介紹
傳統的對象檢測模型大多是封閉詞匯類型,只能識別有限的固定類別。增加新的類別需要大量的注釋數據。然而,現實世界中的物體類別幾乎無窮無盡,這就需要能夠檢測未知類別的開放式詞匯類型。對比學習(Contrastive Learning)使用成對的圖像和語言數據,在這一挑戰中備受關注。著名的模型包括 CLIP,但將其應用于物體檢測,如在訓練過程中處理未見類別,仍然是一個挑戰。
本文使用標準視覺轉換器(ViT)建立了一個開放詞匯對象檢測模型——開放世界定位視覺轉換器(OWL-ViT),只做了極少的修改。該模型在大型圖像-文本對的對比學習預訓練和端到端檢測的微調方面表現出色。特別是,使用類名嵌入可以實現對未學習類別的零檢測。
OWL-ViT 在單次檢測方面也很強大,因為它可以使用圖像嵌入和文本作為查詢。特別是在 COCO 數據集中,對于未經訓練的類別,OWL-ViT 比以前的一流模型有了顯著的性能提升。這一特性對于檢測難以描述的對象(如特殊部件)非常有用。
我們還證明,增加預訓練時間和模型大小能持續提高檢測性能。特別是,我們發現,即使圖像-文本對的數量超過 200 億,開放詞匯檢測的性能改善仍在繼續。此外,通過在檢測微調中適當使用數據擴展和正則化,即使使用簡單的訓練配方,也能實現較高的零次和單次檢測性能。
建議方法
OWL-ViT 是一個兩階段的學習過程,具體如下:
- 使用大型圖像-文本對進行對比預訓練。
- 將學習過渡到檢測任務。
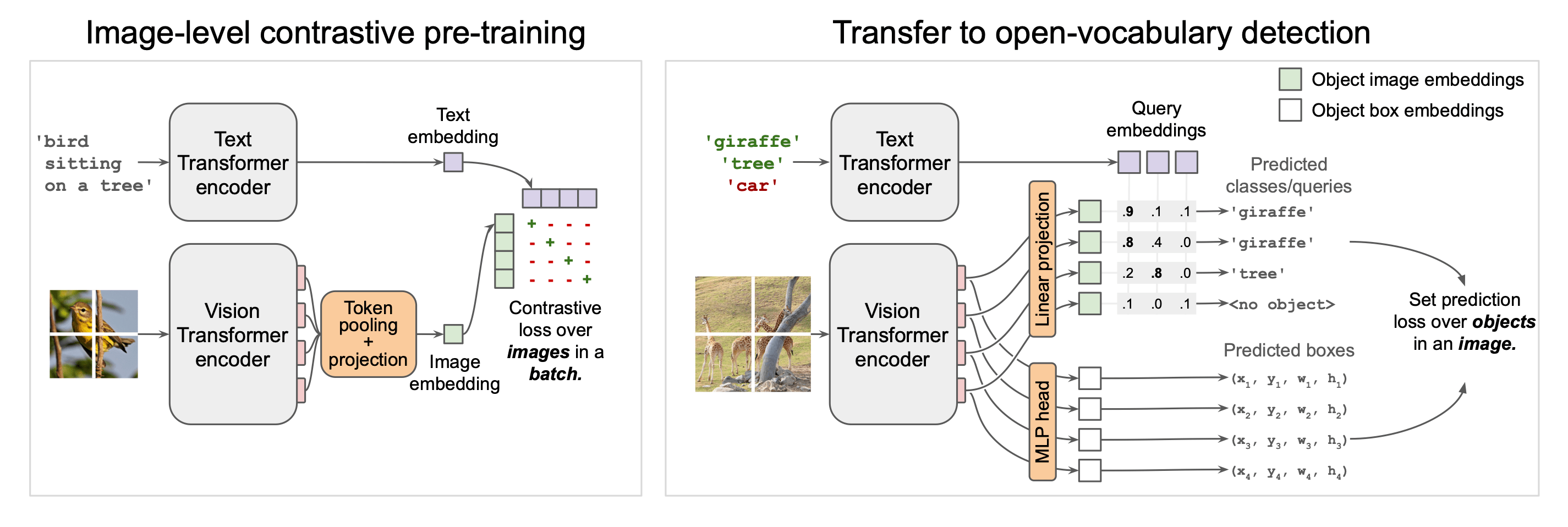
使用大型圖像-文本對進行對比預訓練
這樣做的目的是將視覺和語言模式映射到一個統一的表示空間中。學習過程使用圖像和文本編碼器進行訓練,以處理每種模態,使相關的圖像和文本嵌入相互靠近,并使不相關的圖像和文本嵌入相互遠離。
圖像編碼器采用視覺變換器(ViT)架構,該架構具有可擴展性和強大的表示能力。圖像被劃分為多個片段,每個片段都作為一個標記進行處理,從而實現具有空間關系的特征提取。在這一過程中,ViT 標記化過程將圖像轉換成一串固定長度的標記,并通過變換器層學習各補丁之間的關系。另一方面,文本編碼器處理標記化的句子,并生成濃縮整個句子含義的嵌入。文本表示通常是通過轉換器最后一層的句末標記(EOS 標記)輸出獲得的。
OWL-ViT 預訓練的一個重要設計特點是圖像和文本編碼器是獨立的。這種設計允許預先計算查詢文本和圖像的嵌入,從而大大提高了推理過程中的計算效率。這種獨立性還為在同一架構中處理查詢(無論是文本還是圖像)提供了靈活性。
將學習過渡到檢測任務
在這里,首先去掉了 ViT 中最后的標記池層(通常用于提取整個圖像的表示)。取而代之的是,將一個小型分類頭和一個盒式回歸頭直接連接到每個輸出標記。這種設計確保了 ViT 中的每個輸出標記都與圖像中的不同空間位置相對應,每個標記都代表一個潛在的候選對象。分類頭預測物體類別,而方框回歸頭則估算相應邊框的位置。
傳統的對象檢測模型在分類層中學習每個類別的固定權重,而 OWL-ViT 不使用固定的類別分類層。相反,對象類別名稱被輸入到文本編碼器中,生成的文本嵌入直接用作分類頭的權重。只要給出類名,即使是未經訓練的類,這種方法也能讓模型檢測到相應的對象。
轉換學習采用 DEtection TRansformer (DETR) 中使用的兩端匹配損失來預測物體的位置。這種損失是模型預測的邊框與正確邊框之間的最佳映射,并計算每一對邊框的損失。這樣可以調整模型,使預測的物體位置和實際的物體位置保持一致。
在分類方面,焦點 sigmoid 交叉熵用于考慮長尾分布數據集的不平衡。與經常出現的類別相比,這種損失函數對罕見類別的誤報懲罰更大,從而提高了罕見類別的檢測性能。
此外,對于聯合數據集,即并非所有圖像都注釋了所有類別,但每幅圖像中只注釋了有限數量的類別的數據集,對于每幅訓練圖像,查詢是注釋了的類別(正例明確標注為不存在的類別(負面示例)作為查詢。這樣,模型就能根據明確識別的信息進行學習,并減少對負面示例的錯誤處理。為了進一步避免對未注明類別的誤解,我們在訓練過程中隨機選擇類別并將其作為 “偽負例”,為每幅圖像準備了至少 50 個負例查詢。
試驗
實驗中使用了多個數據集。在訓練中,我們主要使用 OpenImages V4(約 170 萬張圖像,600 多個類別)、Visual Genome(8.45 萬張圖像,包括大量對象關系信息)和 Objects365(包含 365 個類別的大型檢測數據集)。一方面,評估使用了長尾分布。同時,評估主要使用了長尾分布的 LVIS v1.0,特別是用于驗證零鏡頭性能。此外,COCO 2017 用于比較標準對象檢測性能,Objects365 用于驗證一般檢測能力。
對開放詞匯對象檢測的評估主要集中在 LVIS 數據集上未經訓練類的性能上。在該實驗中,OWL-ViT 在零拍攝條件下的 APrare 達到了 31.2%,明顯優于現有的先進方法。這表明,在預訓練過程中使用圖像-文本對能夠從類名和描述中有效提取對象的語義特征。尤其是文本條件檢測法,只需輸入類別名稱的文本查詢,就能高精度地檢測出未學習過的類別,這是該方法與以往方法的主要區別。
Hewshot 圖像條件檢測實驗評估了 COCO 數據集上圖像查詢的檢測性能;OWL-ViT 比現有的最先進方法提高了 72%,AP50 分數從 26.0 提高到 41.8。這些結果表明,OWL-ViT 綜合利用了視覺和語言表征,即使對于沒有給出名稱的未知對象,也能提供出色的檢測性能。特別是,圖像條件檢測通過使用包含特定對象的圖像嵌入作為查詢,有效地檢測出了視覺上相似的對象。
對縮放特性的分析證實,增加預訓練中使用的圖像-文本對數量和模型大小可持續提高檢測性能。特別是,在預訓練中使用超過 200 億個圖像-文本對往往能顯著提高零點檢測性能。這一結果表明,在預訓練中使用大規模數據也能有效地過渡到物體檢測任務。同樣明顯的是,基于視覺轉換器的模型比其他架構具有更好的擴展性能,尤其是在模型規模較大的情況下。
拓展與增強
背景知識
- 對比學習的重要性:對比學習通過將圖像和文本對齊到一個共享的嵌入空間,使得模型能夠理解視覺和語言之間的語義關系。這對于開放詞匯對象檢測至關重要,因為它允許模型通過文本描述來識別未見過的類別。
- 視覺轉換器(ViT)的優勢:ViT 將圖像分割成固定大小的補丁,并將每個補丁視為一個標記,類似于自然語言處理中的單詞。這種設計使得 ViT 能夠捕捉圖像中的全局特征和局部特征,從而在視覺任務中表現出色。
相關工作
- CLIP 模型:CLIP 是一個開創性的模型,它通過對比學習將圖像和文本嵌入到一個共享的向量空間中。雖然 CLIP 主要用于圖像分類和文本生成任務,但其思想為 OWL-ViT 提供了重要的啟發。OWL-ViT 在此基礎上進一步擴展,將對比學習應用于對象檢測任務。
- DETR 模型:DETR 使用 Transformer 架構來處理對象檢測任務,通過端到端的方式學習對象的位置和類別。OWL-ViT 借鑒了 DETR 的思想,使用兩端匹配損失來優化檢測性能。
實際應用場景
- 工業檢測:在工業環境中,OWL-ViT 可以用于檢測生產線上的缺陷或異常部件。通過提供圖像查詢或類別名稱,模型能夠快速定位并識別問題,從而提高生產效率和質量控制。
- 自動駕駛:在自動駕駛場景中,OWL-ViT 可以幫助車輛識別道路上的未知障礙物或交通標志。通過實時檢測和識別,車輛可以做出更安全的決策。
- 醫療影像分析:在醫療領域,OWL-ViT 可以用于分析醫學影像,如 X 光或 CT 掃描。通過提供疾病名稱或圖像示例,模型能夠幫助醫生快速定位病變區域,輔助診斷。
行業影響
- 推動開放詞匯檢測的發展:OWL-ViT 的出現為開放詞匯對象檢測領域帶來了新的突破。它證明了通過對比學習和 Transformer 架構,可以有效地識別未見過的類別,為未來的研究提供了新的方向。
- 促進多模態學習的發展:OWL-ViT 結合了圖像和文本兩種模態,展示了多模態學習的強大潛力。這種結合不僅提高了檢測性能,還為其他領域(如自然語言處理和計算機視覺的交叉領域)提供了新的思路。
總結
利用視覺轉換器進行簡單的開放詞匯對象檢測(OWL-ViT)是一項開創性的研究。這項研究的最大貢獻在于,它利用圖像和文本的大規模對比預訓練,實現了對未知類別的零次和一次對象檢測,而且準確率很高。特別是直接使用預訓練的文本編碼器輸出作為類嵌入,而不是使用固定的類分類層的設計,在靈活性和可擴展性方面取得了重大進展。



















)