背景意義
隨著經濟的發展和數字支付的普及,傳統硬幣的使用逐漸減少,但在某些地區和特定場合,硬幣仍然是重要的支付手段。因此,硬幣的分類與識別在自動化支付、智能零售和物聯網等領域具有重要的應用價值。尤其是在銀行、商超和自助售貨機等場景中,快速、準確地識別和分類硬幣不僅可以提高交易效率,還能降低人工成本,提升用戶體驗。
近年來,深度學習技術在計算機視覺領域取得了顯著進展,尤其是目標檢測和實例分割技術的快速發展,為硬幣識別提供了新的解決方案。YOLO(You Only Look Once)系列模型因其高效的實時檢測能力,已成為目標檢測領域的主流選擇。隨著YOLOv11的推出,其在檢測精度和速度上的進一步提升,使其成為硬幣分類與識別的理想選擇。
本研究旨在基于改進的YOLOv11模型,構建一個高效的硬幣分類與識別系統。所使用的數據集包含5600張經過精心標注的硬幣圖像,涵蓋了四種不同面值的硬幣(1 rs、2 rs、5 rs、10 rs)。這些圖像經過多種預處理和數據增強技術,確保了模型在不同場景下的魯棒性和準確性。通過對硬幣的實例分割和分類,本系統不僅能夠實現對硬幣的精確識別,還能為后續的自動化交易系統提供數據支持。
此外,本研究的成果將為相關領域的研究提供理論基礎和實踐指導,推動硬幣識別技術的進一步發展。通過提升硬幣識別的自動化水平,能夠有效應對日益增長的交易需求,促進經濟的數字化轉型。總之,基于改進YOLOv11的硬幣分類與識別系統的研究,不僅具有重要的學術價值,也具備廣泛的實際應用前景。
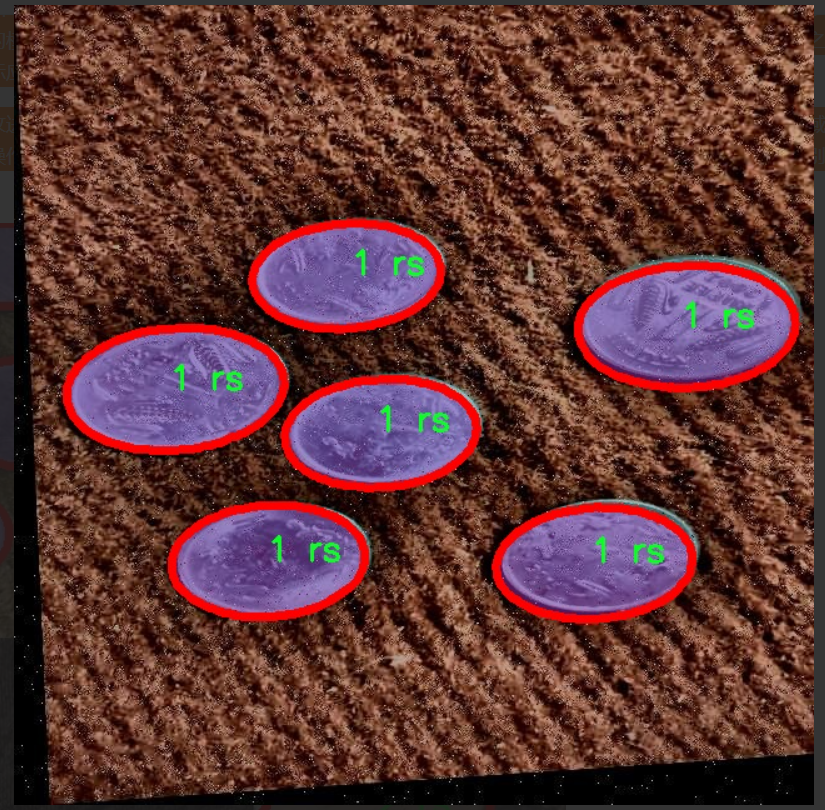
圖片效果
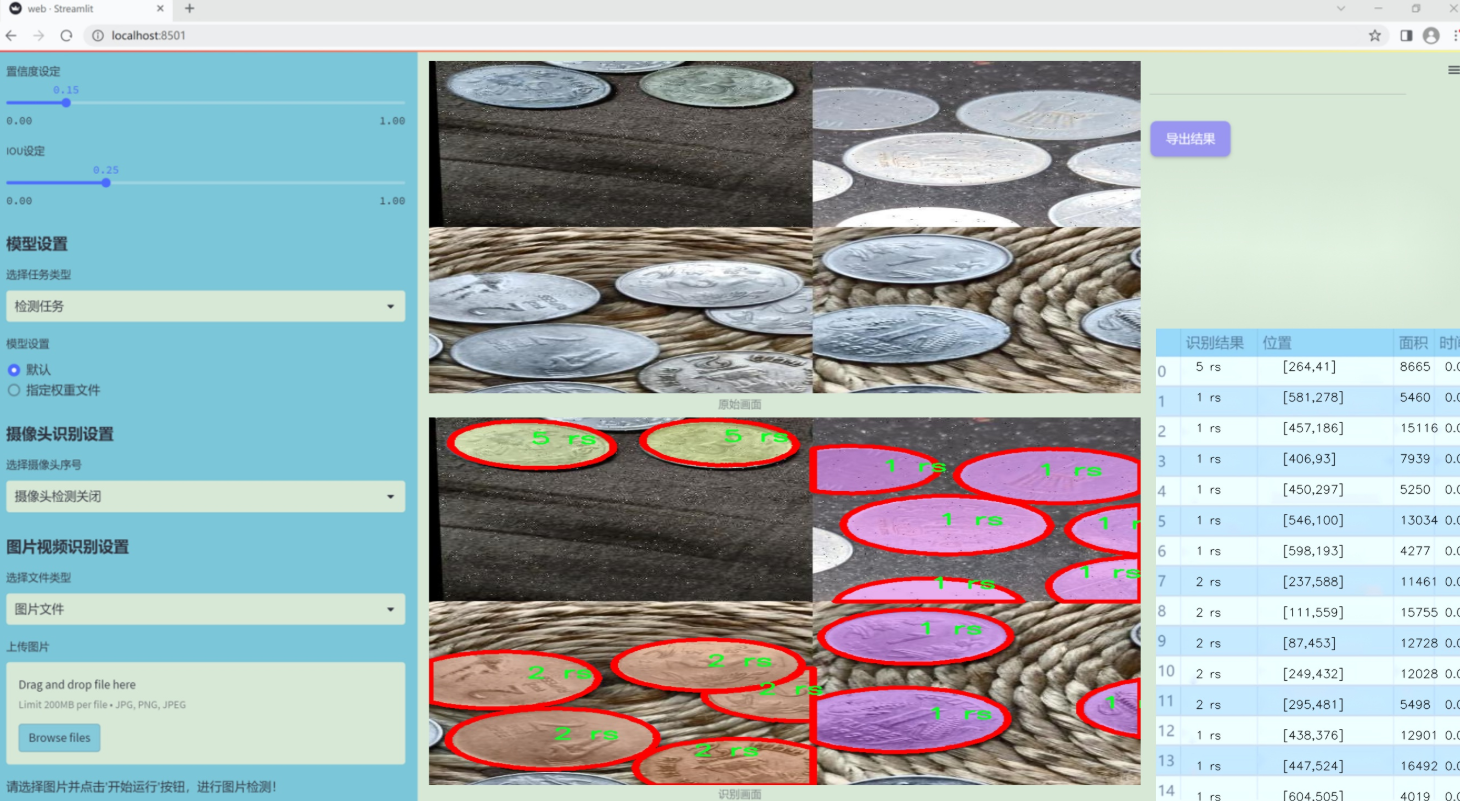
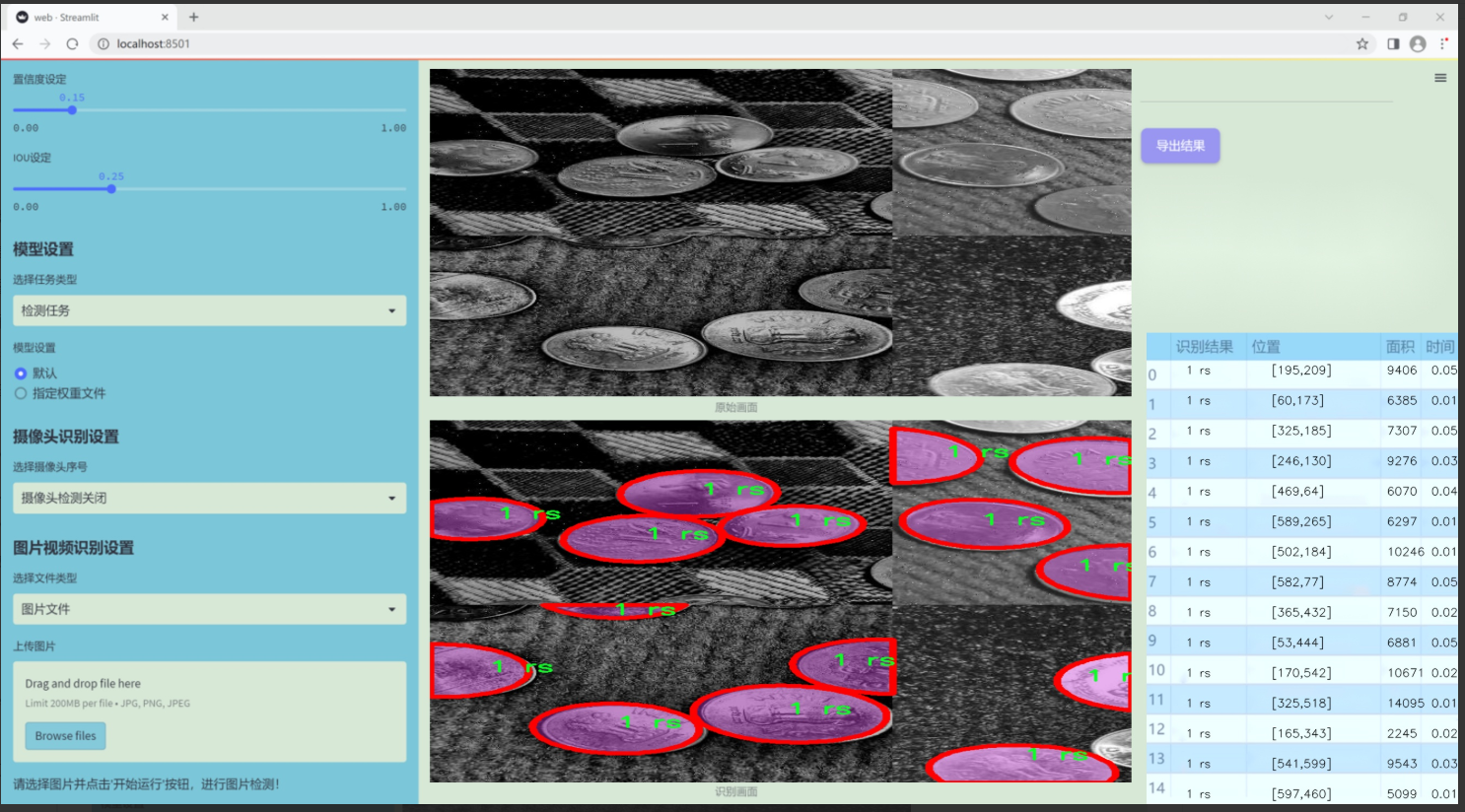
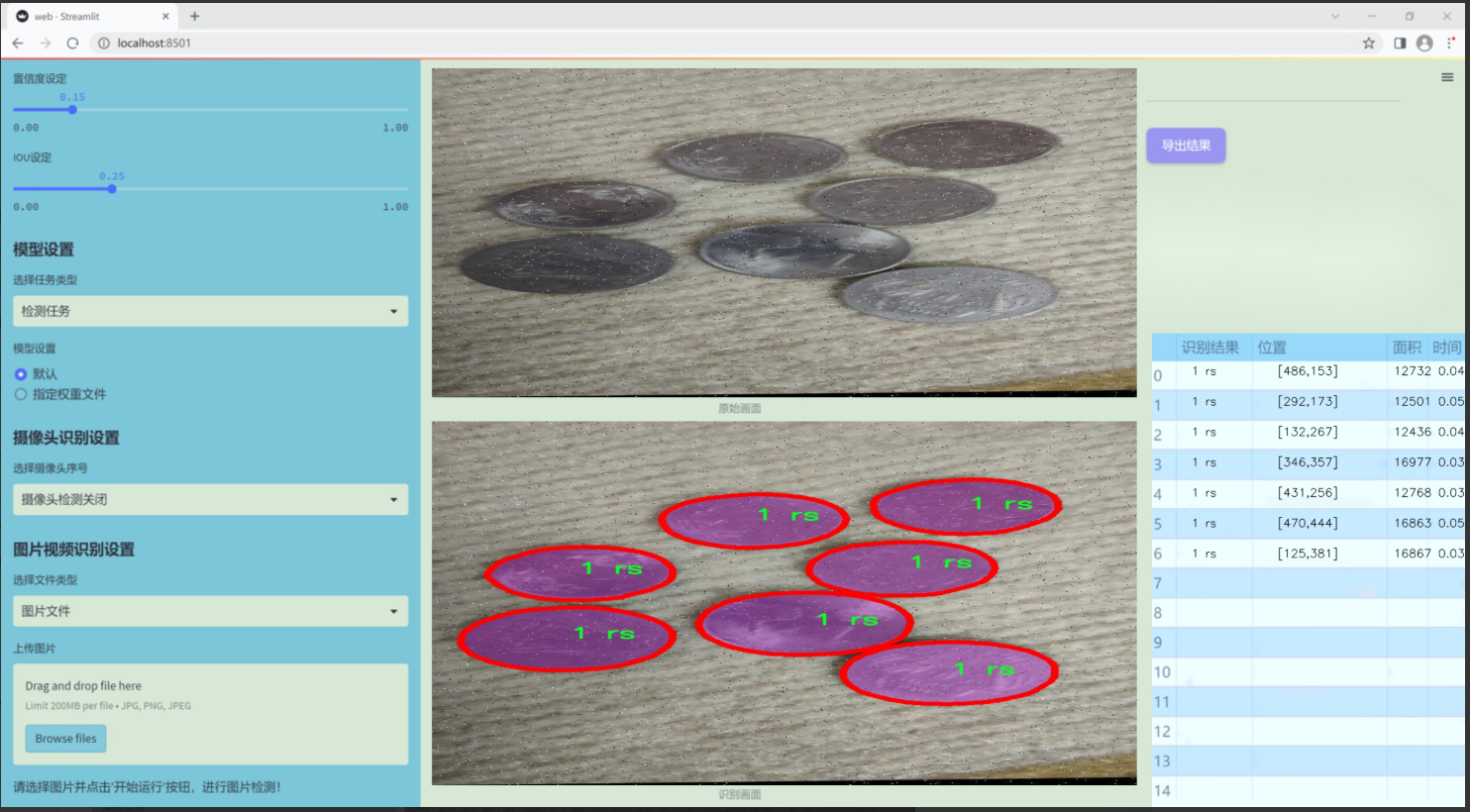
數據集信息
本項目數據集信息介紹
本項目所使用的數據集專注于硬幣的分類與識別,旨在改進YOLOv11模型的性能,以實現更高效的硬幣識別系統。數據集包含四個主要類別,分別為“1 rs”、“10 rs”、“2 rs”和“5 rs”,這些類別涵蓋了印度流通的主要硬幣面值。每個類別的樣本數量經過精心挑選,以確保模型在訓練過程中能夠獲得足夠的多樣性和代表性,從而提高其在實際應用中的準確性和魯棒性。
數據集中的圖像均為高質量的硬幣照片,拍攝時考慮了不同的光照條件、背景和角度,以模擬真實世界中可能遇到的各種情況。這種多樣性不僅增強了模型的泛化能力,還使其能夠在不同環境下保持穩定的識別性能。此外,數據集中還包含了多種硬幣的細節特征,如硬幣的紋理、邊緣和圖案,這些特征對于分類任務至關重要。
為了確保數據集的有效性和可靠性,所有圖像均經過人工標注,確保每個樣本的類別信息準確無誤。這一過程不僅提高了數據集的質量,也為后續的模型訓練奠定了堅實的基礎。通過對這些硬幣圖像的深入分析,模型將能夠學習到各個類別之間的細微差別,從而在實際應用中實現快速且準確的硬幣識別。
總之,本項目的數據集為改進YOLOv11的硬幣分類與識別系統提供了豐富的訓練素材,旨在推動智能識別技術在金融領域的應用,提升用戶體驗與操作效率。通過不斷優化和擴展數據集,我們期望能夠進一步提高模型的性能,使其在硬幣識別任務中表現出色。

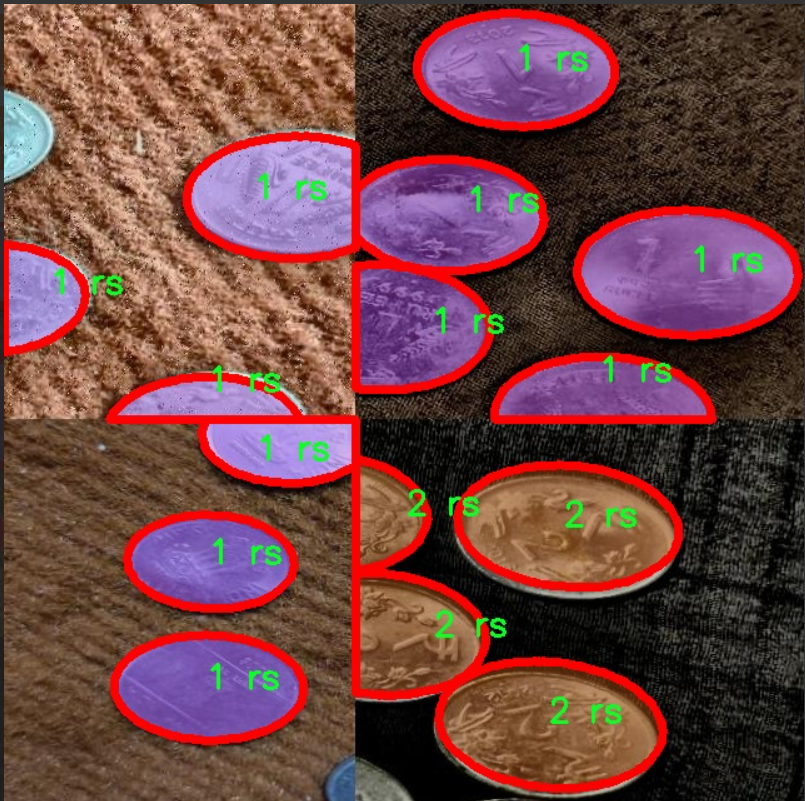

核心代碼
以下是經過簡化并注釋的核心代碼部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DWConv2d(nn.Module):
“”" 深度可分離卷積層 “”"
def init(self, dim, kernel_size, stride, padding):
super().init()
# 使用 groups=dim 實現深度可分離卷積
self.conv = nn.Conv2d(dim, dim, kernel_size, stride, padding, groups=dim)
def forward(self, x: torch.Tensor):""" 前向傳播x: 輸入張量,形狀為 (b, h, w, c)"""x = x.permute(0, 3, 1, 2) # 轉換為 (b, c, h, w)x = self.conv(x) # 卷積操作x = x.permute(0, 2, 3, 1) # 轉換回 (b, h, w, c)return x
class FeedForwardNetwork(nn.Module):
“”" 前饋神經網絡 “”"
def init(self, embed_dim, ffn_dim, activation_fn=F.gelu, dropout=0.0):
super().init()
self.fc1 = nn.Linear(embed_dim, ffn_dim) # 第一層線性變換
self.fc2 = nn.Linear(ffn_dim, embed_dim) # 第二層線性變換
self.dropout = nn.Dropout(dropout) # dropout層
self.activation_fn = activation_fn # 激活函數
def forward(self, x: torch.Tensor):""" 前向傳播x: 輸入張量,形狀為 (b, h, w, c)"""x = self.fc1(x) # 線性變換x = self.activation_fn(x) # 激活函數x = self.dropout(x) # dropoutx = self.fc2(x) # 線性變換return x
class RetBlock(nn.Module):
“”" 保留塊,用于處理輸入的殘差連接和前饋網絡 “”"
def init(self, embed_dim, num_heads, ffn_dim):
super().init()
self.ffn = FeedForwardNetwork(embed_dim, ffn_dim) # 前饋網絡
self.pos = DWConv2d(embed_dim, 3, 1, 1) # 位置卷積
def forward(self, x: torch.Tensor):""" 前向傳播x: 輸入張量,形狀為 (b, h, w, c)"""x = x + self.pos(x) # 添加位置卷積x = x + self.ffn(x) # 添加前饋網絡的輸出return x
class BasicLayer(nn.Module):
“”" 基礎層,包含多個保留塊 “”"
def init(self, embed_dim, depth, num_heads, ffn_dim):
super().init()
self.blocks = nn.ModuleList([
RetBlock(embed_dim, num_heads, ffn_dim) for _ in range(depth) # 創建多個保留塊
])
def forward(self, x: torch.Tensor):""" 前向傳播x: 輸入張量,形狀為 (b, h, w, c)"""for blk in self.blocks:x = blk(x) # 逐塊處理輸入return x
class VisRetNet(nn.Module):
“”" 可視化保留網絡 “”"
def init(self, in_chans=3, num_classes=1000, embed_dims=[96, 192, 384, 768], depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], ffn_dim=96):
super().init()
self.patch_embed = nn.Conv2d(in_chans, embed_dims[0], kernel_size=4, stride=4) # 圖像到補丁的嵌入
self.layers = nn.ModuleList([
BasicLayer(embed_dim=embed_dims[i], depth=depths[i], num_heads=num_heads[i], ffn_dim=ffn_dim) for i in range(len(depths))
])
def forward(self, x: torch.Tensor):""" 前向傳播x: 輸入張量,形狀為 (b, c, h, w)"""x = self.patch_embed(x) # 嵌入操作for layer in self.layers:x = layer(x) # 逐層處理return x
創建模型實例
def RMT_T():
model = VisRetNet(
embed_dims=[64, 128, 256, 512],
depths=[2, 2, 8, 2],
num_heads=[4, 4, 8, 16]
)
return model
if name == ‘main’:
model = RMT_T() # 創建模型
inputs = torch.randn((1, 3, 640, 640)) # 隨機輸入
res = model(inputs) # 前向傳播
print(res.size()) # 輸出結果的形狀
代碼注釋說明:
DWConv2d: 實現深度可分離卷積的模塊,適用于圖像特征提取。
FeedForwardNetwork: 實現前饋神經網絡,包括線性變換和激活函數。
RetBlock: 包含殘差連接和前饋網絡的模塊,能夠增強模型的學習能力。
BasicLayer: 由多個保留塊組成的基礎層,負責處理輸入特征。
VisRetNet: 主網絡結構,負責將輸入圖像轉化為特征表示,包含補丁嵌入和多個基礎層。
RMT_T: 用于創建特定配置的可視化保留網絡模型實例。
這個程序文件 rmt.py 實現了一個基于視覺變換器(Vision Transformer)的網絡模型,名為 VisRetNet,并定義了一些相關的模塊和功能。代碼中包含多個類和函數,每個類和函數負責不同的功能,整體結構清晰,適合進行圖像處理和特征提取。
首先,程序導入了必要的庫,包括 PyTorch 和一些自定義的層和模塊。接著,定義了一些基礎的卷積層、注意力機制和網絡層。以下是各個部分的詳細說明:
DWConv2d 類:實現了深度可分離卷積,主要用于減少參數數量和計算量。它將輸入的張量進行維度變換,然后應用卷積操作,最后再變換回原來的維度。
RelPos2d 類:用于生成二維相對位置編碼,支持生成不同維度的衰減掩碼。這個類在注意力機制中非常重要,因為它幫助模型理解輸入特征之間的相對位置關系。
MaSAd 和 MaSA 類:這兩個類實現了多頭自注意力機制。MaSAd 適用于分塊的注意力計算,而 MaSA 則用于整體的注意力計算。它們通過線性變換生成查詢、鍵和值,并結合相對位置編碼進行注意力計算。
FeedForwardNetwork 類:實現了前饋神經網絡,包含兩個線性層和激活函數。它用于在每個變換層后處理特征。
RetBlock 類:定義了一個殘差塊,結合了注意力機制和前饋網絡。它可以選擇性地使用層歸一化和層縮放,以提高模型的穩定性和性能。
PatchMerging 類:實現了圖像的分塊合并層,主要用于下采樣操作,將特征圖的分辨率降低。
BasicLayer 類:構建了一個基本的變換器層,包含多個殘差塊,并在最后進行下采樣。
LayerNorm2d 類:實現了二維層歸一化,用于對特征圖進行歸一化處理。
PatchEmbed 類:將輸入圖像轉換為補丁嵌入,使用卷積層進行特征提取,并將輸出的特征圖轉換為適合后續處理的格式。
VisRetNet 類:這是整個模型的核心類,負責構建整個網絡結構。它包括多個基本層和補丁嵌入層,并實現了前向傳播方法。
最后,文件中定義了幾個函數(RMT_T, RMT_S, RMT_B, RMT_L),用于創建不同規模的 VisRetNet 模型。這些函數根據不同的參數設置構建模型,并返回相應的網絡實例。
在 main 部分,代碼創建了一個 RMT_T 模型實例,并生成一個隨機輸入進行測試,輸出每個特征圖的尺寸。這部分代碼可以用來驗證模型的構建是否正確。
總體來說,這個程序文件展示了如何構建一個復雜的視覺變換器模型,結合了多種深度學習技術,如自注意力機制、前饋網絡和層歸一化等,適用于圖像分類和特征提取任務。
10.4 rep_block.py
以下是代碼中最核心的部分,并附上詳細的中文注釋:
import torch
import torch.nn as nn
import torch.nn.functional as F
def transI_fusebn(kernel, bn):
“”"
將卷積核和批歸一化層的參數融合為一個卷積核和偏置。
參數:
kernel: 卷積核權重
bn: 批歸一化層返回:
融合后的卷積核和偏置
"""
gamma = bn.weight # 獲取批歸一化的縮放因子
std = (bn.running_var + bn.eps).sqrt() # 計算標準差
# 融合卷積核和批歸一化
return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / std
def conv_bn(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1):
“”"
創建一個卷積層和批歸一化層的組合。
參數:
in_channels: 輸入通道數
out_channels: 輸出通道數
kernel_size: 卷積核大小
stride: 步幅
padding: 填充
dilation: 膨脹
groups: 分組卷積的組數返回:
包含卷積層和批歸一化層的序列
"""
conv_layer = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, dilation=dilation, groups=groups,bias=False) # 創建卷積層,不使用偏置
bn_layer = nn.BatchNorm2d(num_features=out_channels, affine=True) # 創建批歸一化層
return nn.Sequential(conv_layer, bn_layer) # 返回包含卷積和批歸一化的序列
class DiverseBranchBlock(nn.Module):
def init(self, in_channels, out_channels, kernel_size, stride=1, padding=None, dilation=1, groups=1):
“”"
初始化多分支塊。
參數:in_channels: 輸入通道數out_channels: 輸出通道數kernel_size: 卷積核大小stride: 步幅padding: 填充dilation: 膨脹groups: 分組卷積的組數"""super(DiverseBranchBlock, self).__init__()self.kernel_size = kernel_sizeself.in_channels = in_channelsself.out_channels = out_channelsself.groups = groupsif padding is None:padding = kernel_size // 2 # 默認填充為卷積核大小的一半assert padding == kernel_size // 2 # 確保填充正確# 定義原始卷積和批歸一化層self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,stride=stride, padding=padding, dilation=dilation, groups=groups)def forward(self, inputs):"""前向傳播函數。參數:inputs: 輸入張量返回:輸出張量"""out = self.dbb_origin(inputs) # 通過原始卷積和批歸一化層計算輸出return out # 返回輸出
示例使用
if name == “main”:
model = DiverseBranchBlock(in_channels=3, out_channels=16, kernel_size=3)
x = torch.randn(1, 3, 224, 224) # 創建一個隨機輸入
output = model(x) # 通過模型進行前向傳播
print(output.shape) # 輸出形狀
代碼核心部分解釋:
transI_fusebn: 該函數用于將卷積層的權重和批歸一化層的參數融合,生成一個新的卷積核和偏置。這在模型推理時可以減少計算量。
conv_bn: 該函數創建一個包含卷積層和批歸一化層的序列,方便在模型中使用。
DiverseBranchBlock: 這是一個自定義的神經網絡模塊,包含一個卷積層和批歸一化層。其構造函數接受輸入通道數、輸出通道數、卷積核大小等參數,并在前向傳播中計算輸出。
forward: 前向傳播方法,接受輸入并通過定義的卷積層和批歸一化層計算輸出。
以上是對代碼中最核心部分的保留和詳細注釋。
這個程序文件 rep_block.py 定義了一些用于構建神經網絡中多樣化分支模塊的類和函數,主要用于深度學習中的卷積神經網絡(CNN)。文件中使用了 PyTorch 框架,并實現了一些特定的卷積操作和批歸一化(Batch Normalization)功能。
首先,文件中導入了必要的庫,包括 torch 和 torch.nn,并從其他模塊中引入了一些自定義的卷積函數。接下來,定義了一些轉換函數,例如 transI_fusebn、transII_addbranch 等,這些函數主要用于處理卷積核和偏置的融合、合并等操作,以便在網絡推理時提高效率。
接下來,定義了幾個類,主要包括 DiverseBranchBlock、WideDiverseBranchBlock 和 DeepDiverseBranchBlock,這些類實現了不同類型的分支模塊。每個模塊的構造函數中都包含了多個卷積層和批歸一化層的組合,具體的實現細節根據輸入和輸出通道數、卷積核大小、步幅、填充等參數進行調整。
DiverseBranchBlock 類實現了一個多樣化的分支模塊,支持多種卷積操作,包括 1x1 卷積和 kxk 卷積。它還提供了一個 switch_to_deploy 方法,用于在推理階段將模型轉換為更高效的形式,減少計算量。
WideDiverseBranchBlock 類則在此基礎上增加了對水平和垂直卷積的支持,能夠處理不同方向的卷積操作,并將其結果合并到輸出中。這個模塊在設計上更為復雜,能夠處理更豐富的特征信息。
DeepDiverseBranchBlock 類是一個更深層次的模塊,允許用戶自定義內部卷積通道數,并支持在推理階段的高效轉換。
此外,文件中還定義了一些輔助類,如 IdentityBasedConv1x1 和 BNAndPadLayer,分別用于實現帶有身份映射的 1x1 卷積和結合批歸一化的填充層。這些類的設計旨在增強模型的靈活性和可擴展性。
總體來說,這個文件實現了一種靈活的神經網絡模塊設計,能夠根據不同的需求組合多種卷積操作,并通過批歸一化提高訓練和推理的效率。通過這些模塊,用戶可以方便地構建和調整深度學習模型,以適應各種計算任務。
源碼文件

源碼獲取
歡迎大家點贊、收藏、關注、評論啦 、查看👇🏻獲取聯系方式



)
】bash方式啟動模型訓練)
基本概念與三種操作(Read / Write / Notify)的理解)
:從 0 掌握 Set 集合)






階段小總結(一)——大數據與Java)



)

![[機器學習]基于K-means聚類算法的鳶尾花數據及分類](http://pic.xiahunao.cn/[機器學習]基于K-means聚類算法的鳶尾花數據及分類)