記錄測試環境hertzbeat壓測cpu高,oom問題排查。jvm,mat,visulavm
一,問題背景
運維平臺,采用hertzbeat開源代碼進行采集。對單個設備連接,采集9個指標。目前hertzbeat對1個設備連接,下發9次單獨采集并獲取采集結果,存放到tsdb數據庫。測試環境進行壓測,造500個設備,hertzbeat共計500個采集任務,運行一天后,hertzbeat web頁面采集任務宕機約300+,且正常狀態的采集任務,查看采集詳情,只有實時數據,沒有歷史數據。(將查詢時間擴大到1天,則發現歷史數據只在20多分鐘的時間段內才有)。
問題整理:
1.hertzbeat任務運行一天后存在宕機
2.hertzbeat任務歷史采集數據無法查看
3.hertzbeat服務cpu在200+
4.運維服務oom
本文討論1,2,3問題。第4問題不做討論。
其中問題,1,3是同一種。2單獨。
涉及的核心服務:
運維服務,hertzbeat服務,kafka,模擬設備,emqx,tsdb時序數據庫(存放采集數據的歷史記錄)
服務部署信息和版本信息
k8s部署
hertzbeat 分支: 1.6.1
emqx版本 5.7.1
mqtt協議:5.0
核心服務配置:
hertzbeat服務,最大堆15g
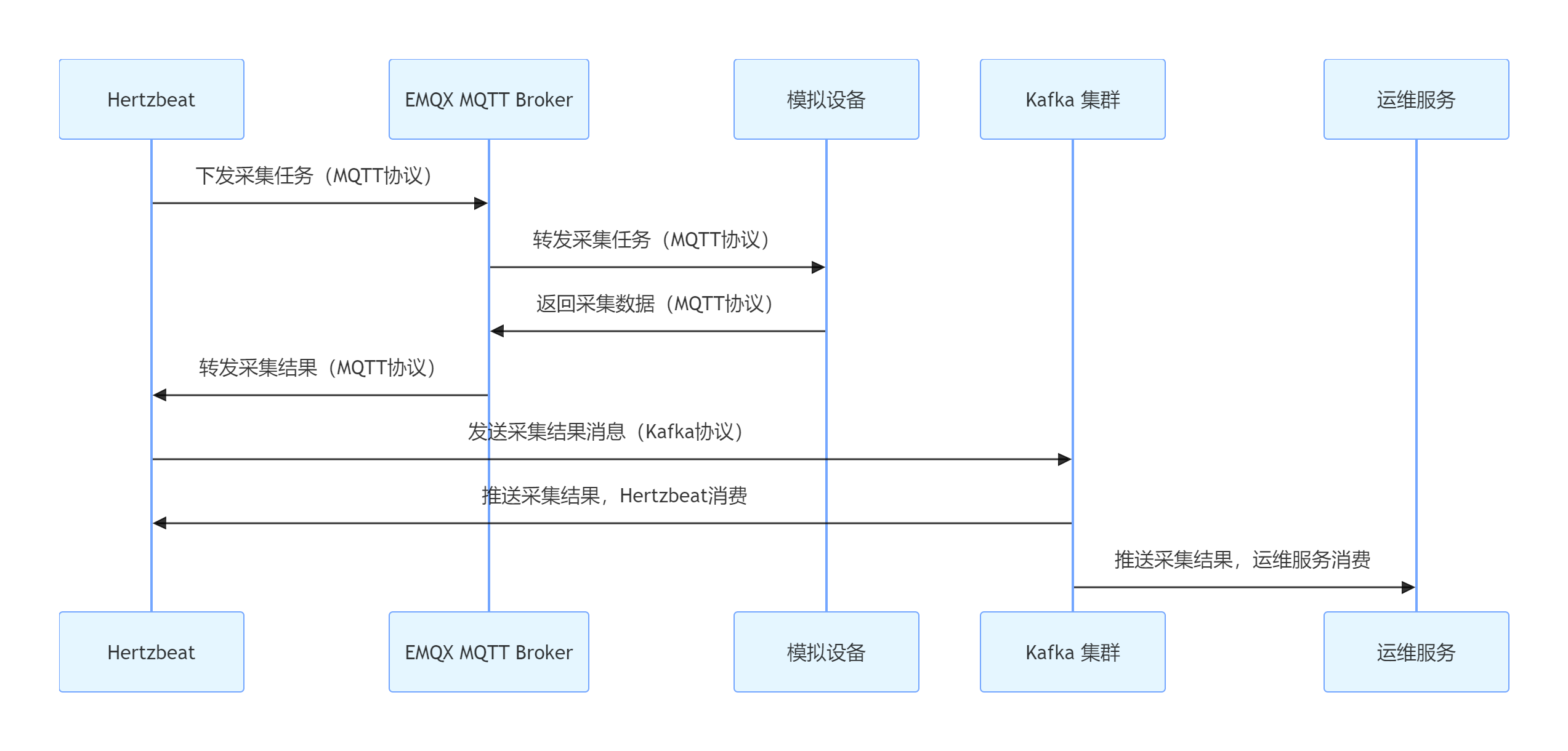
采集流程:
hertzbeat 通過mqtt協議下發采集任務,模擬設備收到消息后,返回采集數據(mqtt協議消息都通過emqx broker轉發),hertzbeat收到采集結果后,通過kafka發送采集結果消息,然后hertzbeat和運維服務消費這個消息。
流程圖如下:
二,使用工具
k8s:部署服務的部署平臺
VisulaVm:堆,線程分析工具
MAT:內存泄漏分析工具
豆包:工具人
MAT下載地址:
https://blog.csdn.net/wutrg1502/article/details/132315468
三,排查問題2,hertzbeat采集歷史數據無法查看。
排查思路:
hertzbeat采集數據收到后由kafka發送后,hertzbeat消費,然后寫入tsdb數據庫。
已知模擬器不停在上報。
檢查點:
kafaka消息是否有積壓情況。
tsdb是否有歷史數據。
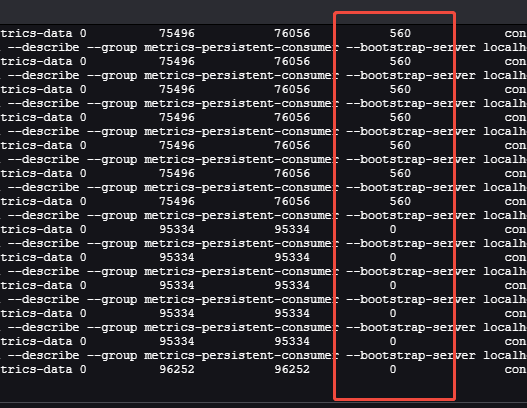
kafka看是否消息積壓:
進入k8s的kafka容器,cd bin
然后執行:
查看消費組:./kafka-consumer-groups.sh --list --bootstrap-server localhost:9092
看 hertzbeat消費./kafka-consumer-groups.sh --describe --group xxt-consumer --bootstrap-server localhost:9092 | grep xxtopic
數字分別為:已消費,總數,待消費(這個圖是修復后,修復前有大量消息積壓。也就解釋了為什么tsdb數據庫沒有歷史數據寫入。)
如何找到寫入tsdb數據庫代碼:
直接停止tsdb數據庫服務,看hertzbeat報錯日志,根據調用棧找到代碼。
原因是,hertzbeat將指標拆成多個小的循環進行調用并存儲到tsdb數據庫。將單條處理為批量調用:
List<CollectRep.Field> fields = metricsData.getFieldsList();Long[] timestamp = new Long[]{metricsData.getTime()};Map<String, Double> fieldsValue = new HashMap<>(fields.size());Map<String, String> labels = new HashMap<>(fields.size());StringBuilder batchPayload = new StringBuilder();int qty = 0;for (CollectRep.ValueRow valueRow : metricsData.getValuesList()) {fieldsValue.clear();labels.clear();for (int index = 0; index < fields.size(); index++) {CollectRep.Field field = fields.get(index);String value = valueRow.getColumns(index);if (field.getType() == CommonConstants.TYPE_NUMBER && !field.getLabel()) {// number metrics dataif (!CommonConstants.NULL_VALUE.equals(value)) {fieldsValue.put(field.getName(), CommonUtil.parseStrDouble(value));}}// labelif (field.getLabel() && !CommonConstants.NULL_VALUE.equals(value)) {labels.put(field.getName(), value);}}for (Map.Entry<String, Double> entry : fieldsValue.entrySet()) {if (entry.getKey() != null && entry.getValue() != null) {try {labels.putAll(defaultLabels);String labelName = isPrometheusAuto ? metricsData.getMetrics() : metricsData.getMetrics() + SPILT + entry.getKey();labels.put(LABEL_KEY_NAME, labelName);labels.put(MONITOR_METRIC_KEY, entry.getKey());VictoriaMetricsContent content = VictoriaMetricsContent.builder().metric(labels).values(new Double[]{entry.getValue()}).timestamps(timestamp).build();batchPayload.append(JsonUtil.toJson(content)).append("\n");qty = qty + 1;} catch (Exception e) {log.error("flush metrics data to victoria-metrics error: {}.", e.getMessage(), e);}}}}if (qty > 0){sendBatchData(batchPayload);}}
三,排查問題1,3,hertzbeat采集任務宕機和cpu高問題
生成堆,線程dump文件
進入hertzbeat容器,生成堆,線程的dump文件
命令:
1 和22 是容器中java的進程id
如何查看:
jps -v
生成線程堆棧
jstack 1 > /home/app/logs/thread_dump_$(date +%Y%m%d%H%M%S).txtjstack 1 > /home/app/logs/thread_dump_$(date +%Y%m%d%H%M%S).tdump生成堆棧
jmap -dump:format=b,file=/home/app/logs/heap_dump_$(date +%Y%m%d%H%M%S).hprof 1jstack 22 > /home/app/logs/hert_thread_dump_$(date +%Y%m%d%H%M%S).tdump
jmap -dump:format=b,file=/home/app/logs/hert_heap_dump_$(date +%Y%m%d%H%M%S).hprof 21注意,要重啟pod前先將轉儲的文件拷貝到本地電腦。
快速試錯
重啟hertzbeat服務。重啟后發現原本宕機的采集任務,恢復上線。
推測是hertzbeat服務性能問題導致采集任務宕機。
信息可視化
連接visulaVm
因為是測試環境,可以使用visulaVm對hertzbeat服務做一個堆,線程監控。本地windows安裝visulaVm后連接遠程服務。
具體連接操作為:(待完善,k8s管理的服務,開通jconsle連接端口)
連接好后如圖:
本次處理中關注的關鍵信息:
Uptime: jvm運行時長
Heap/metaspace:堆信息/元空間
Threads:線程創建和銷毀信息
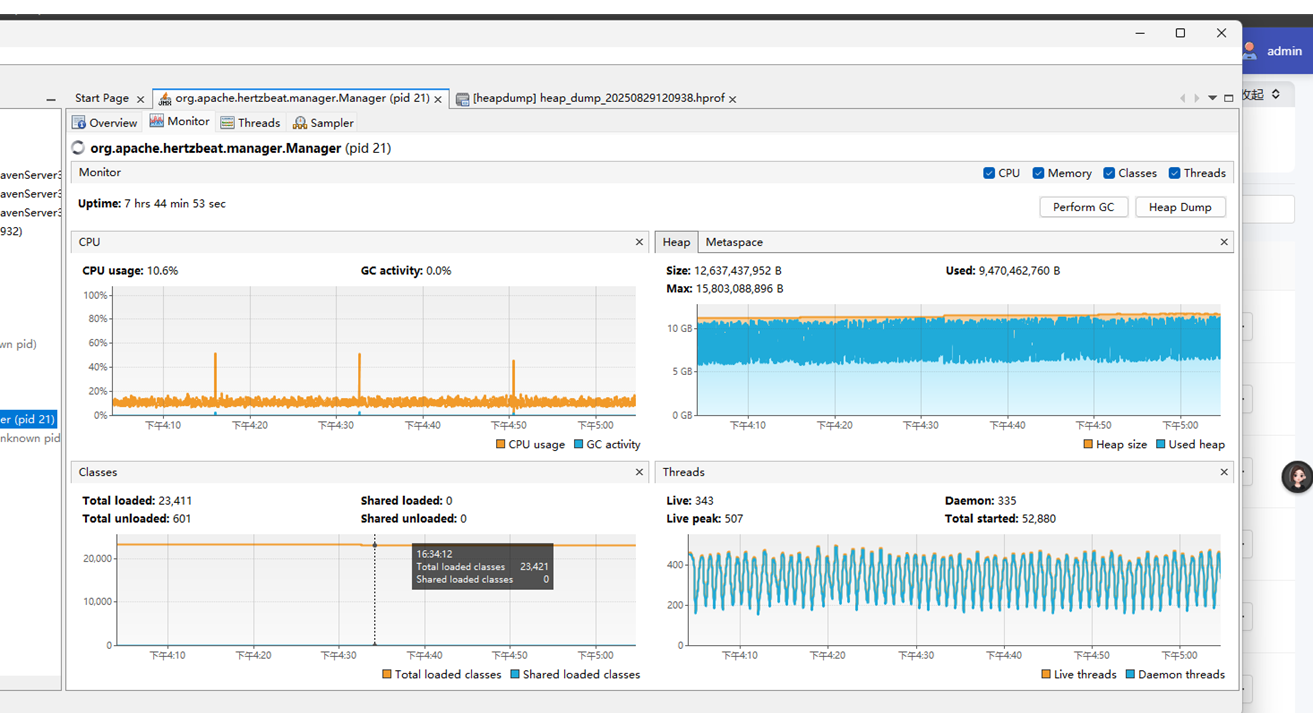
圖中反饋的問題:
1.堆占用巨大,快10G并且在頻繁gc (首先應該限制這么大的堆)
2.線程創建總數 5w+,存活 300+,守護線程300+。反映出有非常多的線程創建后就銷毀。(頻繁創建線程會消耗cpu)
問題處理:
注意,如果有k8s可視化頁面,在頁面操作就行。比如rancher,以下以rancher為例(直接用命令修改k8s配置文件也是相同的)
1.針對大堆,檢查容器啟動命令,發現k8s沒有配置pod資源限制,和java -jar啟動沒有設置堆信息。
查看k8s資源限制:
修改k8s配置文件
kubectl edit deployment hertzbeat-serv(服務名稱) -n devops(命名空間)
沒有resources limit字樣。
設置資源限制路徑:
deployment -> edit config -> resources -> memoryLimit (設置的是pod的資源,java啟動比這個小)
配置為3Gi
設置java啟動參數。找到hertzbeat啟動命令添加 -Xmx2048m -Xms2048m
2.針對線程創建問題。
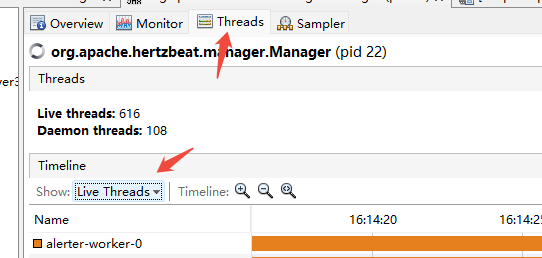
選擇live thread和 finished thread進行查看。
觀察到有大量live thread是與mqtt有關,這個是自定義拓展的代碼線程。
如果在上面就能判斷創建后銷毀的線程大部分都是mqtt相關的話,可以直接搜索代碼。關鍵字 mqtt之類。
我之前使用豆包生成的java代碼解析jstack生成的 線程dump.txt文件(并發截圖時的線程dump),結論為:
===== MQTT線程統計結果 =====
當前存活的MQTT線程總數:219
估算的MQTT線程總創建數:36963
估算的MQTT線程銷毀數:36744
找到代碼:
CommonDispatcher 類中處理任務下發的線程池,發現創建的線程池為:
int coreSize = Math.max(2, Runtime.getRuntime().availableProcessors());int maxSize = Runtime.getRuntime().availableProcessors() * 16;workerExecutor = new ThreadPoolExecutor(coreSize,maxSize,10,TimeUnit.SECONDS,new SynchronousQueue<>(),threadFactory,new ThreadPoolExecutor.AbortPolicy());
SynchronousQueue隊列的意思時,核心線程用完后,任務到達隊列,則直接按照最大線程數進行創建。
參考visulavm線程存活信息,重新設置新的線程池進行替換,原hertzbeat線程池不動。
新線程設置為:
int coreSize = 500;int maxSize = 1500;collectExecutor = new ThreadPoolExecutor(coreSize,maxSize,10,TimeUnit.MINUTES,new SynchronousQueue<>(),threadFactory,new ThreadPoolExecutor.AbortPolicy());
修改jvm堆為2g,和線程池500后運行觀察結果
結果圖:
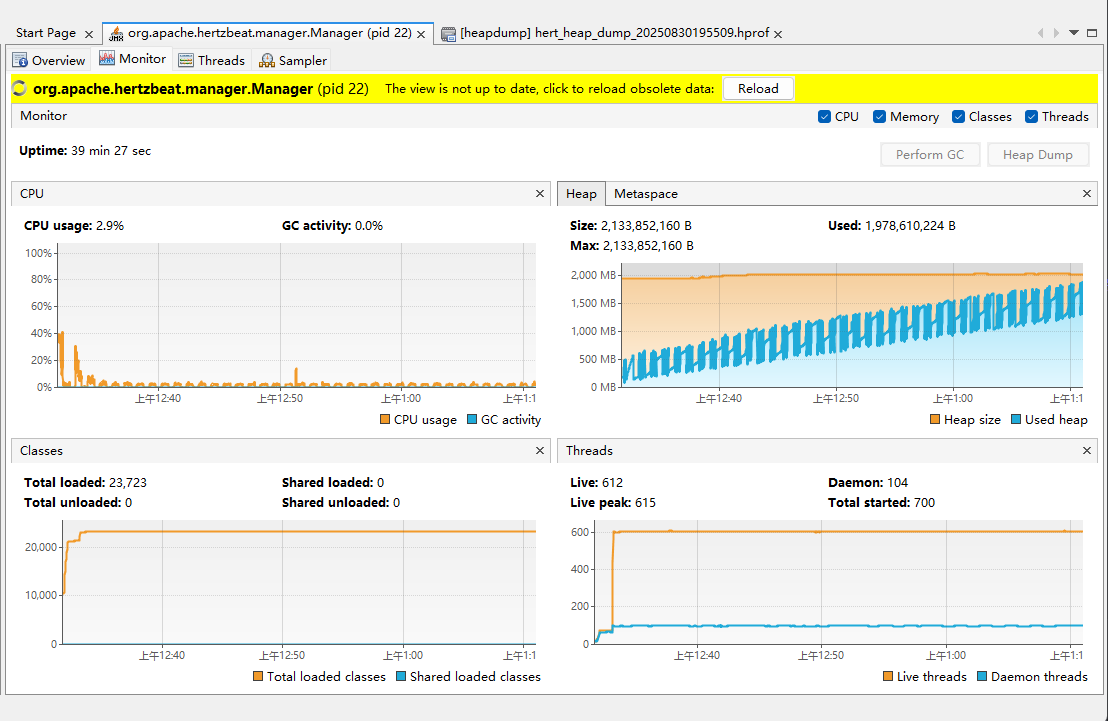
問題:
1.hertzbeat堆最大2g,運行近40分鐘后pod被重啟,看著是oom kill,查看rancher,發現這個pod的確被oom kill,且存在restart次數。
解決問題:
1.線程創建多,且沒有線程復用的問題。
繼續排查:
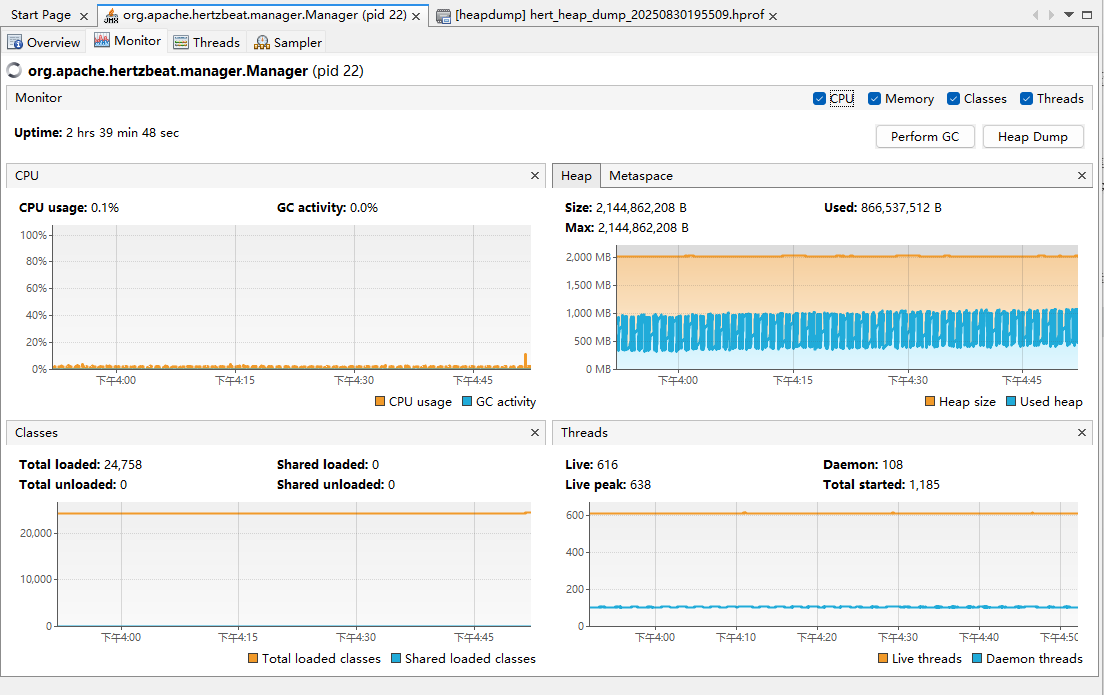
通過上面的圖可以看出,heap圖,不停在gc,但每gc一次,堆的使用則比之前大一點,直到達到最大堆觸發 oom被k8s kill重拉。
懷疑是gc后對象沒有被及時清理,或者堆內存泄漏。
visulaVm分析堆內存占用
將堆dump文件導入visulaVm。
在summary頁面。
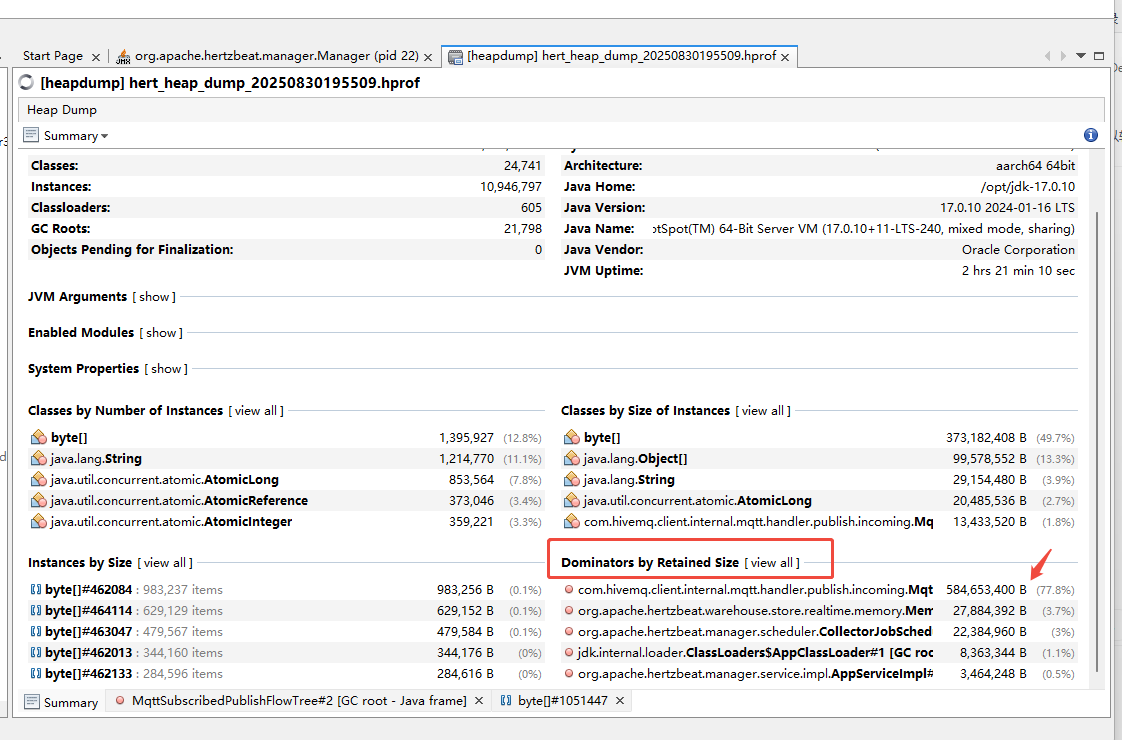
發現mqtt相關的占到了77.8%
右鍵這行,點擊open in new tab
看到類 MqttSubscribedPublishFlowTree 這個是mqtt發布訂閱的代碼。
于是想到業務上是用mqtt的同步響應模式進行數據采集。找到這個代碼
大概為:
每次hertzbeat執行采集,都會觸發到這個代碼。
代碼先訂閱,在發布采集消息。
在高頻的采集任務下,會出現高頻訂閱,而訂閱本質是長期關聯的,因此優化為單個設備采集topic就訂閱一次。
優化這個后,運行2小時,查看堆dump文件:
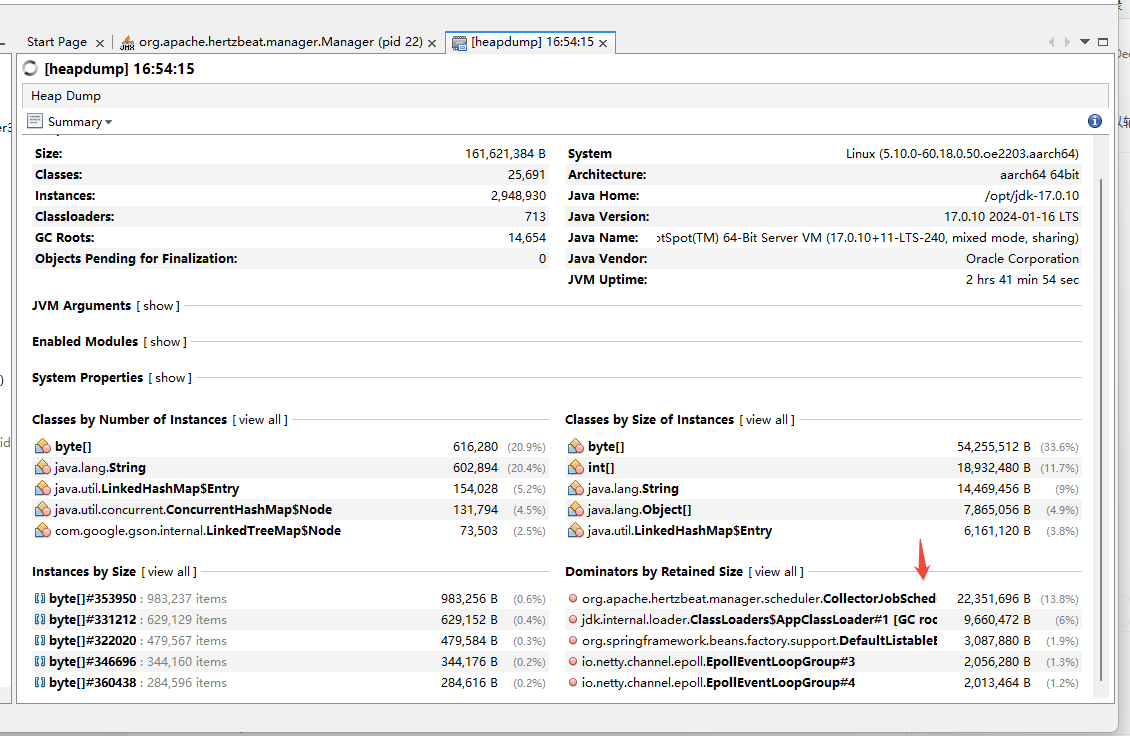
使用mat分析堆內存泄漏
獲取java堆的dump文件,存放到本地,用mat打開。
注意mat如果打不開卡死了,則需要配置他內存大小,路徑:
mat安裝文件夾,MemoryAnalyzer.ini文件,設置-Xmx和-Xms,默認1g。我給的3g
使用mat加載dump文件。
點file -> open xx
導入后總覽為:
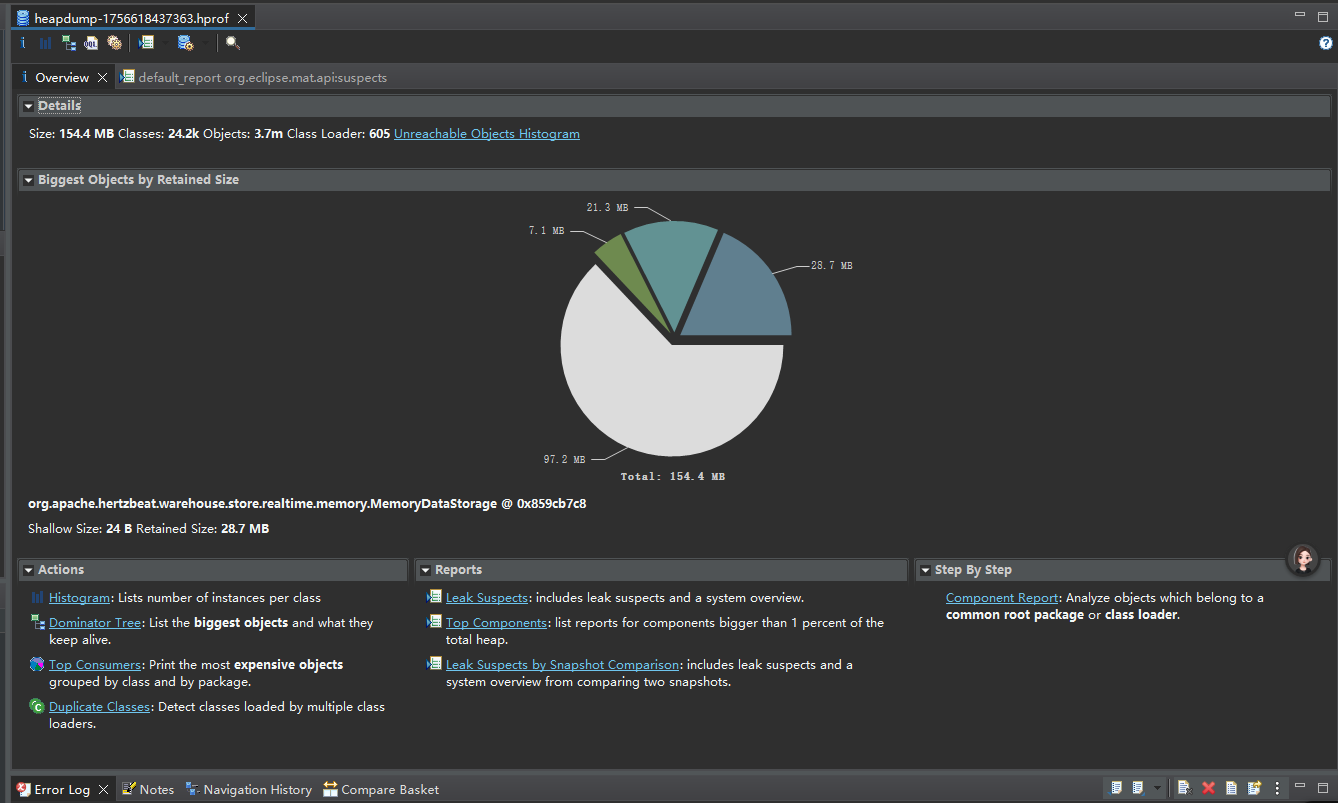
推薦查看:
Leak Suspects
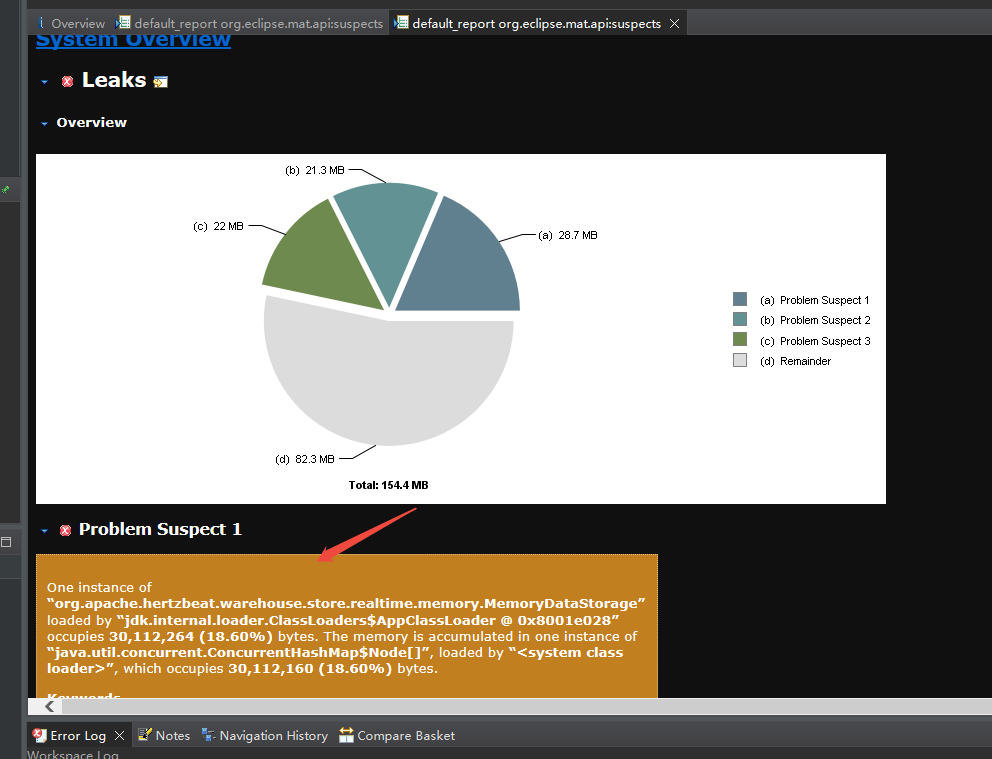
這里會列出嫌疑比較大的。
上面已經有類名了,直接搜這個類名:
MemoryDataStorage
發現是hertzbeat存儲實時數據的核心類。有2中實現。內存,redis。
查看hertzbeat nacos配置:
real-time:memory:enabled: trueinit-size: 16redis:enabled: false# redis mode: single, sentinel, cluster. Default is singlemode: single# separate each address with comma when using cluster mode, eg: 127.0.0.1:6379,127.0.0.1:6380address: 127.0.0.1:6379# enter master name when using sentinel modemasterName: mymasterpassword: 123456# redis db index, default: DB0db: 0
的確,這里也使用的是內存。
切換到redis 后重啟服務。
排查內存泄漏后繼續觀察
visulaVm截圖:
已運行2小時多。
此時繼續查看mat信息:
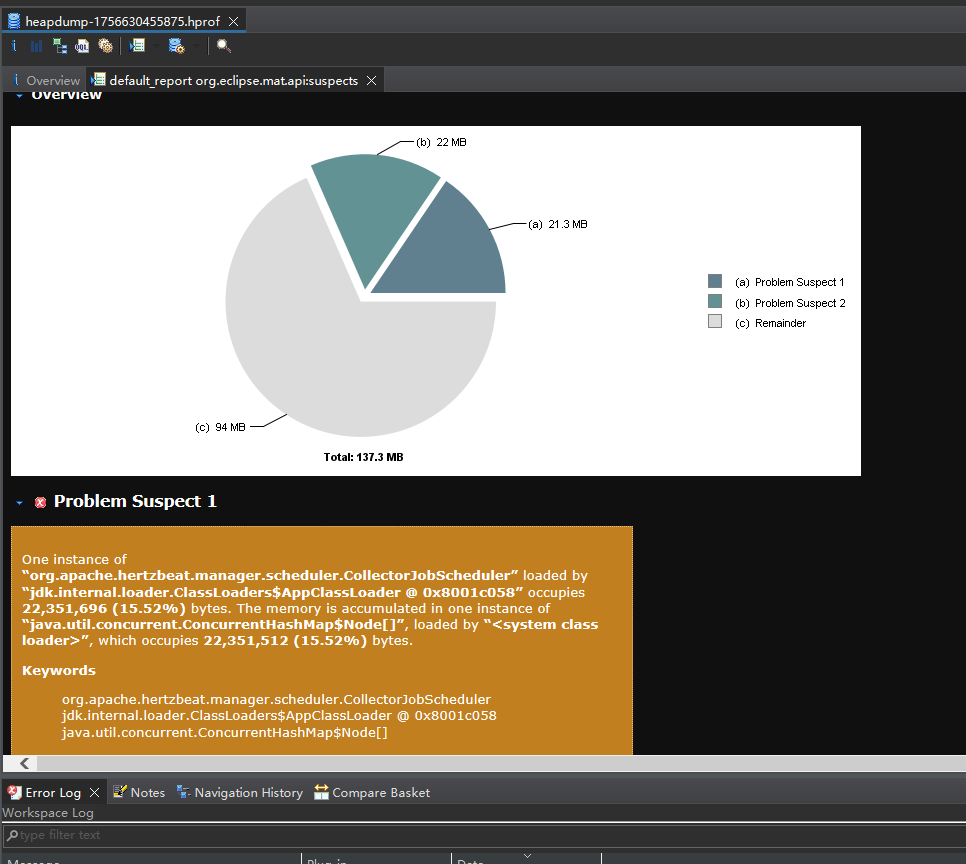
這個problem 1在上面mat圖的第二個problerm。
暫不處理這個,繼續觀察hertzbeat再看看。
更新運行結果:
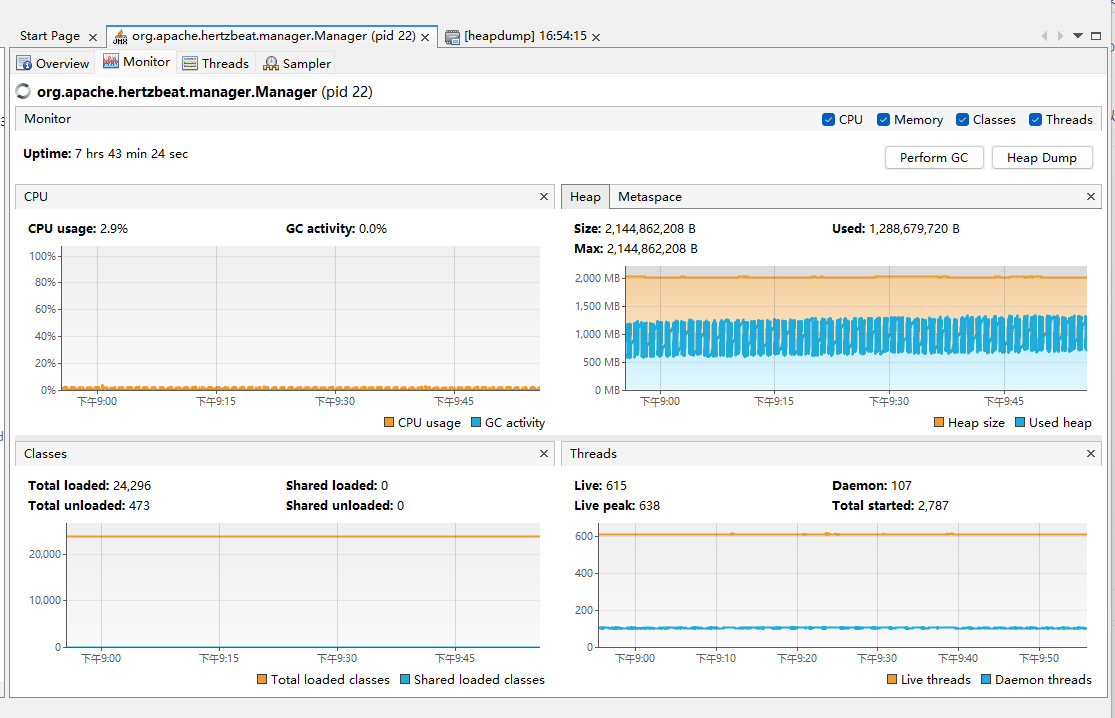
結果上看優化有效果。7小時,沒有崩潰。
看服務器上top信息,hertzbeat cpu在30~80%之間,多數在60%以下。
看hertzbeat 采集任務,沒有宕機。
看web采集結果正常。
到此優化完成。
到此,優化的點為:
修改前:visulaVm監控8h內總計創建7w線程,活躍線程400+,守護線程100+,且堆占用到了15G,且hertzbeat頁面,存在約一半采集任務宕機情況。
1.修改了執行采集任務的線程池,配置核心500 最大1500
修改點:CommonDispatcher中分發采集任務的線程池改造
修改后:觀察2H,線程創建總數1100左右,存活640,守護線程100+
2.分析堆dump文件,查看主要占用內存數據,找到,MqttSubscribedPublishFlowTree,發現采集的mqtt同步響應模式下存在重復訂閱問題。
優化訂閱次數,完成1個模擬器,1個topic訂閱1次。
3.給pod增加容量限制3G,堆增加限制最大,最小2G
修改點:配置堆最大,最小為2G,給pod增加資源限制3G
修改后:觀察40Min,存在重啟pod現象,因為oom,觀察到頻繁gc且,gc后,內值在不斷變大。懷疑內存泄漏
用mat分析發現,MemoryDataStorage占用內存高。(這個是存放采集的實時數據核心類)
4.將檢測采集的實時數據,修改到redis
修改點:將hertzbeat實時數據采集nacos配置,從內存,改動到redis
修改后:觀察20min后,堆占用在220m到890m之間波動,
排查建議
建議將堆信息,比如作為提問內容,且帶上懷疑代碼,直接問ai這有什么可以優化的,或者是否有問題。











—— IOT 設備 OTA 升級方案)

)
)


)

