🐯貓頭虎薦研|騰訊開源長篇敘事音頻生成模型 AudioStory:統一模型,讓 AI 會講故事
大家好,我是貓頭虎 🐯🦉,又來給大家推薦新鮮出爐的 AI 開源項目!
這次要聊的是騰訊 ARC Lab 最近開源的一個相當炸裂的模型 —— AudioStory。
一句話總結:它能把文本、視頻,甚至已有音頻,變成 長篇、完整、有情緒、有邏輯的音頻故事。
👉 有聲小說、動畫配音、長音頻敘事,全都不在話下。
文章目錄
- 🐯貓頭虎薦研|騰訊開源長篇敘事音頻生成模型 **AudioStory**:統一模型,讓 AI 會講故事
- ? 為什么值得關注?
- 📖 它能做什么?
- 1?? 視頻配音(Video Dubbing)
- 2?? 文本轉長篇音頻(Text-to-Long Audio)
- 3?? 音頻續寫(Audio Continuation)
- 🧩 技術原理
- ?? 安裝與上手
- 📊 實驗結果
- 🔋 致謝與生態
- 🐯貓頭虎點評
? 為什么值得關注?
我們先來看看痛點。
傳統的 Text-to-Audio (TTA) 技術,的確能生成短音頻,但要做長篇敘事就會遇到三大難題:
- 場景割裂 —— 一會兒是森林,一會兒是都市,過渡生硬;
- 情緒漂移 —— 上一秒還在悲傷,下一秒突然變嗨,完全不連貫;
- 模塊割裂 —— 大多數方案要把理解、生成、后處理拆成好幾個流水線模塊,工程復雜,效果還經常對不上。
而 AudioStory 的厲害之處在于:
它是一個 統一模型,把 指令理解 + 音頻生成 + 跨場景一致性 全部揉在一起。
這意味著它不僅能生成自然過渡的敘事音頻,還能穩住整體基調和情感,效果遠超擴散模型或 LLM+擴散的組合。
研究團隊也拿出了數據:在 FD (Fréchet Distance) 和 FAD (Fréchet Audio Distance) 兩個關鍵指標上,AudioStory 的表現全面優于基線模型。
📖 它能做什么?
AudioStory 提供了三大核心能力:
1?? 視頻配音(Video Dubbing)
像 Tom & Jerry 這樣的動畫片,你只需要給出視覺字幕,AudioStory 就能自動生成擬聲和對白。
它還能跨域泛化,比如 Snoopy、哪吒、Donald Duck、熊出沒 風格全都能玩。
換句話說:你給它一個視頻,模型能自動加上“活靈活現的聲音軌”。
2?? 文本轉長篇音頻(Text-to-Long Audio)
和普通的 TTS 不一樣,它能把你的文本變成 完整的場景敘事。
示例指令:
生成一段完整音頻:Jake Shimabukuro 在錄音室彈奏復雜的尤克里里曲目,獲得掌聲,并在采訪中討論職業生涯。總時長 49.9 秒。
生成結果包含:演奏聲 🎶 + 環境聲 🌌 + 掌聲 👏 + 采訪 🎤 —— 全流程沉浸式敘事。
3?? 音頻續寫(Audio Continuation)
給定一段已有音頻,AudioStory 能理解上下文,并自然銜接后續。
例如:輸入一段籃球教練訓練的錄音,模型能生成教練繼續講解戰術的音頻。
就像 GPT 寫小說的續寫,但對象換成了音頻流。
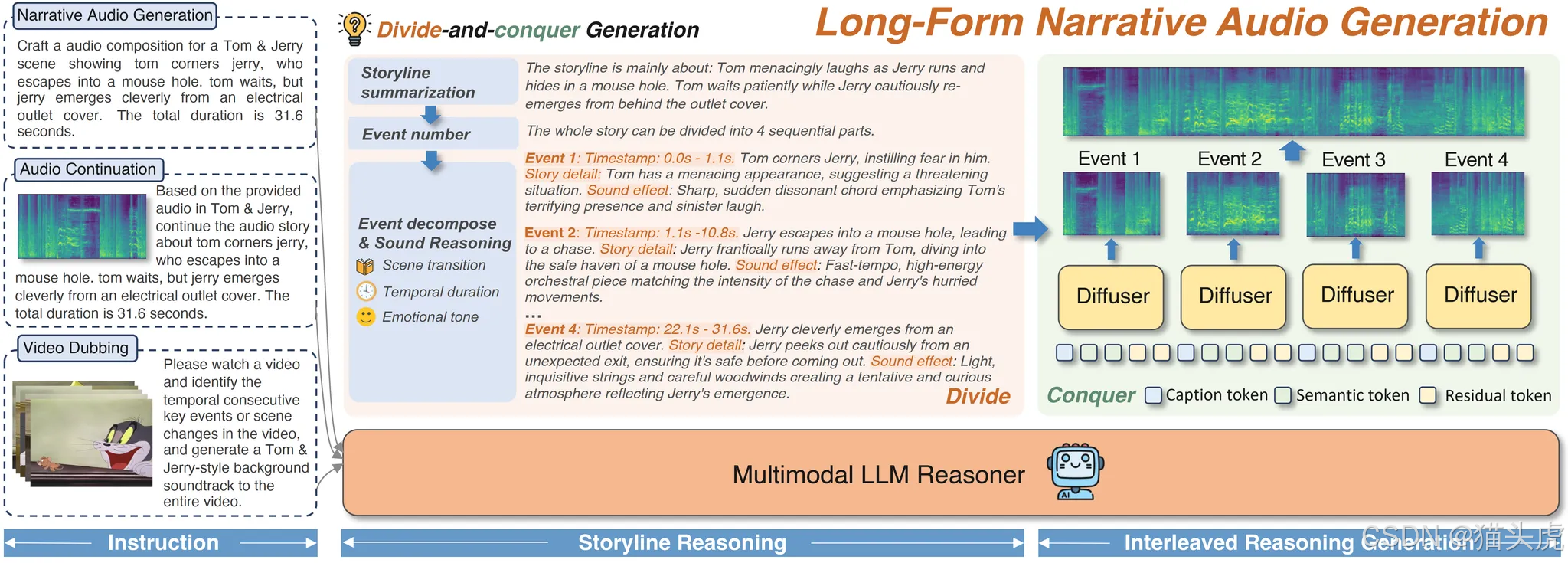
🧩 技術原理
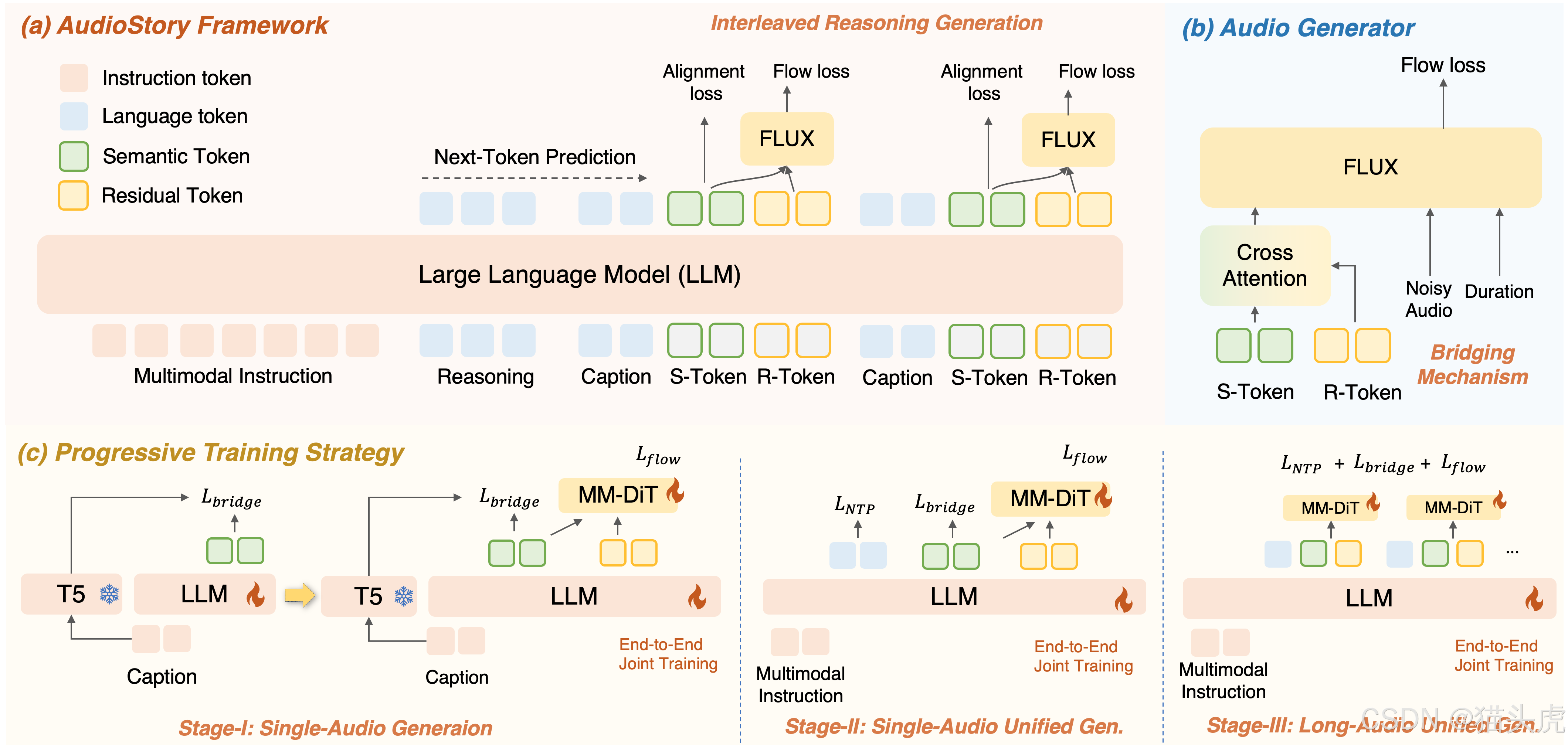
核心架構是一個 理解–生成統一框架:
-
輸入理解
- LLM 先對輸入(文本 / 音頻 / 視頻字幕)進行分析,拆解為有邏輯順序的 子事件。
-
推理生成
- 每個子事件由 LLM 生成 描述字幕 (captions)、語義 token 和 殘余 token;
- 這些 token 被送進 DiT(Diffusion Transformer),合成高保真音頻片段。
-
一致性機制
- Bridging Query:保持單場景內部的語義穩定;
- Consistency Query:確保跨場景的情感和敘事基調統一。
最終效果:情緒和過渡都自然得像真人配音師。
?? 安裝與上手
項目已開源在 GitHub,環境配置很友好:
git clone https://github.com/TencentARC/AudioStory.git
cd AudioStory
conda create -n audiostory python=3.10 -y
conda activate audiostory
bash install_audiostory.sh
推理示例:
python evaluate/inference.py \--model_path ckpt/audiostory-3B \--guidance 4.0 \--save_folder_name audiostory \--total_duration 50
依賴環境:
- Python >= 3.10
- PyTorch >= 2.1.0
- NVIDIA GPU + CUDA
📊 實驗結果
團隊在多任務測試中給出了硬指標:
- FD/FAD:明顯優于擴散模型和 LLM+擴散基線。
- 敘事一致性:在動畫配音和自然場景音頻中,人類聽感評測也顯著提升。
可以說,AudioStory 把長篇敘事音頻生成拉到了一個新高度。
🔋 致謝與生態
在持續噪聲去除器(continuous denoisers)構建上,AudioStory 參考了 SEED-X 和 TangoFlux 項目。
學術圈的相互借鑒與迭代,正推動整個 TTA 領域的飛速發展。
🐯貓頭虎點評
為什么我推薦大家關注 AudioStory?
- 場景落地感強 —— 有聲小說、播客、動畫后期、虛擬主播,馬上能用。
- 統一模型思路 —— 省去了多模塊拼接的麻煩,更簡潔也更穩健。
- 開源可玩性 —— 代碼+模型+Demo 全放出,研究者和開發者都能快速上手。
未來如果結合 多模態大模型(如視覺+音頻),再疊加 實時生成,那真的就是“AI 聲音導演”了。
👉 地址奉上:https://github.com/TencentARC/AudioStory
🐯 總結一句:
AudioStory = 讓 AI 不僅能說話,更能講故事。
從短音頻走向長篇敘事,這是 TTA 的關鍵突破,也可能是下一波“有聲內容產業”的催化劑。








】項目管理上:盈虧平衡分析與進度管理)










