文章目錄
- 1.概率論基礎
- 1.1 單事件概率
- 1.2 多事件概率
- 1.3 條件概率
- 1.3.1 多事件概率與條件概率的區別
- 1.4 貝葉斯定理
- 傳統思維誤區
- 貝葉斯定理計算
- 2. 樸素貝葉斯法
- 2.1 基本概念
- 2.2 模型
- 2.3 學習策略
- 2.4 優化算法
- 2.5 優化技巧
- 拉普拉斯平滑
- 對數似然
- 3. 情感分析實戰
- 3.1 流程
- 3.2 模型評價
- 3.3 應用場景
- 3.4 局限性
- 3.4 局限性
1.概率論基礎
1.1 單事件概率
定義:一個事件發生的可能性。
例子:假設事件A表示“一個文本是正向的”,則P(A) = 正向文本數 / 總文本數。
解釋:比如有20個文本,其中13個是正向的,那么P(A) = 13/20 = 0.65。

1.2 多事件概率
定義:多個事件同時發生的概率。
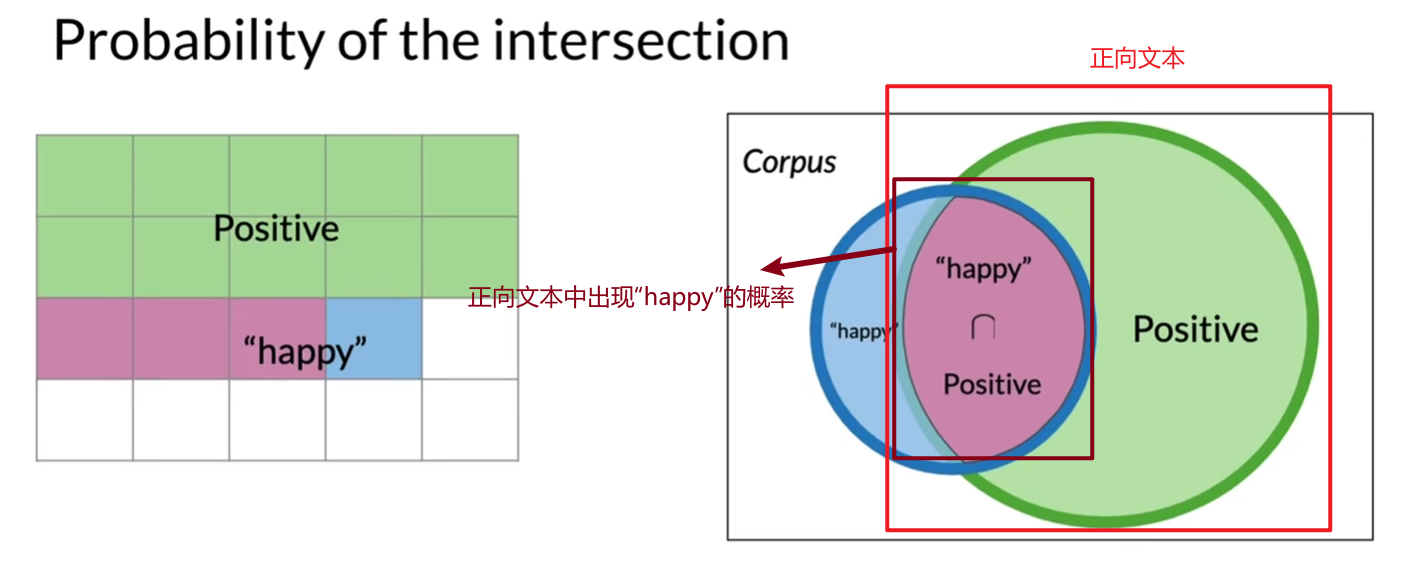
例子:事件A(文本是正向的)和事件B(文本包含單詞“happy”)同時發生的概率P(A,B) = P(A∩B) = 3/20。
舉個例子:假設某餐廳統計發現:
- 30%的訂單點了漢堡(事件A)
- 20%的訂單同時點了漢堡和薯條(事件A∩B)
那么:
- 多事件概率:P(漢堡且薯條) = 20%
(直接表示同時點這兩樣的概率)
1.3 條件概率
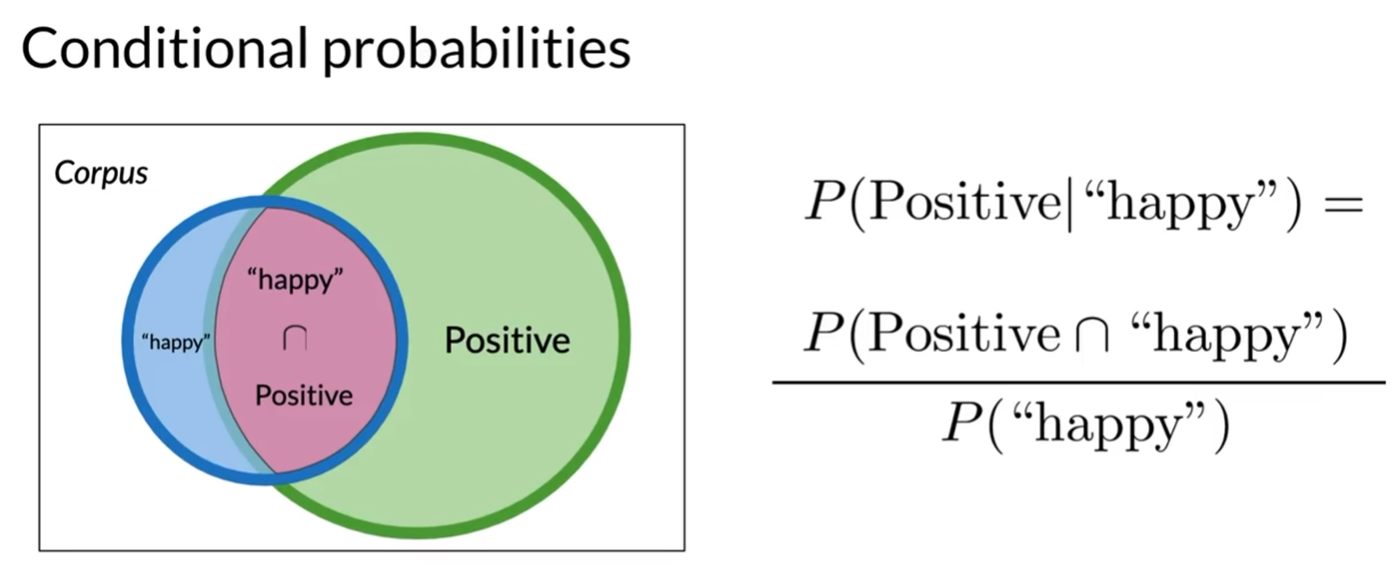
定義:在已知事件B發生的情況下,事件A發生的概率,記作P(A|B)。
公式:P(A|B) = P(A∩B) / P(B)。
作用:縮小計算范圍。例如,已知文本包含“happy”,計算它是正向的概率時,只需關注包含“happy”的文本。
延續剛剛的例子:已知某餐廳統計發現:
- 薯條訂單占全店40%(事件B)
- 漢堡和薯條同時點占20%(事件A∩B)
則:
- 條件概率:P(漢堡|已點薯條) = 20%/40% = 50% 【兩者同時的概率 / 單單薯條的概率】
(在已經點薯條的訂單中,有50%會加購漢堡)
1.3.1 多事件概率與條件概率的區別
| 維度 | 多事件概率 | 條件概率 |
|---|---|---|
| 計算范圍 | 全局樣本空間 | 限定在條件事件發生的子空間 |
| 信息量 | 反映單純共存概率 | 揭示事件間的關聯強度 |
| 應用場景 | 分析事件組合頻率 | 研究因果關系/預測 |
典型誤區分辨
- ?錯誤理解:“今天下雨且堵車”(多事件概率) vs “下雨導致堵車”(條件概率)
- ?正確區分:
- 多事件概率:全市范圍內同時下雨和堵車的概率(比如10%)
- 條件概率:在下雨的日子里發生堵車的概率(可能高達70%)
NLP應用實例(情感分析)
假設分析1,000條商品評論:
- 200條出現"價格"(事件A)
- 50條同時出現"價格"和"昂貴"(事件A∩B)
- "昂貴"出現總次數100次(事件B)
多事件概率:
P(“價格"且"昂貴”) = 50/1000 = 5%
(所有評論中同時包含這兩個詞的概率)
條件概率:
P(“昂貴”|出現"價格") = 50/200 = 25%
(在提到價格的評論中,"昂貴"出現的概率)【兩者同時的概率 / 單單價格的概率】
1.4 貝葉斯定理
定義:通過已知事件Y反推事件X的概率。貝葉斯定理是"用結果反推原因"的概率計算方法。就像偵探破案:已知犯罪現場有某種證據(結果),計算某個嫌疑人作案(原因)的概率。
公式:P(X|Y) = P(Y|X) * P(X) / P(Y)。
用途:在分類問題中,通過觀測數據反推類別概率。
舉個例子(疾病檢測)
假設:
- 某疾病在人群中的患病率是1%(先驗概率)
- 檢測準確率:
- 真有病的人,99%能測出陽性(真陽性率)
- 沒病的人,2%會誤測為陽性(假陽性率)
問題:如果一個人檢測呈陽性,他實際患病的概率是多少?
傳統思維誤區
很多人會直接認為概率是99%,忽略了基礎患病率。
貝葉斯定理計算
P(患病|陽性) = P(陽性|患病) * P(患病) / P(陽性) P(陽性) = [P(陽性|患病) * P(患病) + P(陽性|正常) * P(正常)
= (99% * 1%) / (99% * 1% + 2% * 99%) 這里的P(正常)更多的是:1-P(患病) = 99%
≈ 33%
【“患病”是因,“陽性”是果 ,先乘因,再除果】
即使檢測呈陽性,實際患病概率只有33%!
接下來我將對公式進行拆解:
P(原因|結果) = [P(結果|原因) × P(原因)] / P(結果)
- P(原因):先驗概率(已知的客觀事實)
- P(結果|原因):似然度(原因導致結果的可能性)
- P(原因|結果):后驗概率(我們想求的答案)
NLP應用實例(垃圾郵件過濾)
已知:
- 郵件中出現**“折扣”**這個詞:
- 在垃圾郵件中出現的概率是80%(P(折扣|垃圾))
- 在正常郵件中出現的概率是10%(P(折扣|正常))
- 整體郵件中垃圾郵件占比20%(P(垃圾))
計算:
P(垃圾|折扣) = [P(折扣|垃圾) * P(垃圾)] / [P(折扣|垃圾) * P(垃圾) + P(折扣|正常) * P(正常)]
= (80% * 20%) / (80% * 20% + 10% * 80%) 這里的P(正常)更多的是:1-P(垃圾) = 80%
= 66.7%
雖然"折扣"在垃圾郵件中出現概率高,但綜合考量后,含這個詞的郵件是垃圾郵件的概率是66.7%。
那么為什么叫"定理"?
因為可以通過條件概率公式嚴格推導:
- 根據條件概率定義:P(A|B)=P(A∩B)/P(B)
- 同理:P(B|A)=P(A∩B)/P(A)
- 聯立兩式消去P(A∩B)即得貝葉斯定理
2. 樸素貝葉斯法
2.1 基本概念
概述:基于貝葉斯定理的分類方法,假設特征之間相互獨立(稱為“樸素”)。
優點:簡單高效,適合文本分類等任務。
缺點:特征獨立性假設可能影響準確性。
條件獨立假設:
- 假設所有特征在類別確定時彼此獨立。
- 雖然簡化計算,但現實中特征可能相關。
2.2 模型
目標:對輸入數據x,預測最可能的類別y。
核心公式:
y = argmax P(y) * Π P(x_i|y),即選擇使后驗概率最大的類別。
2.3 學習策略
極大似然估計(MLE):
- 估計先驗概率P(y)和條件概率P(x_i|y)。
- 先驗概率:P(y) = 類別y的樣本數 / 總樣本數。
- 條件概率:P(x_i|y) = 類別y中特征x_i出現的次數 / 類別y的總樣本數。
2.4 優化算法
后驗概率最大化:
- 選擇使后驗概率最大的類別,等價于最小化分類錯誤。
2.5 優化技巧
拉普拉斯平滑
問題:某些特征未出現時概率為0,導致整體概率為0。
解決:分子加1,分母加特征總數V,避免零概率。
對數似然
問題:連乘小數可能導致數值下溢(結果過小無法表示)。
解決:對概率取對數,將連乘轉為連加。
- 概率比值:ratio(w_i) = P(w_i|正向) / P(w_i|負向)。
- 對數似然:λ(w_i) = log(ratio(w_i))。
- 最終決策:若對數先驗 + Σλ(w_i) > 0,則為正向;否則為負向。
3. 情感分析實戰
3.1 流程
- 數據預處理:清洗文本(如去標點、分詞)。
- 構建詞頻表:統計單詞在正向/負向文本中的出現次數。
- 計算概率:
- 條件概率:P(w_i|正向)和P(w_i|負向)。
- 對數似然:λ(w_i) = log(P(w_i|正向)/P(w_i|負向))。
- 預測:根據對數先驗 + Σλ(w_i)的符號判斷情感傾向。
3.2 模型評價
準確度:正確預測的文本數 / 總文本數。
3.3 應用場景
- 垃圾郵件分類
- 新聞分類
- 情感分析
3.4 局限性
- 條件獨立假設:忽略單詞間的關聯(如“not happy”)。
- 數據不平衡:正向/負向樣本數量差異大時影響效果。
- 文本復雜性:
- 標點可能攜帶情感(如“好!” vs “好?”)。
- 停用詞(如“的”)有時也有情感意義。
- 反諷或夸張難以捕捉。
- 新聞分類
- 情感分析
3.4 局限性
- 條件獨立假設:忽略單詞間的關聯(如“not happy”)。
- 數據不平衡:正向/負向樣本數量差異大時影響效果。
- 文本復雜性:
- 標點可能攜帶情感(如“好!” vs “好?”)。
- 停用詞(如“的”)有時也有情感意義。
- 反諷或夸張難以捕捉。




)





機制:讓AI擁有“短期記憶”與“長期記憶”)

Auto-Encoding Variational Bayes)






