RAG技術完全指南(一):檢索增強生成原理與LLM對比分析
文章目錄
- RAG技術完全指南(一):檢索增強生成原理與LLM對比分析
- 1. RAG 簡介
- 2. 核心思想
- 3. 工作流程
- 3.1 數據預處理(索引構建)
- 3.2 查詢階段
- 3.3 流程圖
- 4. RAG VS LLM
- 4.1 RAG vs 傳統LLM 對比表
- 4.2 如何選擇
- 5. 挑戰與改進
- 6. 代碼示例(簡易 RAG 實現)
- 7. 總結
1. RAG 簡介
RAG(檢索增強生成) 是一種結合 信息檢索(Retrieval) 和 大語言模型生成(Generation) 的技術,旨在提升模型生成內容的準確性和事實性。它通過從外部知識庫中動態檢索相關信息,并將這些信息作為上下文輸入給生成模型,從而減少幻覺并提高回答質量。
2. 核心思想
- 檢索(Retrieval):根據用戶問題,從外部數據庫(如文檔、網頁、知識圖譜)中查找相關片段。
- 生成(Generation):將檢索到的內容與問題一起輸入 LLM,生成更準確的回答。
類比:就像寫論文時先查資料(檢索),再結合自己的理解寫出內容(生成)。
3. 工作流程
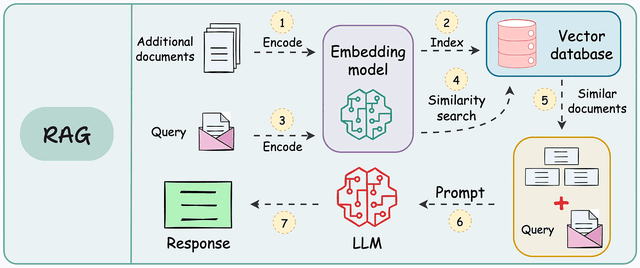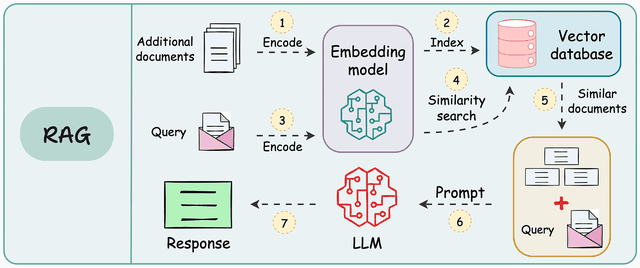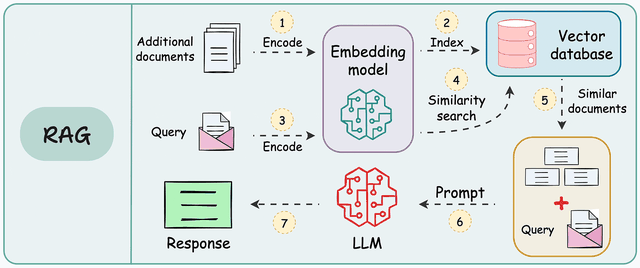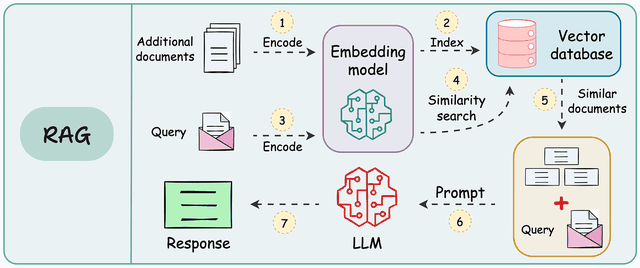
3.1 數據預處理(索引構建)
- 將知識庫(如 PDF、網頁、數據庫)拆分成文本塊(chunks)。
- 使用 Embedding 模型 將文本轉換為向量,存入向量數據庫
3.2 查詢階段
- 用戶提問:例如 “什么是RAG?”
- 檢索相關文檔:
- 用相同的 Embedding 模型將問題轉換為向量。
- 在向量數據庫中計算相似度(如余弦相似度),返回最匹配的文本片段。
- 生成回答:
- 將檢索到的文本 + 用戶問題一起輸入 LLM。
- LLM 結合檢索內容生成最終回答。
3.3 流程圖
以下是 RAG 的工作流程圖:
4. RAG VS LLM
以下是 RAG(檢索增強生成) 與傳統 大語言模型(LLM) 的對比表格,清晰展示兩者的優劣勢及適用場景:
4.1 RAG vs 傳統LLM 對比表
| 對比維度 | RAG(檢索增強生成) | 傳統大語言模型(如GPT-4、Llama) |
|---|---|---|
| 知識實時性 | ? 可動態更新知識庫(依賴外部數據源) | ? 僅依賴預訓練數據,無法主動更新 |
| 事實準確性 | ? 基于檢索內容生成,減少幻覺(可引用來源) | ? 可能生成虛假信息(幻覺問題顯著) |
| 領域適應性 | ? 靈活接入專業數據(醫學、法律等) | ? 通用性強,但專業領域需微調(成本高) |
| 計算成本 | ?? 需維護向量數據庫+檢索步驟(額外開銷) | ? 僅生成步驟,推理成本低 |
| 響應速度 | ? 檢索+生成兩步,延遲較高 | ? 純生成,響應更快 |
| 可解釋性 | ? 可返回參考來源(支持溯源) | ? 黑箱生成,無法提供依據 |
| 長尾問題處理 | ? 通過檢索補充罕見知識 | ? 依賴模型記憶,長尾知識覆蓋率低 |
| 數據隱私 | ?? 依賴外部數據源,需安全管控 | ? 純模型推理,隱私風險更低 |
| 實現復雜度 | ? 需搭建檢索系統(分塊、Embedding、向量數據庫) | ? 直接調用API或部署模型,簡單易用 |
| 典型應用場景 | 客服問答、學術研究、法律咨詢、動態知識庫 | 創意寫作、代碼生成、通用對話、無需更新的場景 |
4.2 如何選擇
- 選 RAG:
- 需要高準確性、可溯源的回答(如醫療、法律、學術/研究助手)。
- 知識需頻繁更新(如新聞、產品文檔)。
- 選傳統LLM:
- 追求低延遲和簡單部署(如聊天機器人)。
- 創意生成任務(如寫故事、營銷文案)。
5. 挑戰與改進
| 挑戰 | 解決方案 |
|---|---|
| 檢索效率低 | 使用更快的向量數據庫(如 FAISS) |
| 檢索內容不精準 | 優化分塊策略(chunk size)和 Embedding 模型 |
| 生成模型忽略檢索內容 | 在 Prompt 中強調“必須基于檢索內容回答” |
| 多模態數據支持 | 結合文本+圖像檢索(如 CLIP 模型) |
6. 代碼示例(簡易 RAG 實現)
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np# 1. 加載 Embedding 模型
model = SentenceTransformer("all-MiniLM-L6-v2")# 2. 模擬知識庫
documents = ["量子計算利用量子比特(qubit)進行并行計算。","2023年,IBM 發布了433量子比特處理器。","RAG 技術結合檢索與生成提升LLM準確性。",
]
doc_embeddings = model.encode(documents) # 向量化知識庫# 3. 用戶查詢
query = "哪一年IBM發布了量子比特處理器?"
query_embedding = model.encode(query)# 4. 檢索最相似文檔
similarities = cosine_similarity([query_embedding], doc_embeddings)[0]
most_relevant_idx = np.argmax(similarities)
retrieved_text = documents[most_relevant_idx]# 5. 生成回答(模擬LLM)
prompt = f"基于以下信息回答問題:{retrieved_text}\n\n問題:{query}"
print("檢索到的內容:", retrieved_text)7. 總結
- RAG = 檢索(Retrieval) + 生成(Generation),動態增強 LLM 的知識。
- 核心價值:解決 LLM 的幻覺問題,支持實時更新和領域適配。
- 關鍵組件:Embedding 模型、向量數據庫、檢索策略、生成模型。
RAG 是當前最流行的增強 LLM 方案之一,廣泛應用于企業知識庫、教育、研究等領域。




(文末有下載方式))
)



)







)

