基本介紹
隨著大語言模型(LLM)的規模不斷擴大,模型的推理效率和計算資源的需求也在迅速增加。DeepSeek-V2作為當前熱門的LLM之一,通過創新的架構設計與優化策略,在資源受限環境下實現了高效推理。
本文將詳細介紹DeepSeek-V2是如何通過“異構和局部MoE推理”、優化算子以及量化技術,實現推理效率的顯著提升。此外,本文還將探討MoE模型的背景、優勢、應用場景,以及未來可能的發展趨勢。
官方對這塊做了詳細的解讀,有興趣可以詳細了解:https://kvcache-ai.github.io/ktransformers/en/deepseek-v2-injection.html
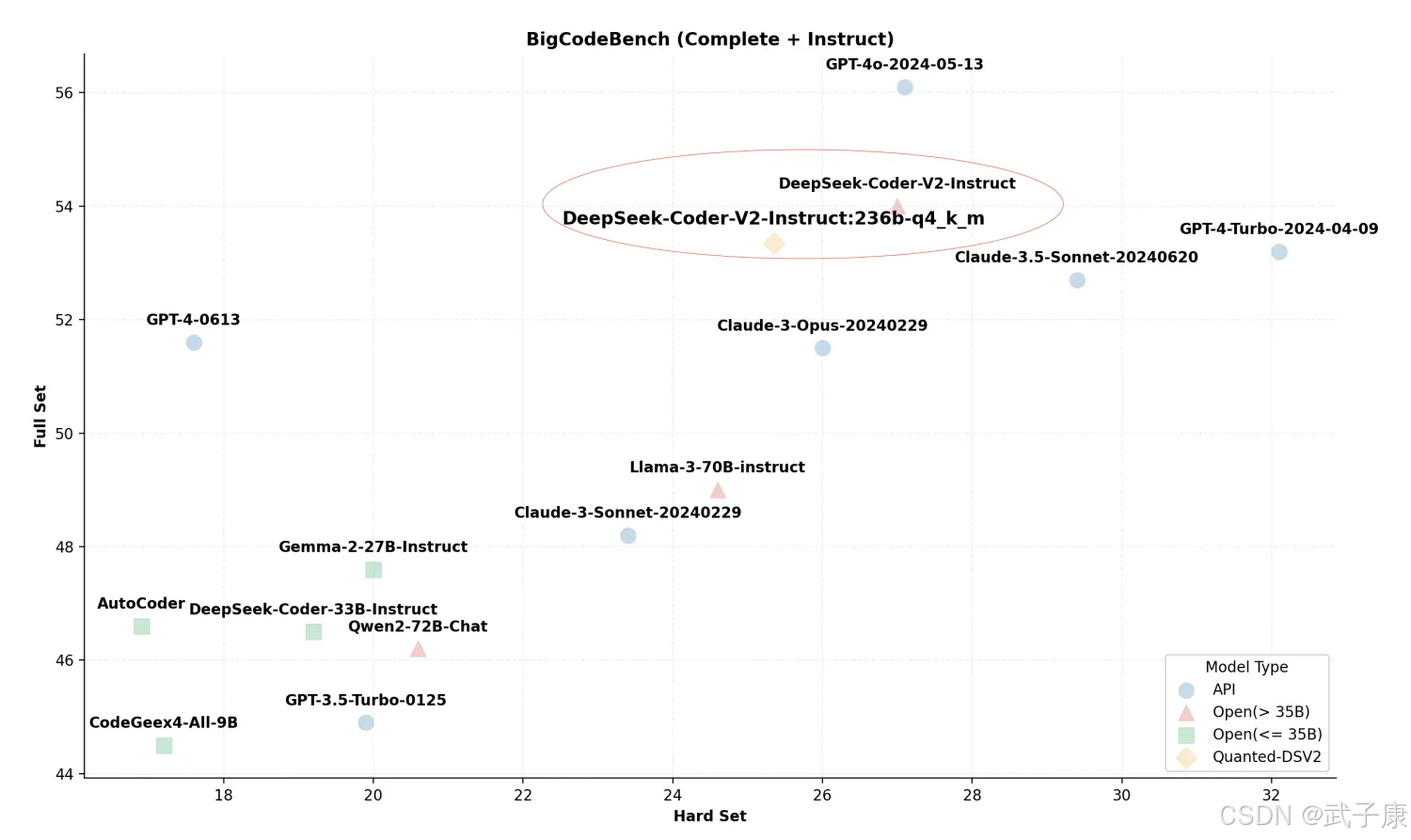
簡單來說,是通過 “異構和局部 MoE 推理” 實現的。
【MoE = mixture-of-experts 專家混合模型】
在 V2 版本中,總共是 2360 億個參數,每個 token 會激活 210 億個參數。
在傳統注意力機制模型中,采用的是分組查詢注意力(Grouped-Query Attention = GQA);在 DeepSeek-V2 中引入了多頭潛在注意力(Multi-head Latent Attention = MLA)。
通過這種方式減少了推理過程中所需要的KV緩存的大小,以此來提高效率。
DeepSeek-V2 本身大約需要:80GB GPU * 8 才可以運行,但是在項目組努力下,實現了在 21GB VRAM 和 136GB DRAM 的機器上運行。
什么是DeepSeek-V2?
DeepSeek-V2是一種采用專家混合模型(Mixture-of-Experts, MoE)的新型大語言模型。在V2版本中,該模型共擁有2360億個參數,但每個token僅激活210億個參數,大幅減少了推理計算量。
傳統的Transformer模型通常采用分組查詢注意力機制(Grouped-Query Attention, GQA),而DeepSeek-V2則引入了多頭潛在注意力機制(Multi-head Latent Attention, MLA),從而有效降低推理階段的KV緩存大小,提升推理性能。
MoE(專家混合模型)的背景與優勢
- 專家混合模型最早由Jacobs等人在1991年提出,旨在通過多個子模型(專家)協作解決單個復雜問題。MoE模型具有以下優勢:
- 高效參數利用:通過稀疏激活機制,每個輸入僅激活少數專家,大大降低了推理成本。
- 強大的模型容量:相比傳統單一模型,MoE能夠以較少的計算資源實現更高的模型容量。
- 更好的泛化能力:不同的專家擅長處理不同類型的輸入,整體表現更加穩定和魯棒。
MoE 特點
- 減少計算復雜度:通過動態選擇激活的專家數量,DeepSeek 的 MoE 可以在保持較高模型表達能力的同時,顯著降低計算成本和推理時間。
- 大規模參數:DeepSeek 的 MoE 采用大規模的參數量(例如 2360 億個參數),但每個 token 只激活一部分參數,這使得推理過程更加高效,避免了計算冗余。
- 提高推理速度:通過專家模型的局部激活和精簡的計算,DeepSeek 的 MoE 在推理速度上取得了顯著的提升。例如,DeepSeek 在 V2 版本中的 MoE 推理性能相比傳統的全模型推理提升了約 6 倍。
MoE 工作原理
- 專家選擇:MoE 模型會根據輸入數據自動選擇一些專家模型進行推理,而不是讓所有專家參與計算。這種選擇機制通常依賴于輸入的特征或預設的策略。例如,輸入的不同部分可以激活不同的專家,從而根據任務的需求只激活一部分網絡,減少不必要的計算。
- 局部專家:與傳統的深度學習模型相比,MoE 模型并不會在每個時間步都使用所有的參數,而是通過“局部專家”策略僅激活一部分專家來處理輸入數據。這意味著模型會動態選擇合適的專家進行推理,節省了計算資源。
- 異構結構:DeepSeek 在其 MoE 機制中采用了異構結構,能夠在不同的硬件環境下靈活運行。比如,可以根據計算需求調整使用的專家數目,或者根據 GPU 的可用資源選擇不同的網絡結構。
MoE 的應用
- 大規模語言模型:DeepSeek 的 MoE 模型在自然語言處理任務中表現出色,特別是在生成式任務和大規模文本推理中,MoE 的優勢可以有效減少計算和提升響應速度。
- 高效推理:由于 MoE 能夠根據輸入的內容選擇性地激活專家,DeepSeek 的推理過程非常高效,尤其適用于需要大規模計算和實時響應的應用場景,如聊天機器人、搜索引擎優化等。
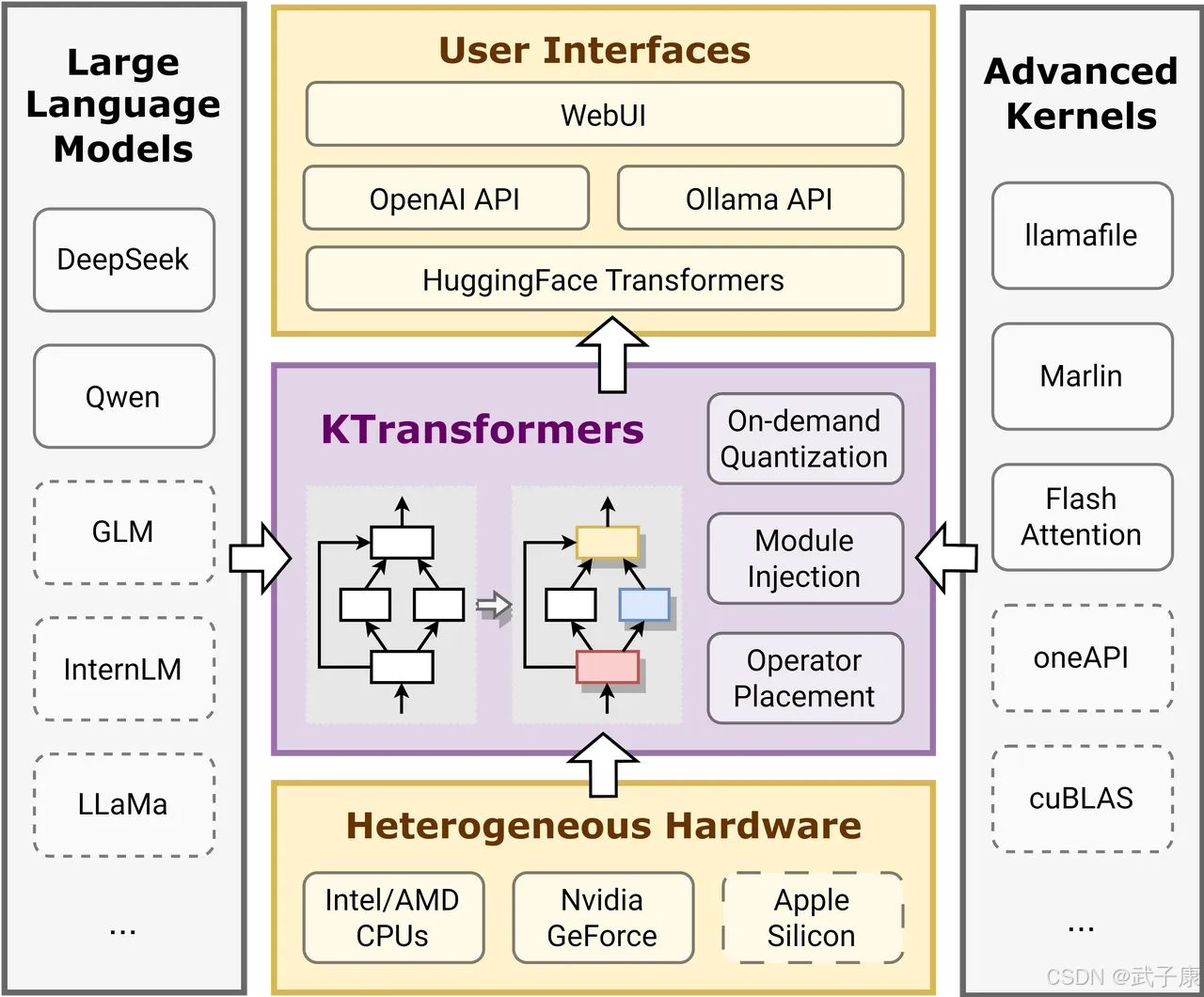
KTransformers對DeepSeek-V2的關鍵優化
優化的MLA算子
原始DeepSeek-V2的MLA算子在解壓后進行KV緩存鍵值對存儲,這種方法會擴大KV緩存大小并降低性能。KTransformers項目組基于原始論文,開發了專門針對推理場景的優化版本,大幅減少KV緩存大小,同時提高算子的計算性能,充分發揮GPU的計算能力。
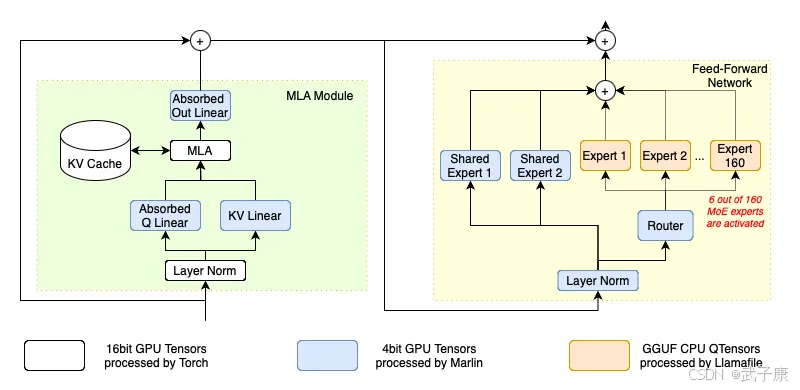
高級量化內核
原始DeepSeek-V2以BF16精度運行,需要約470GB的存儲空間。項目組采用了社區中廣泛認可的GGUF量化方法,并開發了直接處理量化數據類型的高級內核,有效優化了模型的推理性能。此外,團隊選擇Marlin作為GPU內核,llamafile作為CPU內核。這些內核都是經過專門設計的,并通過專家并行性和其他優化策略,實現了高效的CPU端MoE推理,被稱為CPUInfer。
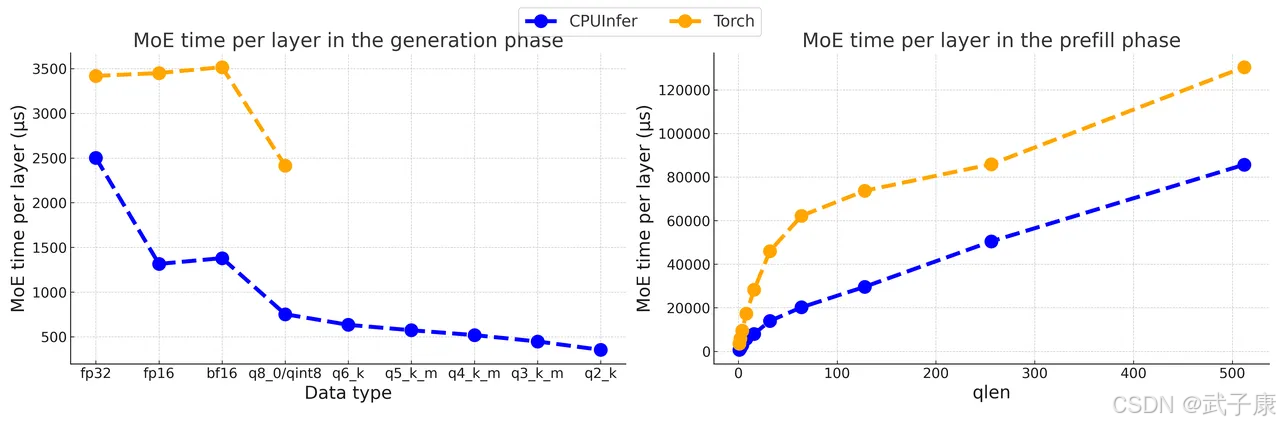
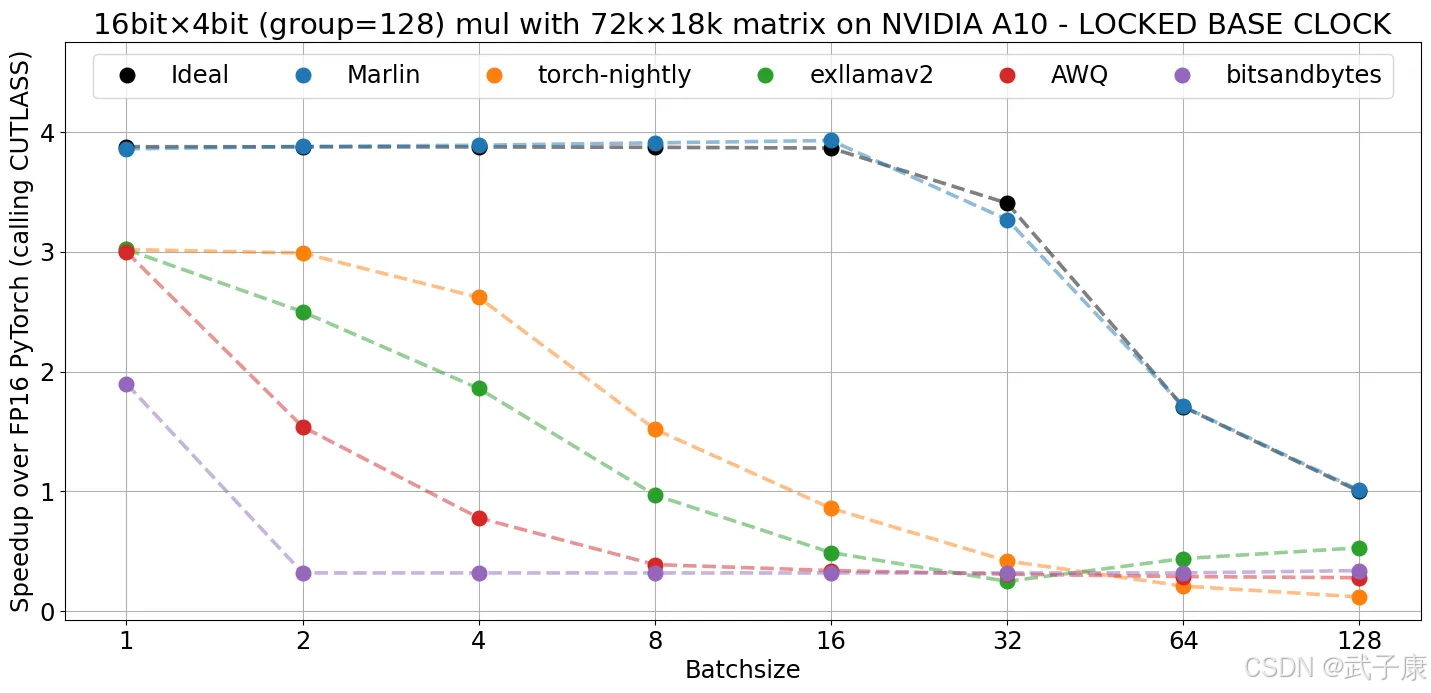
算術強度引導卸載策略
項目組采用了一種稱為“算術強度引導卸載”的策略,將計算最密集的參數策略性地存儲在GPU上,而非將全部2360億參數放入GPU內存中。
在DeepSeek-V2的每個Transformer Block中,有160位混合專家(MoE),占總參數的96%。但每個token僅激活其中的6個專家,因此解碼階段實際使用的MoE參數僅占3.75%。這一策略極大地減少了GPU的負擔,提升了計算資源的利用效率。
YAML模板配置實現優化
為實現上述優化,用戶需要定義特定的YAML配置文件,該配置文件主要包括以下三項關鍵優化規則:
- 將注意力模塊替換為優化的MLA算子。
- 將路由專家模塊替換為使用llamafile內核的CPUInfer。
- 將非注意力相關的線性模塊替換為Marlin內核。
具體的配置流程與細節,建議參考KTransformers官方文檔。
MoE模型的應用場景
MoE模型憑借其高效能的特性,廣泛應用于多種領域,包括但不限于:
- 自然語言處理(NLP):如語言生成、翻譯和問答系統。
- 計算機視覺:如大規模圖像分類、目標檢測任務。
- 推薦系統:高效處理大規模個性化推薦任務。
MoE模型未來發展趨勢
未來,MoE模型預計將朝著以下幾個方向發展:
- 更加高效的路由機制:優化專家選擇策略,進一步降低延遲。
- 跨模態MoE架構:結合視覺、語言、語音等多種數據類型,構建更加強大的多模態MoE模型。
- 資源受限環境部署優化:持續優化模型壓縮與量化技術,進一步降低部署門檻。
最后總結
通過上述優化,DeepSeek-V2能夠在僅有21GB VRAM與136GB DRAM的資源條件下穩定運行,展現了強大的推理能力。這些技術創新不僅使得超大規模語言模型的部署更具可行性,也為未來大模型的發展提供了寶貴的實踐經驗。
DeepSeek 的 MoE 通過靈活的專家選擇、局部激活和異構計算的設計,有效提升了模型的推理效率和計算能力。它的應用不僅限于自然語言處理,也可以擴展到其他需要大規模推理的任務中。
希望本文對你理解DeepSeek-V2及其優化策略有所幫助。如需進一步了解,推薦閱讀官方文檔以獲取更深入的信息。


















)
)