于文本/語義相似性場景); 可選 IP/COSINE/L2 "params": {"level":1}, }, # 搜索參數limit=top_k, # 查詢結果數量output_fields= output_fields, # 查詢結果需要返回的字段consistency_level="Bounded" # 數據一致性級別,Bounded允許在有限時間窗口內讀取舊數據,相比強一致性(STRONG)提升 20 倍查詢性能,適合高吞吐場景; )return res3.2.6?generate_text_request.py
import requestsurl = "http://0.0.0.0:8000/generate?prompt=廣州有什么好玩的"
response = requests.get(url, stream=True)
print(response.text)四、調用結果
4.1 啟動vllm
python -m vllm.entrypoints.openai.api_server --model /mnt/workspace/models/Qwen2-7B-Instruct --swap-space 10 --disable-log-requests --max-num-seqs 256 --host 0.0.0.0 --port 9000 --dtype float16 --max-parallel-loading-workers 1 --max-model-len 10240 --enforce-eager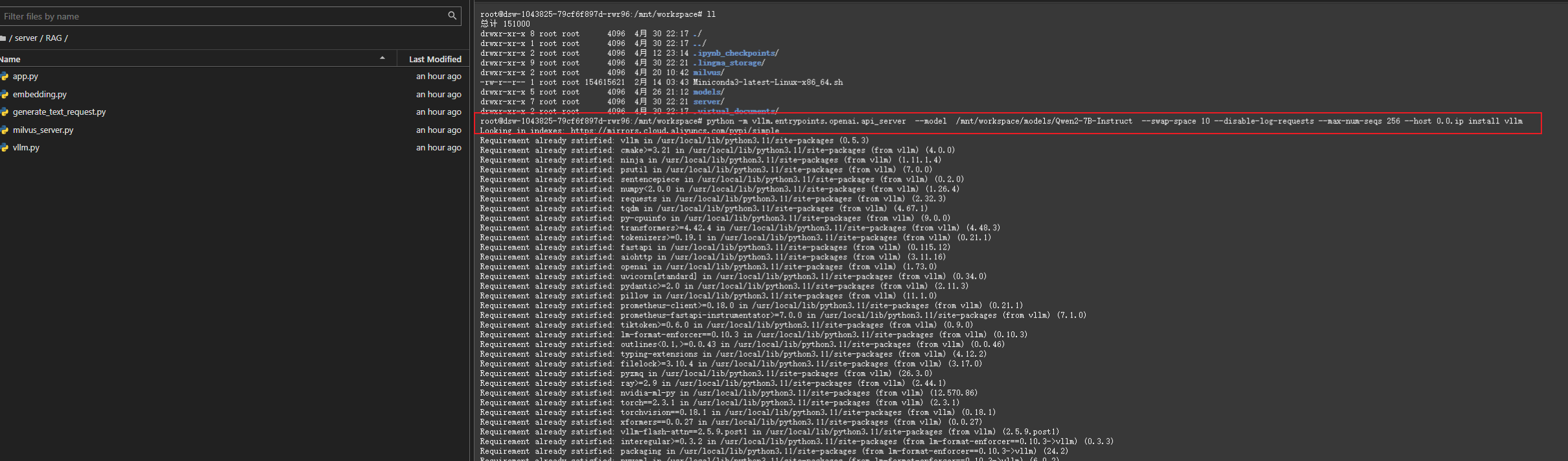
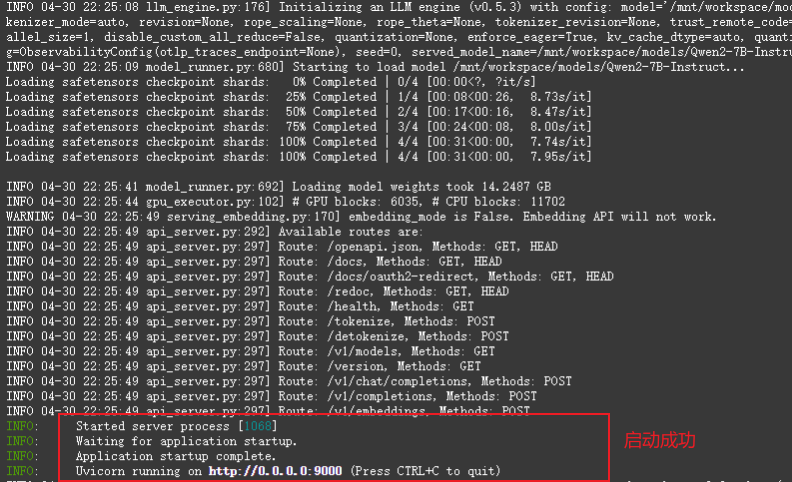
4.2 啟動FastAPI

4.3 上游業務系統調用

情況1:向量查詢結果相似度低于閾值(90%相似度)的情況 ==> 通過Qwen7B模型生成內容
情況2:向量查詢結果相似度高于于閾值(75%相似度)的情況 ==> 直接返回向量查詢結果的內容



:檢索增強生成原理與LLM對比分析)




(文末有下載方式))
)



)





