數據湖和傳統數據倉庫的主要區別
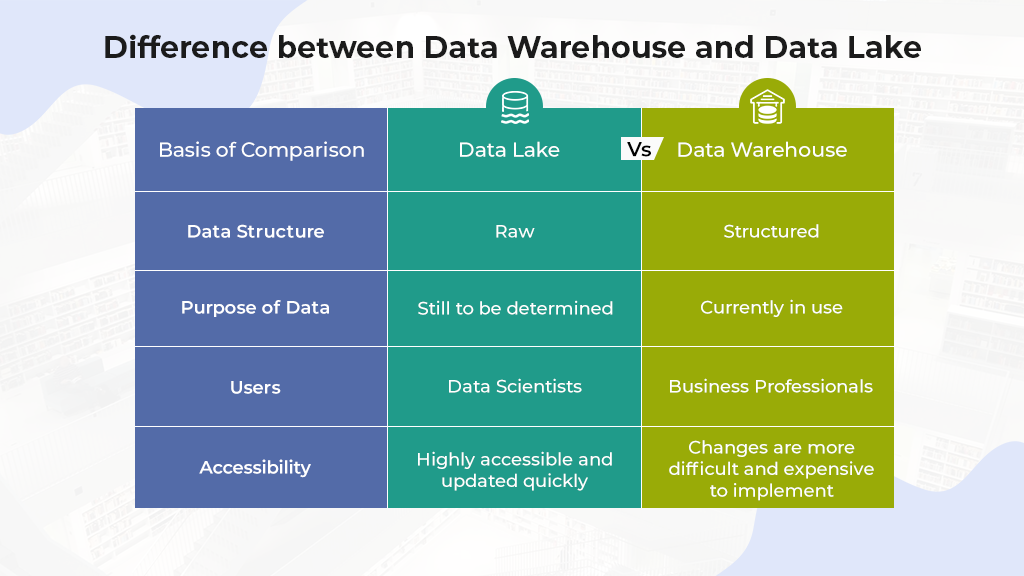
以下是數據湖和傳統數據倉庫的主要區別,以表格形式展示:
| 特性 | 數據湖 | 傳統數據倉庫 |
|---|---|---|
| 數據類型 | 支持結構化、半結構化及非結構化數據 | 主要處理結構化數據 |
| 架構設計 | 扁平化架構,所有數據存儲在一個大的“池”中 | 多層架構,包括ETL層、數據存儲層等 |
| 數據模式 | 存儲原始或接近原始格式的數據,無預定義模式(schema-on-read) | 需要在數據加載前定義好數據模型(schema-on-write) |
| 處理方式 | 支持批處理、流處理等多種數據處理模式 | 主要針對批量處理優化 |
| 應用場景 | 實時分析、機器學習、大數據分析、IoT數據分析等 | 商業智能(BI)、固定報表生成、OLAP分析等 |
| 靈活性 | 高度靈活,適合探索性分析和數據科學項目 | 更加嚴格和規范,適用于已知查詢和報告需求 |
| 成本效益 | 使用低成本存儲解決方案,支持大規模擴展 | 可能更昂貴,尤其是在需要高可用性和高性能時 |
| 用戶群體 | 數據科學家、數據工程師 | 商業分析師、業務用戶 |
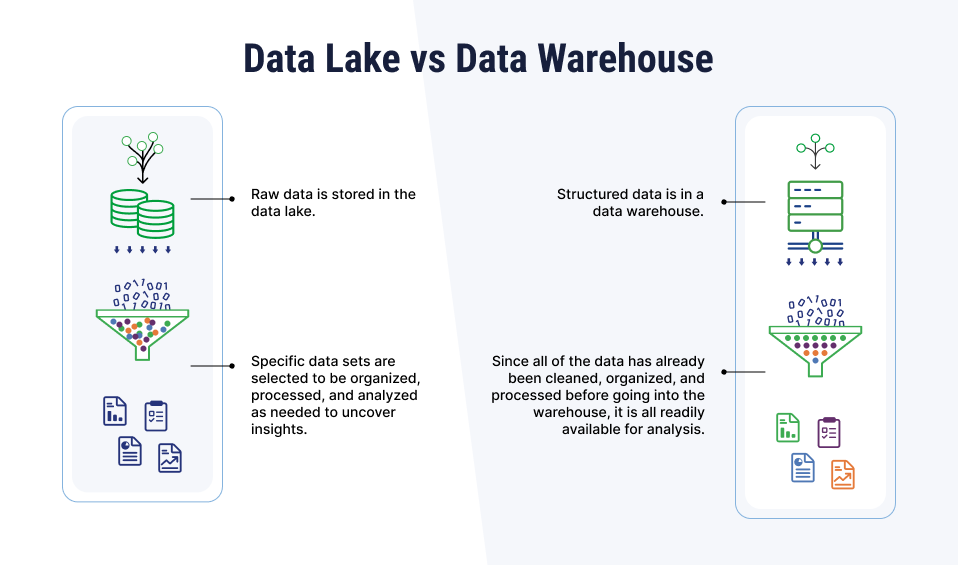
數據湖和傳統數據倉庫的優缺點
以下是數據湖和傳統數據倉庫的優缺點對比:

數據湖的優點:
- 靈活性高:支持存儲結構化、半結構化和非結構化數據,無需預先定義數據模式(schema-on-read)。
- 成本效益:使用低成本的存儲解決方案(如云存儲),特別適合需要存儲大量原始數據的情況。
- 支持多種處理方式:可以執行批處理、流處理等多種數據處理模式,適用于機器學習、實時分析等高級應用場景。
- 擴展性強:易于擴展以容納更多種類和更大規模的數據。
數據湖的缺點:
- 管理復雜:由于數據沒有預定義模式,管理和維護數據質量變得更加困難。
- 安全性和治理挑戰:確保敏感數據的安全和合規性更加復雜,特別是在數據量龐大且類型多樣的情況下。
- 性能問題:對于某些類型的查詢和分析任務,可能不如傳統的數據倉庫高效。

傳統數據倉庫的優點:
- 數據一致性高:數據在加載到倉庫之前已經過清洗、轉換,保證了數據的一致性和準確性。
- 查詢效率高:針對聯機分析處理(OLAP)進行了優化,能夠快速響應復雜的查詢請求。
- 成熟的工具和技術:擁有豐富的商業智能(BI)工具和報表生成軟件支持,便于業務用戶使用。
傳統數據倉庫的缺點:
- 靈活性差:只能處理結構化數據,并且需要預先定義好數據模型(schema-on-write),不適合探索性數據分析。
- 擴展性有限:隨著數據量的增長,擴容的成本較高,且難以支持大規模的數據集。
- 成本較高:尤其是當需要高性能和高可用性時,傳統數據倉庫的硬件和軟件成本可能會非常高。
通過以上對比可以看出,數據湖和傳統數據倉庫各有優勢和局限。選擇哪一種取決于具體的業務需求、預算以及技術環境。在實際應用中,許多企業選擇將兩者結合使用,以充分利用各自的優勢。





)




)


而不是圓形類型)





