目錄
YOLO v1 算法詳解?
?1. 核心思想?
?2. 算法優勢?
?3. 網絡結構(Unified Detection)??
?4. 關鍵創新?
?5. 結構示意圖(Fig1)?
Confidence Score 的計算?
類別概率與 Bounding Box 的關系?
后處理:非極大值抑制(NMS)??
網絡結構實現細節?
輸出張量示例(7×7×30)??
深入解析YOLO v1:實時目標檢測的開山之作??
YOLO(You Only Look Once)是目標檢測領域的里程碑式算法,由Joseph Redmon等人在2016年CVPR會議上提出。作為第一個將目標檢測任務轉化為單階段(one-stage)回歸問題的算法,YOLO v1以其驚人的速度和簡潔的網絡結構迅速成為研究熱點。本文將全面剖析YOLO v1的核心思想、實現細節及技術優勢,并對比同期算法(如Faster R-CNN)的差異。
論文名稱:You only look once unified real-time object detection
論文鏈接
YOLO v1 算法詳解?
?1. 核心思想?
YOLO(You Only Look Once)將物體檢測(object detection)任務視為一個端到端的回歸問題,通過單個卷積神經網絡(CNN)直接從輸入圖像預測目標邊界框(bounding box)和類別概率。
?2. 算法優勢?
YOLO v1 的主要優勢包括:
- ?速度快?:在 Titan X GPU 上達到 ?45 FPS,快速版(Fast YOLO)可達 ?150 FPS,適合實時檢測。
- ?全局推理?:基于整張圖像進行預測(而非滑動窗口或候選區域),減少背景誤檢(false positives),比 Fast R-CNN 的誤檢率低一半以上。
- ?泛化能力強?:學習到的特征更具通用性,在遷移到新領域時表現較好。
- ?高準確率?:在 VOC 2007 數據集上 mAP 達 63.4%,兼顧速度和精度。
?3. 網絡結構(Unified Detection)??
YOLO v1 采用 ?24 層卷積網絡 + 2 層全連接層,結構特點如下:
- ?輸入?:448×448 圖像(通過下采樣適應網絡)。
- ?輸出?:
S×S×(B×5 + C)?的張量,其中:S×S?表示網格劃分(默認?7×7)。B?是每個網格預測的邊界框數量(默認?2)。5?包含邊界框的坐標(x, y, w, h)和置信度(confidence)。C?是類別概率(如 VOC 數據集的 20 類)。
?4. 關鍵創新?
- ?網格化預測?:圖像被劃分為?
S×S?網格,每個網格負責預測中心落在該區域的目標。 - ?多任務損失函數?:聯合優化邊界框坐標、置信度和分類概率,損失函數設計如下:
- 坐標誤差(加權)
- 置信度誤差(區分有無目標)
- 分類誤差(交叉熵)
?5. 結構示意圖(Fig1)?
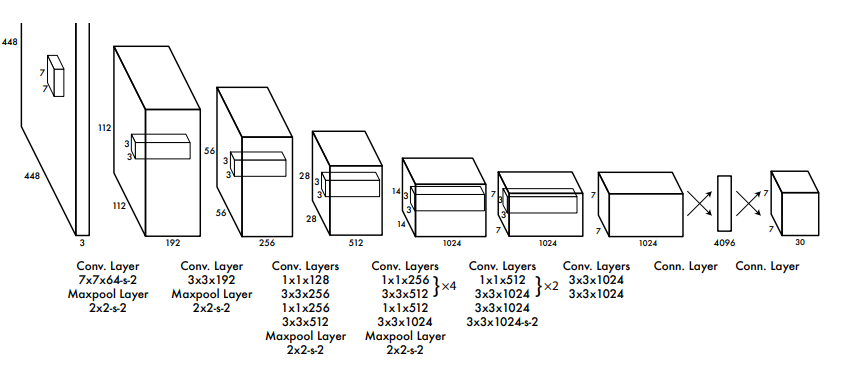
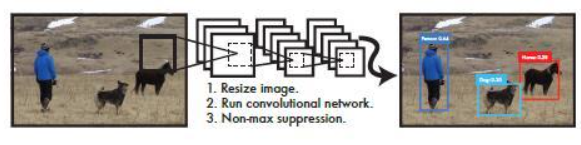
?
Confidence Score 的計算?
每個 bounding box 對應一個 ?confidence score,用于衡量該框內是否包含物體以及預測框的準確性:
- ?公式?:
![]()
-
- 如果 grid cell 中沒有物體?(背景),則 confidence = 0。
- 如果 grid cell 中有物體,confidence = 預測框與真實框的 ?IOU(交并比)?。
?如何判斷 grid cell 是否包含物體???
- 規則:若某物體的 ground truth 邊界框的中心點坐標落在某個 grid cell 內,則該 grid cell 負責預測該物體。
類別概率與 Bounding Box 的關系?
-
?類別概率(Class Probability)??:
- 每個 grid cell 預測 ?C 個類別概率?(如 VOC 數據集的 20 類),表示該 grid cell 包含物體時屬于各類別的概率。
- ?注意?:類別概率是針對 grid cell? 的,而非單個 bounding box。
-
?Bounding Box 的最終分類得分?:
- 將每個 bounding box 的 confidence 與 grid cell 的類別概率相乘,得到該 box 屬于某類別的置信度得分:
![]()
-
- ?輸出矩陣?:
- 形狀為?
20×(7×7×2) = 20×98(20 類,98 個 bounding box)。
- 形狀為?
- ?輸出矩陣?:
后處理:非極大值抑制(NMS)??
- ?閾值過濾?:
- 對每一類別(矩陣的每一行),將得分 < 0.2 的 bounding box 置 0。
- ?排序與去重?:
- 按得分從高到低排序,選擇最高得分的 box,計算其與其余 box 的 IOU:
- 若 IOU > 0.5(重疊過高),則抑制(得分置 0)。
- 否則保留。
- 重復上述過程,直到所有 box 被處理。
- 按得分從高到低排序,選擇最高得分的 box,計算其與其余 box 的 IOU:
- ?最終分類?:
- 對每個 bounding box,取 20 個類別得分中的最大值:
- 若最大值 > 0,則判定為對應類別;
- 若最大值 = 0,判定為背景(忽略)。
- 對每個 bounding box,取 20 個類別得分中的最大值:
網絡結構實現細節?
- ?Backbone?:基于 ?GoogLeNet? 改進的卷積網絡(24 層卷積 + 4 層 Inception 模塊)。
- ?輸出層?:
- 全連接層輸出?
7×7×30?的張量,其中:7×7:grid cell 數量。30:包含 2 個 bounding box 的坐標(x,y,w,h)和 confidence,以及 20 個類別概率。
- 全連接層輸出?
- ?關鍵改動?:
- 替換 GoogLeNet 的復雜 Inception 模塊為簡單的?
1×1?和?3×3?卷積組合,提升速度。 - 最后一層全連接層直接回歸邊界框和類別(端到端訓練)。
- 替換 GoogLeNet 的復雜 Inception 模塊為簡單的?
輸出張量示例(7×7×30)??
| 分量 | 維度 | 說明 |
|---|---|---|
| Bounding Box 1 | 5 (x,y,w,h,conf) | 第一個預測框的坐標和置信度 |
| Bounding Box 2 | 5 (x,y,w,h,conf) | 第二個預測框的坐標和置信度 |
| Class Probabilities | 20 | 20 個類別的條件概率(P(class|obj)) |
?

安裝fedora42的方法)







如何調試HardFault)









