問題:主從延遲與寫后讀不一致
在典型的 MySQL 主從架構下,所有寫操作都會直接進入主庫,而讀操作大多分流到從庫,從而實現讀寫分離,緩解主庫壓力。
然而 MySQL 的復制機制是異步的:主庫先寫入 binlog,從庫 I/O 線程拉取到 relay log,再交由 SQL 線程順序回放。這個鏈路包含網絡傳輸與多步處理,因此天然會引入延遲。當網絡抖動、主庫寫入量過大或從庫執行能力不足時,延遲可能進一步加劇。
這種延遲在大多數場景下可以容忍,但在涉及 寫后立即讀 的業務時問題尤為突出。例如,用戶剛下單立刻查詢訂單詳情,如果讀請求被路由到了從庫,就可能讀到舊數據,造成一致性問題。在過去一年,公司內部就發生過 6 起因主從延遲導致的線上事故,幾乎全部由這種場景觸發。由于問題往往跨接口、跨服務,難以在代碼評審或測試階段提前發現,最終只能緊急切換為“強制讀主”兜底,恢復過程耗時且影響業務穩定。
為了監控和判斷主從延遲,MySQL 提供了一個常用指標:Seconds_Behind_Master。
Seconds_Behind_Master 的計算方式
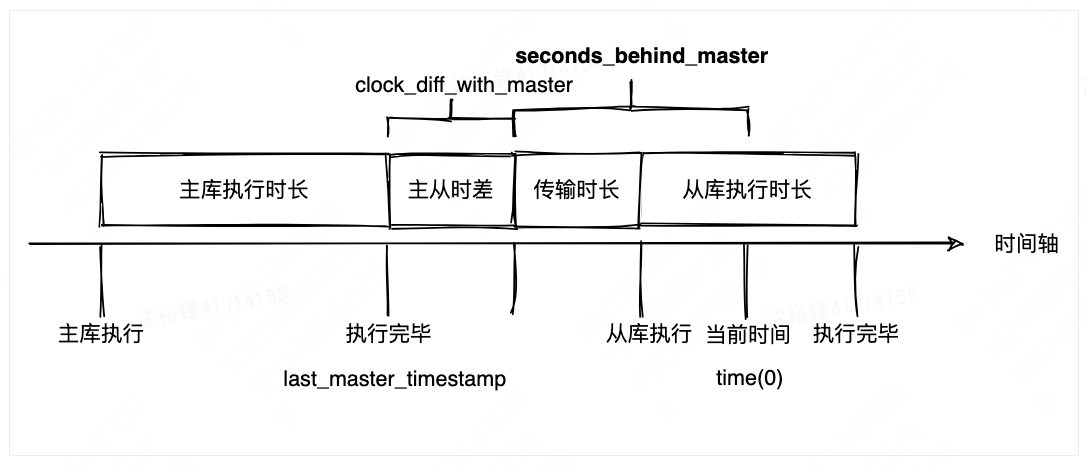
根據 MySQL 官方文檔與源碼,Seconds_Behind_Master 的計算公式如下:
Seconds_Behind_Master
= 從庫當前系統時間 (time(0))
- SQL 線程正在執行的 event 時間戳 (last_master_timestamp)
- 主從系統時間差 (clock_diff_with_master)
其中:
- last_master_timestamp:主庫 binlog event 的時間戳,隨復制傳到從庫。
- 如果
binlog_format=STATEMENT,則last_master_timestamp = 主庫開始執行的時間戳 + exec_time - 如果
binlog_format=ROW,則last_master_timestamp = 主庫開始執行的時間戳。
- 如果
- clock_diff_with_master:主從系統時間差,I/O 線程啟動時會在主庫執行
SELECT UNIX_TIMESTAMP()獲取,只計算一次,之后復用,直到 I/O 線程重啟。如果啟動后手動修改了服務器時間,這個差值不會更新,可能導致計算結果失真。 - time(0):從庫當前系統時間。
源碼中還定義了結果判定規則:
- SQL 與 I/O 線程均運行且空閑 → 延遲結果為
0。此時從庫已經把 relay log 中的事件全部回放完畢,I/O 線程又保持著和主庫的連接,因此從庫已經與主庫保持同步,沒有新的 event 需要應用,延遲自然為 0。 - SQL 線程未運行 → 延遲為
NULL。如果 SQL 線程沒有運行(例如被管理員手動STOP SLAVE SQL_THREAD,或因錯誤導致中止),那么從庫根本沒有在執行任何 event。此時返回數值型延遲沒有意義,因此直接返回 NULL 來提醒用戶“復制中斷”。 - SQL 線程空閑但 I/O 線程未運行 → 延遲為
NULL。這種情況下,SQL 線程雖然沒有待執行的 relay log(看起來像“追上了”),但 I/O 線程已經停止,不再從主庫獲取新的 binlog。這意味著復制鏈路實際上中斷了。如果繼續返回 0,會給人錯誤的印象,好像一切正常,所以 MySQL 設計為返回 NULL 來明確告警。 - 計算結果為負數 → 強制歸零。按照公式
Seconds_Behind_Master = time(0) - last_master_timestamp - clock_diff_with_master,如果主從時間不同步,或者事務時間戳落在未來(例如 binlog 被修改、系統時間漂移等),計算結果可能出現負數。但“延遲”為負數在邏輯上沒有意義,所以源碼中用max(0, time_diff)強制將其歸零,避免誤導。
局限性
雖然 Seconds_Behind_Master 在多數場景下能反映延遲情況,但在生產環境中,它仍存在明顯的局限。下面結合實際場景進行說明。
延遲為 0 并不代表沒有延遲
- 場景:在主從架構中,I/O 線程負責從主庫拉取 binlog 并寫入 relay log,SQL 線程再從 relay log 中讀取并回放。如果主從之間網絡較慢,I/O 線程就可能長期落后主庫,積壓大量尚未傳輸的 binlog。
- 表現:當 SQL 線程把 relay log 消費完時,
SHOW SLAVE STATUS會顯示Seconds_Behind_Master = 0,似乎表示“沒有延遲”。 - 實際情況:從庫雖然追上了 I/O 線程,但 I/O 線程本身離主庫最新的 binlog 可能還有幾十 MB,甚至幾分鐘的差距。換句話說,從庫與主庫之間仍存在顯著延遲,只是指標無法體現。
- 風險:業務層可能基于延遲值為 0 做出“主從一致”的判斷,結果讀到的數據卻仍是舊的,造成寫后讀不一致。
系統時間修改會導致失真
- 場景:在運維過程中,DBA 可能會因為時區調整、NTP 時間同步異常、手工校準等原因修改主庫或從庫的系統時間。
- 表現:
Seconds_Behind_Master的計算依賴于 binlog 事件的時間戳(來自主庫)和從庫當前的系統時間。一旦系統時間被修改,這兩者的對應關系就會被破壞,延遲值可能出現異常,甚至出現負數。 - 源碼處理:MySQL 為避免出現“負延遲”,源碼中使用
max(0, time_diff)強制將負數歸零。 - 結果:這會導致監控曲線突然出現“不合理的斷層”,讓運維人員無法正確評估延遲情況。
- 例子:主庫時間向前撥快 5 分鐘 → 從庫計算出的延遲會瞬間飆升;主庫時間向后撥慢 5 分鐘 → 從庫計算出的延遲可能變成負數,最后被歸零,看起來好像“沒有延遲”。
長事務導致延遲值波動
- 場景:主庫執行一個耗時數分鐘的大事務,例如大批量的
INSERT或UPDATE。 - 表現:在事務執行期間,binlog 中多個 event 的時間戳可能相同(通常是事務開始時的時間戳)。SQL 線程在從庫上回放這些 event 時,
Seconds_Behind_Master會不斷增大,因為從庫當前時間與事務開始時間的差值在拉大。一旦事務提交,從庫應用完成,延遲值瞬間歸零。 - 結果:監控曲線會出現典型的“逐漸升高 → 瞬間清零”的模式,容易被誤判為網絡抖動或系統故障。
- 例子:某個大事務從 10:00:00 開始,主庫執行 5 分鐘才提交。從庫在 10:04:59 時仍在執行該事務,延遲值可能顯示接近 300 秒;但到 10:05:00 一提交,延遲值直接歸零,看似“延遲消失”,實際卻只是事務執行完畢。
STATEMENT 與 ROW 格式差異
MySQL 的 binlog 格式有 STATEMENT 和 ROW,兩種模式下 Seconds_Behind_Master 的計算邏輯不同。
STATEMENT 格式:記錄的是 SQL 語句本身,例如:DELETE FROM t WHERE id=1。binlog 中會包含 exec_time 字段,表示該語句在主庫執行所花的時間。從庫計算 last_master_timestamp 時,會在主庫開始執行的時間戳上加上 exec_time。
- 結果:延遲值被“平滑”掉,實際延遲被低估。
- 例子:某條 DELETE 在主庫執行耗時 9 秒,從庫在 18 秒后才執行到這一 event。按理應該顯示 18 秒延遲,但由于公式減去了 9 秒,最終只顯示 9 秒。
ROW 格式:記錄的是行級變更數據,例如:Delete_rows event,而不是 SQL 語句。binlog 不包含 exec_time,所以從庫的延遲計算直接基于事務開始時間戳。
- 結果:延遲值更接近真實情況。
- 例子:同樣的事務,從庫在 24 秒后執行,延遲顯示 24 秒,與實際差距一致。
- 對比總結:在短事務場景下,兩種格式差異不大;在長事務或復雜 SQL 場景下,STATEMENT 模式會嚴重低估延遲值,ROW 模式更準確。
在 MySQL 的 binlog 里,不管是 STATEMENT 模式還是 ROW 模式,數據變更都會被寫成一條條 event。
event 就是 binlog 里的“記錄單元”,包含 header(時間戳、server_id、位置等)和 body(具體內容)。在 ROW 格式 下,binlog 記錄的是行級變更事件(如
Delete_rows event),這些事件不包含exec_time字段,所以Seconds_Behind_Master的計算完全依賴于事件 header 中的timestamp。對于一個事務來說,絕大多數 row events 的時間戳等于事務開始時刻,只有最后的XID_EVENT才標記提交時間。因此,在長事務場景下,延遲值會隨著事務執行逐漸升高,而在提交時瞬間歸零。
例子
STATEMENT 格式大事務案例
主庫執行語句
BEGIN;
INSERT INTO t_user (name, age)
VALUES ('Alice', 20), ('Bob', 25), ('Cathy', 30), ... 共 100 萬行;
COMMIT;
binlog 內容(STATEMENT 模式)
# at 100
# 250914 10:00:00 server id 1 end_log_pos 200 CRC32 0xaaaa
BEGIN# at 200
# 250914 10:00:00 server id 1 end_log_pos 300 CRC32 0xbbbb
# Query thread_id=11 exec_time=300 error_code=0
SET TIMESTAMP=1726298400/*!*/; -- 事務開始時間 (10:00:00)
INSERT INTO t_user (name, age)
VALUES ('Alice',20),('Bob',25),('Cathy',30), ... 共 100萬行
/*!*/;# at 5000
# 250914 10:05:00 server id 1 end_log_pos 5100 CRC32 0xcccc
Xid = 12345
COMMIT;
特點
-
exec_time=300秒,binlog 記錄了主庫執行這條 SQL 的耗時。 -
從庫在計算
last_master_timestamp時:last_master_timestamp = 10:00:00 + 300s = 10:05:00 -
所以在從庫回放時,不管過程多長,最終 SBM 顯示偏小(會被 exec_time 矯正)。
-
結果:真實延遲可能幾百秒,但 SBM 看起來更“溫和”。
ROW 格式大事務案例
主庫執行語句
BEGIN;
INSERT INTO t_user (name, age) VALUES ('Alice', 20);
INSERT INTO t_user (name, age) VALUES ('Bob', 25);
...
INSERT INTO t_user (name, age) VALUES ('User1000000', 99);
COMMIT;
binlog 內容(ROW 模式)
# at 100
# 250914 10:00:00 server id 1 end_log_pos 200 CRC32 0xaaaa
BEGIN# at 200
# 250914 10:00:00 server id 1 end_log_pos 250 CRC32 0xbbbb
### INSERT INTO `test`.`t_user`
### SET
### @1=1, @2='Alice', @3=20# at 250
# 250914 10:00:00 server id 1 end_log_pos 300 CRC32 0xcccc
### INSERT INTO `test`.`t_user`
### SET
### @1=2, @2='Bob', @3=25-- ... 中間還有 999,998 條 Write_rows_event ...
-- 注意:所有 row event 的時間戳都是 10:00:00# at 5000000
# 250914 10:05:00 server id 1 end_log_pos 5000100 CRC32 0xdddd
Xid = 12345
COMMIT;
特點
-
所有 row events 的時間戳都是事務 開始時的 10:00:00。
-
從庫 SQL 線程回放這些 row event 時:
-
在 10:04:59 還在執行 →
SBM = 10:04:59 - 10:00:00 = 299 秒 -
一旦遇到
XID_EVENT(10:05:00) →SBM = 10:05:00 - 10:05:00 = 0
-
-
結果:延遲曲線先逐漸升高,再在提交瞬間清零。
對比總結:
- STATEMENT:有
exec_time,SBM 往往被低估,延遲曲線更“平滑”。 - ROW:事件時間戳基本等于事務開始時間,延遲曲線會拉高再瞬間歸零,更容易表現出“抖動”。
總結
Seconds_Behind_Master 是 MySQL 提供的一個延遲指標,但其計算方式決定了它并不能完全反映真實延遲。在網絡抖動、系統時間漂移或長事務場景下,它可能顯示為 0 或出現異常波動;在 STATEMENT 格式下可能被低估,在 ROW 格式下更接近真實;
因此,在數據庫架構和業務邏輯設計中,不能單純依賴這一指標。線上常見做法是:借助 pt-heartbeat 或 MySQL 8.0 performance_schema 原生方案進行更可靠的延遲監控;或在業務層結合 插件化攔截、配置化強制讀主、長事務拆分 等措施,主動規避寫后讀不一致風險。
盡管 Seconds_Behind_Master 存在一定的局限性,但在大多數場景下,它依然能夠較為準確地反映主從復制的延遲情況。
參考
[1] MySQL自治平臺建設的內核原理及實踐
[2] Seconds_Behind_Master 的局限性及如何監控主從延遲
[3] MySQL 復制延遲 Seconds_Behind_Master 究竟是如何計算的
)



——2 環境搭建與入門)


)



支持能力評估)







