
目錄
一、引言
二、挑戰和貢獻
密集小目標和遮擋
實時性要求與精度權衡
復雜背景
三、MPE-YOLO模型細節
多級特征集成器(MFI)
感知增強卷積(PEC)
增強范圍C2f模塊(ES-C2f)
四、Coovally AI模型訓練與應用平臺
五、實驗
消融實驗
對比實驗
可視化分析
泛化研究
總結
一、引言
無人機航拍技術已廣泛應用于城市規劃、交通監控、災害評估等領域。通過自動分析航拍圖像中的目標(如車輛、行人、建筑物),我們可以快速獲取地理信息、監測城市動態。然而,現有的檢測算法在復雜環境下的小目標識別和準確率方面存在不足。針對這一問題,本文提出了一種基于YOLOv8的改進模型,即MPE-YOLO。

論文題目:
MPE?YOLO: enhanced small target detection in aerial imaging
論文鏈接:
https://www.nature.com/articles/s41598-024-68934-2
二、挑戰和貢獻
在無人機航拍圖像中,目標檢測面臨幾個具體的挑戰:
-
密集小目標和遮擋
低空拍攝的圖像通常包含大量密集的小目標,尤其是在城市或復雜地形中。由于距離較遠,這些目標在圖像中顯得較小,并且容易被遮擋。例如,建筑物可能相互遮擋,或者樹木可能遮擋停放的車輛。這種遮擋會導致目標特征被部分隱藏,從而影響檢測算法的性能。即使是先進的檢測算法,也難以在高密度和嚴重遮擋的環境中準確識別和定位所有目標。
-
實時性要求與精度權衡
無人機航拍圖像目標檢測必須滿足實時性要求,尤其是在監控和應急響應場景中。實現實時檢測需要降低算法的計算復雜度,而這往往與檢測精度相沖突。高精度檢測算法通常需要大量的計算資源和時間,而實時性要求算法能夠快速處理海量數據。挑戰在于如何在確保實時性的同時保持較高的檢測精度。這需要優化網絡架構,以有效地平衡參數數量和精度。
-
復雜背景
航拍圖像通常包含大量不相關的背景信息,例如建筑物、樹木和道路。背景信息的復雜性和多樣性會干擾小物體的正確檢測。此外,小物體的特征本身就不那么明顯。傳統的單階段和雙階段算法主要關注全局特征,可能會忽略對小物體檢測至關重要的細粒度特征。這些算法往往無法捕捉小物體的細節,導致檢測精度較低。因此,迫切需要更先進的深度學習模型和算法來處理這些細微的特征,從而提高小物體檢測的準確性。
針對上述問題,本研究基于 YOLOv8 模型提出了一種名為 MPE-YOLO 的算法,該算法在保持輕量級模型的同時,提升了小物體的檢測精度。
本研究的主要貢獻如下:
-
開發了一個具有分層結構的多級特征集成器 (MFI) 模塊,用于合并不同級別的圖像特征,從而增強場景理解能力并提高物體檢測精度。
-
提出了一個感知增強卷積 (PEC) 模塊,該模塊利用多切片操作和通道維度串聯來擴展感受野,從而提升模型捕獲目標細節信息的能力。
-
通過結合所提出的增強型范圍-C2f (ES-C2f) 操作并引入高效的特征選擇和利用機制,進一步增強了特征的選擇性使用,有效提高了小物體檢測的精度和魯棒性。
-
經過與其他各種目標檢測模型的全面對比實驗,MPE-YOLO 的性能顯著提升,證明了其有效性。
三、MPE-YOLO模型細節
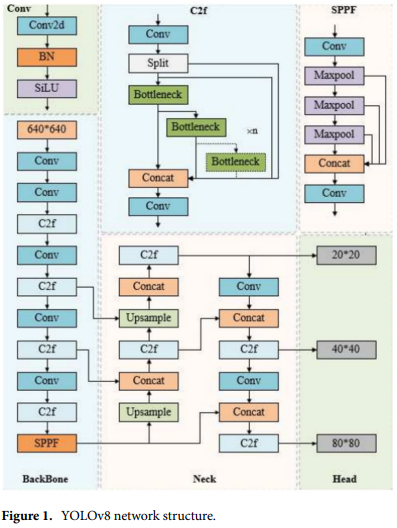
與其他模型相比,YOLOv8s 在準確率和模型復雜度之間取得了平衡。因此,本研究選擇 YOLOv8s 作為基線網絡。
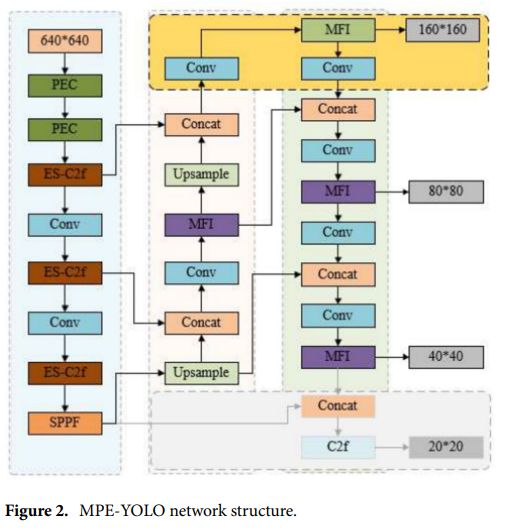
如圖所示,通過設計多級特征集成器(MFI)模塊,優化小目標特征的表示和信息融合,減少特征融合過程中的信息損失。感知增強卷積(PEC)模塊的引入取代了傳統的卷積層,擴展了網絡的細粒度特征處理能力,顯著提升了復雜背景下小目標的識別精度。將主干網絡中最后兩個下采樣層和20*20尺寸目標的檢測層替換為160*160尺寸小目標的檢測層,使模型能夠更加關注小目標的細節。最后,通過增強的scope-C2f(ES-C2f)模塊,利用通道擴展和多尺度卷積核的堆疊,進一步提升了模型的特征提取效率和運算效率。結合這些改進,MPE-YOLO在復雜環境下的小物體檢測任務中取得了良好的表現,并顯著提升了模型的準確率和性能。
-
多級特征集成器(MFI)
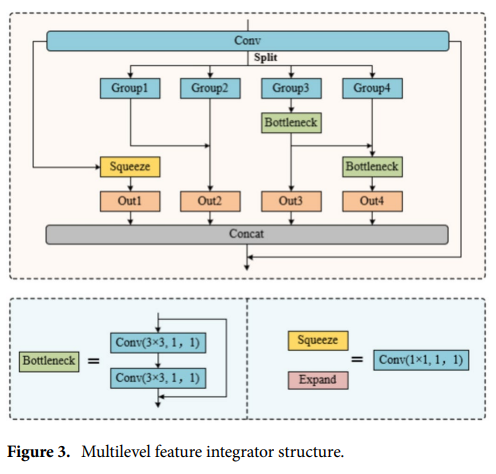
在目標檢測任務中,由于尺寸限制,小目標的特征表示往往不清晰,這會導致它們在特征融合過程中被忽略或丟失,從而降低檢測性能。為了有效解決這一問題,借鑒Res2Net的結構,設計了一種創新的多級特征集成器(MFI)。MFI模塊的結構如圖所示,旨在通過一系列細節策略優化小目標的特征表示和信息融合,減少特征信息的丟失,并抑制冗余和噪聲。
MFI模塊利用卷積操作降低輸入特征圖的通道維數,從而簡化后續計算過程。然后將輸入特征圖均勻分為4組,分別提取不同層次的語義信息(低層細節+高層語義),最后在通道維度融合,提升對小目標的感知能力。
-
感知增強卷積(PEC)
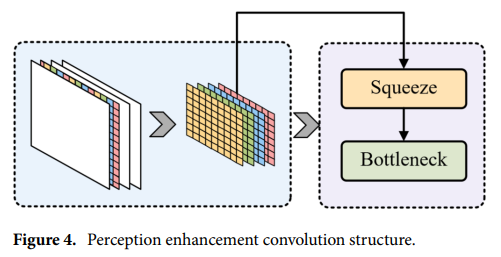
傳統的卷積神經網絡通常面臨諸如感受野固定、上下文信息利用不足以及環境感知受限等挑戰。尤其是在小目標檢測中,這些限制會顯著抑制模型的性能。為了克服這些問題,我們引入了感知增強卷積(PEC),如圖所示,這是一個專為骨干網絡設計的模塊,旨在取代傳統的卷積層。PEC的主要優勢在于,它在模型提取主要特征的階段引入了一個新維度,可以顯著擴展感受野并更有效地整合上下文信息,從而進一步加深模型對小目標及其環境的理解。
PEC模塊將輸入特征圖切割為4個子塊,拼接后壓縮通道維度,通過這種精細的空間維度劃分,生成的小塊在確保信息覆蓋均勻的同時,保留了重要的空間信息。為了實現更深層次的特征提取,還結合瓶頸結構強化細節提取,從而進一步提升了特征的計算效率。
-
增強范圍C2f模塊(ES-C2f)
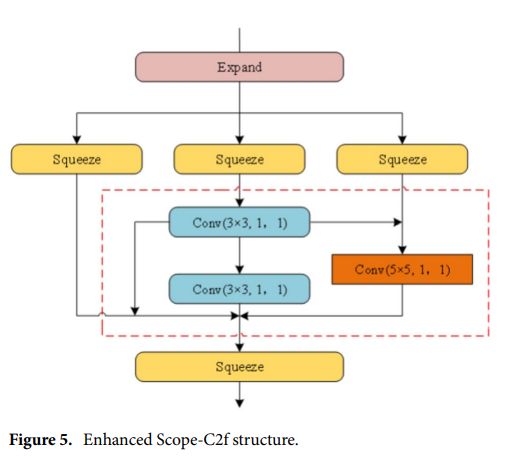
在處理航拍圖像中的小目標或低對比度目標時,原YOLOv8的C2f模塊對小目標特征表達能力不足,ES-C2f模塊專注于提升網絡捕捉細節的能力和特征利用效率,尤其是在小目標和低對比度目標的表達方面。通過擴展通道容量和多尺度卷積堆疊,增強對微小目標的敏感度。
ES-C2f模塊引入通道擴展策略,該策略致力于通過更廣泛的特征表示來增強網絡對小目標細節的敏感度,并提高對低對比度目標環境的適應性。為了在兼顧計算效率的同時擴展通道容量,ES-C2f 模塊巧妙地集成了一系列壓縮層。不僅簡化了特征表示,還保留了關鍵信息的捕獲。
四、Coovally AI模型訓練與應用平臺
如果你也想要使用模型進行訓練或改進,Coovally平臺滿足你的要求!
Coovally平臺整合了國內外開源社區1000+模型算法和各類公開識別數據集,無論是YOLO系列模型還是Transformer系列視覺模型算法,平臺全部包含,均可一鍵下載助力實驗研究與產業應用。
而且在該平臺上,無需配置環境、修改配置文件等繁瑣操作,一鍵上傳數據集,使用模型進行訓練與結果預測,全程高速零代碼!
具體操作步驟可參考:YOLO11全解析:從原理到實戰,全流程體驗下一代目標檢測
平臺鏈接:https://www.coovally.com
如果你想要另外的模型算法和數據集,歡迎后臺或評論區留言,我們找到后會第一時間與您分享!
五、實驗
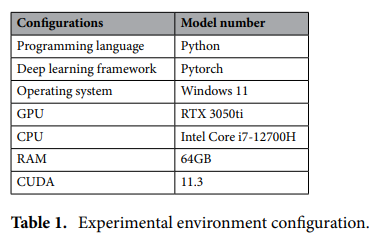
批次大小設置為 4 以避免內存溢出,學習率設置為 0.01,采用余弦退火算法調整學習率,隨機梯度下降 (SGD) 的動量設置為 0.937,并使用馬賽克法進行數據增強。輸入圖形的分辨率統一設置為 640×640。所有模型共訓練 200 個 epoch,訓練過程中未使用任何預訓練模型,以確保實驗的公平性。選擇隨機權重初始化,確保每個模型的初始權重來自同一分布。表1列出了訓練環境配置。
-
消融實驗
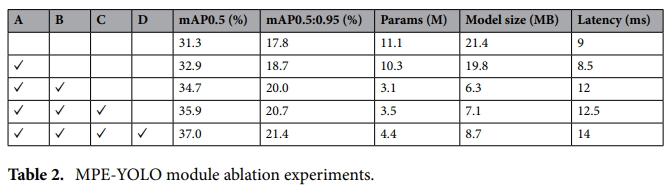
其中A代表添加MFI模塊,B代表改進網絡結構,C代表添加PEC模塊,D代表添加ES-C2f模塊。
-
僅添加MFI模塊:參數量減少0.8M,mAP0.5提升1.6%(達32.9%),模型體積縮減至19.8MB。
-
疊加網絡結構調整:移除冗余檢測頭,新增160×160小目標檢測層,mAP0.5再提升1.8%(達34.7%),但延遲從9ms增至12ms。
-
引入PEC模塊:通過特征切割與通道拼接,mAP0.5提升至35.9%,模型參數量僅增加0.4M。
-
整合ES-C2f模塊:最終mAP0.5達37.0%,參數量4.4M,體積8.7MB,較基線壓縮60%以上。
模塊的逐級疊加驗證了各組件對小目標檢測的貢獻,MFI優化特征融合,PEC增強細節感知,ES-C2f提升通道表達能力。
-
對比實驗

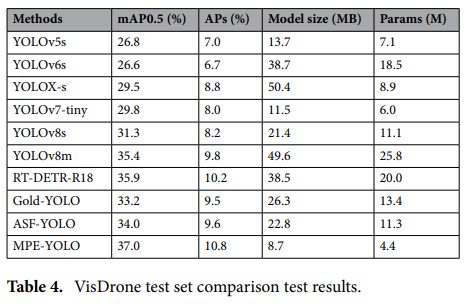
在VisDrone數據集上,觀察到最經典的YOLOv5s模型在小目標檢測中,mAP0.5準確率為26.8%,APs準確率為7.0%。YOLOv6 的表現略差,mAP0.5 為 26.6%,AP 為 6.7%,但盡管如此,兩種方法的性能差異并不大。模型大小和參數數量明顯不同,YOLOv6 的模型大小幾乎是 YOLOv5 的三倍,參數數量則增加了一倍多。
YOLOX-s 將 mAP0.5 提升至 29.5%,AP 提升至 8.8%,表明檢測效果顯著提升。然而,這種提升是以模型大小增加(50.4 MB)和參數數量增加(8.9 MB)為代價的。
YOLOv8 和 YOLOv8m。 YOLOv8s 模型的 mAP0.5 準確率和 AP 準確率分別為 31.3% 和 8.2%,表明結構優化帶來了顯著的提升。YOLOv8m 模型的 mAP0.5 準確率和 AP 準確率分別達到了 35.4% 和 9.8%。
與 YOLO 系列的傳統架構相比,RT-DETR-R18 模型的 mAP0.5 和 AP 準確率均取得了較高的分數(35.9% vs. 10.2%),并且它采用了 DETR 架構。
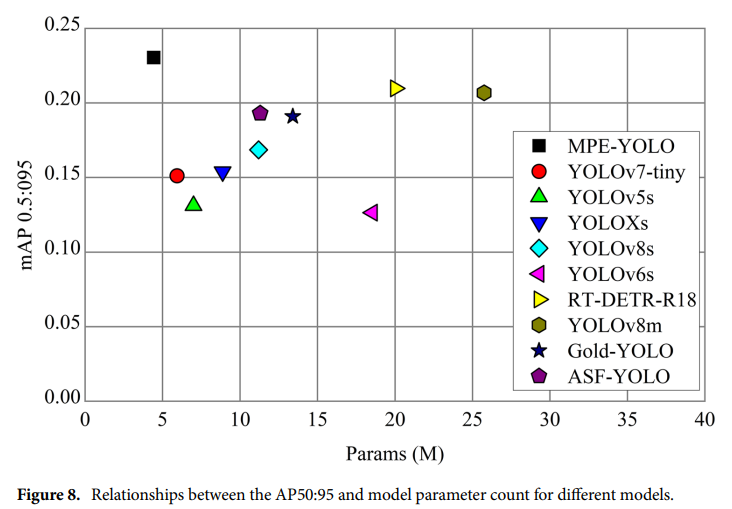
MPE-YOLO在精度與輕量化上實現雙重突破,參數量僅為YOLOv8s的40%,但mAP0.5提升5.7%。
-
可視化分析


通過精心挑選圖像樣本,將基線模型和 MPE-YOLO 模型應用于目標檢測。如圖所示,在多種場景和挑戰性條件下,MPE-YOLO 模型的檢測置信度顯著優于基線模型。這體現在其識別的目標邊界框具有更高的置信度得分,并且這些得分與實際目標更加一致。更重要的是,MPE-YOLO 在降低誤報和漏報方面也表現出顯著的提升,能夠準確識別和識別大多數目標,同時最大限度地減少非目標區域的誤識別。此外,即使在陰影或光照條件不佳的情況下,MPE-YOLO 也能實現較低的漏檢率。
改進的MPE-YOLO模型展現了其更卓越的特征提取和目標定位能力,體現在它所反映的高響應區域更加集中且強化。該特征在熱力圖上呈現為更明亮的區域,緊密貼合目標的實際位置和輪廓,表明MPE-YOLO模型能夠有效地聚焦重要信號。此外,與基線模型相比,改進模型生成的熱力圖中目標周圍散落的熱點更少,從而降低了誤檢和誤報的可能性。
-
泛化研究
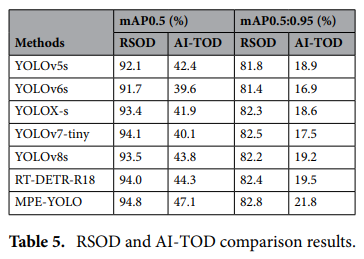
通過對表中兩個不同的遙感圖像數據集RSOD和AI-TOD進行的全面對比測試,MPE-YOLO模型展現了其卓越的泛化能力。測試結果表明,與現有的幾種先進目標檢測模型相比,MPEYOLO模型在mAP0.5和mAP0.5:0.95兩個關鍵性能指標上表現出較高的準確率,尤其是在平均目標尺寸僅為12.8像素的AI-TOD數據集上。
實驗結果表明,MPE-YOLO 具有強大的檢測能力,即使在小目標檢測場景下也能保持較高的準確率,證明了其在遙感圖像分析領域的實用性和有效性。下圖顯示,YOLOv8 對較小目標的漏檢數量顯著高于 MPE-YOLO,而 MPE-YOLO 的漏檢數量明顯較少。


總結
MPE-YOLO通過多級特征融合、擴大感受野、增強細節感知三大策略,顯著提升了航拍圖像中小目標的檢測精度,同時保持模型輕量化,適合部署在無人機等資源受限設備。MPE-YOLO的精準表現,為無人機實時監測、災害救援、智慧城市等場景提供了可靠的技術基石。
歡迎留言交流或私信獲取資源,我們也會持續更新相關項目與案例,如果你有想要了解的模型或數據集也可以留言哦,我們會竭盡全力去尋找的!


)







)

)


—— 默認成員函數與運算符重載的深度解析:構造函數,析構函數,拷貝構造函數,賦值運算符重載,普通取地址重載,const取地址重載)
)

)
