01 概覽
隨著數字化轉型的來臨,企業對于數據服務的實時化需求日益增長,在大規模數據和復雜場景的情況下,Flink在實時計算數據鏈路中扮演著極為重要的角色,本文介紹了網盤如何通過 Flink 構建實時計算引擎,從而提供高性能、低延遲、穩定的實時計算能力。
02 百度網盤實時計算演進
2.1 百度網盤實時計算演進歷程
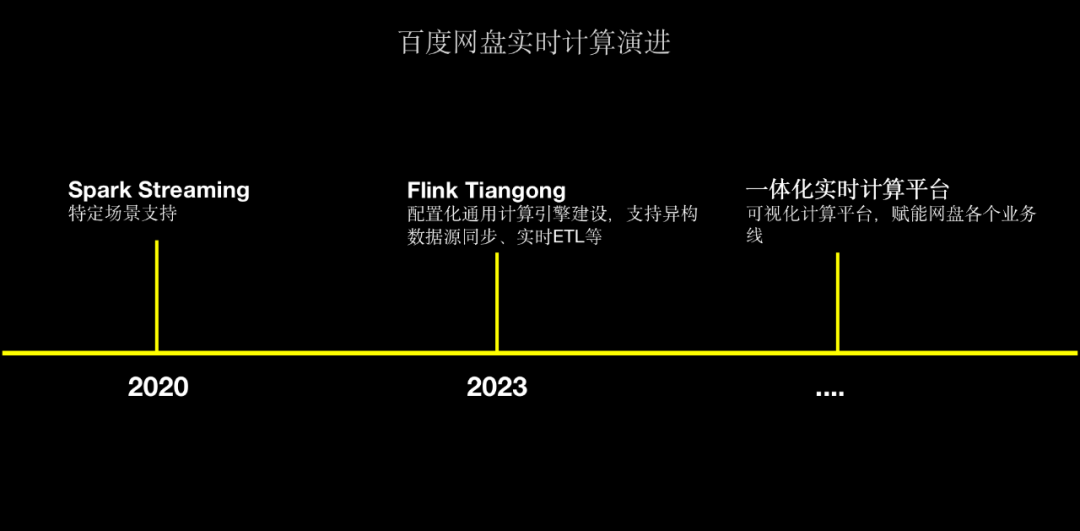
△百度網盤實時計算演進
在 2020 年,網盤主要通過Spark Streaming和Spark Structured Streaming來用于特定場景的支持,主要是在數據同步場景、實時清洗方面的應用。
為了解決Spark Streaming存在的監控告警薄弱、接入成本高、時效性低等問題,網盤于2023年初首次引入Flink實時計算引擎,并基于百度內部StreamCompute平臺快速建設集指標監控、告警、任務生命周期管理能力;經過調研測試我們發現Flink任務從0到1接入成本高、開發門檻高,因此,我們開始調研實時計算引擎的解決方案,目標是降低開發門檻、配置化任務接入,最終建設網盤內部的實時計算引擎Tiangong來為業務提供更好的支持。
截止至今,Tiangong計算引擎目前已在數據團隊、反作弊團隊、用戶增長等場景廣泛應用,并支持數百萬億的大流量場景。未來我們也計劃將基于Tiangong建設網盤一體化實時計算平臺,從而賦能網盤內部各個業務線實時計算能力建設。
2.2 為什么選擇Flink
網盤實時計算引擎從Spark Streaming和Spark Structured Streaming演進而來,為什么放棄Spark體系選擇Flink主要從以下幾個方面出發:
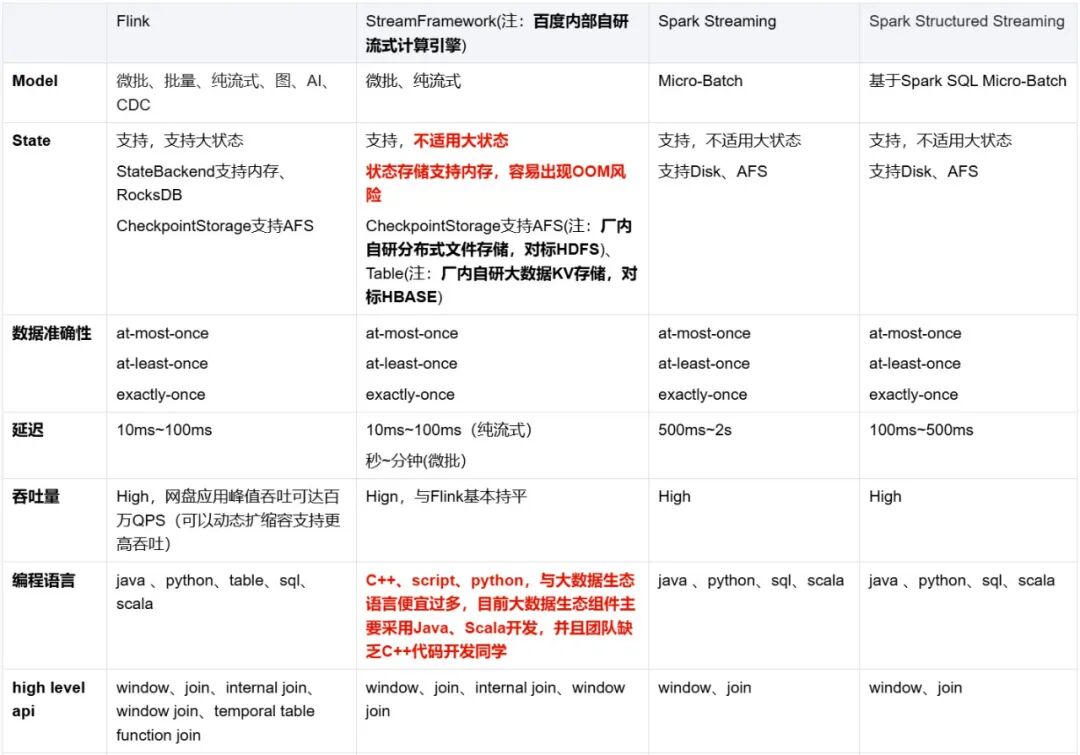
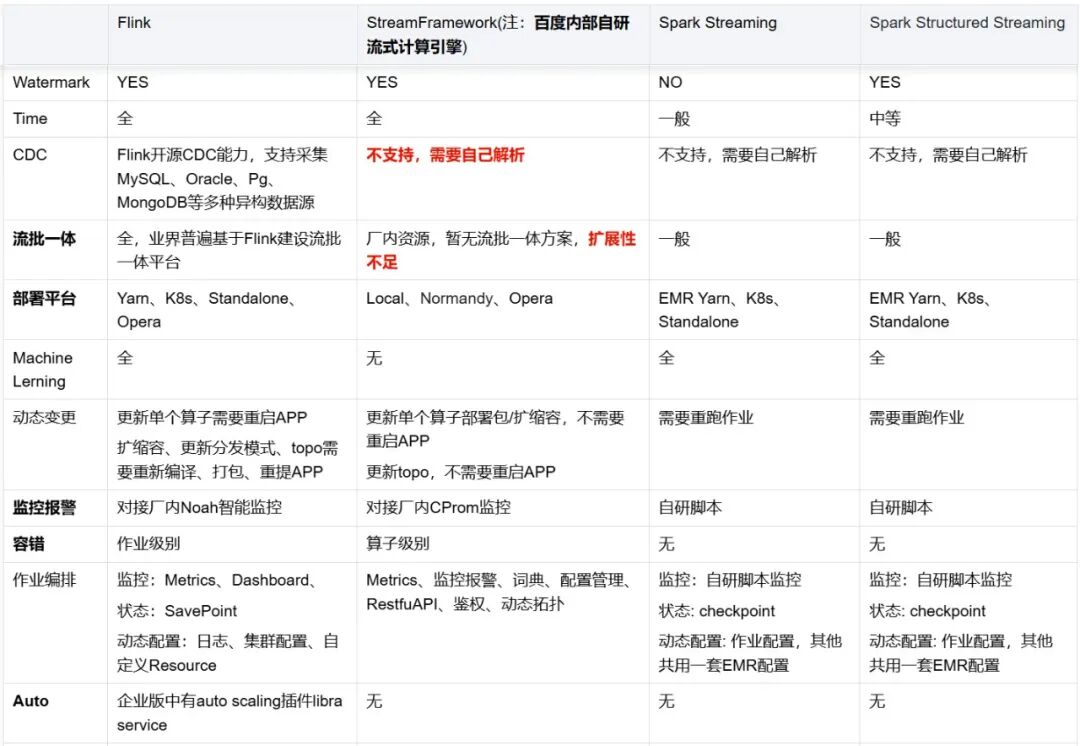

從百度內部實時計算RoadMap和狀態管理、流批一體、監控告警、任務管理、生態體系等各方面我們選擇基于Flink建設網盤內部的實時計算平臺。
2.3 實時計算引擎
2.3.1 實時計算引擎接入現狀
目前,百度網盤的Tiangong計算引擎已接入17+應用場景,高峰時作業處理的吞吐量達到千萬/s,而機器規模也已經達到了1500臺,資源5800CU,并且已經覆蓋用商策略、反作弊、主端一刻用增實時投放等多個場景。
2.3.2 Flink Tiangong引擎架構
如下圖所示的是網盤Tiangong實時計算引擎的架構。
-
最下層為Runtime層,負責Tiangong計算任務的部署方式,目前支持StreamCompute、Kubernetes、Yarn、Local等方式;
-
核心能力包括Source組件、Sink組件以及數據轉換引擎
-
Source組件:支持Db、Message Queue、BigData組件、自定義Source等多個異構數據源;
-
Sink組件:支持Db、Message Queue、BigData組件、自定義Sink等多個異構數據目的地;
-
數據轉換引擎:支持流批一體、自定義配置化數據清洗、精準一次數據處理、失敗容錯、IOC容器化管理、自定義SQL拓撲、靈活監控告警等能力;
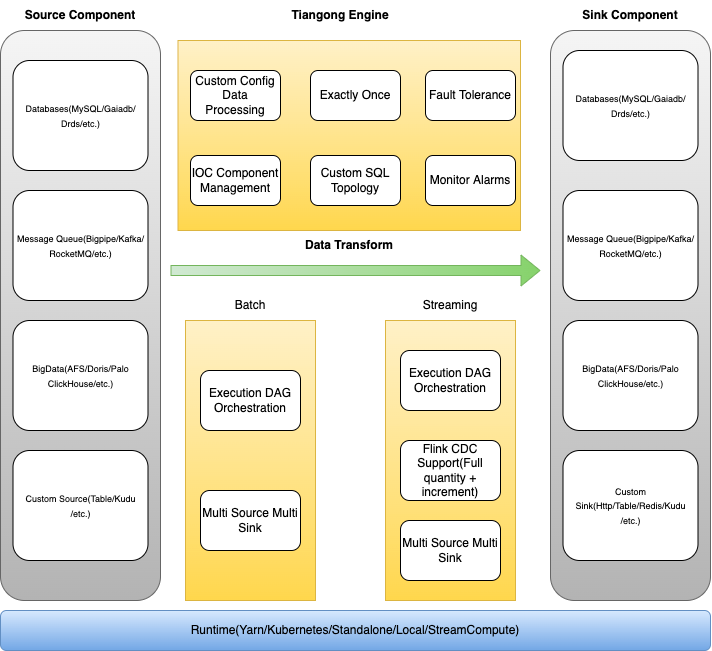
△ Tiangong計算引擎
從功能層面來看,Tiangong實時計算引擎主要包括作業管理和資源管理。其中,作業部分包括作業配置、作業上線以及作業生命周期管理三個方面的功能。
- 在作業配置方面,則包括運行環境配置、source配置、sink配置、清洗邏輯配置以及作業拓撲結構設置;
{"jobName": "作業名","env": {運行環境配置},"sources": [source端配置],"udfs": [用戶定義函數],"views": [清洗邏輯],"coreSql": [核心寫入邏輯],"sinks": [sink端配置],"customTopology": {自定義作業運行拓撲}
}
- 在作業發布方面,則包括作業啟動、取消以及刪除等;
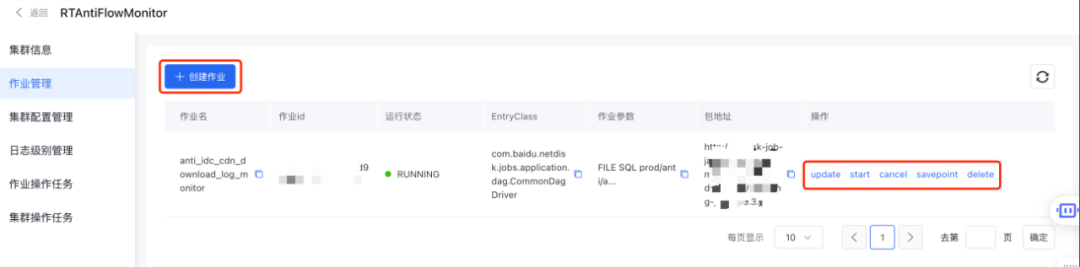
- 作業狀態則包括自定義規則告警、監控大盤等;
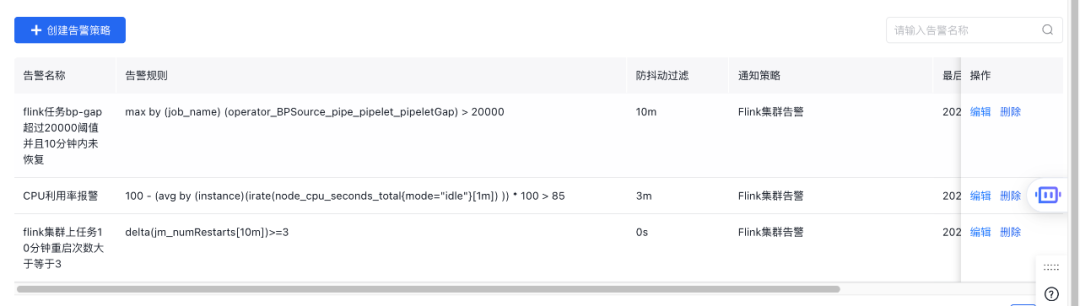
△ 自定義規則告警
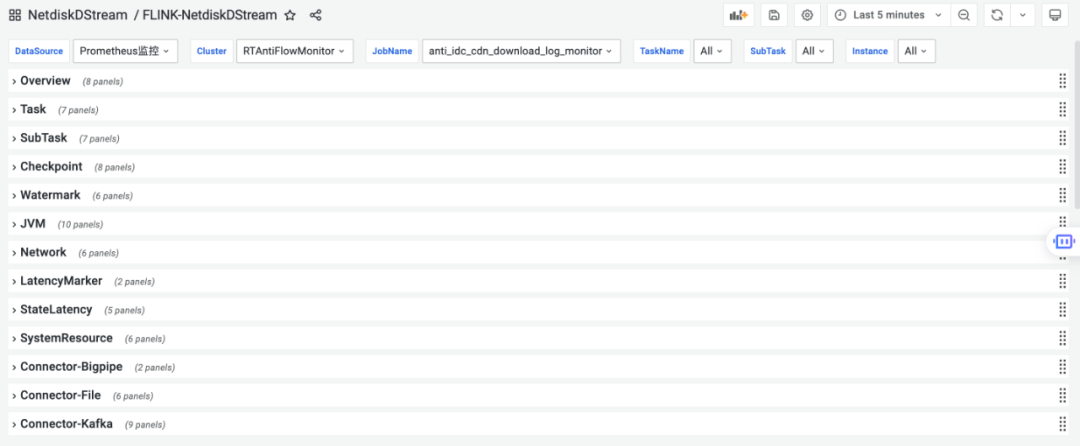
△ 監控大盤
- 在資源管理方面,利用StreamCompute平臺能力支持Flink集群動態擴縮容能力與灰度發布能力;
2.4 業務場景實踐
前面提到實時計算引擎演進過程和實時計算引擎對比,可以看出網盤實時計算引擎更多地會關注在易用性、穩定性和監控告警體系等方面,具體體現的應用場景主要涉及服務端日志、埋點日志、DB Binlog等場景的實時清洗計算。
2.4.1 網盤實時商業BI中心
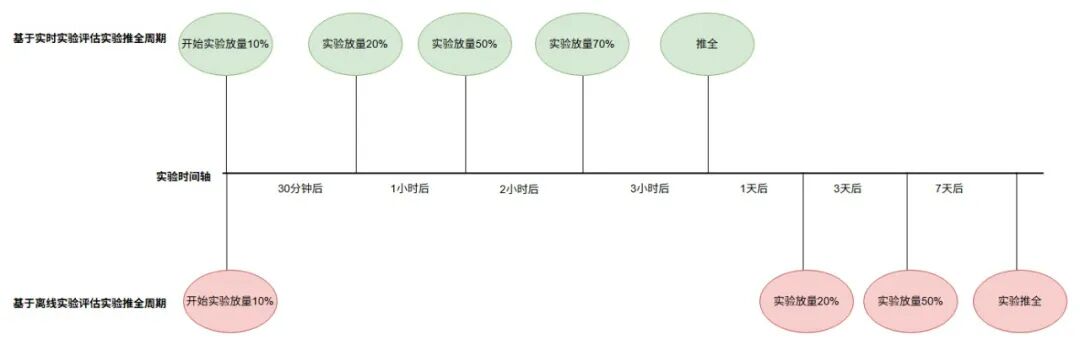
網盤現階段缺乏商業收入數據實時分析與商業策略實驗實時評估的能力,導致商業策略AB實驗推全鏈路往往需要經過周粒度才能完成,建設一套適用于網盤的實時商業BI中心有益于加快策略實驗迭代與實時商業流水波動分析,助力網盤整體收入增長;
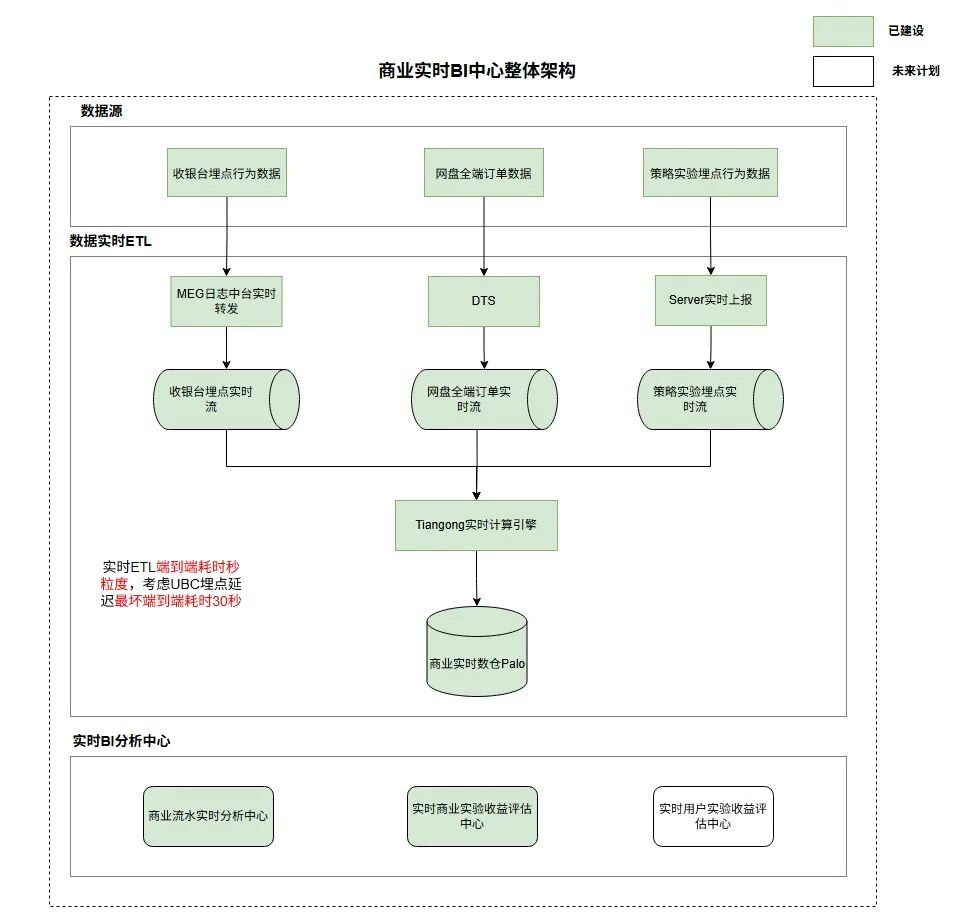
如上圖,通過將收銀臺行為、商業訂單、策略實驗埋點數據秒粒度接入至實時數倉Palo中后,配合數據可視化平臺Sugar建設商業實時BI中心,以此來助力商業策略、商業PM等各個角色快速完成AB實驗快速推全,將天粒度實驗收益評估機制優化至分鐘粒度,整體實驗推全鏈路由周粒度優化至天粒度;
2.4.1.1 Tiangong配置化接入
下述案例為Tiangong引擎配置化接入商業訂單實時流:
- 實時流數據源配置
{"sourceType": "bp_source","deserializerType": "STRING","sourceConfig": {"parallelism": 20,"operatorName": "xietong_strategy_businessorder_fr_bp_source","metaHost": "host:ip","cluster": "demo-cluster","username": "username","password": "password","pipeletName": "demo-pipelet-name","pipeletNum": "20","startingOffset": {},"startPoint": "LATEST","endOffset": {},"bpWebServiceAddress": "service_address"}- 核心處理邏輯配置
{"jobName": "netdisk_membership_order_deatils_bp2doris","env": {"streamConfigName": "20p_ck_3s_10fail_env", ## 環境配置,主要配置Checkpoint間隔和并行度,根據數據量定義,一般為上游消息隊列分區倍數"tableConfig": {}},"sources": [{"configType": "CONFIG","sourceTableName":"membership_order_binlog", ## 數據源配置,bigpipei訂單實時流"sourceConfig": "prod/netdisk_membership_order_bp_source"},{"configType": "SQL","sourceConfig": "CREATE TABLE ods_order_info_rt ## 寫入目的地配置,palo寫入表(id bigint,order_no string,user_id bigint,dev_uid bigint,app_id bigint,client_channel tinyint,pay_channel tinyint,product_id string,.... ) WITH ('connector' = 'doris','fenodes' = 'host:ip','table.identifier' = 'dbName:tableName','username' = 'username','password' = 'password','sink.properties.format' = 'json','sink.properties.read_json_by_line' = 'true','sink.label-prefix' = 'label-prefix','sink.enable-2pc'='true','sink.parallelism' = '1')"}],"views": [{"name": "binlog_filter_view", ## 核心數據處理邏輯,純SQL接入"sql": "select CAST(JSON_VALUE(new_values, '$.id') as bigint) as id,JSON_VALUE(new_values, '$.business_no') as business_no,JSON_VALUE(new_values, '$.order_no') as order_no,UNIX_TIMESTAMP() as write_timestamp,.....FROM membership_order_binlog,LATERAL TABLE(BINLOG_NEWVALUES_FILTER(f0))" ## 系統內置Binlog清洗TableFunction}],"coreSql": "insert into ods_order_info_rt select id, ## 寫入下游palo表,寫入間隔為Checkpoint間隔,上述配置為3秒,每3秒寫一批business_no,order_no,user_id,write_timestamp from binlog_filter_view"
}2.4.1.2 可視化監控體系
Flink作業UI監控
Grafana監控大盤
實時任務監控配置
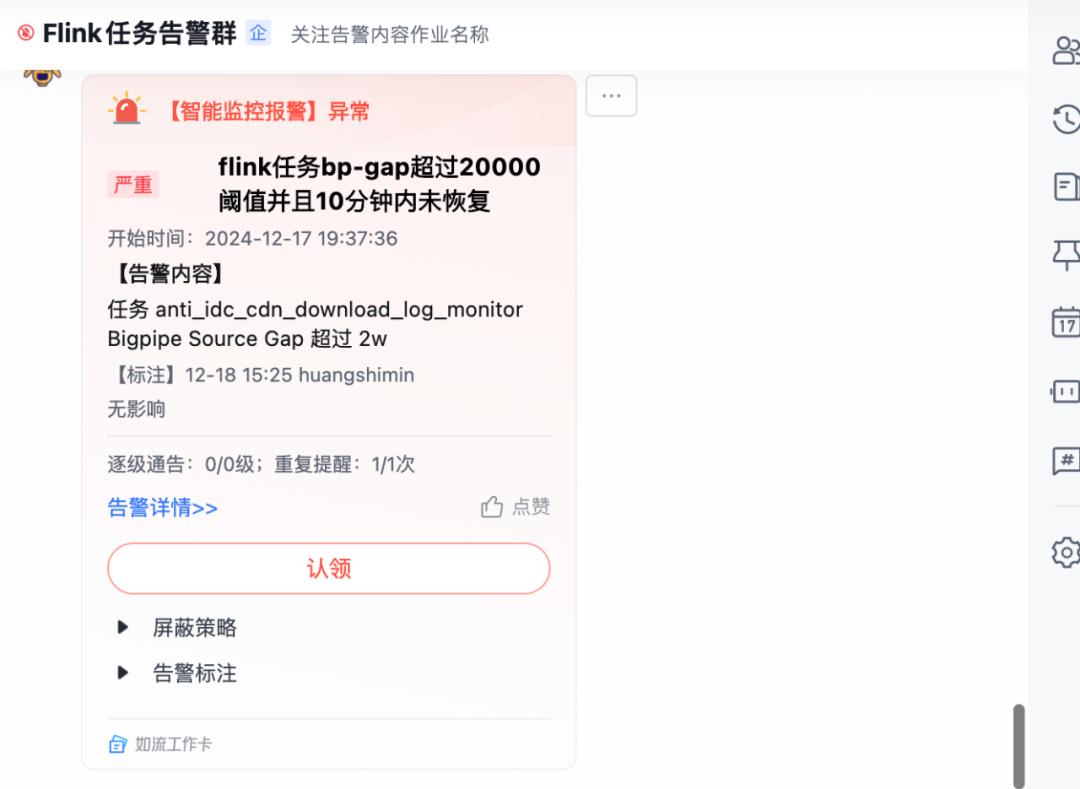
2.4.2 用戶商業策略實時特征
基于商業策略實時核心行為相關特征依賴場景,結合核心行為以及用戶付費埋點行為數據建設從0點實時累計特征與基于滾動窗口的近X分鐘實時特征有助力策略側對用戶剛需需求的感知,并結合用戶剛需行為個性化出價以此促進整體商業收入。
2.4.2.1 核心方案
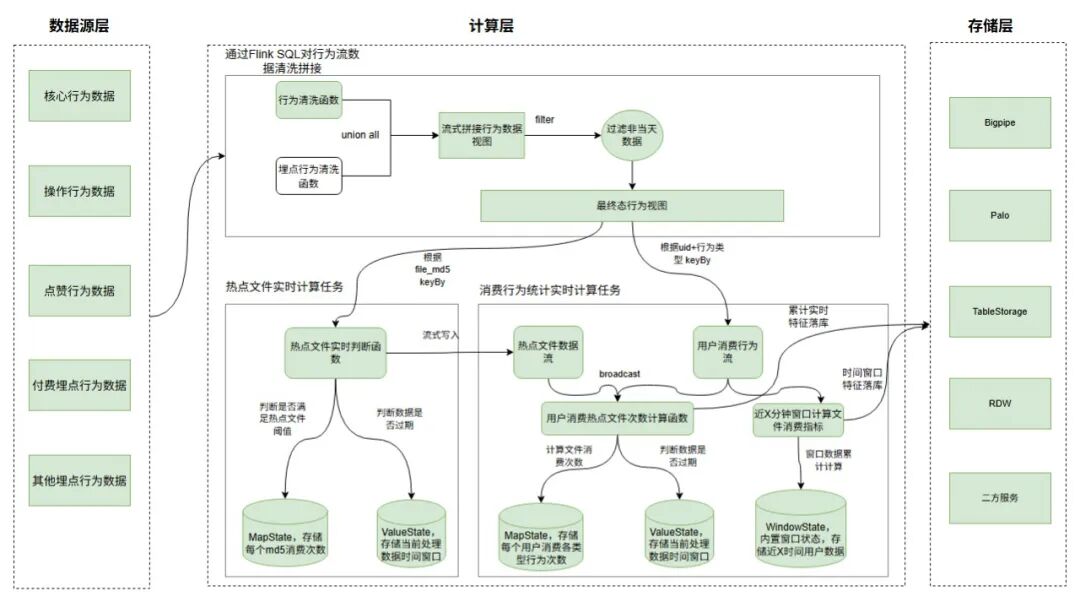
-
如上圖,方案二主要將數據流拆為三塊,如流數據拼接、熱點文件計算、消費行為統計;
-
流數據拼接:利用Tiangong計算引擎,通過Flink SQL+行為清洗UDF函數,將各類行為數據打平為統一格式,并通過union all進行聚合,過濾異常數據后行為行為視圖,數據流式產出。
-
熱點文件計算:實時將各個file_md5的消費次數存儲Flink Map狀態中,并根據離線分析得到的熱點文件消費閾值判斷熱點文件,將熱點文件流式寫入Bigpipe與Palo中,數據流式產出,最優可做到毫秒級;
-
消費行為次數計算:根據熱點文件數據流關聯用戶消費行為,實時對用戶消費的文件進行熱點/普通歸一化處理,后續將每個用戶消費不同行為類型的熱點/普調次數寫入Flink Map狀態中,累加計算從0點至今的文件消費次數,實時寫入Doris和Palo中,最優可做到秒級;
2.4.2.2 技術難點
(1)大狀態問題
問題引入
-
熱點文件和用戶消費文件次數的計算,都涉及到數據累計的問題,如果將數據存儲在共享存儲(例如Redis/Table)這類kv存儲中,每條數據或每個窗口的數據都需要先查一下上次的計算結果,累加后再寫入共享存儲中,這從而導致每次計算多一次網絡讀IO操作,故利用Flink狀態機制,將熱點文件和用戶消費次數存儲在Flink狀態中,每次判斷都在TaskManger本地或者內存中,不涉及到網絡IO操作,故性能更好。
-
數據都存入Flink狀態中也導致Flink存在大狀態問題,從而導致Checkpoint耗時過大從而引起任務背壓,最終導致數據處理延遲等問題。
解決方案
狀態后端優化
-
選擇Rocksdb作為狀態后端,開啟增量Checkpoint
-
配置changelog狀態機制,防止Rocksdb定期Compaction導致的Checkpoint耗時久問題
-
調整rocksdb manged內存大小、rocksdb write buffer大小
快照存儲優化
- 開啟快照壓縮配置
狀態TTL機制
- 長期為更新的狀態做小時粒度更新,防止狀態持續增大。
(2)TableStroage寫入性能差
問題引入
- 因廠內Table API創建Table Client過程中需要根據特定表對應的機器數創建對應個數的brpc-client-work-thread、brpc-client-io-thread、fairStrategy-timer-thread等線程,共計3*機器數個,網盤特征Table存儲底層表占用200臺機器,故創建一個Table Client需要創建600+線程,從而導致Flink計算節點的底層martix容器線程超限,經過和StreamCompute同學溝通需限制Table Client的Rpc線程數為1,并對應Flink集群的計算節點容器最大線程數由1000->1500,從而解決線程超限問題。但因限制Table Client Rpc線程為1導致Table整體寫入性能偏差。
解決方案
- 細粒度拆分任務,首先對用戶各類行為以及消費的熱點/普調資源進行實時計算,后續根據user_id+行為類型keyby,并開3s窗口,取最新的數據落入Table,將3s一個窗口的數據進行壓縮。
優化效果
- 原本天粒度寫入48億+次行為特征優化為2億+次,具體效果如下圖:

業務場景大致可以分為實時數倉、實時數據復雜聚合計算、DB業務數據CDC等場景,在這幾個場景Flink本身就提供高性能、高穩定性的能力,再配合網盤Tiangong實時計算引擎不熟悉Flink的業務方也可以配置化、低代碼的方式快速建設起實時應用。
03 Flink技術挑戰和解決方案
3.1 Flink底座建設

△ Flink基建建設
基于StreamCompute平臺提供的動態擴縮容、任務生命周期管理、Flink多版本管理、云原生監控告警體系等能力,來快速構建網盤Flink實時計算能力。
3.2 實時計算平臺建設

△ Tiangong計算引擎
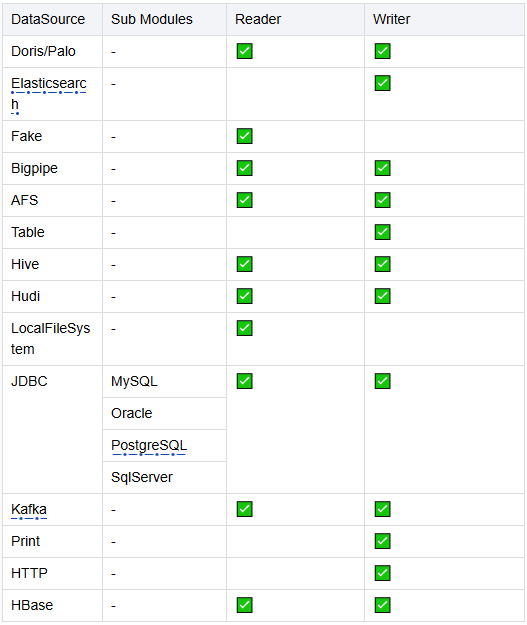
以上為Tiangong計算引擎能力支持,其作為網盤實時計算平臺支持目前廠內大部分異構數據源,使用方可以通過簡單的配置快速建設實時計算能力,拿上述業務場景實踐中的用戶商業策略實時特征項目接入Tiangong來看,只需下述配置和少量窗口數據聚合邏輯開發即可:
{"jobName": "business_feature_compute_bp2table", // 作業名"env": { // 作業運行環境配置"streamConfigName": "300p_ck_30s_5fail_env","tableConfig": {"stateTtlMs": 600000}},"sources": [ // source配置,download日志{"configType": "CONFIG","sourceTableName": "idc_log_source","sourceConfig": "prod/business_strategy_idc_bp_source"}],"udfs":[ // 數據清洗轉換邏輯,SQL無法完成時通過UDF{"name": "idc_log_filter_func","className": "com.baidu.xxx.IdcLogFilterFunction"},{"name": "idc_feature_transform_func","className": "com.baidu.xxx.IdcFeatureTransformFunction"}],"views": [{"name": "idc_log_feature_view","sql": "select feature_data.event_time as event_time,.....from (select idc_feature_transform_func(f0) as feature_datafrom idc_log_sourcewhere idc_log_filter_func(f0) = true) as tmpwhere feature_data.log_time <> '0' and ....}],"sinks": [ // 雙寫TableStorage、Doris{"sinkConfigNames": ["prod/netdisk_strategy_idc_feature_mi_table_sink","prod/netdisk_strategy_feature_doris_sink"],"transformSQL": "select event_time,.....from idc_log_feature_view","watermarkConfig":{ // 涉及開窗邏輯所涉及的watermark配置"maxOutOfOrdernessMs": 5000,"idlenessMs": 10000,"timeAssignerFunctionName": "row_event_time_assigner"},// 開窗計算邏輯函數"rowTransformFunc": "strategyFeatureTransformFunction"}]}
}3.3 自定義作業執行計劃
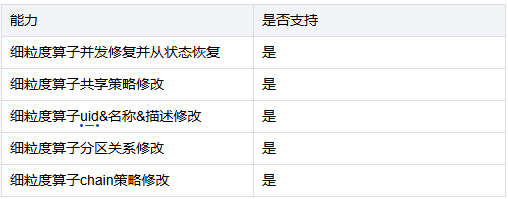
3.3.1 細粒度算子并行度優化
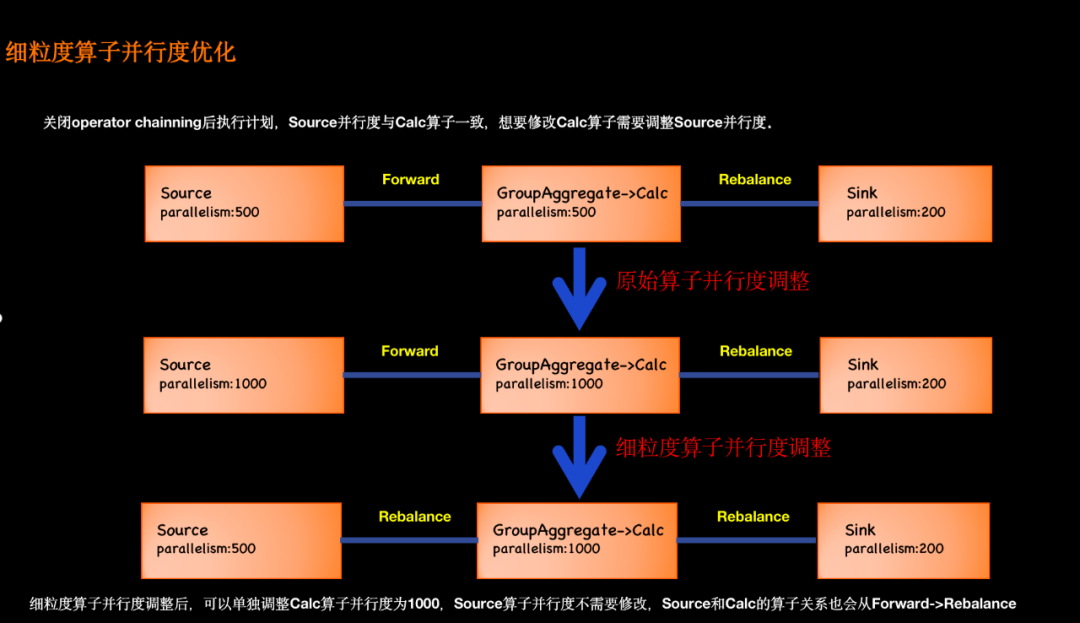
△ 細粒度算子并行度優化
Tiangong計算引擎本質基于Flink SQL+Table API+DataStream API做的混合計算引擎,其本質相當于Flink SQL,因此一旦定義好Source和Sink并行度后,其任務所涉及的計算、清洗、聚合等算子都與Source端并行度一致,從而導致如果想要增加清洗等算子的并行度需要把Source的并行度也增加,從而造成資源浪費、性能降低等問題。
3.3.2 分區關系優化
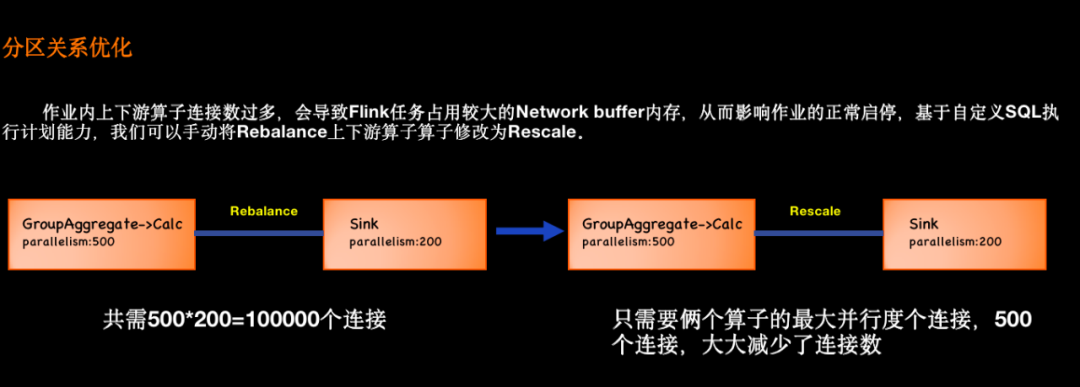
△ 分區關系優化
作業內上下游算子連接數過多,會占用較大的 Network buffer 內存,從而影響作業的正常啟停,基于自定義SQL執行計劃能力,我們可以手動將 Rebalance 邊修改為 Rescale。
比如上圖的示例,左邊上游算子有 500 個并發,而下游的 Sink 算子只有 200 個并發。在這種場景下,Flink SQL 會默認生成 Rebalance 的連接方式,共需 500*200,共 10 萬個邏輯連接。
通過自定義SQL執行計劃能力,我們手動將 Rebalance 設置為 Rescale 后,它只需要 500 個連接,大大降低了 Network buffer 的內存需求。
3.3.3 資源共享策略優化
3.3.3.1 資源共享
-
默認情況下,flink允許subtask共享slot,即使是不同task的subtask,這樣的結果是一個slot可以保存作業的整個管道。
-
如果是同一步操作的并行subtask需要放到不同的slot,如果是先后發生的不同的subtask可以放在同一個slot中,實現slot的共享。
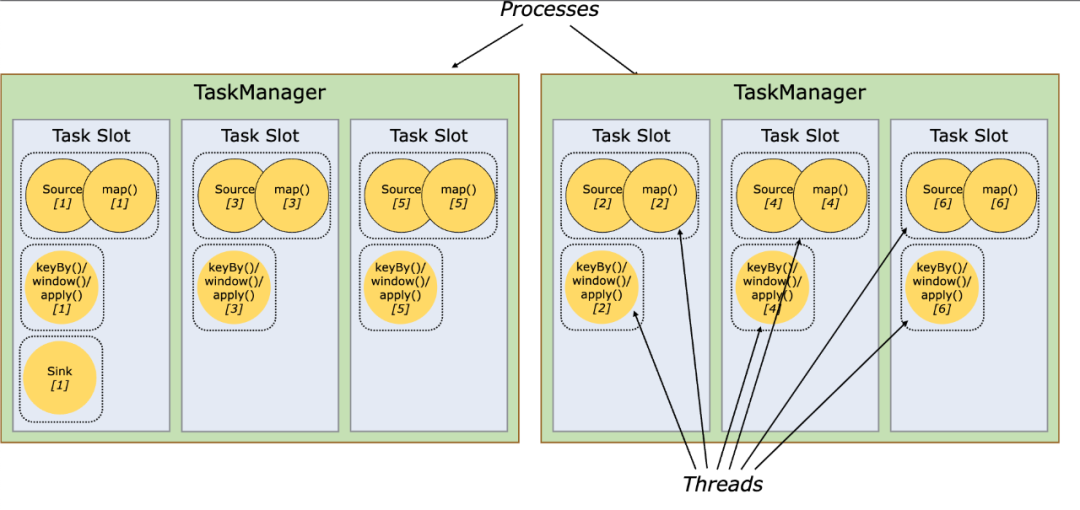
△ Slot與Task的關系
3.3.3.2 自定義共享策略
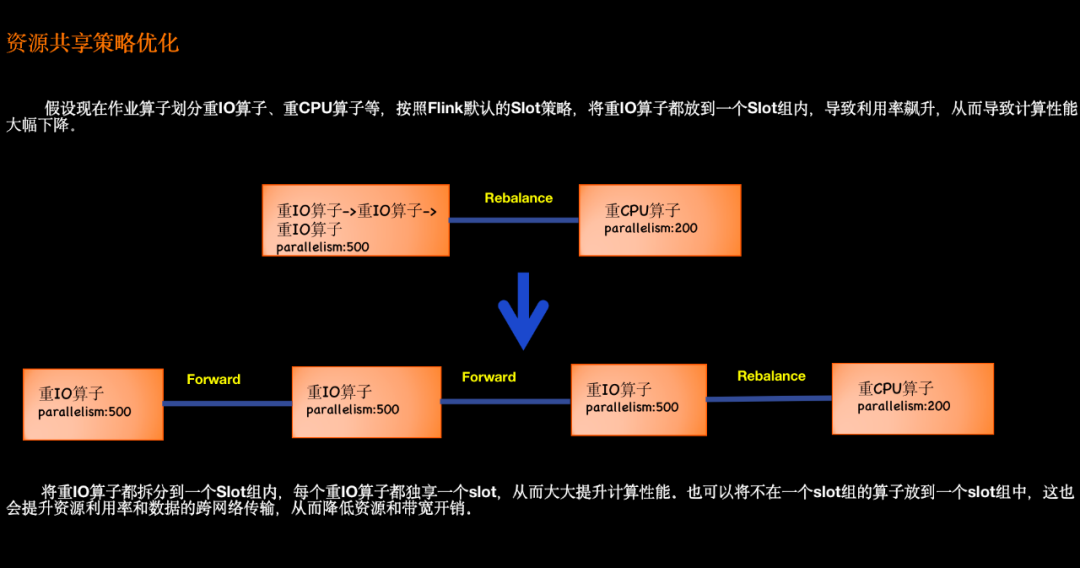
△ 資源共享策略優化
支持按照算子類型將算子劃分到一個slot group中,從而來減少數據的跨網絡傳輸、提升資源利用率以及提升計算性能等。
3.3.4 算子名稱優化
Flink SQL不支持為每個算子自定義名稱,從而導致算子名是根據系統規則來生成的,從而導致算子名稱不能夠通俗的表示其具體含義。為了便于作業維護和管理,自定義作業執行計劃支持算子名稱優化。
04 未來展望
△ 未來展望
4.1 實時計算平臺化
目前Tiangong計算引擎的使用方式主要在公共代碼庫提交任務配置和UDF代碼的方式接入,使用方需要擁有Tiangong計算引擎的代碼庫權限,存在代碼安全和任務隔離性差等問題,后續我們計劃基于Tiangong計算引擎搭建網盤自己的實時化計算平臺,實現頁面低代碼方式快速接入實時任務。
4.2 實時DTS平臺
目前網盤主要使用廠內DTS平臺,通過增量binlog和全量select快照方式采集數據至下游AFS,整體鏈路為DTS->AFS->UDW,一旦上游表格式變化下游的采集任務就會失敗,因此整體穩定性、維護成本和性能都過差。因此我們計劃基于Tiangong計算引擎構建實時DTS平臺,具體架構如下:
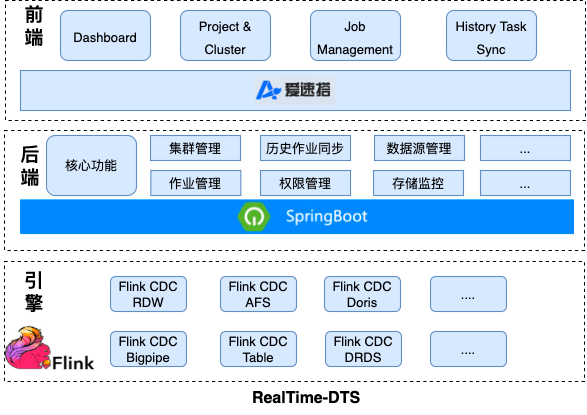
△ RealTime-DTS架構


】項目管理上:盈虧平衡分析與進度管理)













—— Fuzz模糊測試口令爆破目錄爆破參數爆破Payload爆破)

)
