最近接了個模型訓練編排多機多卡的改造需求,要求使用argo? dag task啟動多個節點,同時多個節點能實現 torch.distributed.launch 這樣多機多卡的訓練模式
簡述技術
?torch.distributed.launch命令介紹
我們在訓練分布式時候,會使用到 torch.distributed.launch
可以通過命令,來打印該模塊提供的可選參數 python -m torch.distributed.launch --help
usage: launch.py [-h] [--nnodes NNODES] [--node_rank NODE_RANK]
? ? ? ? ? ? ? ? [--nproc_per_node NPROC_PER_NODE] [--master_addr MASTER_ADDR] [--master_port MASTER_PORT]?
? ? ? ? ? ? ? ? [--use_env] [-m] [--no_python] [--logdir LOGDIR]
? ? ? ? ? ? ? ? training_script ...
?
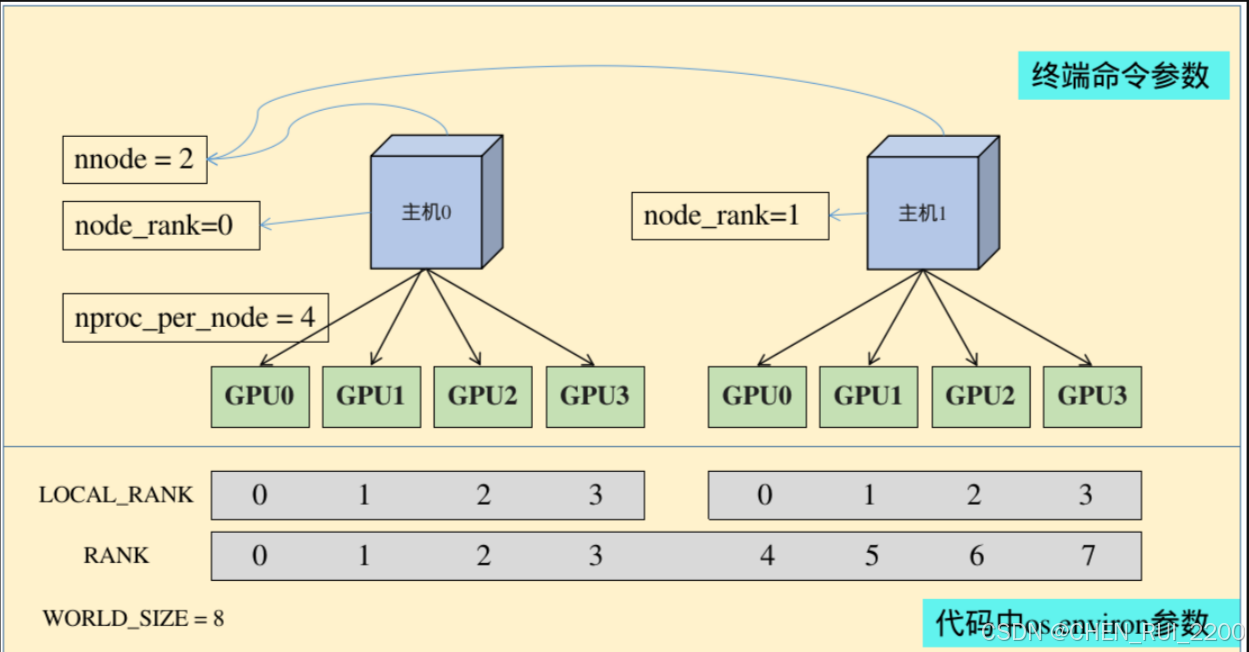
torch.ditributed.launch參數解析(終端運行命令的參數):
- nnodes:節點的數量,通常一個節點對應一個主機,方便記憶,直接表述為主機
- node_rank:節點的序號,從0開始
- nproc_per_node:一個節點中顯卡的數量
- master_addr:master節點的ip地址,也就是0號主機的IP地址,該參數是為了讓 其他節點 知道0號節點的位,來將自己訓練的參數傳送過去處理
- master_port:master節點的port號,在不同的節點上master_addr和master_port的設置是一樣的,用來進行通信
?
torch.ditributed.launch相關環境變量解析(代碼中os.environ中的參數):
- WORLD_SIZE:os.environ[“WORLD_SIZE”]所有進程的數量
- LOCAL_RANK:os.environ[“LOCAL_RANK”]每張顯卡在自己主機中的序號,從0開始
- RANK:os.environ[“RANK”]進程的序號,一般是1個gpu對應一個進程
多機上訓練步驟看下圖就明白了
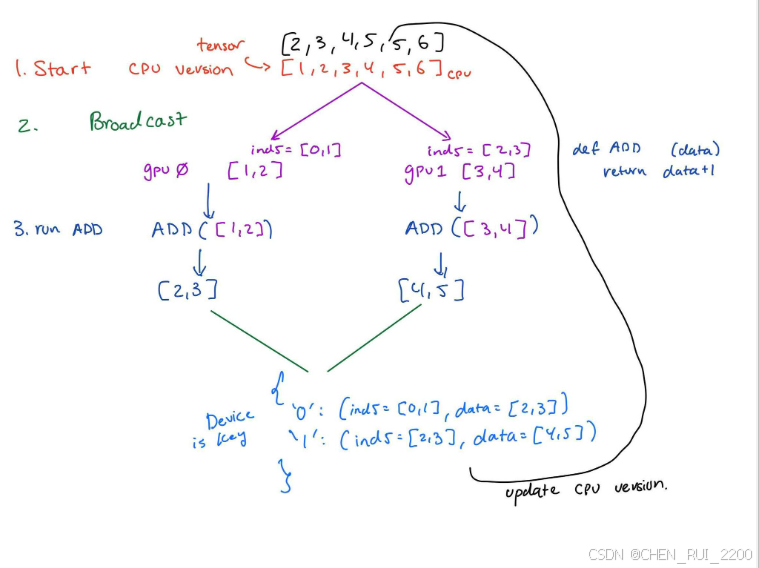
假設我連接了兩個 GPU。一個在 Device0 上,另一個在 Device1 上。
在 CPU 上存儲一個非常大的數組(單個設備/GPU 無法容納),例如 X = [1,2,3,4,5,6]。
將數組的一部分廣播到 GPU 設備 0 和 GPU 設備 1。0 和 1 分別包含該數組的不同塊。GPU0 的 Inds = [0,1] GPU0 的數據 = [1,2] GPU1 的 Inds = [2,3] GPU1 的數據 = [2,3]
在 GPU0 和 GPU1 上分別運行一個進程。為此,一個簡單的 Add() 函數即可完成。
根據需要(對于 GPU 獲取的 inds),使用 GPU 數據更新 CPU 版本。這時我可能會使用 reduce 從設備獲取兩個張量。我可能會將其存儲在一個鍵值字典中,其中鍵是設備 ID(0 代表 GPU 0,1 代表 GPU 1),并將 inds 和數據存儲在一個元組中。然后,我需要更新 CPU 版本并再次運行整個過程。
分布式訓練鏡像
基礎鏡像使用
swr.cn-south-1.myhuaweicloud.com/ascendhub/ascend-pytorch:24.0.RC2-A2-2.1.0-ubuntu20.04
使用這個train.py 作為訓練入口
import os
import argparse
import sys
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
import torch.nn.functional as F
from torch.nn.parallel import DistributedDataParallel as DDP# 檢查是否支持昇騰 NPU
try:import torch_npuNPU_AVAILABLE = Trueprint("NPU support detected: torch_npu is available")
except ImportError:NPU_AVAILABLE = Falseprint("NPU support not detected: torch_npu is not available")
sys.stdout.flush()# 定義簡單的神經網絡模型
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet, self).__init__()self.fc1 = nn.Linear(10, 50)self.fc2 = nn.Linear(50, 10)def forward(self, x):x = F.relu(self.fc1(x))x = self.fc2(x)return x# 解析命令行參數
def parse_args():parser = argparse.ArgumentParser(description="Distributed Training with BladeTrain")parser.add_argument('--type', type=str, default='example', help='Type argument')parser.add_argument('--parameter', type=str, default='default', help='Parameter argument')args = parser.parse_args()print(f"Parsed arguments: type={args.type}, parameter={args.parameter}, server_address={args.server_address}, job_id={args.job_id}")sys.stdout.flush()return args# 訓練函數
def train(model, optimizer, rank, epoch):model.train()print(f"Rank {rank}: Entering training loop")sys.stdout.flush()while True: # 無限訓練循環inputs = torch.randn(32, 10).to(rank) # 批次大小 32,輸入維度 10targets = torch.randn(32, 10).to(rank) # 輸出維度 10optimizer.zero_grad()outputs = model(inputs)loss = F.mse_loss(outputs, targets)loss.backward()optimizer.step()# 增加更頻繁的日志輸出if rank == 0:if epoch % 10 == 0: # 每 10 步打印一次print(f"Epoch {epoch}, Loss: {loss.item():.4f}")sys.stdout.flush()epoch += 1def main():# 從環境變量獲取 local_ranklocal_rank = int(os.environ['LOCAL_RANK'])print(f"Starting process on local_rank {local_rank}")sys.stdout.flush()args = parse_args()# 初始化分布式環境if NPU_AVAILABLE:# 使用昇騰 NPUprint(f"Rank {local_rank}: Setting NPU device to {local_rank}")torch_npu.npu.set_device(local_rank)device = torch.device(f'npu:{local_rank}')print(f"Rank {local_rank}: Initializing distributed group with hccl backend")dist.init_process_group(backend='hccl') # 使用 hccl 后端print(f"Rank {local_rank}: Distributed group initialized with hccl")else:# 回退到 CPUdevice = torch.device('cpu')print(f"Rank {local_rank}: Initializing distributed group with gloo backend (CPU fallback)")dist.init_process_group(backend='gloo')print(f"Rank {local_rank}: Distributed group initialized with gloo")sys.stdout.flush()world_size = dist.get_world_size()print(f"Rank {local_rank}: World size is {world_size}")sys.stdout.flush()# 創建模型并移到設備print(f"Rank {local_rank}: Creating and moving model to device {device}")model = SimpleNet().to(device)model = DDP(model, device_ids=[local_rank] if NPU_AVAILABLE else None)print(f"Rank {local_rank}: Model wrapped with DDP")sys.stdout.flush()# 定義優化器optimizer = optim.SGD(model.parameters(), lr=0.01)print(f"Rank {local_rank}: Optimizer initialized")sys.stdout.flush()# 開始訓練print(f"Rank {local_rank}: Starting training with world size {world_size}")sys.stdout.flush()train(model, optimizer, local_rank, epoch=0)# 清理分布式環境print(f"Rank {local_rank}: Cleaning up distributed environment")dist.destroy_process_group()sys.stdout.flush()if __name__ == "__main__":main()把訓練用train.py 添加到鏡像里?
java 創建argo workflow的代碼
import io.argoproj.workflow.ApiClient;
import io.argoproj.workflow.ApiException;
import io.argoproj.workflow.Configuration;
import io.argoproj.workflow.apis.WorkflowServiceApi;
import io.argoproj.workflow.models.*;
import io.kubernetes.client.custom.Quantity;
import io.kubernetes.client.openapi.models.*;private Workflow createWorkflow(JobConfig jobConfig, String graph) {String cmd = jobConfig.getCmd();String image = jobConfig.getImage();logger.info("image:{}", image);String jobType = jobConfig.getJobType();Map<String, String> labels = jobConfig.getLabels();Map<String, String> map = new HashMap<>();map.put(PARAMETER_CMD, cmd);map.put(PARAMETER_IMAGE, image);map.put(PARAMETER_ENV, jobType);Map<String, Object> node_resource_map = new HashMap<>();if (graph != null) {Map<String, Object> graphMap =JSON.parseObject(graph, new TypeReference<HashMap<String, Object>>() {});Map<String, Object> resource_config = (Map<String, Object>) graphMap.get("resource_config");JSONArray jsonArray = (JSONArray) resource_config.get("nodeConfigs");String distributed_master = jobConfig.getTrainingNodes().stream().filter(TrainingNode::getIsMaster).map(TrainingNode::getNodeName).findFirst().orElse(null);// 使用 Java 8 的流遍歷 jsonArrayIntStream.range(0, jsonArray.size()).forEach(i -> {try {JSONObject object = jsonArray.getJSONObject(i);String parameterNodeName = object.getString(PARAMETER_NODE_NAME);// 創建一個新的 HashMap 并放入 mapnode_resource_map.put(parameterNodeName, new HashMap<>() {{put(PARAMETER_CPU_LIMIT, String.valueOf(object.get("cpu_value")));put(PARAMETER_GPU_LIMIT, String.valueOf(object.get("gpu_value")));put(PARAMETER_MEM_LIMIT, String.valueOf(object.get("mem_value")));if (object.containsKey("gpu_mem_value")) {put(PARAMETER_GPU_MEM_LIMIT, String.valueOf(object.get("gpu_mem_value")));}if (object.containsKey("gpu_cores_value")) {put(PARAMETER_GPU_CORES_LIMIT, String.valueOf(object.get("gpu_cores_value")));}put(PARAMETER_ENV, String.join(" ","--nproc_per_node=1","--nnodes=" + jsonArray.size(),"--node_rank=" + (StringUtils.equals(distributed_master, parameterNodeName)? "0":"1"),"--master_addr=" + distributed_master,"--master_port=" + jobConfig.getDistributed_port(),jobConfig.getMainfile()));}});}catch (Exception e) {e.printStackTrace();}});}WorkflowCreateRequest body = new WorkflowCreateRequest();Workflow workflow = getWorkflowFromTemplate(jobConfig, map, node_resource_map, labels);body.setWorkflow(workflow);try {Workflow result = apiInstance.workflowServiceCreateWorkflow(jobConfig.namespace, body);return result;} catch (Exception e) {logger.error("argo workflow api err:" + e.toString());throw new RuntimeException(e);}}... (其他方法略)private Workflow createWorkflow(JobConfig jobConfig, String graph) {String cmd = jobConfig.getCmd();String image = jobConfig.getImage();logger.info("image:{}", image);String jobType = jobConfig.getJobType();Map<String, String> labels = jobConfig.getLabels();Map<String, String> map = new HashMap<>();map.put(PARAMETER_CMD, cmd);map.put(PARAMETER_IMAGE, image);map.put(PARAMETER_ENV, jobType);Map<String, Object> node_resource_map = new HashMap<>();if (graph != null) {Map<String, Object> graphMap =JSON.parseObject(graph, new TypeReference<HashMap<String, Object>>() {});Map<String, Object> resource_config = (Map<String, Object>) graphMap.get("resource_config");JSONArray jsonArray = (JSONArray) resource_config.get("nodeConfigs");String distributed_master = jobConfig.getTrainingNodes().stream().filter(TrainingNode::getIsMaster).map(TrainingNode::getNodeName).findFirst().orElse(null);// 使用 Java 8 的流遍歷 jsonArrayIntStream.range(0, jsonArray.size()).forEach(i -> {try {JSONObject object = jsonArray.getJSONObject(i);String parameterNodeName = object.getString(PARAMETER_NODE_NAME);// 創建一個新的 HashMap 并放入 mapnode_resource_map.put(parameterNodeName, new HashMap<>() {{put(PARAMETER_CPU_LIMIT, String.valueOf(object.get("cpu_value")));put(PARAMETER_GPU_LIMIT, String.valueOf(object.get("gpu_value")));put(PARAMETER_MEM_LIMIT, String.valueOf(object.get("mem_value")));if (object.containsKey("gpu_mem_value")) {put(PARAMETER_GPU_MEM_LIMIT, String.valueOf(object.get("gpu_mem_value")));}if (object.containsKey("gpu_cores_value")) {put(PARAMETER_GPU_CORES_LIMIT, String.valueOf(object.get("gpu_cores_value")));}put(PARAMETER_ENV, String.join(" ","--nproc_per_node=1","--nnodes=" + jsonArray.size(),"--node_rank=" + (StringUtils.equals(distributed_master, parameterNodeName)? "0":"1"),"--master_addr=" + distributed_master,"--master_port=" + jobConfig.getDistributed_port(),jobConfig.getMainfile()));}});}catch (Exception e) {e.printStackTrace();}});}WorkflowCreateRequest body = new WorkflowCreateRequest();Workflow workflow = getWorkflowFromTemplate(jobConfig, map, node_resource_map, labels);body.setWorkflow(workflow);try {Workflow result = apiInstance.workflowServiceCreateWorkflow(jobConfig.namespace, body);return result;} catch (Exception e) {logger.error("argo workflow api err:" + e.toString());throw new RuntimeException(e);}}
private Workflow getWorkflowFromTemplate(JobConfig jobConfig,Map<String, String> parameter_map,Map<String, Object> node_resource_map,Map<String, String> labels) {Workflow workflow = new Workflow();workflow.setMetadata(getMetaData(jobConfig));WorkflowSpec spec = new WorkflowSpec();//spec.setArguments(getArguments(parameter_map));spec.setPodMetadata(getPodMetadata(labels));if (StringUtils.isNotBlank(jobConfig.getImage())) {spec.setHostNetwork(true);}Template mainTemplate = new Template();mainTemplate.setMetadata(new Metadata());mainTemplate.getMetadata().setLabels(labels);mainTemplate.setName("rl-main");V1Container container = new V1Container();container.setName("rl-job-container");container.setImage(StringUtils.isNotBlank(jobConfig.getImage()) ?jobConfig.getImage() : config.rayImage);container.setCommand(List.of(jobConfig.getCmd()));if (!CollectionUtils.isEmpty(jobConfig.getTrainingNodes())) {List<TrainingNode> nodes = jobConfig.getTrainingNodes();DAGTemplate dag = new DAGTemplate();List<DAGTask> dagTasks = new ArrayList<>();List<Template> templates = new ArrayList<>();for (int i = 0; i < nodes.size(); i++) {TrainingNode node = nodes.get(i);DAGTask task = new DAGTask();task.setName(node.getDagTaskName());task.setTemplate("task-template-" + (i + 1));dagTasks.add(task);Template taskTemplate = new Template();taskTemplate.setName("task-template-" + (i + 1));// 使用 V1Affinity 替換 nodeSelectorV1Affinity affinity = new V1Affinity();V1NodeAffinity nodeAffinity = new V1NodeAffinity();// 設置硬性要求 (requiredDuringSchedulingIgnoredDuringExecution)V1NodeSelectorRequirement nodeSelectorRequirement = new V1NodeSelectorRequirement();nodeSelectorRequirement.setKey("kubernetes.io/hostname");nodeSelectorRequirement.setOperator("In");nodeSelectorRequirement.setValues(Collections.singletonList(node.getNodeName()));V1NodeSelectorTerm nodeSelectorTerm = new V1NodeSelectorTerm();nodeSelectorTerm.setMatchExpressions(Collections.singletonList(nodeSelectorRequirement));nodeAffinity.setRequiredDuringSchedulingIgnoredDuringExecution(new V1NodeSelector().nodeSelectorTerms(Collections.singletonList(nodeSelectorTerm)));affinity.setNodeAffinity(nodeAffinity);taskTemplate.setAffinity(affinity);// 容器配置保持不變V1Container taskContainer = new V1Container();taskContainer.setName("container-" + (i + 1) + "-" + node.getNodeName().replace(".", "-"));taskContainer.setImage(container.getImage());Map<String, String> nodeMap = (Map<String, String>) node_resource_map.get(node.getNodeName());V1ResourceRequirements resources = getResourceLimit(nodeMap);taskContainer.setResources(resources);List<String> command = new ArrayList<>(container.getCommand());List<String> args = getDistributedArgs(nodeMap);command.add("-m");command.add("torch.distributed.launch");command.addAll(args);taskContainer.setCommand(command);taskTemplate.setContainer(taskContainer);templates.add(taskTemplate);}dag.setTasks(dagTasks);mainTemplate.setDag(dag);templates.add(mainTemplate);spec.setTemplates(templates);} else {mainTemplate.setContainer(container);spec.setTemplates(Collections.singletonList(mainTemplate));}spec.setEntrypoint("rl-main");workflow.setSpec(spec);return workflow;}創建argo workflow
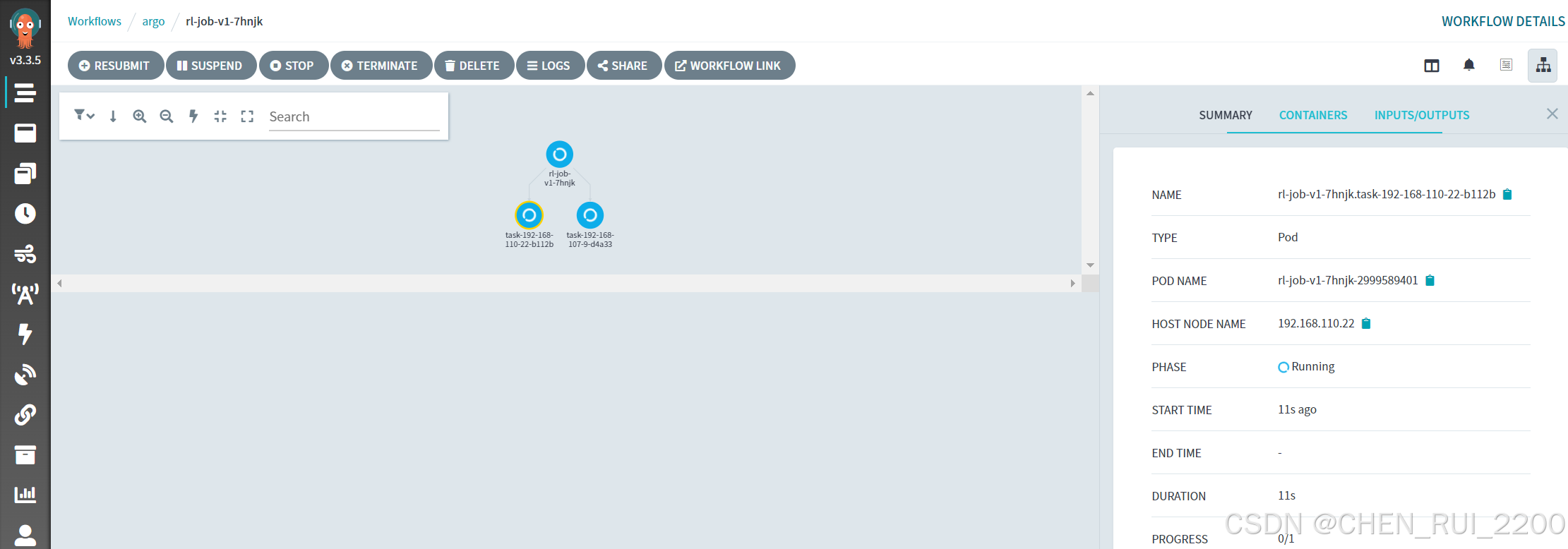
查看作業信息
container:name: container-1-192-168-110-22image: '192.168.110.125:8443/agent/ppo_torch:3.1'command:- python- '-m'- torch.distributed.launch- '--nproc_per_node=1'- '--nnodes=2'- '--node_rank=0'- '--master_addr=192.168.110.22'- '--master_port=25195'- /code/rl/BladeTrain.pyresources:limits:cpu: 512mhuawei.com/Ascend310P: '0'huawei.com/Ascend910: '0'memory: 1Ginvidia.com/gpu: '0'requests:cpu: 512mhuawei.com/Ascend310P: '0'huawei.com/Ascend910: '0'memory: 1Ginvidia.com/gpu: '0'
查看端口工作狀態,看到子節點連接過來

但是一段時間后 dag task上master節點錯誤掛掉了
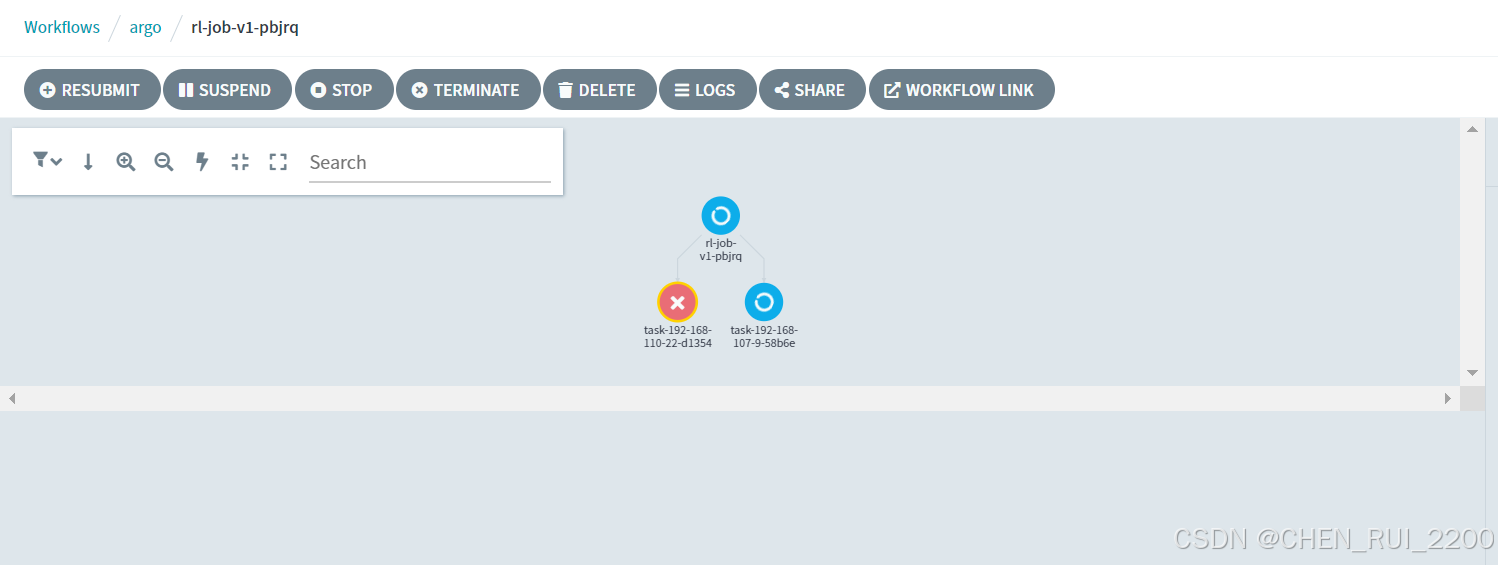
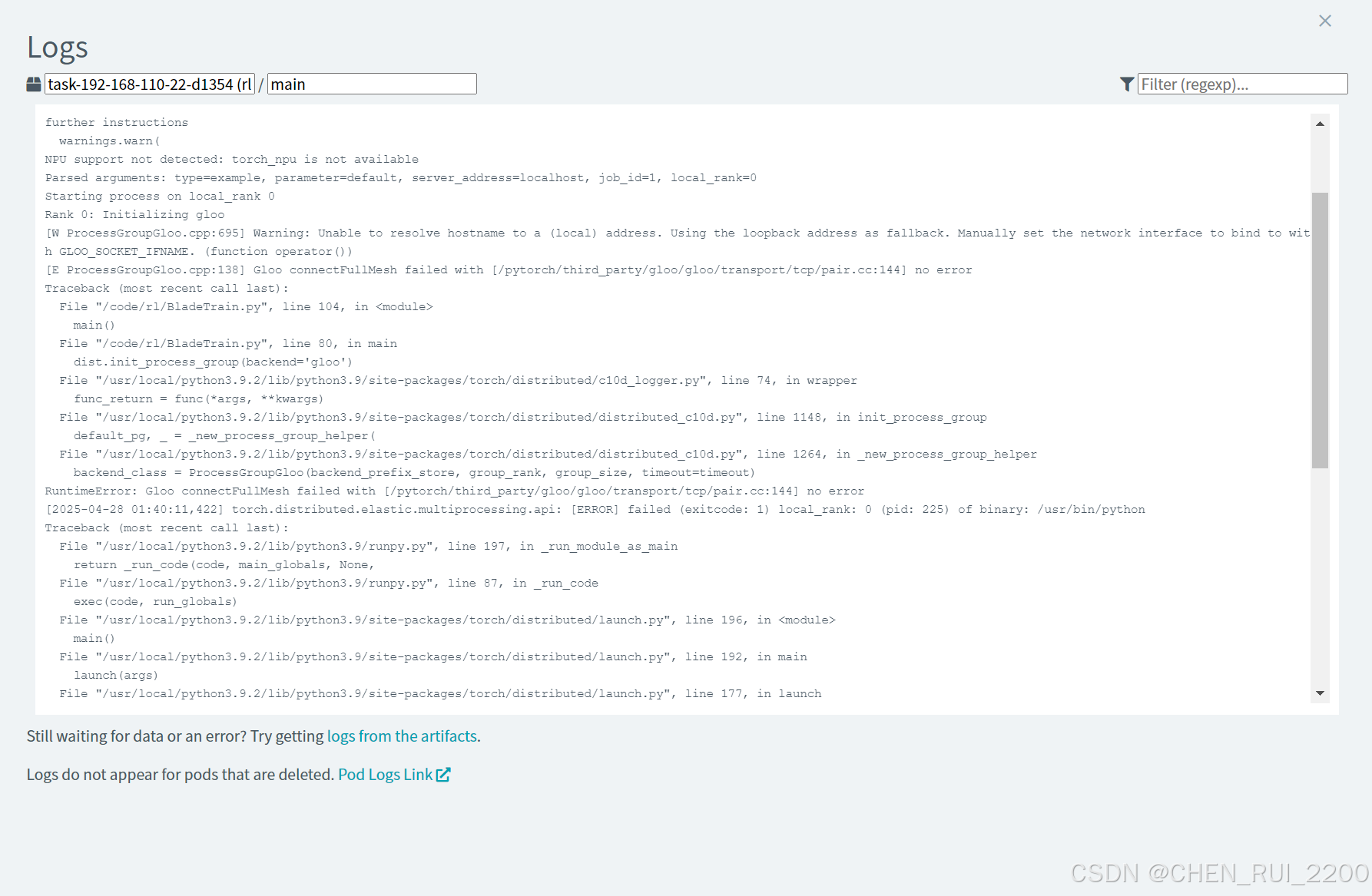
查看日志
File "/usr/local/python3.9.2/lib/python3.9/runpy.py", line 87, in _run_codeexec(code, run_globals)File "/usr/local/python3.9.2/lib/python3.9/site-packages/torch/distributed/launch.py", line 196, in <module>main()File "/usr/local/python3.9.2/lib/python3.9/site-packages/torch/distributed/launch.py", line 192, in mainlaunch(args)File "/usr/local/python3.9.2/lib/python3.9/site-packages/torch/distributed/launch.py", line 177, in launchrun(args)File "/usr/local/python3.9.2/lib/python3.9/site-packages/torch/distributed/run.py", line 797, in runelastic_launch(File "/usr/local/python3.9.2/lib/python3.9/site-packages/torch/distributed/launcher/api.py", line 134, in __call__return launch_agent(self._config, self._entrypoint, list(args))File "/usr/local/python3.9.2/lib/python3.9/site-packages/torch/distributed/launcher/api.py", line 264, in launch_agentraise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
/code/rl/BladeTrain.py FAILED
------------------------------------------------------------
Failures:<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:time : 2025-04-28_01:40:11host : feitengrank : 0 (local_rank: 0)exitcode : 1 (pid: 225)error_file: <N/A>traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
============================================================
Error: exit status 1問題分析
GLOO_SOCKET_IFNAME 是一個環境變量,用于指定 PyTorch 的 gloo 后端在進行分布式通信時綁定的網絡接口(網卡)。讓我詳細解釋一下它的作用和背景:
作用
GLOO_SOCKET_IFNAME 告訴 gloo 后端(一個基于 TCP 的通信庫)在當前機器上使用哪個網絡接口來進行分布式進程之間的通信。換句話說,它綁定了通信所使用的網卡,從而決定了通過哪個網絡接口發送和接收數據。
- 為什么需要它? 在分布式訓練中,多個進程(可能運行在同一臺機器或不同機器上)需要通過網絡相互通信。gloo 默認會嘗試自動選擇一個網絡接口,但如果機器有多個網卡(例如 eth0、eth1 或虛擬接口),或者網絡環境復雜(如容器化環境 Kubernetes),它可能會選擇錯誤的接口(例如回環接口 lo),導致通信失敗或無法連接到其他節點。
- Warning: Unable to resolve hostname to a (local) address. Using the loopback address as fallback.??這表明 gloo 無法正確解析主節點地址(192.168.110.22),于是退回到使用回環地址(127.0.0.1)。但回環地址只能用于本地通信,無法連接到其他機器或 pod,因此造成了 connectFullMesh failed 的錯誤。設置 GLOO_SOCKET_IFNAME 可以強制 gloo 使用正確的網卡,避免這種問題。
它本質上是綁定使用某個網卡,而這個網卡通常關聯著一個或多個 IP 地址。具體來說:
- 你通過設置 GLOO_SOCKET_IFNAME 指定網卡的名稱(例如 eth0),gloo 會使用這個網卡的 IP 地址進行通信。
- 如果一臺機器有多個網卡(例如一個內網接口 eth0: 192.168.110.x,一個外網接口 eth1: 10.0.0.x),GLOO_SOCKET_IFNAME 確保 gloo 使用你指定的那個網卡,而不是隨機選擇或默認回環。
ip addr?輸出所有網絡接口,根據 ip addr 的輸出,選擇正確的網卡名稱(例如 enp11s0f0)
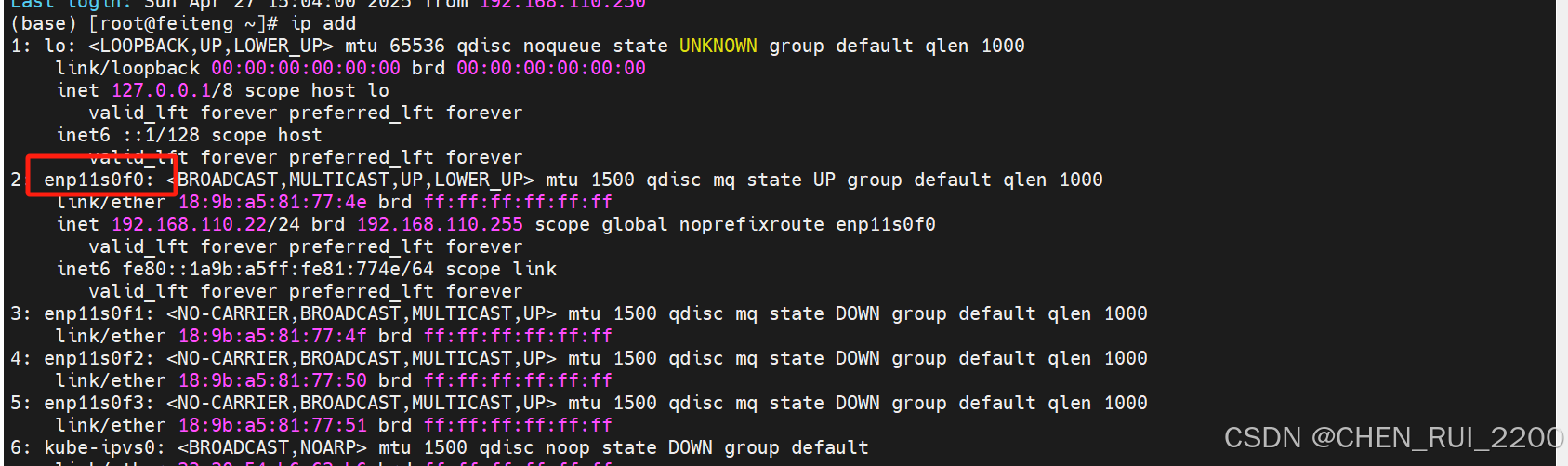
GLOO_SOCKET_IFNAME 的作用是指定 gloo 通信綁定的網卡,避免它選擇錯誤的網絡接口(比如回環)。在測試場景中設置它為正確的網卡可以解決 gloo 回退到 localhost 的問題,從而修復分布式訓練的連接失敗。嘗試著在 Argo 工作流中加上這個環境變量,然后觀察是否還有錯誤。
兩個節點上的網卡名都需要配置
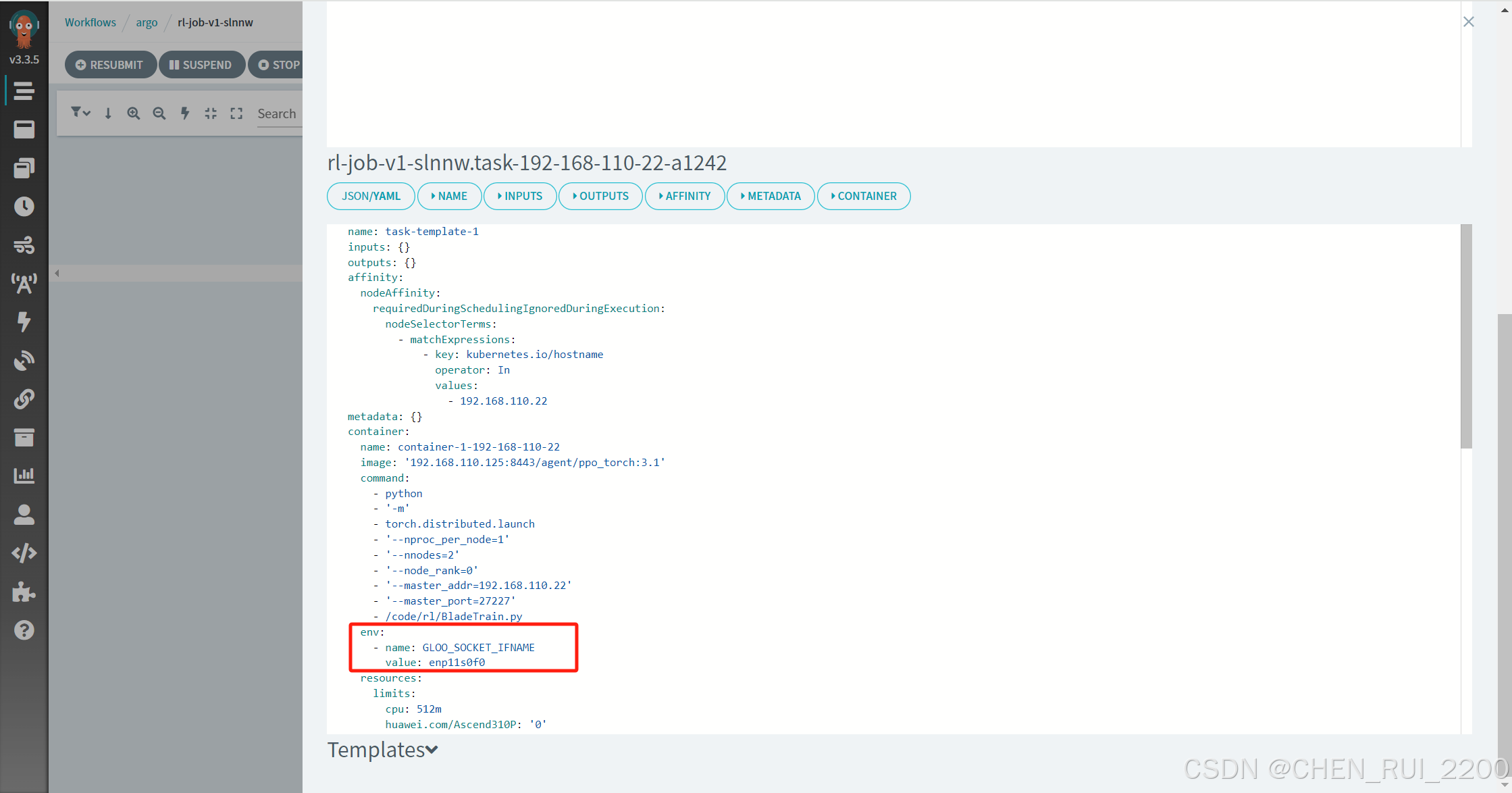
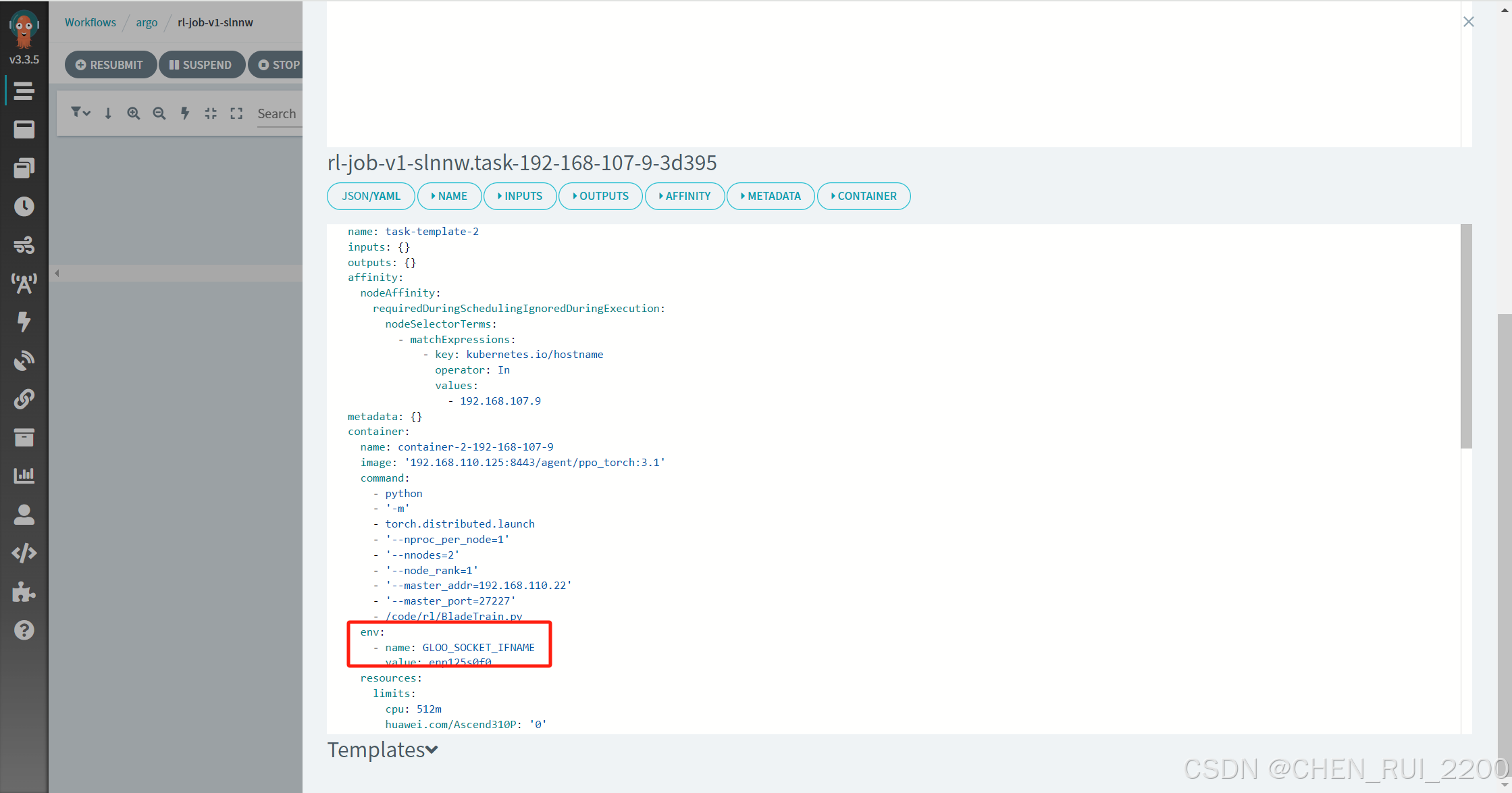
再次啟動實現多機多卡運行了
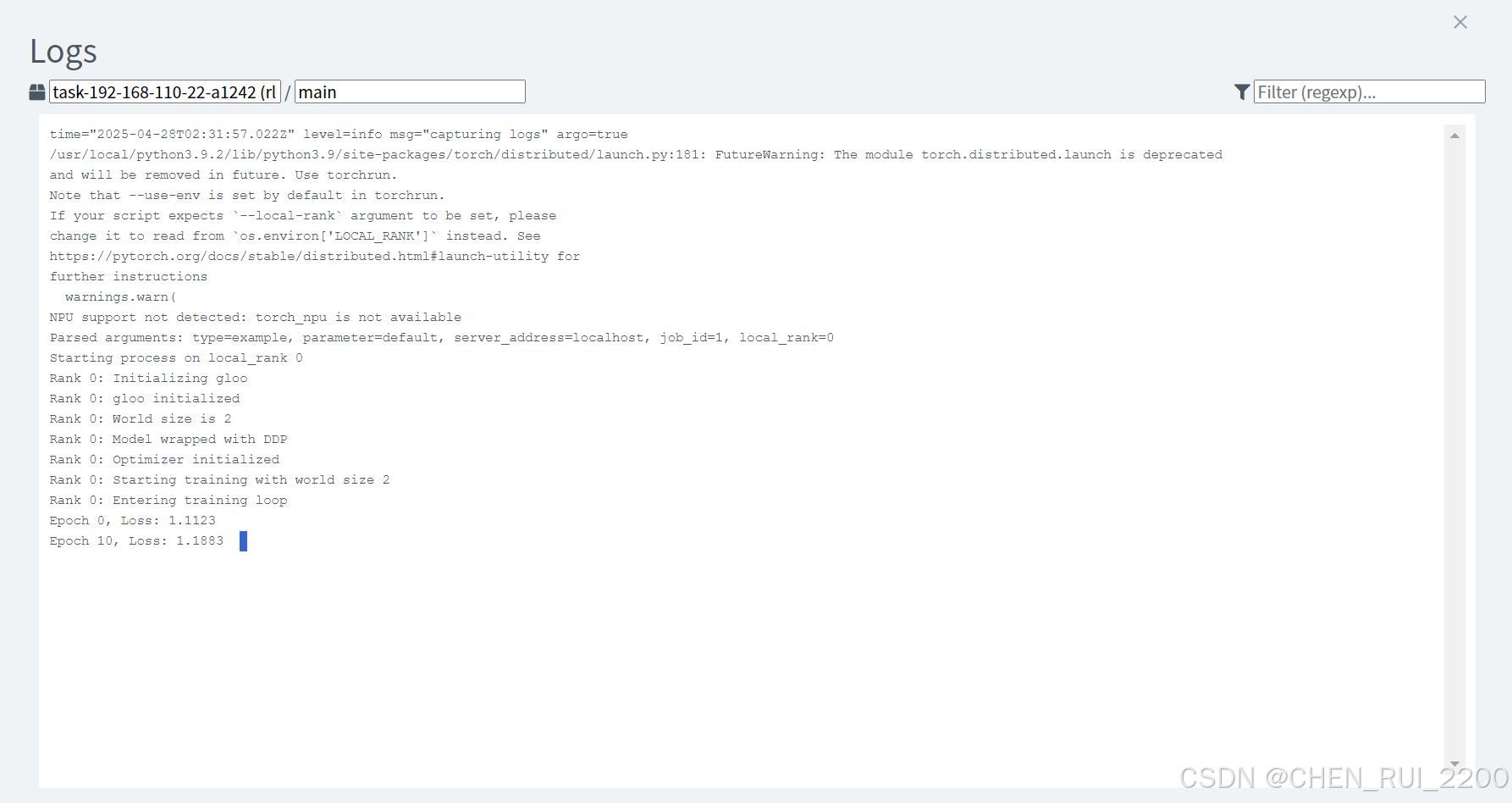
目前使用的cpu訓練, 通訊用的gloo , 因為我只有一臺機器上裝有npu的卡
那么是否可以級聯cpu+npu共同訓練呢?
torch_npu.npu.set_device(local_rank) 的作用
- 功能:
- torch_npu.npu.set_device(local_rank) 是 torch_npu 模塊提供的函數,用于在昇騰 NPU(例如 Ascend 310P)上設置當前進程使用的設備。
- local_rank 通常是分布式訓練中的一個參數,表示當前進程在本地節點上的設備編號(從 0 開始)。
- 它的作用類似于 PyTorch 中的 torch.cuda.set_device(local_rank),但專用于華為的 NPU。
- 具體作用:
- 設備分配:在多 NPU 環境下,確保每個進程綁定到特定的 NPU。例如,如果一臺機器有 4 個 NPU,local_rank=0 的進程使用 NPU 0,local_rank=1 使用 NPU 1。
- 上下文隔離:設置后,后續的 NPU 操作(例如張量計算)會默認在這個設備上執行,避免設備沖突。
- 分布式訓練支持:與 torch.distributed.launch 配合使用,確保每個進程在正確的設備上運行。
- 使用場景:
- 在代碼中:
if NPU_AVAILABLE:torch_npu.npu.set_device(local_rank)device = torch.device(f'npu:{local_rank}')dist.init_process_group(backend='hccl') else:device = torch.device('cpu')dist.init_process_group(backend='gloo') - 這里 set_device(local_rank) 是為了在 NPU 可用時,將進程綁定到特定 NPU。
- 在代碼中:
- 是否必須?:
- 如果不調用 set_device,PyTorch 默認使用設備 0(npu:0),可能會導致多進程競爭同一個 NPU,引發錯誤或性能問題。
- 在單 NPU 或非分布式環境下,可以省略,但分布式訓練中通常需要。
是否可以不用 torch_npu,一臺機器用昇騰 310P,另一臺用 CPU?
在一臺機器上使用昇騰 310P(NPU),另一臺機器使用 CPU,通過 torch.distributed.launch 進行分布式訓練,同時盡量避免依賴 torch_npu。得分析可行性和實現方式。
可行性分析
- 可以實現,但有條件:
- PyTorch 的分布式訓練(torch.distributed)支持異構設備(例如一臺機器用 NPU,另一臺用 CPU),但需要正確配置通信后端和設備。
- torch_npu 是華為專為昇騰 NPU 設計的適配模塊,如果你不用 torch_npu,需要確保 NPU 被 PyTorch 原生識別(通常不行,因為 PyTorch 原生不支持 Ascend NPU)。
- 通信后端(backend)需要兼容兩臺機器:NPU 通常用 hccl(Huawei Collective Communication Library),CPU 用 gloo。混合使用需要特別處理。
- 如果不使用 torch_npu,昇騰 310P 無法被 PyTorch 直接識別為計算設備(不像 CUDA GPU)。torch.distributed.launch 依賴一致的設備和后端配置,混合 NPU 和 CPU 會增加復雜性。
看樣子不現實,因為 PyTorch 原生不認識昇騰 310P,必須用 torch_npu 支持 NPU。
所以等采購到位后再測試兩臺機器上都使用torch_npu進行訓練
![[Mac] 使用homebrew安裝miniconda](http://pic.xiahunao.cn/[Mac] 使用homebrew安裝miniconda)
——環境搭建)
)




采樣)
)




![[密碼學實戰]商用密碼產品密鑰體系架構:從服務器密碼機到動態口令系統](http://pic.xiahunao.cn/[密碼學實戰]商用密碼產品密鑰體系架構:從服務器密碼機到動態口令系統)


——4.28)
在圖像分類中的應用)
》)
