12滑動窗口—將 x 減到 0 的最小操作數
題目傳送門
題目描述:
給你一個整數數組?
nums?和一個整數?x?。每一次操作時,你應當移除數組?nums?最左邊或最右邊的元素,然后從?x?中減去該元素的值。請注意,需要?修改?數組以供接下來的操作使用。
如果可以將?x?恰好?減到?0?,返回?最小操作數?;否則,返回?-1?。
示例 1:
輸入 nums = [1,1,4,2,3], x = 5
輸出: 2
解釋 最佳解決方案是移除后兩個元素,將 x 減到 0 。
示例 2:
輸入 nums = [5,6,7,8,9], x = 4
輸出:-1
示例 3:
輸入 nums = [3,2,20,1,1,3], x = 10
輸出: 5
解釋: 最佳解決方案是移除后三個元素和前兩個元素(總共 5 次操作),將 x 減到 0 。
這里我們通過示例1里面的數據,我們可以發現最優的操作次數是2次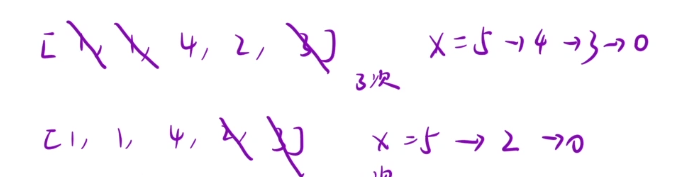
對于示例2來說的話,我們不論是從左邊還是右邊進行刪除操作,我們的x永遠不可能到0的,所以我們返回-1
現在我們將問題進行轉換:原來要求的是我們從最左邊或者是最右邊進行x刪除元素,直到x變成0。那么我們可以將這個進行區域劃分,如下圖,左邊的區域是a,右邊的區域是b,a區域和b區域里面的數值加起來等于x,那么我們中間剩下的就是我們整個數組的值減去x,題目讓我們求出最小的操作次數,那么就是說我們a+b最短的情況,換種思路,就是中間區域最長的情況,即sum-x,我們只要求出整個數組中和為sum-x的區域的最長值就行了
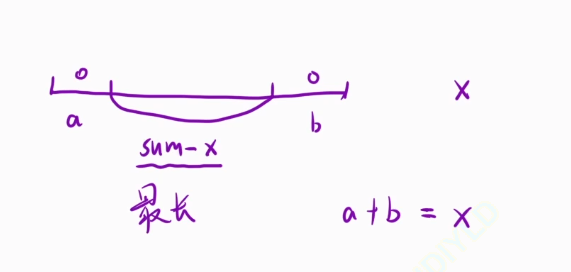
找出最長的子數組的長度,子數組的所有元素的和正好等于sum-x
做這種題我們可以想對立面
我們可以先想想 暴力解法:我們設置兩個指針,左和右,我們讓兩個指針一開始指向起點,然后讓右指針進行移動操作,直到我們的兩個指針的區域間的值大于等于sum-x,我們就更新下我們的操作次數,然后移動我們的左指針繼續進行更新的操作
當我們的左指針往右邊移動了,那么我們的右指針就沒有必要往左邊進行移動了,因為我們左指針向右移動過后,我們的兩個指針區間中的元素大小更小了,我們右指針只能往右移動
那么我們現在在這個暴力解法的基礎上進行優化
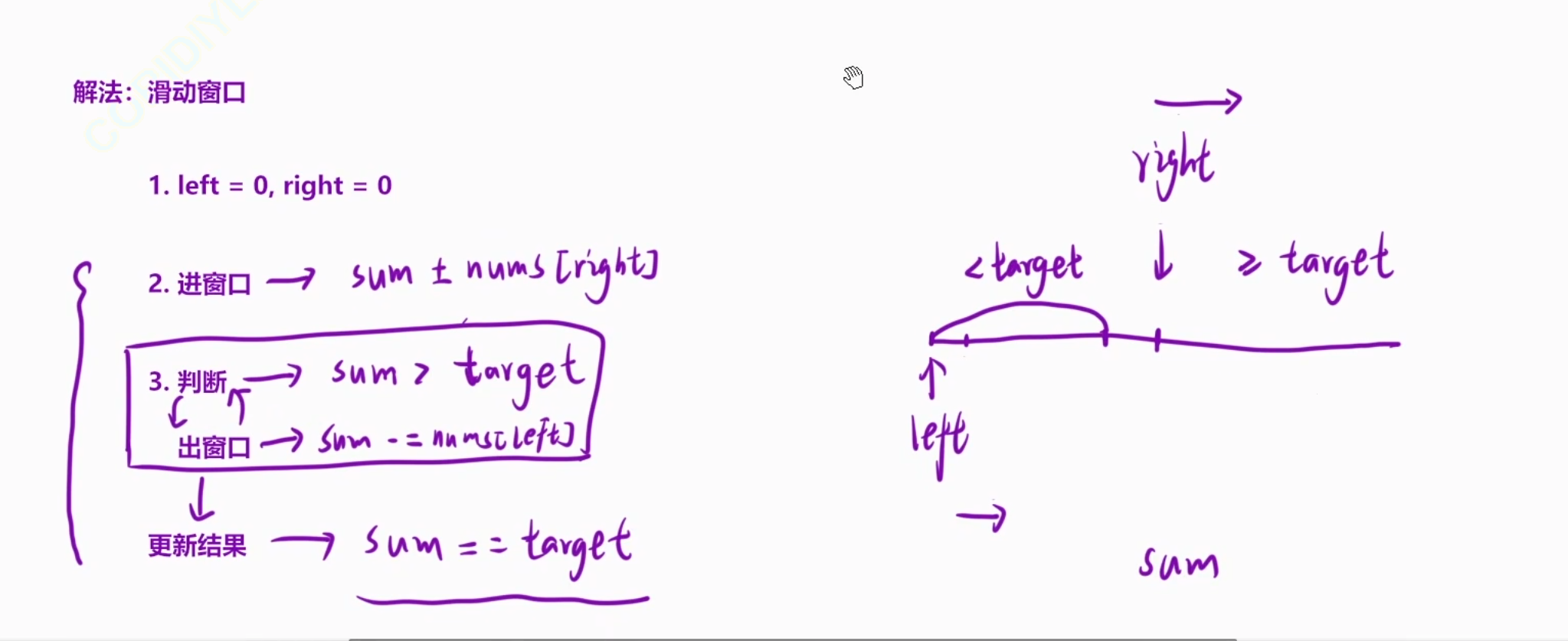
class Solution {public:int minOperations(vector<int>& nums, int x){int sum =0;for(int a:nums){sum+=a;}int target =sum-x;//細節問題,target的值不能小于0if(target<0) return -1;int ret=-1;for(int left=0,right=0,tmp=0;right<nums.size();right++){//tmp來計算我們左右指針中間的值的大小的tmp+=nums[right];//進窗口的操作while(tmp>target)//進行判斷,如果區間中的值大于了target我們就停下來{tmp-=nums[left];left++;//出窗口}if(tmp==target)//更新結果{//更新我們兩個指針中間的長度ret=max(ret,right-left+1);}}if(ret==-1) return ret;//沒有找到else return nums.size()-ret;//找到的話我們直接返回我們的這個總長度減去我們中間的值}};
13滑動窗口—水果成籃
題目傳送門
你正在探訪一家農場,農場從左到右種植了一排果樹。這些樹用一個整數數組?fruits?表示,其中?fruits[i]?是第?i?棵樹上的水果?種類?。
你想要盡可能多地收集水果。然而,農場的主人設定了一些嚴格的規矩,你必須按照要求采摘水果:
- 你只有?兩個?籃子,并且每個籃子只能裝?單一類型?的水果。每個籃子能夠裝的水果總量沒有限制。
- 你可以選擇任意一棵樹開始采摘,你必須從?每棵?樹(包括開始采摘的樹)上?恰好摘一個水果?。采摘的水果應當符合籃子中的水果類型。每采摘一次,你將會向右移動到下一棵樹,并繼續采摘。
- 一旦你走到某棵樹前,但水果不符合籃子的水果類型,那么就必須停止采摘。
給你一個整數數組?fruits?,返回你可以收集的水果的?最大?數目。
示例 1:
輸入: fruits = [1,2,1 ]
輸出 3
解釋: 可以采摘全部 3 棵樹。
示例 2:
輸入: fruits = [0,_1,2,2]
輸出: 3
解釋: 可以采摘 [1,2,2] 這三棵樹。
如果從第一棵樹開始采摘,則只能采摘 [0,1] 這兩棵樹。
示例 3:
輸入: fruits = [1,_2,3,2,2]
輸出: 4
解釋: 可以采摘 [2,3,2,2] 這四棵樹。
如果從第一棵樹開始采摘,則只能采摘 [1,2] 這兩棵樹。
示例 4:
輸入: fruits = [3,3,3,1,2,1,1,2,3,3,4]
輸出: 5
解釋: 可以采摘 [1,2,1,1,2] 這五棵樹。
我們現在有兩個籃子進行摘水果,然后每個籃子只能裝一個水果,不能裝多種水果,我們現在按實例2來說,示例二我們先采摘0號水果,然后再采摘1號水果,然后我們就不能采摘了,因為再后面的2號水果和1號水果種類不同,所以我們是只能采摘2棵樹,但是我們如果從1號開始采摘的話,我們然后可以摘2號水果,我們再還能接著采摘2號水果,所以我們這種方案是可以采摘3棵樹的
就是我們的兩個籃子只能裝兩種類型的水果,就是一個區間只能存在兩種數字,不能存在第三種數字
轉化: 找出一個最長的子數組,子數組里面不超過兩種類型的水果
暴力解法:直接將所有的子數組都給找出來,找出其中最長的一個
我們可以借助一個哈希表來記錄我們當前出現水果種類的次數
我們現在定義兩個指針,左和右,兩個指針都從最開始的位置行動,右指針保持運行,直到我們水果的種類大于2了,我們就停下來,那么此時左和右中間的區域就是我們要求的
然后我們的左指針往右運行,那么我們就得想想我們的右指針回不回來呢?是不是和左指針重新開始還是說直接從上次的位置開始
我們的左指針往右運行,那么我們水果種類只能出現兩種:不變或者是變小,絕不可能變大,因為我們左往右走了一步,水果少了一個
如果這個在左指針運行后,我們水果的種類不變的話,我們右指針就沒必要品回來了
如果水果種類減少的話,那么我們區間里面還是只存在一種類型的結果,我們的右指針也是沒有必要回去的,右指針直接右移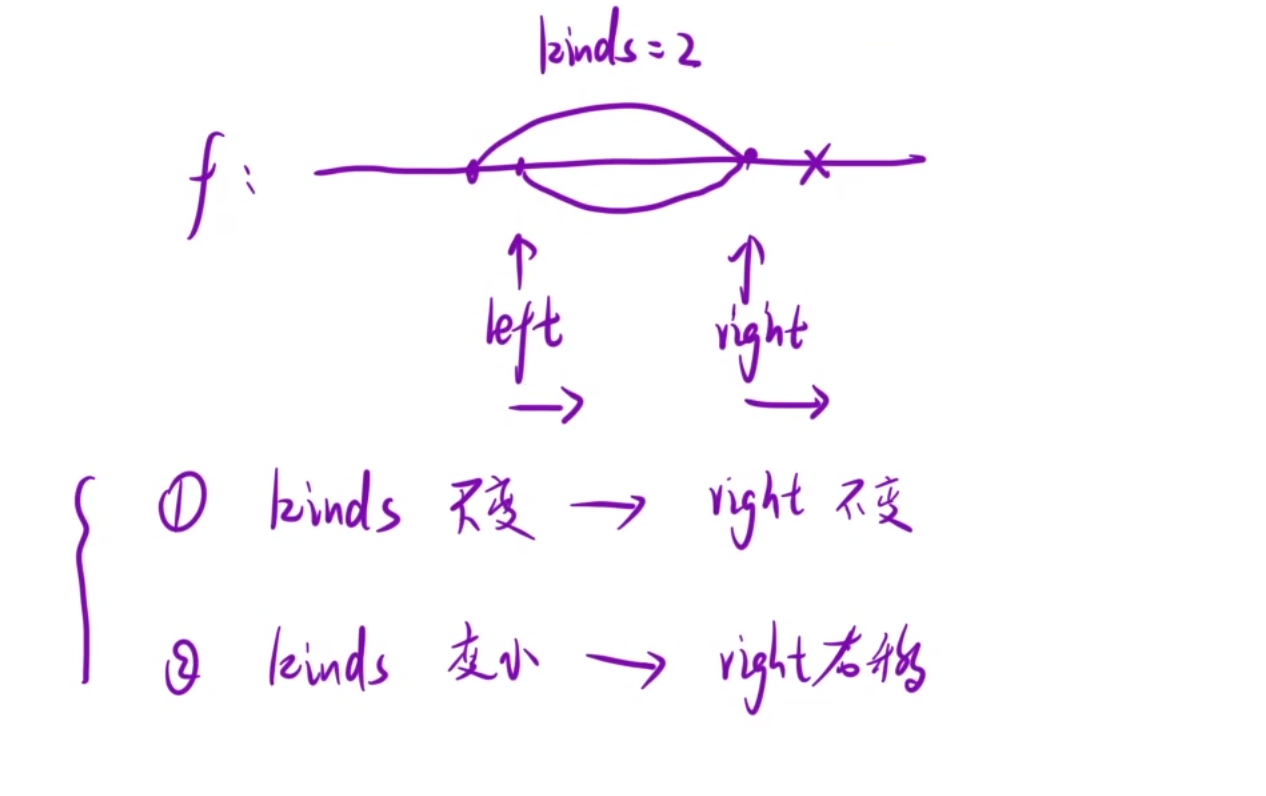
那么我們就可以使用滑動窗口進行解答了
進窗口的操作就是將我們右指針指向的元素丟到哈希表中
如果這個哈希表的長度大于2的話,我們就進行出窗口的操作
在哈希表中,我們不僅僅存入這個水果的種類,還要存入水果的數量
在出窗口的時候我們還要對我們哈希表中的元素進行判斷,如果某種種類的水果數量變成了0的話,那么我們要將這個水果從哈希表中刪除的
下面是我們的代碼
class Solution {public:int totalFruit(vector<int>& f){unordered_map<int ,int>hash;//統計窗口內出現多少種水果int ret=0;for(int left=0,right=0;right<f.size();right++){hash[f[right]]++;//進窗口while(hash.size()>2)//進行判斷,查看我們哈希表中的水果種類是否大于2{//出窗口操作hash[f[left]]--;//因為我們當前left要往右邊走,那么我們就得判斷下我們這個減少數量的這個水果的個數是否變成了0if(hash[f[left]]==0)//如果這個水果數量變成了0的話,那么我們就得將這個水果從哈希表中刪除了{hash.erase(f[left]);//將這個種類變為0的水果從哈希表中刪除}left++;//左指針往右邊走}ret=max(ret,right-left+1);//更新結果,結果就是我們左右指針中間的區間的長度}return ret;}};
但是我們發現我們的這個時間復雜度不行,因為我們哈希表中插入刪除元素
所以我們這里是可以進行優化的操作的,對當前的哈希表進行優化操作
我們可以直接利用一個數組來創建哈希表,并且增加一個變量kinds來表示我們水果的種類
下面我們就是直接利用數組進行操作
class Solution {public:int totalFruit(vector<int>& f){int hash[100001]={0};//統計窗口內出現多少種水果int ret=0;for(int left=0,right=0,kinds=0;right<f.size();right++){//如果當前right指針指向的水果的個數為0的話,我們就種類++if(hash[f[right]]==0) kinds++;//維護水果的種類hash[f[right]]++;//進窗口while(kinds>2)//進行判斷,查看我們哈希表中的水果種類是否大于2{//出窗口操作hash[f[left]]--;//因為我們當前left要往右邊走,那么我們就得判斷下我們這個減少數量的這個水果的個數是否變成了0if(hash[f[left]]==0)//如果這個水果數量變成了0的話,我們直接讓種類減一{kinds--;}left++;//左指針往右邊走}ret=max(ret,right-left+1);//更新結果,結果就是我們左右指針中間的區間的長度}return ret;}};
14滑動窗口_找到字符串中所有字母異位詞
題目鏈接
給定兩個字符串?s?和?p,找到?s?中所有?p?的
異位詞
的子串,返回這些子串的起始索引。不考慮答案輸出的順序。
示例?1:
輸入: s = “cbaebabacd”, p = “abc”
輸出: [0,6]
解釋:
起始索引等于 0 的子串是 “cba”, 它是 “abc” 的異位詞。
起始索引等于 6 的子串是 “bac”, 它是 “abc” 的異位詞。
示例 2:
輸入: s = “abab”, p = “ab”
輸出: [0,1,2]
解釋:
起始索引等于 0 的子串是 “ab”, 它是 “ab” 的異位詞。
起始索引等于 1 的子串是 “ba”, 它是 “ab” 的異位詞。
起始索引等于 2 的子串是 “ab”, 它是 “ab” 的異位詞
我們需要快速判斷兩個字符串是異位詞,我們可以通過比較兩個字符串來比較判斷是否是異位詞

操作方式就是利用哈希表來進行計數
下方就是暴力解法:不斷的比較
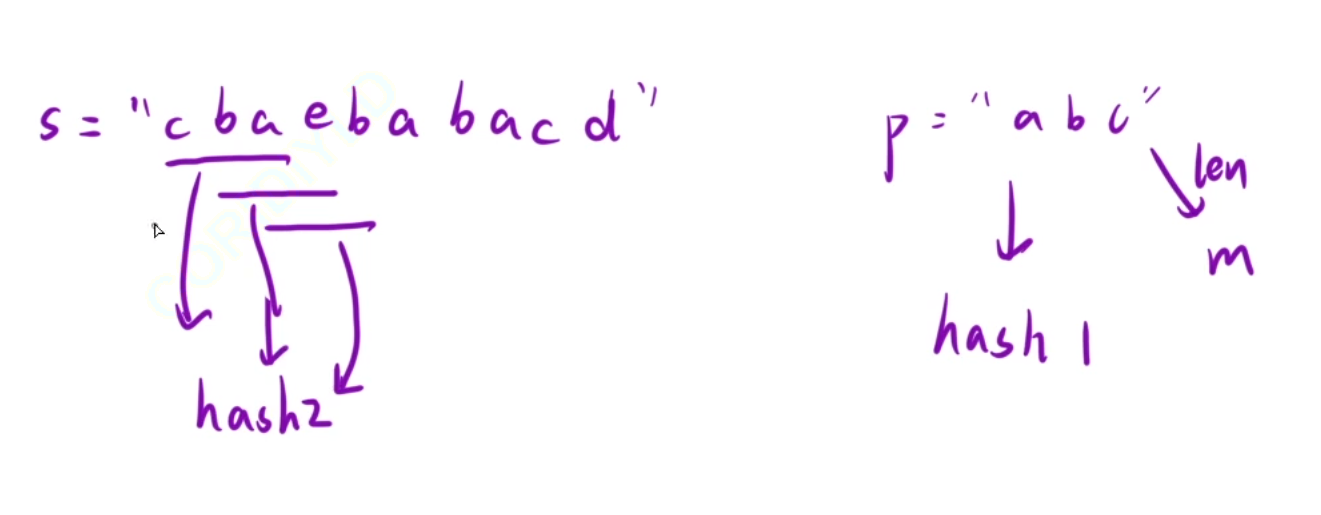
一次移動len個子串然后和另一個子串進行比較,那么我們這里是可以用滑動窗口進行解答的
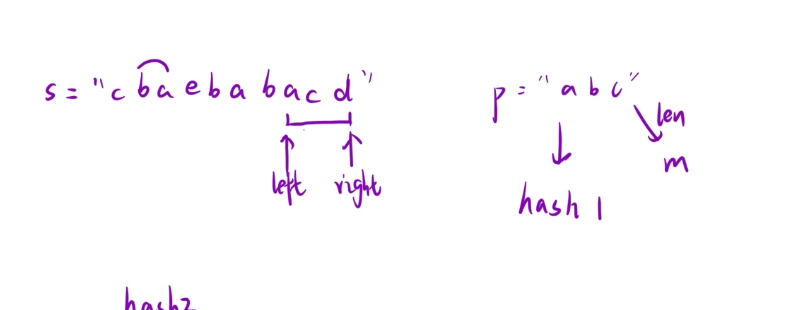
利用count來統計窗口中有效字符的個數
進窗口后我們考慮下我們進窗口的這個數據是否是有效的數據,這個字母的出現個數是否個另一個字符串里面對應字母的出現次數相等
出窗口之前我們判斷下我們出去這個字符是否是有效字符,是有效字符的話那么我們就進行count–操作
然后我們更新結果
class Solution {public:vector<int> findAnagrams(string s, string p){vector<int >ret;int hash1[26]={0};//統計字符串p中每個字符出現的個數for(auto ch:p){hash1[ch-'a']++;//對應字符的下標,統計對應字母出現的次數}int hash2[26]={0};//統計窗口里面的每一個字符出現的個數int m=p.size();for(int left=0,right=0,count=0;right<s.size();right++){char in =s[right];//進窗口hash2[in-'a']++;//統計對應字符出現的個數if(hash2[in-'a']<=hash1[in-'a']) count++;//如果s中的這個字符的出現次數小于p中字符出現的個數的話,那么有效字符要++的if(right-left+1>m)//判斷,這個就是窗口大了,我們得進行出窗口的操作{//出窗口&&維護countchar out=s[left++];//將這個元素丟出去,將這個元素丟出去,我們的left往右走if(hash2[out-'a']<=hash1[out-'a']) count--;//如果滿足條件的話,那么就說明當前滑出去的是一個有效字符hash2[out-'a']--;}//更新if(count==m) ret.push_back(left);//直接將起始位置的下標進行輸出}return ret;}};
說白了就是一直維持這個count的大小,然后知道count的大小等于這個p字符串的長度了,我們就將起始的左指針進行返回的操作
15滑動窗口—串聯所有單詞的子串
題目鏈接
給定一個字符串?s?和一個字符串數組?words。?words?中所有字符串?長度相同。
s?中的?串聯子串?是指一個包含??words?中所有字符串以任意順序排列連接起來的子串。
- 例如,如果?
words = ["ab","cd","ef"], 那么?"abcdef",?"abefcd","cdabef",?"cdefab","efabcd", 和?"efcdab"?都是串聯子串。?"acdbef"?不是串聯子串,因為他不是任何?words?排列的連接。
返回所有串聯子串在?s?中的開始索引。你可以以?任意順序?返回答案。
示例 1:
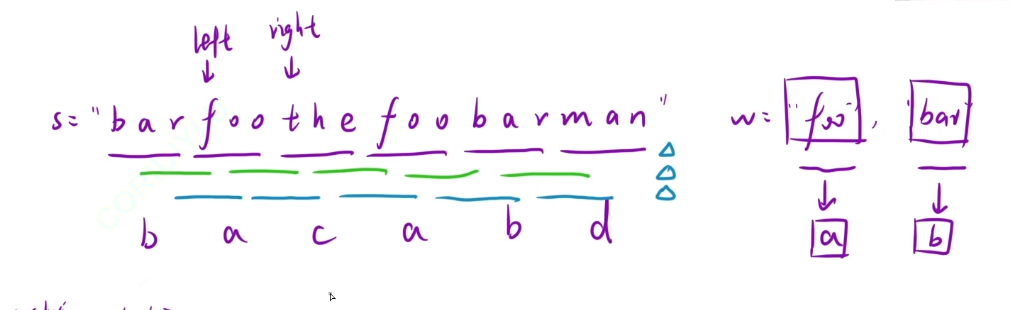
輸入: s = “barfoothefoobarman”, words = [“foo”,“bar”]
輸出:[0,9]
解釋: 因為 words.length == 2 同時 words[i].length == 3,連接的子字符串的長度必須為 6。
子串 “barfoo” 開始位置是 0。它是 words 中以 [“bar”,“foo”] 順序排列的連接。
子串 “foobar” 開始位置是 9。它是 words 中以 [“foo”,“bar”] 順序排列的連接。
輸出順序無關緊要。返回 [9,0] 也是可以的。
示例 2:
輸入: s = “wordgoodgoodgoodbestword”, words = [“word”,“good”,“best”,“word”]
輸出 []
解釋: 因為 words.length == 4 并且 words[i].length == 4,所以串聯子串的長度必須為 16。
s 中沒有子串長度為 16 并且等于 words 的任何順序排列的連接。
所以我們返回一個空數組。
示例 3:
輸入: s = “barfoofoobarthefoobarman”, words = [“bar”,“foo”,“the”]
輸出:[6,9,12]
解釋: 因為 words.length == 3 并且 words[i].length == 3,所以串聯子串的長度必須為 9。
子串 “foobarthe” 開始位置是 6。它是 words 中以 [“foo”,“bar”,“the”] 順序排列的連接。
子串 “barthefoo” 開始位置是 9。它是 words 中以 [“bar”,“the”,“foo”] 順序排列的連接。
子串 “thefoobar” 開始位置是 12。它是 words 中以 [“the”,“foo”,“bar”] 順序排列的連接。
我們可以將題目進行轉換,在左邊的字符串中找到我們右邊的a b的異位詞就行了,那么這個題就很像之前的那個找到字符串中所有字母異位詞這個題了
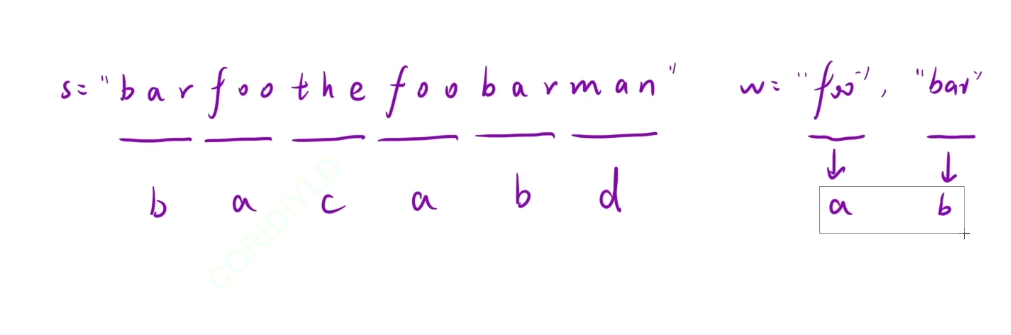
找到一個字符串就返回起始位置
那么這個題我們就會使用到滑動窗口和哈希表了
相較于找到字符串中所有字母異位詞這個題的話,我們有三點不同
-
哈希表
之前的那題我們里面的哈希表存儲的是一個個的字符,這里的話我們是一個又一個的字符串 -
left和right指針的移動
因為我們字符串數組里面的字符串的長度都是相等的,那么我們在移動的時候為了讓新的字符串進入到窗口的話,那么我們每次移動的話是需要前進len個距離,len就是我們單個字符串的長度
移動的步長是每個單詞的長度 -
滑動窗口的執行次數
我們滑動窗口執行的次數是len次
因為我們的指針不僅僅是從第一個位置開始的,也可能從第二個位置,甚至第len個位置,如果從len+1的位置開始的話,那么就是重復了,和從第一個位置開始的情況重疊了,所以我們進行滑動窗口的次數是len次
class Solution {public:vector<int> findSubstring(string s, vector<string>& words){vector<int> ret;//創建一個哈希表并且將單詞在word中出現的次數進行記錄unordered_map<string, int> hash1;;//保存words里面所有的單詞的頻次for(auto& s:words) hash1[s]++;//記錄words里面所有的單詞出現的頻次//計算單詞的長度int len=words[0].size(),m=words.size();//多少個單詞//我們這里的滑動窗口是需要執行len次的for(int i=0;i<len;i++)//執行len次滑動窗口{unordered_map<string,int>hash2;//維護滑動窗口內單詞的頻次//因為我們right在移動到對應的位置后,我們需要將right+len個字符放到滑動窗口里面去for(int left=i,right=i,count=0;right+len<=s.size();right+=len)//count就是有效字符串的個數了{//進窗口+維護countstring in =s.substr(right,len);//直接獲取right后面len個字符,那么in就是一個字符串了hash2[in]++;//我們將in這個字符出現的頻次進行更新if(hash2[in]<=hash1[in]) count++;//如果我們hash2這個哈希中當前字符串出現的頻次小于hash1的話,說明是有效單詞,如果我們哈希2里面這個字符串出現次數大于哈希1的話,那么這個肯定是一個無效的單詞,因為hash1中都沒有進行記錄//判斷if(right-left+1>len*m)//如果我們當前左右指針的范圍大于我們要找的子串的長度的話,那么我們就進行出窗口操作{//出窗口,維護countstring out=s.substr(left,len);//我們將left后面三個單詞的范圍的這個字符串拿出來if(hash2[out]<=hash1[out]) count--;//有效單詞減一hash2[out]--;//出完窗口之后,我們的left需要向后移動left+=len;}//更新結果if(count==m) ret.push_back(left);//將我們}}//當整個循環結束之后,我們ret中存儲的就是結果了return ret;}};
我們先創建一個哈希1,用來存儲我們words中的單詞出現的次數,利用范圍for獲得每個單詞出現的頻次
然后我們再計算len就是每個單詞的長度,因為這個題中每個單詞的長度都是一樣的
然后我們再來一個for循環,次數就是len次,因為我們的左指針有效循環的次數就是len次,如果是len+1次的話,那么結果是和第一次的結果是相同的
在這個for循環中我們再來一個for循環進行進窗口的操作,在進窗口之前我們需要創建一個哈希2來記錄我們滑動窗口內單詞的頻次
這個內循環的我們需要維護好count,就是窗口內有效單詞的數量,如果沒有在哈希1中出現過的,統統都是無效單詞,出現過的才算是有效單詞
然后我們進行進窗口的操作,利用substr獲取我們right后面len個范圍的單詞,將這個字符串放到in中,然后給hash2記錄這個單詞出現的次數,我們在進窗口后我們維護好我們的count,如果當前的單詞在hash2中出現的次數小于hash1中出現的次數的話,那么就證明這個單詞是有效的,為什么呢?因為如果hash2中這個單詞出現的次數大于hash1中的話,那么這個單詞就是無效的,在hash1中不存在的,所以hash2中出現次數小于等于hash1中單詞的次數的話,那么在這個單詞就是有效的單詞,那么我們count++
然后我們進行判斷,如果我們當前的right和left的范圍大于我們words中字符串組合成的字符串的長度的話,那么我們就進行出窗口的操作,我們就得將我們的left往右邊進行移動了,還是利用substr獲取我們left后面len個字符的字符串,將這個字符串存在out中,然后將hash2中的out這個字符串給減一,在減一之前我們還需要維護下我們的count,對我們這個單詞進行判斷,是否是有效的單詞
出完窗口后,我們的left需要往右邊進行移動,移動的距離是len
然后我們進行結果的更新,如果我們count=m的話,那么我們將此時的left,就是這個對應字符串的開始位置存儲子啊我們的vector容器中去
最后直接返回了
但是吧,我們當前的這個效率比較慢,因為我們在判斷當前的字符串是否是有效的字符串的時候,如果我們這個字符串in在hash1中不存在 的話,那么我們就得進行創建hash1[in]了,所以這里是存在效率變低的,所以我們可以在判斷條件中加上hash1.count(in)來判斷我們的這個單詞的數量,如果是0的話,我們 直接退出了這個條件判斷了
class Solution {public:vector<int> findSubstring(string s, vector<string>& words){vector<int> ret;//創建一個哈希表并且將單詞在word中出現的次數進行記錄unordered_map<string, int> hash1;;//保存words里面所有的單詞的頻次for(auto& s:words) hash1[s]++;//記錄words里面所有的單詞出現的頻次//計算單詞的長度int len=words[0].size(),m=words.size();//多少個單詞//我們這里的滑動窗口是需要執行len次的for(int i=0;i<len;i++)//執行len次滑動窗口{unordered_map<string,int>hash2;//維護滑動窗口內單詞的頻次//因為我們right在移動到對應的位置后,我們需要將right+len個字符放到滑動窗口里面去for(int left=i,right=i,count=0;right+len<=s.size();right+=len)//count就是有效字符串的個數了{//進窗口+維護countstring in =s.substr(right,len);//直接獲取right后面len個字符,那么in就是一個字符串了hash2[in]++;//我們將in這個字符出現的頻次進行更新if(hash1.count(in)&&hash2[in]<=hash1[in]) count++;//如果我們hash2這個哈希中當前字符串出現的頻次小于hash1的話,說明是有效單詞,如果我們哈希2里面這個字符串出現次數大于哈希1的話,那么這個肯定是一個無效的單詞,因為hash1中都沒有進行記錄//判斷if(right-left+1>len*m)//如果我們當前左右指針的范圍大于我們要找的子串的長度的話,那么我們就進行出窗口操作{//出窗口,維護countstring out=s.substr(left,len);//我們將left后面三個單詞的范圍的這個字符串拿出來if(hash1.count(out)&&hash2[out]<=hash1[out]) count--;//有效單詞減一hash2[out]--;//出完窗口之后,我們的left需要向后移動left+=len;}//更新結果if(count==m) ret.push_back(left);//將我們}}//當整個循環結束之后,我們ret中存儲的就是結果了return ret;}};
16滑動窗口—最小覆蓋子串
題目鏈接
給你一個字符串?s?、一個字符串?t?。返回?s?中涵蓋?t?所有字符的最小子串。如果?s?中不存在涵蓋?t?所有字符的子串,則返回空字符串?""?。
注意:
- 對于?
t?中重復字符,我們尋找的子字符串中該字符數量必須不少于?t?中該字符數量。 - 如果?
s?中存在這樣的子串,我們保證它是唯一的答案。
示例 1:
輸入: s = “ADOBECODEBANC”, t = “ABC”
輸出:“BANC”
解釋: 最小覆蓋子串 “BANC” 包含來自字符串 t 的 ‘A’、‘B’ 和 ‘C’。
示例 2:
輸入: s = “a”, t = “a”
輸出:“a”
解釋: 整個字符串 s 是最小覆蓋子串。
示例 3:
輸入: s = “a”, t = “aa”
輸出: “”
解釋: t 中兩個字符 ‘a’ 均應包含在 s 的子串中,
因此沒有符合條件的子字符串,返回空字符串。
只要我們的s中可以將t全部涵蓋了的話,那么就是符合要求的
使用暴力解決,如果hash2中的ABC的次數大于hash1中的次數的話,那么hash2里面存的這一段字符串就是有效的字符串了
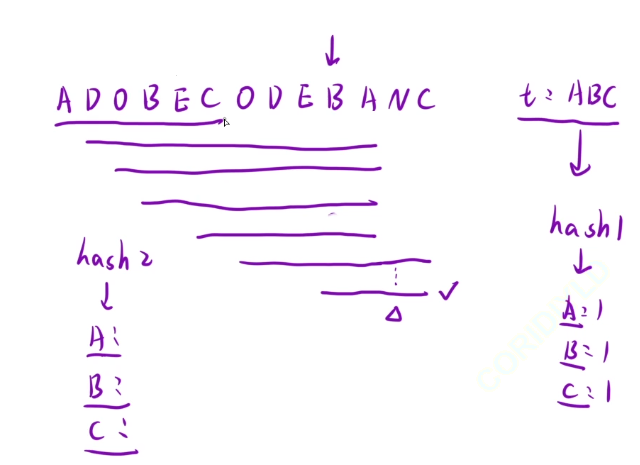
然后接下來從D這個位置接著枚舉,就這種暴力解決的方法
解法一:暴力枚舉+哈希表
那么我們是否可以在這個解法的基礎上進行優化呢
我們在找到符合要求的一組之后,我們的left往右走,那么此時我們的right是沒有必要回去的
如果我們原先left指向的元素他的出現次數太多了或者是一個無效的,那么我們的left往右邊移動一位,和此時right組成的區間依舊是有效的
但是如果我們原先left指向的元素是一個有效字符并且出現次數的小于我們hash1中的次數,那么我們此時的區間就是不符合要求的,我們的right依舊不用回來,繼續向后面走,直到找到了符合要求的那個元素為止
那么優化的方案就是滑動窗口+哈希表
當我們的窗口合法之后我們再進行出窗口的操作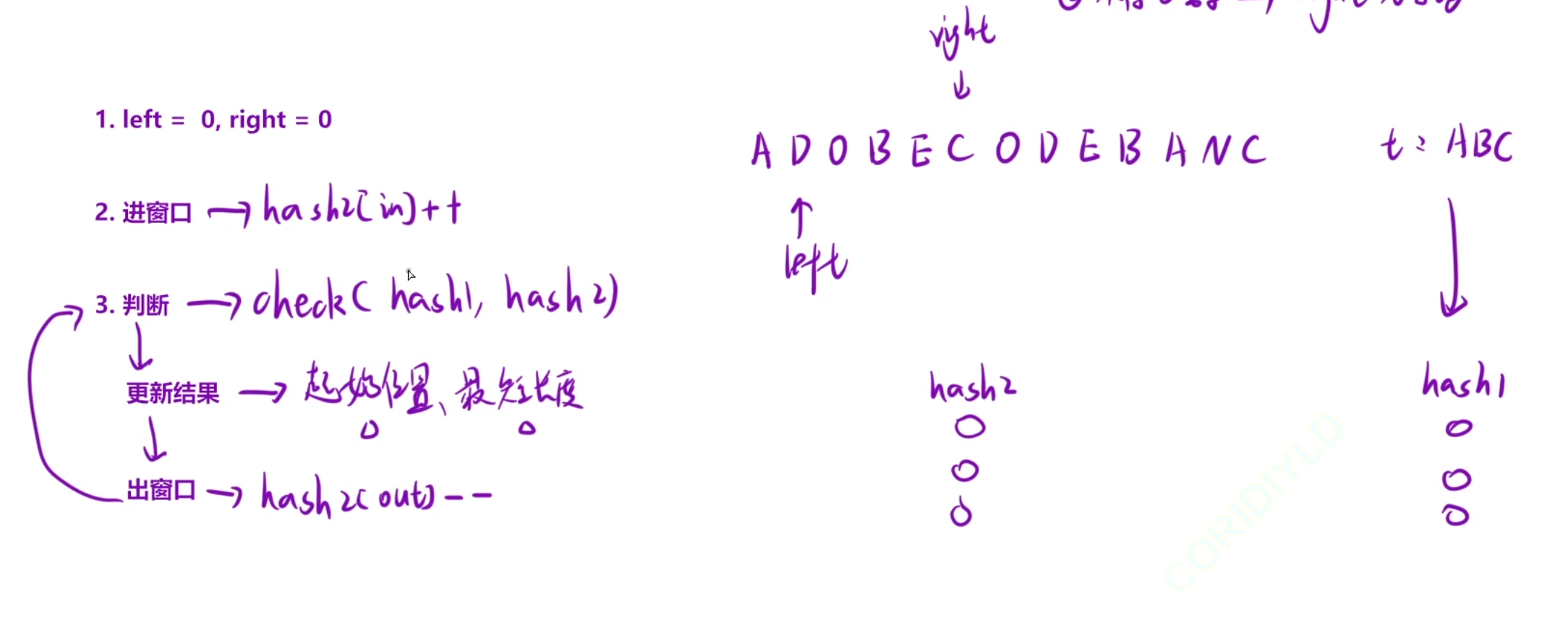
優化操作
我們使用count標記有效字符的種類 ,我們這里需要hash2中出現hash1中所有種類的字符,而不是個數,我們一定要按照有效字符種類來進行操作
我們進窗口的時候維護一下count,出窗口的時候維護一下count,判斷的時候判斷一下count
class Solution {public:string minWindow(string s, string t){int hash1[128]={0};//統計t字符串中每一個字符出現的頻次int kinds=0;//統計有效字符有多少種for(auto ch:t){//如何判斷我們當前的有效字符種類是否增加了呢?//如果在進窗口前這個字符數量為0 的話,并且是有效字符的話,那么我們的種類就多了一種了if(hash1[ch]==0) kinds++;//有效字符的種類加一hash1[ch]++;}//出了循環我們就統計到了我們字符的種類數量int hash2[128]={0};//統計窗口內每個字符的頻次int minlen=INT_MAX,begin=-1;for(int left=0,right=0,count=0;right<s.size();right++){char in=s[right];//獲取我們這個字符的信息hash2[in]++;//給這個字符的次數++//判斷我們加入的字符是否是有效字符//進窗口+維護count變量if(hash2[in]==hash1[in]) count++;//說明我們加入了一個有效的字符//判斷條件while(count==kinds){//更新結果if(right-left+1<minlen)//說明此時我們需要更新結果了{//計算最小的子串的長度minlen=right-left+1;//開始的指針指向我們的leftbegin=left;}//出窗口char out =s[left];//記錄當前出窗口的單詞left++;//左指針往右邊走//維護countif(hash2[out]==hash1[out])count--;//說明我們當前的字符是有效字符hash2[out]--;//將當前出窗口的字符進行--操作}}if(begin==-1) return "";//如果我們開始的指針沒有變的話,那么我們就直接返回空就行了else return s.substr(begin,minlen);//如果變了的話,我們begin后面minlen個范圍的字符串獲取然后返回就行了}};
我們先創建hash1來記錄我們t中字符出現的次數,創建變量kinds記錄種類,
然后我們遍歷t,獲取我們的種類的數量,并且記錄字符出現的頻次
然后我們創建hash2來記錄我們窗口中的每個字符出行的頻次
創建變量minlen記錄我們當前最小的子串長度,以及開始的指針begin
然后我們進入到滑動窗口的操作,我們先獲取我們right指針的位置上的元素,并且在hash2中記錄出現的次數
然后我們在進窗口后判斷下當前進的這個字符是否是有效的字符,并且進行維護我們的count(字符種類)
是否是有效的字符,我們依靠這段代碼hash2[in]==hash1[in],如果我們hash2中進的這個字符的次數等于我們hash1中字符的次數的話,那么我們就判定當前字符是有效的
如果有效的話,那么我們當前的count就++
進行判斷,如果我們的count的大小等于我們的kinds的話,就是說明我們當前的窗口就是一個有效的窗口了
那么我們就進行結果的更新操作
記錄我們當前區間的長度:right-left+1 并且記錄我們當前的begin
然后我們再進行出窗口的操作,我們記錄我們當前left位置的元素,然后從hash2中減少次數
并且我們在減少次數之前我們需要判斷下我們這個出窗口的元素是否是有效的字符,
最后出了循環,我們就返回對應的結果了
![[MySQL初階]MySQL表的操作](http://pic.xiahunao.cn/[MySQL初階]MySQL表的操作)







)










