? ? ? ? 這節我們接著學習 Set 集合。
一、Set 集合
1.1 Set 概述
????????java.util.Set 接口繼承了 Collection 接口,是常用的一種集合類型。 相對于之前學習的List集合,Set集合特點如下:
????????除了具有 Collection 集合的特點,還具有自己的一些特點:
- ?Set是一種無序的集合
- ?Set是一種不帶下標索引的集合
- ?Set是一種不能存放重復數據的集合
Set 接口繼承體系:
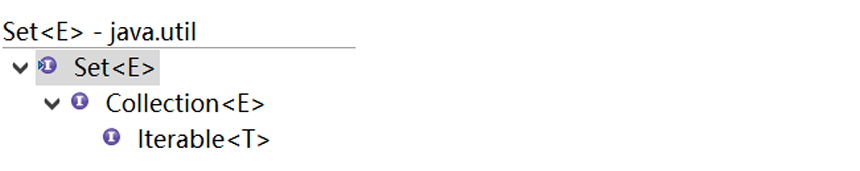
Set 接口方法:

基礎案例:
實例化一個Set集合,往里面添加元素并輸出,注意觀察集合特點(無序、不重復):
import java.util.Set;
import java.util.HashSet;
import java.util.Iterator;public class SetTest {public static void main(String[] args) {//1.實例化Set集合,指向HashSet實現類對象Set<String> set = new HashSet<>();set.add("hello1");set.add("hello2");set.add("hello3");set.add("hello4");set.add("hello5");set.add("hello5"); //添加失敗 重復元素//增強for循環遍歷for (String obj : set) {System.out.println(obj);}System.out.println("------------------");//迭代器遍歷Iterator<String> it = set.iterator();while (it.hasNext()) {Object obj = it.next();System.out.println(obj);}}
}
運行結果:
hello1
hello4
hello5
hello2
hello3
------------------
hello1
hello4
hello5
hello2
hello3通過以上代碼和運行結果,可以看出Set類型集合的特點:無序、不可重復
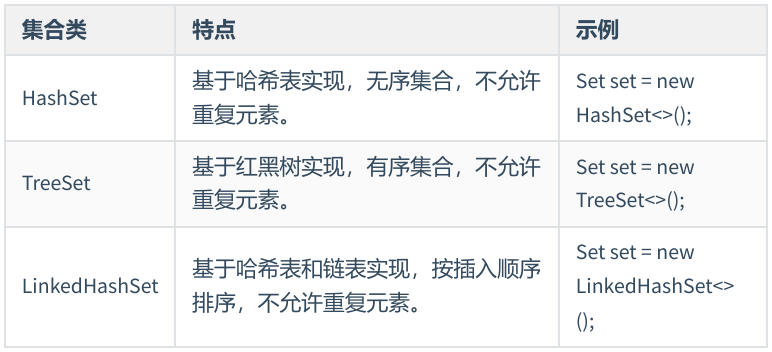
1.2 HashSet
????????java.util.HashSet 是Set接口的實現類,它使用哈希表(Hash Table)作為其底層數據結構來存儲數據。
HashSet特點:
- 無序性:HashSet中的元素的存儲順序與插入順序無關
HashSet使用哈希表來存儲數據,哈希表根據元素的哈希值來確定元素的存儲位置,而哈希值是根據元素的內容計算得到的,與插入順序無關。
- 唯一性:HashSet中不允許重復的元素,即每個元素都是唯一的
關鍵:存儲自定義對象時,必須同時重寫hashCode()和equals(),否則無法保證唯一性(默認用地址值計算哈希,導致內容相同的對象被視為不同元素)。
- 允許null元素:HashSet允許存儲null元素,但只能存儲一個null元素, HashSet中不允許重復元素
- 高效性:HashSet的插入、刪除和查找操作的時間復雜度都是O(1)
哈希表通過將元素的哈希值映射到數組的索引來實現快速的插入、刪除和查找操作。
基礎案例1:
實例化HashSet對象,往里面插入多個字符串,驗證HashSet特點。
import java.util.HashSet;
import java.util.Set;public class HashSetTest {public static void main(String[] args) {//1.實例化HashSet對象Set<String> set = new HashSet<>();//2.添加元素set.add("hello");set.add("world");set.add("nihao");set.add("hello");set.add(null);set.add(null);System.out.println("size:"+set.size());//3.遍歷for (String str : set) {System.out.println(str);}}
}
運行結果:
size:4
null
world
nihao
hello根據結果可知,HashSet無序、唯一、null值可存在且只能存在一個。
元素插入過程:
當向HashSet中插入元素時,先獲取元素的hashCode()值,再檢查HashSet中是否存在相同哈希值的元素,如果元素哈希值唯一,則直接插入元素
如果存在相同哈希值的元素,會調用元素的equals()方法來進一步判斷元素是否是相同。如果相同,則不會插入重復元素;如果不同,則插入元素
案例展示:
重寫Student類的hashCode()方法:
class Student {private String id; // 關鍵屬性1(equals中比較)private String name; // 關鍵屬性2(equals中比較)private int age; // 非關鍵屬性(equals中不比較,hashCode中也不參與計算)// 構造方法public Student(String id, String name, int age) {this.id = id;this.name = name;this.age = age;}// 先重寫equals()(必須與hashCode()基于相同屬性)@Overridepublic boolean equals(Object obj){if (this == obj) {return true;}if (obj == null) {return false;}if (getClass() != obj.getClass()) {return false;}Student other = (Student)obj;if (name == null) {if (other.name != null) {return false;}}else if (!name.equals(other.name)) {return false;}if (age != other.age) {return false;}return true;}// 重寫hashCode()(基于id和name計算)@Overridepublic int hashCode() {int result = 17; // 初始化哈希種子(非零經驗值)// 處理id(引用類型,可能為null)int idHash = (id == null) ? 0 : id.hashCode();result = 31 * result + idHash; // 31是質數,減少哈希沖突// 處理name(引用類型,可能為null)int nameHash = (name == null) ? 0 : name.hashCode();result = 31 * result + nameHash;return result; // 返回最終哈希值}
}如果要往HashSet集合存儲自定義類對象,那么一定要重寫自定義類中的 hashCode方法和equals方法!
1.3 TreeSet
????????TreeSet是SortedSet(Set接口的子接口)的實現類,它基于紅黑樹(Red Black Tree)數據結構實現。
TreeSet特點:
- 有序性:插入的元素會自動排序,每次插入、刪除或查詢操作后,TreeSet會自動調整元素的順序,以保持有序性。
- 唯一性:TreeSet中不允許重復的元素,即集合中的元素是唯一的。如果嘗試插入一個已經存在的元素,該操作將被忽略。
- 動態性:TreeSet是一個動態集合,可以根據需要隨時添加、刪除和修改元素。插入和刪除操作的時間復雜度為O(log n),其中n是集合中的元素數量。
- 高效性:由于TreeSet底層采用紅黑樹數據結構,它具有快速的查找和插入性能。對于有序集合的操作,TreeSet通常比HashSet更高效。
基礎案例:
準備一個TreeSet集合,放入多個自定義類Person對象,觀察是否自動進行排序。
基礎類Person類:
import java.util.Set;import java.util.TreeSet;class Person {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Person [name=" + name + ", age=" + age + "]";}
}測試類:
public class Test_Person {public static void main(String[] args) {//1.實例化TreeSetSet<Person> set = new TreeSet<>();//2.添加元素set.add(new Person("zs", 21));set.add(new Person("ls", 20));set.add(new Person("tom", 19));//3.遍歷集合for (Person person : set) {System.out.println(person);}}
}運行程序發現:
//程序運行,提示異常,具體如下:
Exception in thread "main" java.lang.ClassCastException:
java.lang.Comparableat java.util.TreeMap.compare(TreeMap.java:1290)at java.util.TreeMap.put(TreeMap.java:538)at java.util.TreeSet.add(TreeSet.java:255)at Test_Person.main(Test_Person.java:41)問題分析:
根據異常提示可知錯誤原因是: Person 無法轉化成 Comparable ,從而導致 ClassCastException 異常 。 為什么會這樣呢?
解析:
TreeSet是一個有序集合,存儲數據時,一定要指定元素的排序規則,有兩種指定的方式,具體如下:
- 自然排序(元素所屬類型要實現 java.lang.Comparable 接口)
- 比較器排序
1)自然排序
如果一個類,實現了 java.lang.Comparable 接口,并重寫了 compareTO 方法,那么這個類的對象就是可以比較大小的。
public interface Comparable<T> {public int compareTo(T o);
}compareTo方法說明:
????????int result = this.屬性.compareTo(o.屬性);
- result的值大于0,說明this比o大
- result的值小于0,說明this比o小
- result的值等于0,說明this和o相等
元素插入過程:
????????當向TreeSet插入元素時,TreeSet會使用元素的 compareTo() 方法來比較元素之間的大小關系。根據比較結果,TreeSet會將元素插入到合適的位置,以保持有序性。如果兩個元素相等( compareTo() 方法返回0),TreeSet會認為這是重復的元素,只會保留一個。
基礎 Person 類:
//定義Person類,實現自然排序
public class Person implements Comparable<Person> {private String name;private int age;public Person() {}public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}@Overridepublic String toString() {return "Person [name=" + name + ", age=" + age + "]";}//重寫方法,指定比較規則:先按name升序,name相同則按age降序@Overridepublic int compareTo(Person o) {//注意:字符串比較需要使用compareTo方法int r = name.compareTo(o.name);if(r == 0) {r = o.age - this.age;}return r;}
}測試類:
import java.util.Set;
import java.util.TreeSet;
import com.briup.chap08.bean.Person;//自然排序測試
public class Test073_Comparable {public static void main(String[] args) {//1.實例化TreeSetSet<Person> set = new TreeSet<>();//2.添加元素set.add(new Person("zs", 21));set.add(new Person("ww", 20));set.add(new Person("zs", 21));set.add(new Person("tom", 19));set.add(new Person("tom", 23));set.add(new Person("jack", 20));//3.遍歷集合for (Person person : set) {System.out.println(person);}}
}運行結果:
Person [name=jack, age=20]
Person [name=tom, age=23]
Person [name=tom, age=19]
Person [name=ww, age=20]
Person [name=zs, age=21]????????對于整型、浮點型元素,它們會按照從小到大的順序進行排序。對于字符串類型的元素,它們會按照字典順序進行排序。
注意事項:compareTo方法的放回結果,只關心正數、負數、零,不關心具體的值是多少
2)TreeSet 比較器排序
思考:如果上述案例中Person類不是自定義類,而是第三方提供好的(不可以修改源碼),那么如何實現排序規則的指定?
我們可以使用比較器(Comparator)來自定義排序規則。
比較器排序步驟:
- 創建一個實現了Comparator接口的比較器類,并重寫其中的 compare() 方法
- 該方法定義了元素之間的比較規則。在 compare() 方法中,我們可以根據元素的屬性進行比較,并返回負整數、零或正整數,來表示元素之間的大小關系。
- 創建TreeSet對象時,將比較器對象作為參數傳遞給構造函數,這樣,TreeSet 會根據比較器來進行排序。
compare方法說明:
???????? int result = compare(o1, o2);
- result的值大于0,表示升序
- result的值小于0,表示降序
- result的值等于0,表示元素相等,不能插入
注意:這里和自然排序的規則是一樣的,只關心正數、負數、零,不關心具體的值是多少
案例展示:
使用比較器排序,對上述案例中Person進行排序,要求先按age升序,age相同則按name降序。
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;public class TestPerson {public static void main(String[] args) {//1.準備自定義比較器對象//匿名內部類形式Comparator<Person> comp = new Comparator<Person>() {//重寫比較算法:先按age升序,age相同則按name降序@Overridepublic int compare(Person o1,Person o2){int r = o1.getAge() - o2.getAge();if (r == 0) {//注意:比較字符串需使用compareTo()方法r = o2.getName().compareTo(o1.getName());}return r;}};//2.實例化TreeSet,傳入自定義比較器對象Set<Person> set = new TreeSet<>(comp);//3.添加元素set.add(new Person("zs",21));set.add(new Person("ww",20));set.add(new Person("zs",21));set.add(new Person("tom",19));set.add(new Person("tom",23));set.add(new Person("jack",20));//4.遍歷集合for (Person person : set) {System.out.println(person);}}
}運行結果:
Person [name=tom, age=19]
Person [name=ww, age=20]
Person [name=jack, age=20]
Person [name=zs, age=21]
Person [name=tom, age=23]注意:如果同時使用自然排序和比較器排序,比較器排序將覆蓋自然排序。
| 對比項 | 自然排序(Comparable) | 比較器排序(Comparator) |
|---|---|---|
| 實現位置 | 元素類內部實現接口,重寫?compareTo | 元素類外部創建比較器,重寫?compare |
| 排序規則數量 | 一個類只能有一種自然排序規則 | 一個類可以有多個比較器,實現不同規則 |
| 優先級 | 若同時傳比較器,自然排序會被覆蓋 | 傳入比較器時,優先用比較器規則 |
| 適用場景 | 元素有固定、單一排序規則(如?Integer?數值) | 需要臨時、多樣化排序(如有時按年齡,有時按姓名) |
| 代碼侵入性 | 必須修改元素類代碼(讓其實現?Comparable) | 無需修改元素類,外部單獨定義規則 |
1.4 LinkedHashSet
????????LinkedHashSet 是 HashSet 的一個子類,具有 HashSet 的高效性能和唯一性特性,并且保持了元素的插入順序,其底層基于哈希表和鏈表實現。
案例展示:
實例化一個LinkedHashSet集合對象,存入多個String字符串,觀察是否唯一及順序存儲。
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;public class Test_LinkedHashSet {public static void main(String[] args) {//1.實例化LinkedHashSetSet<String> set = new LinkedHashSet<>();//2.添加元素set.add("bbb");set.add("aaa");set.add("abc");set.add("bbc");set.add("abc");//3.迭代器遍歷Iterator it = set.iterator();while (it.hasNext()) {System.out.println(it.next());}}
}運行結果:
bbb
aaa
abc
bbc1.5 Set 小結
下節我們學習Map集合。






階段小總結(一)——大數據與Java)



)

![[機器學習]基于K-means聚類算法的鳶尾花數據及分類](http://pic.xiahunao.cn/[機器學習]基于K-means聚類算法的鳶尾花數據及分類)
---PCB鋪銅相關操作)

函數分析)

)

