老規矩,今天是使用Gemini2.5pro來生成的模板
這篇論文研究了如何為處理多個相關任務的強化學習智能體自動設計學習課程(即任務順序),以加速訓練過程,并解決現有方法需要大量調參或缺乏理論依據的問題。為此,作者受到教育學中“最近發展區”(Zone of Proximal Development, ZPD)概念的啟發,提出了一種名為 PROCURL 的新策略。該策略的核心思想是選擇那些對智能體來說既不太難也不太容易、預期學習進展最大的任務。作者首先在簡化的理論模型中推導了這一策略,然后設計了一個實用的版本,該版本通過評估智能體對不同任務的 Q 值(動作價值)的統計特性(如標準差)來估計學習潛力,從而選擇下一個訓練任務。這種方法易于集成到現有的深度強化學習框架中,且需要很少的調整。最后,通過在多種模擬環境中的實驗,證明了 PROCURL 相比其他方法能更有效地提升智能體的學習速度
1. 問題陳述 (Problem Statement)
該論文討論了在上下文多任務設置 (contextual multi-task settings) 中為強化學習 (RL) 智能體設計課程的問題。具體來說,它解決了以下問題:
- 現有的自動課程設計技術通常需要大量的領域特定的超參數調整。
- 許多當前方法缺乏強有力的理論基礎來證明其設計選擇的合理性。
- 目標是開發一種課程策略,通過優化選擇任務來加速深度強化學習智能體的訓練過程。
2. 挑戰 (Challenges)
論文中考慮了在為強化學習智能體設計課程時面臨的以下挑戰:
- 平衡探索與利用 (Balancing Exploration and Exploitation): 決定何時專注于智能體已經擅長的任務,何時探索新的、可能更難的任務。
- 任務選擇難度 (Task Selection Difficulty): 識別具有適當挑戰性的任務——既不能太簡單(導致進展緩慢),也不能太難(可能阻礙學習)。這與最近發展區 (Zone of Proximal Development, ZPD) 的概念有關。
- 實際實施 (Practical Implementation): 設計一種易于與現有深度強化學習框架集成、且需要最少超參數調整的策略。
- 理論依據 (Theoretical Justification): 開發一種基于可靠理論原則而非純粹經驗啟發式的課程策略。
3. 解決方案如何應對挑戰 (How the Solution Addresses the Challenges)
論文提出的解決方案 PROCURL (Proximal Curriculum for Reinforcement Learning) 通過以下方式應對這些挑戰:
- 平衡探索與利用 / 任務選擇: PROCURL 在數學上操作化了 ZPD 概念。它根據性能的預期提升 (expected improvement) 來選擇任務,優先考慮那些智能體預期能學到最多的任務。這內在地平衡了在既不太簡單也不太困難的任務上的學習。
- 實際實施: 提出了 PROCURL 的一個實用變體,該變體使用價值函數(或 Q 值)來估計預期提升,使其能夠以最小的開銷和調整與標準的深度強化學習算法兼容。
- 理論依據: PROCURL 是通過分析兩個簡化的理論設置(一個賭博機設置和一個線性上下文賭博機設置)中的學習進展推導出來的,為該策略提供了理論基礎。
4. 解決方案陳述 (Solution Statement)
該論文提出了一種名為 PROCURL 的課程學習策略,具有以下關鍵方面:
- 其靈感來源于教育學概念最近發展區 (ZPD),即當任務既不太容易也不太難時,學習效果最大化。
- 它通過最大化智能體性能的預期提升來數學化任務選擇過程,這一概念是在簡化設置中理論推導出來的。
- 它提供了一個實用變體,該變體易于集成到深度強化學習框架中,使用價值函數來估計預期提升,并且需要最少的超參數調整。
5. 系統模型 (System Model)
論文在上下文多任務強化學習設置中對學習問題進行建模。系統表示如下:
- 一組任務(或上下文),表示為 C。
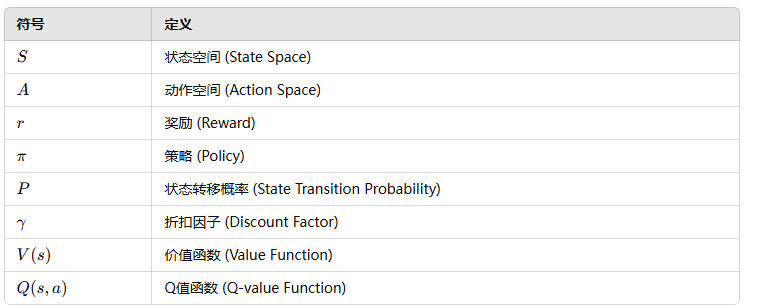
- 對于每個任務 c ∈ C,都有一個相關的馬爾可夫決策過程 (MDP),M<sub>c</sub> = (S, A, P<sub>c</sub>, R<sub>c</sub>, γ),其中 S 是狀態空間,A 是動作空間,P<sub>c</sub> 是轉移概率函數,R<sub>c</sub> 是獎勵函數,γ 是折扣因子。
- 智能體維護一個由 θ 參數化的策略 π<sub>θ</sub>。
- 智能體在任務 c 上的性能通過預期回報 J<sub>c</sub>(θ) = E<sub>π<sub>θ</sub>, M<sub>c</sub></sub>[∑<sub>t=0</sub><sup>∞</sup> γ<sup>t</sup> R<sub>c</sub>(s<sub>t</sub>, a<sub>t</sub>)] 來衡量。
- 總體目標通常是最大化所有任務的平均性能,J(θ) = (1/|C|) ∑<sub>c∈C</sub> J<sub>c</sub>(θ)。
- 課程設計問題涉及在每個步驟選擇一個任務序列或任務分布來訓練智能體,以最大化朝著最終目標的學習速度。
論文中的圖 1 說明了在上下文多任務設置中課程學習的總體概念。
6. 符號表示 (Notation)
7. 設計 (Design)
設計問題被表述為在每個訓練步驟選擇下一個要訓練智能體的任務(或一批任務),目標是最大化朝著最終目標(通常是最大化所有任務的平均性能)的學習進展。
- 設計問題: 如何在每個訓練步驟 t 選擇一個任務 c(或任務上的分布 p(c))來更新策略參數 θ<sub>t</sub> 到 θ<sub>t+1</sub>,從而使整體性能 J(θ) 盡可能快地提高。
- 決策變量: 核心決策變量是為下一次訓練更新選擇的任務 c,或者更一般地,是從中抽取下一個訓練任務的任務集合 C 上的概率分布 p(c)。PROCURL 策略旨在基于最大化預期提升的原則來計算這種選擇/分布。
圖 1 有助于可視化課程策略為 RL 智能體選擇任務的設置。圖 2 說明了指導設計的 ZPD 概念。
8. 解決方案 (確定決策變量) (Solution - Determining Decision Variables)

9. 定理 (Theorems)
該論文主要通過在簡化設置中的分析來呈現理論結果,而不是正式陳述和編號的定理。驅動 PROCURL 的核心理論見解源于對兩種設置中學習進展的分析:
-
多臂賭博機類比 (Multi-Armed Bandit Analogue) (第 3.1 節):
- 內容: 分析了一個簡化場景,其中每個“臂”對應一個任務,拉動一個臂會產生該任務梯度范數平方 (||?J<sub>c</sub>(θ)||<sup>2</sup>) 的噪聲估計。它表明,選擇當前對此梯度范數平方估計最高的臂(任務)可以最大化整體目標函數的預期單步提升。
- 解釋: 這證明了選擇性能梯度較大的任務是合理的,因為這表示了一個陡峭上升的方向,因此通過在該任務上訓練具有很高的即時改進潛力。
-
線性上下文賭博機設置 (Linear Contextual Bandit Setting) (隱含在推導中):
- 內容: 分析通常假設局部線性或使用一階泰勒近似(在優化分析中常見)來近似提升 (Δ<sub>c</sub>(θ) ≈ α ||?J<sub>c</sub>(θ)||<sup>2</sup>)。
- 解釋: 這種近似將預期的即時性能增益直接與任務特定梯度的平方范數聯系起來,強化了梯度較大的任務提供更快學習進展潛力的觀點。
雖然沒有標記為“定理 1”、“定理 2”等,但這些分析部分為 PROCURL 策略提供了理論基礎。
10. 設計過程 (執行步驟) (Process of Design - Execution Procedure)
與深度強化學習算法(如 DQN 或 DDPG)集成的實用 PROCURL 變體 (ProCuRL-val) 的分步執行過程通常如下:
- 初始化 (Initialization): 初始化智能體的策略/價值函數參數 (θ)。初始化可用任務集 C。
- 任務選擇 (Task Selection):
- 對于每個任務 c ∈ C(或當前考慮的子集):
- 使用當前策略/價值函數 π<sub>θ</sub> 估計提升潛力。在 ProCuRL-val 中,這涉及計算基于該任務 Q 值的度量,例如 std<sub>a</sub>(Q<sub>c</sub><sup>π<sub>θ</sub></sup>(s<sub>0</sub>, a)) 或 max<sub>a</sub>(Q<sub>c</sub><sup>π<sub>θ</sub></sup>(s<sub>0</sub>, a)) - min<sub>a</sub>(Q<sub>c</sub><sup>π<sub>θ</sub></sup>(s<sub>0</sub>, a))。
- 選擇最大化此估計提升度量的任務 c*。
- 對于每個任務 c ∈ C(或當前考慮的子集):
- 智能體訓練 (Agent Training):
- 與所選任務 c* 的環境交互一定數量的步驟(或回合)。
- 將收集到的經驗(轉移)存儲在回放緩沖區中(通常是特定于任務的或通用的緩沖區)。
- 采樣一批數據(可能優先考慮來自 c* 的數據或進行通用采樣)。
- 使用采樣批次和所選 RL 算法的損失函數對智能體的參數 θ 執行梯度更新步驟。
- 重復 (Repeat): 返回步驟 2(任務選擇)進行下一次訓練迭代。
- 終止 (Termination): 在固定的訓練步數、回合數后或性能收斂時停止。
11. 模擬 (Simulations)
模擬驗證了 PROCURL 相對于基線方法(如均勻/獨立同分布任務采樣、Goal GAN、ALP-GMM)在各種環境中的有效性。驗證的關鍵方面和結果包括:
- 加速學習 (Accelerated Learning): 與基線相比,PROCURL 顯著加快了訓練過程,在 PointMass、FetchReach、AntMaze 和 BasicKarel 等環境中,用更少的訓練步驟達到了更高的性能水平。(參見圖 3, 4, 5, 6, 11)。
- 魯棒性 (Robustness): 實用變體 ProCuRL-val 在沒有大量超參數調整的情況下表現良好,這與其他一些需要調整的課程方法不同。
- 可擴展性 (Scalability): 在簡單的網格世界和更復雜的具有連續狀態/動作空間的機器人模擬任務中都展示了有效性。
- ZPD 相關性 (ZPD Correlation): 分析表明,PROCURL 選擇的任務通常與中等難度水平相關,這與 ZPD 的直覺一致(例如,圖 7 顯示了任務選擇頻率)。
- 在更難任務上的性能 (Performance on Harder Tasks): 即使任務池變得更具挑戰性,PROCURL 也表現出更好的泛化能力和更快的學習速度(圖 11)。
12. 討論 (局限性與未來工作) (Discussion - Limitations and Future Work)
論文提到了以下局限性和潛在的未來工作方向:
-
局限性 (Limitations):
- 理論分析依賴于簡化的設置和近似(例如,用于提升的一階泰勒展開)。基于 Q 值的實用度量與理論上的預期提升(梯度范數)之間的直接聯系是啟發式的。
- 實際實現需要計算 Q 值統計數據以進行任務選擇,這與更簡單的策略(如均勻采樣)相比增加了一些計算開銷,盡管通常少于需要完整梯度計算的方法。
- 與許多強化學習方法一樣,即使課程部分需要較少調整,性能仍然可能對底層強化學習算法的超參數(學習率、網絡架構等)敏感。
-
未來工作 (Future Work):
- 在實用價值度量與真實預期學習進展之間建立更深入的理論聯系。
- 探索考慮長期學習進展而非僅僅下一步梯度提升的非短視課程策略。
- 研究 PROCURL 在強化學習之外的其他學習范式(如監督學習或自監督學習)中的適用性。
- 將框架擴展到處理動態變化的任務集或任務生成。
- 將 PROCURL 與自動任務生成或參數化的技術相結合。

)

:少量實驗即可找到新材料,黑盒優化?量子退火)







Linux實戰篇)

 vs Python(Flask))





