文章目錄
- 1 案例介紹
- 1.1 應用場景:美國房價預測
- 1.2 核心假設
- 1.3 線性回歸與神經網絡的關系
- 1.4 平方損失(L2 Loss)
- 1.5 訓練模型:最小化損失
- 2 基礎優化算法
- 2.1 梯度下降
- 2.2 小批量隨機梯度下降(Mini-batch SGD)
- 3 實戰:線性回歸的從零實現
- 3.1 生成數據集
- 3.2 讀取數據集
- 3.3 初始化模型參數
- 3.4 定義模型
- 3.5 定義損失函數
- 3.6 優化算法
- 3.7 訓練
- 4 實戰:線性回歸的簡易實現
- 4.1 實現
- 4.2 練習
硬件配置:
- Windows 11
- Intel?Core?i7-12700H
- NVIDIA GeForce RTX 3070 Ti Laptop GPU
軟件環境:
- Pycharm 2025.1
- Python 3.12.9
- Pytorch 2.6.0+cu124

1 案例介紹
1.1 應用場景:美國房價預測
? 在美國買房時,買家需根據房屋信息(如臥室數量、衛生間數量、面積等)預測合理的成交價。
- 輸入數據:房屋特征(如
X1=臥室數,X2=衛生間數,X3=面積)。 - 輸出目標:預測成交價
Y。 - 實際挑戰:賣家的標價和網站估價(如Redfin)僅為參考,最終需通過競價決定成交價,因此準確預測至關重要。
1.2 核心假設
-
房價由關鍵特征的加權和決定:
Y = W 1 X 1 + W 2 X 2 + W 3 X 3 + b Y=W_1X_1+W_2X_2+W_3X_3+b Y=W1?X1?+W2?X2?+W3?X3?+bW1, W2, W3:權重(反映各特征對價格的影響)。b:偏差項(基礎價格,如地段附加值)。

-
一般化形式(N 維輸入):
Y = W 1 X 1 + W 2 X 2 + ? + W N X N + b Y=W_1X_1+W_2X_2+\cdots+W_NX_N+b Y=W1?X1?+W2?X2?+?+WN?XN?+b- 向量表示:
Y = W^T X + b(W為權重向量,X為特征向量)。
- 向量表示:

1.3 線性回歸與神經網絡的關系
? 單層神經網絡:線性回歸可視為最簡單的神經網絡。

- 結構:輸入層(特征)→ 輸出層(預測值),無隱藏層。
- 權重
W對應神經元的連接強度,b對應激活閾值。 - 類比生物神經元:輸入信號加權求和后,若超過閾值則輸出信號。

1.4 平方損失(L2 Loss)
L = 1 2 ( Y ? Y ^ ) 2 L=\frac{1}{2}(Y-\hat{Y})^2 L=21?(Y?Y^)2
-
Y:真實成交價,?:模型預測價。 -
作用:量化預測誤差,誤差越小模型越準。
-
為什么用1/2?
求導時簡化計算(導數變為
Y - ?)

1.5 訓練模型:最小化損失
- 訓練數據:收集歷史成交記錄(如過去 6 個月的房屋數據)。
- 數據矩陣
X(每行一個樣本,每列一個特征),向量Y(真實價格)。
- 數據矩陣

- 損失函數(全體數據):
- 目標:找到
W和b使L(W, b)最小。
- 目標:找到
L ( W , b ) = 1 2 N ∑ i = 1 N ( Y i ? Y ^ i ) 2 L(W,b)=\frac1{2N}\sum_{i=1}^N(Y_i-\hat{Y}_i)^2 L(W,b)=2N1?i=1∑N?(Yi??Y^i?)2

-
求解方法:
-
閉式解(顯示解):僅線性回歸等簡單模型存在。
W ? = ( X T X ) ? 1 X T Y W^*=(X^TX)^{-1}X^TY W?=(XTX)?1XTY- 通過矩陣運算直接計算最優權重。
-
凸函數性質:損失函數是“碗形”,僅有一個全局最小值。
-

2 基礎優化算法
? 線性回歸有顯示解(閉式解),但大多數機器學習模型(如神經網絡)無法直接求解,需通過迭代優化逼近最優解。
? 核心目標是找到模型參數(如權重 W 和偏差 b),使損失函數(如平方誤差)最小化。
2.1 梯度下降
基本思想
-
初始化:隨機選擇參數初始值
W?。 -
迭代更新:沿損失函數下降最快的方向(負梯度)逐步調整參數:
W t = W t ? 1 ? η ? ? L ( W t ? 1 ) W_t=W_{t-1}-\eta\cdot\nabla L(W_{t-1}) Wt?=Wt?1??η??L(Wt?1?)η:學習率(步長),控制更新幅度。?L:損失函數對參數的梯度(偏導數向量)。

直觀理解
- 梯度方向:函數值上升最快的方向,負梯度即下降最快方向。
- 學習率的作用:
- 太小:收斂慢,需大量計算(如蝸牛爬坡)。
- 太大:可能跳過最優解,甚至發散(如邁步過大跌入山谷)。
示例
- 假設損失函數是“碗形”(凸函數),初始點
W?在碗邊緣。 - 每次迭代沿最陡方向(負梯度)移動,逐步接近碗底(最小值)。

2.2 小批量隨機梯度下降(Mini-batch SGD)
動機
- 傳統梯度下降:每次計算需遍歷全部樣本(計算代價高)。
- 隨機梯度下降(SGD):每次隨機選一個樣本計算梯度(噪聲大,不穩定)。
- 折中方案:小批量(
batch_size = B)隨機采樣,平衡效率和穩定性。

批量大小(batch_size)的選擇
- 太小(如
B=1):- 無法利用 GPU 并行計算,訓練波動大。
- 太大(如
B=全數據集):- 內存不足,且可能包含冗余樣本(如相似數據)。
- 經驗值:常用
32、64、128(需根據硬件和數據調整)。
3 實戰:線性回歸的從零實現
? 首先導入相關包。
%matplotlib inline
import random
import torch
from d2l import torch as d2l
? d2l 包下載鏈接:https://github.com/d2l-ai/d2l-zh?tab=readme-ov-file。
? 只要將 d2l 文件夾放在項目中即可。d2l 導入了 numpy,pandas,matplotlib 這些常用包,自己手動安裝即可。

3.1 生成數據集
? 為了簡單起見,我們將根據帶有噪聲的線性模型構造一個人造數據集,任務是使用這個有限樣本的數據集來恢復這個模型的參數。
? 生成一個包含1000個樣本的數據集,每個樣本包含從標準正態分布中采樣的 2 個特征。我們的合成數據集是一個矩陣 X ∈ R 1000 × 2 \mathbf{X}\in \mathbb{R}^{1000 \times 2} X∈R1000×2。使用線性模型參數 w = [ 2 , ? 3.4 ] ? \mathbf{w} = [2, -3.4]^\top w=[2,?3.4]?、 b = 4.2 b = 4.2 b=4.2 和噪聲項 ? \epsilon ? 生成數據集及其標簽( ? \epsilon ? 可以視為模型預測和標簽時的潛在觀測誤差):
y = X w + b + ? \mathbf{y}= \mathbf{X} \mathbf{w} + b + \mathbf\epsilon y=Xw+b+?
? 在這里我們認為標準假設成立,即 ? \epsilon ? 服從均值為 0 的正態分布。為了簡化問題,我們將標準差設為 0.01。
def synthetic_data(w, b, num_examples): #@save# type: (Tensor, float, int) -> tuple[Tensor, Tensor]"""通過噪聲生成y=Xw+b的數據集"""X = torch.normal(0, 1, size=(num_examples, len(w)))y = torch.matmul(X, w) + by += torch.normal(0, 0.01, y.shape)return X, y.reshape((-1, 1))true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
features.shape, labels.shape

? 通過生成第二個特征 features[:, 1] 和 labels 的散點圖, 可以直觀觀察到兩者之間的線性關系。
d2l.set_figsize()
d2l.plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), 1)
d2l.plt.show()

運行
d2l.plt.show()時報錯:OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized. OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://www.intel.com/software/products/support/.
? 這個錯誤是由于 OpenMP 運行時庫沖突 導致的,
libiomp5md.dll被多次加載。PyTorch 和某些科學計算庫(如 NumPy、Scipy)可能各自鏈接了不同版本的 OpenMP 運行時庫。當多個副本被加載時,會導致沖突,出現OMP: Error #15。常見于 Windows 系統上運行 PyTorch 或 NumPy。解決方法
方法 1(推薦):設置環境變量
KMP_DUPLICATE_LIB_OK=TRUE在代碼 最開頭 添加:
import os os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" # 允許重復加載 OpenMP 庫(臨時解決方案)方法 2:更新或重新安裝 PyTorch 和 NumPy
沖突可能是由于版本不匹配導致的,嘗試:
pip install --upgrade torch numpy
3.2 讀取數據集
? 定義一個data_iter函數, 該函數接收批量大小、特征矩陣和標簽向量作為輸入,生成大小為batch_size的小批量。 每個小批量包含一組特征和標簽。
def data_iter(batch_size, features, labels):# type: (int, Tensor, Tensor) -> Iterable[tuple[Tensor, Tensor]]num_examples = len(features)indices = list(range(num_examples))# 隨機打亂樣本順序以實現無偏采樣random.shuffle(indices)# 按批次大小遍歷整個數據集for i in range(0, num_examples, batch_size):# 獲取當前批次的索引范圍,處理最后一個批次可能不足的情況batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])# 生成當前批次的特征和標簽張量yield features[batch_indices], labels[batch_indices]
3.3 初始化模型參數
? 在我們開始用小批量隨機梯度下降優化我們的模型參數之前, 我們需要先有一些參數。
? 在下面的代碼中,我們通過從均值為 0、標準差為 0.01 的正態分布中采樣隨機數來初始化權重, 并將偏置初始化為 0。
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
w, b

3.4 定義模型
? 計算輸入特征 X \mathbf{X} X 和模型權重 w \mathbf{w} w 的矩陣-向量乘法后加上偏置 b b b。
? 注意,上面的 X w \mathbf{Xw} Xw 是一個向量,而 b b b 是一個標量。回想一下廣播機制:當我們用一個向量加一個標量時,標量會被加到向量的每個分量上。
def linreg(X, w, b): #@save# type: (Tensor, Tensor, Tensor) -> Tensor"""線性回歸模型"""return torch.matmul(X, w) + b
3.5 定義損失函數
? 使用平方損失函數。在實現中,我們需要將真實值y的形狀轉換為和預測值y_hat的形狀相同。
def squared_loss(y_hat, y): #@save# type: (Tensor, Tensor) -> Tensor"""均方損失"""return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
3.6 優化算法
? 在每一步中,使用從數據集中隨機抽取的一個小批量,然后根據參數計算損失的梯度。接下來,朝著減少損失的方向更新我們的參數。
? 下面的函數實現小批量隨機梯度下降更新。該函數接受模型參數集合、學習速率和批量大小作為輸入。每 一步更新的大小由學習速率lr決定。因為我們計算的損失是一個批量樣本的總和,所以我們用批量大小(batch_size) 來規范化步長,這樣步長大小就不會取決于我們對批量大小的選擇。
def sgd(params, lr, batch_size): #@save# type: (Iterable[Tensor], float, int) -> None"""小批量隨機梯度下降"""with torch.no_grad():for param in params:param -= lr * param.grad / batch_sizeparam.grad.zero_()
3.7 訓練
? 在每次迭代中,我們讀取一小批量訓練樣本,并通過我們的模型來獲得一組預測。計算完損失后,我們開始反向傳播,存儲每個參數的梯度。最后,我們調用優化算法sgd來更新模型參數。
? 概括一下,我們將執行以下循環:
- 初始化參數
- 重復以下訓練,直到完成
- 計算梯度 g ← ? ( w , b ) 1 ∣ B ∣ ∑ i ∈ B l ( x ( i ) , y ( i ) , w , b ) \mathbf{g} \leftarrow \partial_{(\mathbf{w},b)} \frac{1}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} l(\mathbf{x}^{(i)}, y^{(i)}, \mathbf{w}, b) g←?(w,b)?∣B∣1?∑i∈B?l(x(i),y(i),w,b)。
- 更新參數 ( w , b ) ← ( w , b ) ? η g (\mathbf{w}, b) \leftarrow (\mathbf{w}, b) - \eta \mathbf{g} (w,b)←(w,b)?ηg。
? 在每個迭代周期(epoch)中,使用data_iter函數遍歷整個數據集,并將訓練數據集中所有樣本都使用一次(假設樣本數能夠被批量大小整除)。
? 這里的迭代周期個數num_epochs和學習率lr都是超參數,分別設為 3 和 0.03。設置超參數很棘手,需要通過反復試驗進行調整。
lr = 0.03 # 學習率
num_epochs = 3 # 迭代次數
batch_size = 10 # 批量大小
net = linreg
loss = squared_lossfor epoch in range(num_epochs):for X, y in data_iter(batch_size, features, labels):l = loss(net(X, w, b), y) # X和y的小批量損失# 因為l形狀是(batch_size,1),而不是一個標量。l中的所有元素被加到一起,# 并以此計算關于[w, b]的梯度l.sum().backward()sgd([w, b], lr, batch_size) # 使用參數的梯度更新參數# print('w:', w, 'b:', b)with torch.no_grad():train_l = loss(net(features, w, b), labels)print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')

? 上述訓練將 1000 個數據分為 100 批次,每個批次大小為 10。我們認為每個批次的 w 和 b 與總體一致。
? 因此,每一次迭代中,訓練 100 批次,一共迭代 3 次,即訓練了 300 批次。
? 通過比較真實參數和通過訓練學到的參數來評估訓練的成功程度。事實上,真實參數和通過訓練學到的參數確實非常接近。
print(f'w的估計誤差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估計誤差: {true_b - b}')

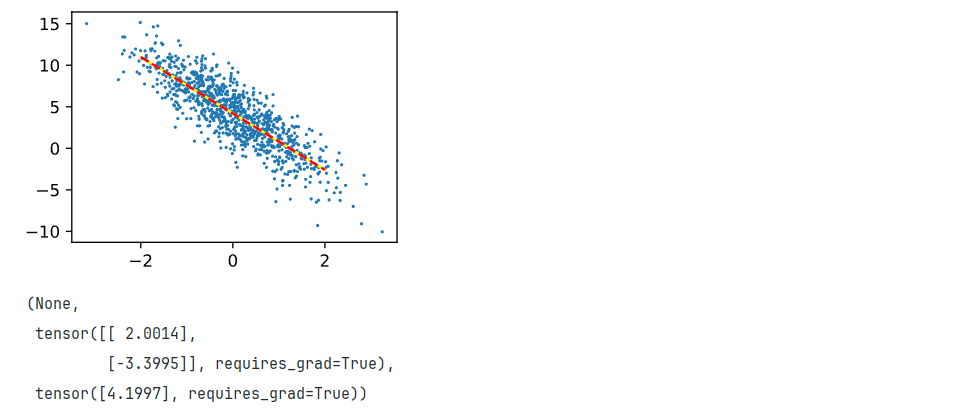
? 繪制圖像比較真實數據(黃色直線)與擬合結果(紅色虛線)。
d2l.set_figsize()
d2l.plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), 1) # 繪制數據點
d2l.plt.plot(d2l.np.arange(-2, 3), d2l.np.arange(-2, 3) * true_w[1].detach().numpy() + true_b, color='yellow') # 繪制真實直線
d2l.plt.plot(d2l.np.arange(-2, 3), d2l.np.arange(-2, 3) * w[1, :].detach().numpy() + b.detach().numpy(), color='red', linestyle='--') # 繪制擬合直線
d2l.plt.show(), w, b
4 實戰:線性回歸的簡易實現
4.1 實現
? 與上章類似,我們首先生成數據集。
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2ltrue_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
? 我們可以調用框架中現有的 API 來讀取數據。 我們將features和labels作為 API 的參數傳遞,并通過數據迭代器指定batch_size。 此外,布爾值is_train表示是否希望數據迭代器對象在每個迭代周期內打亂數據。
def load_array(data_arrays, batch_size, is_train=True): #@save# type: (tuple[Tensor, Tensor], int, bool) -> data.DataLoader"""構造一個PyTorch數據迭代器"""dataset = data.TensorDataset(*data_arrays)return data.DataLoader(dataset, batch_size, shuffle=is_train) # 隨機選取 batch_size 大小的數據batch_size = 10
data_iter = load_array((features, labels), batch_size)
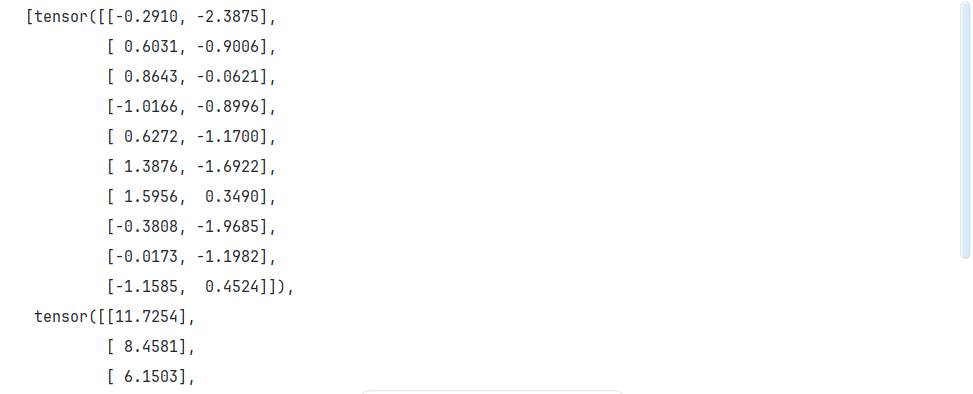
? 使用data_iter的方式與上章中使用data_iter函數的方式相同。為了驗證是否正常工作,讓我們讀取并打印第一個小批量樣本。 這里我們使用iter構造 Python 迭代器,并使用next從迭代器中獲取第一項。
next(iter(data_iter))
? 對于標準深度學習模型,我們可以使用框架的預定義好的層。
? 首先定義一個模型變量net,它是一個Sequential類的實例。Sequential類將多個層串聯在一起。當給定輸入數據時,Sequential實例將數據傳入到第一層,然后將第一層的輸出作為第二層的輸入,以此類推。在下面的例子中,我們的模型只包含一個層,因此實際上不需要Sequential。 但是由于以后幾乎所有的模型都是多層的,在這里使用Sequential會讓你熟悉“標準的流水線”。
? 這一單層被稱為全連接層(fully-connected layer), 因為它的每一個輸入都通過矩陣-向量乘法得到它的每個輸出。
# nn是神經網絡的縮寫
from torch import nnnet = nn.Sequential(nn.Linear(2, 1))
? 在使用net之前,我們需要初始化模型參數。通過net[0]選擇網絡中的第一個圖層, 然后使用weight.data和bias.data方法訪問參數。 我們還可以使用替換方法normal_和fill_來重寫參數值。
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)

? 計算均方誤差使用的是MSELoss類,也稱為平方 L2 范數。 默認情況下,它返回所有樣本損失的平均值。
? 小批量隨機梯度下降算法是一種優化神經網絡的標準工具, PyTorch在optim模塊中實現了該算法的許多變種。 當我們實例化一個SGD實例時,我們要指定優化的參數 (可通過net.parameters()從我們的模型中獲得)以及優化算法所需的超參數字典。 小批量隨機梯度下降只需要設置lr值,這里設置為 0.03。
loss = nn.MSELoss()
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
? 在每個迭代周期里,我們將完整遍歷一次數據集(train_data), 不停地從中獲取一個小批量的輸入和相應的標簽。 對于每一個小批量,我們會進行以下步驟:
- 通過調用
net(X)生成預測并計算損失l(前向傳播)。 - 通過進行反向傳播來計算梯度。
- 通過調用優化器來更新模型參數。
? 為了更好的衡量訓練效果,我們計算每個迭代周期后的損失,并打印它來監控訓練過程。
num_epochs = 3
for epoch in range(num_epochs):for X, y in data_iter:l = loss(net(X), y)trainer.zero_grad()l.backward()# print(net[0].weight.grad)trainer.step()l = loss(net(features), labels)print(f'epoch {epoch + 1}, loss {l:f}')

? 下面我們比較生成數據集的真實參數和通過有限數據訓練獲得的模型參數。 要訪問參數,我們首先從net訪問所需的層,然后讀取該層的權重和偏置。 正如在從零開始實現中一樣,我們估計得到的參數與生成數據的真實參數非常接近。
w = net[0].weight.data
print('w的估計誤差:', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print('b的估計誤差:', true_b - b)

4.2 練習
-
如果我們用
nn.MSELoss(reduction=‘sum’)替換nn.MSELoss(),為了使代碼的行為相同,需要怎么更改學習速率?為什么?答:這樣替換的結果是會使得梯度值放大為原來的 num_example 倍,原有的學習率顯得過大,使得其出現了振蕩,即步長過長導致。應該把學習率除以
batch_size,因為默認參數是'mean',換成'sum'需要除以批量數。一般會采用默認,因為這樣學習率可以跟batch_size解耦。 -
如何訪問線性回歸的梯度?
答:使用
net[0].weight.grad。num_epochs = 3 for epoch in range(num_epochs):for X, y in data_iter:l = loss(net(X), y)trainer.zero_grad()l.backward()print(net[0].weight.grad)trainer.step()l = loss(net(features), labels)print(f'epoch {epoch + 1}, loss {l:f}')










)

![[密碼學基礎]密碼學常用名詞深度解析:從基礎概念到實戰應用](http://pic.xiahunao.cn/[密碼學基礎]密碼學常用名詞深度解析:從基礎概念到實戰應用)

)

)


